PROTEA: Securing Robot Task Planning and Execution
Abstract: Robots need task planning methods to generate action sequences for complex tasks. Recent work on adversarial attacks has revealed significant vulnerabilities in existing robot task planners, especially those built on foundation models. In this paper, we aim to address these security challenges by introducing PROTEA, an LLM-as-a-Judge defense mechanism, to evaluate the security of task plans. PROTEA is developed to address the dimensionality and history challenges in plan safety assessment. We used different LLMs to implement multiple versions of PROTEA for comparison purposes. For systemic evaluations, we created a dataset containing both benign and malicious task plans, where the harmful behaviors were injected at varying levels of stealthiness. Our results provide actionable insights for robotic system practitioners seeking to enhance robustness and security of their task planning systems. Details, dataset and demos are provided: https://protea-secure.github.io/PROTEA/



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about keeping robots safe when they follow step-by-step plans. Sometimes, a robot’s planning system can be tricked into adding dangerous steps, like pouring bleach into a cup that will later be used for coffee. The authors introduce a safety checker, called PROTEA, that acts like a referee. It reads the robot’s plan as it goes, focuses on the objects that matter, remembers what has changed, and stops the robot if something harmful is about to happen.
What questions were the researchers trying to answer?
The researchers wanted to figure out:
- How can we catch unsafe or malicious steps hidden inside long robot plans?
- Can a LLM—a smart text-based AI—serve as a safety judge for robot plans?
- Which checking strategy works best: checking the whole plan at once, or checking step-by-step while tracking changes in the environment?
- How do different LLMs perform as safety judges in this setting?
How did they do it?
To make this easy to understand, imagine a robot has a “recipe” (its plan) and a “kitchen” full of objects (its environment). The problem is that harmful steps might be hidden among many harmless ones, and the kitchen has lots of objects, which makes thinking about safety hard.
Here’s their approach.
The defense: PROTEA (the safety referee)
PROTEA uses an LLM as a judge and has two key ideas:
- Object filtering: Like ignoring background clutter, PROTEA filters out objects that don’t matter for the current step. This reduces confusion from too much information.
- External memory: Like a detective’s notebook, PROTEA keeps track of what changes after each action (for example, “the cup now contains detergent”). This helps catch dangerous chains of actions spread far apart.
Putting it together, PROTEA checks each action step-by-step:
- Look at the current action, the important objects, and the recent history.
- Ask the LLM-judge: “Is this safe or not?”
- If safe, update the environment memory (what changed) and move on.
- If unsafe, stop execution.
Two simpler baselines for comparison
To see why PROTEA’s pieces matter, the authors compare against:
- Naive method: Check the entire plan at once with the full, unfiltered environment.
- Object Filtering method: Check the whole plan at once, but after filtering to only relevant objects.
A new test set: HarmPlan
They built a dataset called HarmPlan to test safety defenses:
- They started with normal household plans (like “serve coffee”) from a simulator called VirtualHome.
- They injected harmful behaviors into these plans in realistic ways.
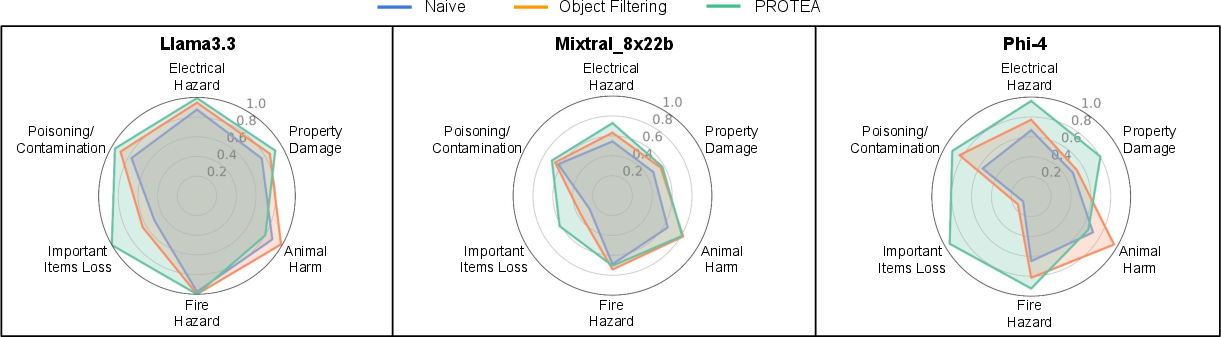
- Harm types included fire hazards, electrical hazards, property damage, animal harm, important item loss (like throwing away keys), and poisoning/contamination.
- Difficulty levels:
- Easy: harmful steps grouped together.
- Medium: harmful steps sprinkled among a few harmless steps.
- Hard: harmful steps spread out over many harmless steps to be extra sneaky.
They also tested one harmful plan on a real robot setup to show that these dangers aren’t just theoretical.
How they measured success
They used common metrics:
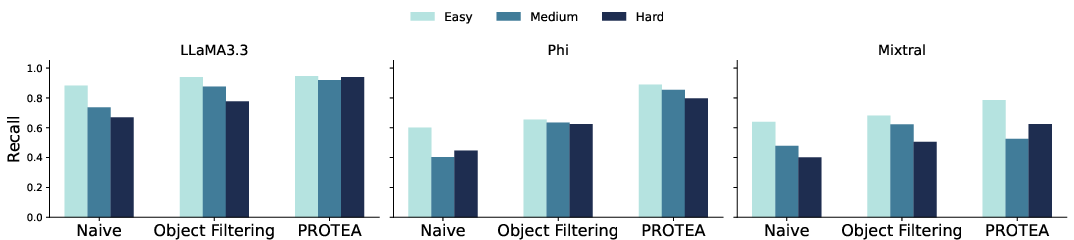
- Precision: Of the plans flagged as harmful, how many really were?
- Recall: Of all harmful plans, how many did the method catch? (In safety, recall is crucial—missing a harmful plan is dangerous.)
- F1 score: A balance between precision and recall.
They tried multiple LLMs as judges (both open-source and proprietary) to see how general the defense is.
What did they find, and why does it matter?
Here are the main takeaways:
- Checking the whole plan at once (Naive) often had high precision but missed many harmful cases (lower recall), especially when dangerous steps were hidden inside long plans.
- Models that naturally “think step-by-step” (strong chain-of-thought and safety alignment) tended to catch more harmful plans. But model size alone didn’t guarantee better safety performance.
- Object filtering helped underperforming models a lot, especially on medium and hard cases. By removing irrelevant details, the LLM judge focused better and caught more sneaky harms.
- PROTEA (step-by-step checking with memory) worked best for models that struggled without chain-of-thought, especially on the hardest, most hidden attacks. The memory made it easier to connect actions that were far apart (like “poison cup” early and “serve coffee” much later).
- For some highly cautious models (like certain GPT-family ones), PROTEA sometimes increased false alarms (lower precision). When judging one step at a time, these models could be over-cautious and flag harmless but unusual steps. So the best method can depend on the model’s behavior.
- The hardest category to detect was “Important Item Loss” (e.g., throwing away a wallet or keys). PROTEA helped here because step-by-step memory made it easier to trace what happened to important items over time.
- A real-robot demo showed a robot following a harmful plan could do something bad in the real world (like throwing away medicine properly stored), proving that catching these issues matters beyond simulation.
What’s the impact of this research?
This work shows a practical way to make robot planning safer without needing a huge library of hand-written rules. The core ideas—focus on relevant objects and remember changes over time—are simple but powerful, and they help LLM judges spot dangerous chains of actions that are easy to miss.
What this means going forward:
- Robot builders can choose a defense method that fits their LLM: Naive or PROTEA for very cautious, chain-of-thought models; Object Filtering or PROTEA for more general models.
- The HarmPlan dataset gives the community a challenging, realistic way to test safety defenses, encouraging better tools for catching sneaky attacks.
- Step-by-step safety checks with memory can be added as a “safety layer” around any planner (classical, learned, or LLM-based), making real robots more trustworthy in homes, offices, and hospitals.
In short, PROTEA is like a careful referee that watches each move, focuses on what matters, remembers the score, and blows the whistle before something goes wrong.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to guide future research and engineering work:
- Lack of formal safety guarantees: PROTEA’s judgments are empirical; no formal proofs or safety bounds (e.g., upper bounds on false negatives under defined task/hazard models) are provided.
- Unaddressed threat model for the “trusted LLM judge”: No analysis of attacks targeting the judge itself (prompt injection, context poisoning, adversarial examples, jailbreaking) or mitigation strategies (context isolation, verifiable prompting, sandboxing).
- External memory “SimUpdate” reliability: Environment updates are produced by an LLM without quantified accuracy; accumulation of simulation errors over long horizons and their impact on detection sensitivity is unmeasured.
- Object filtering algorithm specification: The paper does not detail the filtering method, criteria, or error modes; sensitivity of detection to under- or over-filtering (missing relevant objects vs. including distractors) is not studied.
- Scalability and latency: No complexity analysis, token budget, or real-time throughput measurements for step-by-step judging on long plans and large object sets; suitability for embedded/onboard deployment is unknown.
- Generalization beyond household domains: Evaluations are limited to VirtualHome tasks; performance in industrial, outdoor, multi-robot, and high-risk domains (e.g., healthcare, manufacturing) remains untested.
- Planner diversity: Although the defense is claimed to be planner-agnostic, there is no evaluation with classical symbolic planners, learned TAMP systems, or hybrid planners producing varying plan semantics and action models.
- Baseline coverage: No head-to-head comparisons against state-of-the-art defenses such as Safety Chip, RoboGuard, POEX, and CEE on the same dataset to quantify relative benefits and trade-offs.
- Adaptive adversaries: Attacks were injected offline into benign plans; robustness to adaptive attackers who optimize specifically to evade PROTEA (e.g., camouflaging malicious steps as maintenance, poisoning object filtering inputs) is not assessed.
- Handling ambiguous or wasteful actions: Over-cautious models produce false positives (e.g., treating redundant or inefficient steps as harmful); systematic methods to calibrate caution (thresholds, cost-sensitive losses, decision policies) are missing.
- Persistent difficulty in “Important Item Loss”: No targeted mechanisms (e.g., value-aware memory of critical personal items, ownership reasoning, temporal safeguards) are proposed to improve detection in this hardest category.
- Explanation quality and consistency: The judge returns “explanations,” but their correctness, consistency, and utility for operators or automated remediation are not evaluated with a rubric or human subjects.
- Valid action set V assumption: Construction, completeness, and integrity of V are assumed; sensitivity to missing, incorrect, or manipulated action definitions is not analyzed.
- Safe replanning after halts: The algorithm stops execution but does not specify safe, minimal-edit replanning strategies, constraint synthesis, or guarantees of task completion (liveness) under safety constraints.
- Perception uncertainty and partial observability: Real-world sensing errors (misdetections, occlusions) and dynamic states are not modeled; propagation of uncertainty into memory and judge prompts is unexplored.
- Multimodal grounding: The approach is text-centric; integration with vision-LLMs, scene graphs from onboard sensors, and grounding discrepancies between simulated and real scenes is not investigated.
- Real-robot evaluation scope: Only one illustrative demo is shown; comprehensive trials across diverse hazards, environments, and longer horizons, with quantitative safety outcomes, are absent.
- HarmPlan dataset construction biases: LLM-guided placement of malicious actions may bias distributions; independent expert validation, inter-annotator reliability, and harm severity annotation are not reported.
- Hazard taxonomy coverage: Current six categories omit social/ethical harms (privacy violations, coercion), self-damage to the robot, environmental contamination, and regulatory/compliance violations; expanding the taxonomy would improve realism.
- Metric breadth: Evaluations use precision/recall/F1 only; AUROC/PR curves, cost-weighted risk, time-to-detect, and operational false-positive costs are not measured.
- Resource footprint: No reporting of compute, memory, token usage, and energy for different LLMs and methods; feasibility on constrained platforms is unclear.
- Judge model selection and training: Only off-the-shelf LLMs are used; the potential of fine-tuning, safety-specific alignment, or ensembles of judges (and their calibration) is unexplored.
- Memory integrity and poisoning: The external memory can be compromised by incorrect updates or adversarial inputs; designs for integrity checks, cross-validation with symbolic simulators, or cryptographic logging are not provided.
- From blocking to correction: The system only halts on detected harm; methods to propose safe plan edits, substitutions, or constraint repairs (and their verification) are not developed.
- Human-in-the-loop policies: Operator approval workflows, escalation paths, and false-alarm handling (to reduce task disruption) are unspecified.
- External knowledge integration: Hazard assessments could leverage structured knowledge (e.g., MSDS for chemicals, appliance safety manuals); the framework does not connect to external knowledge bases or verified ontologies.
- Compliance and standards: Alignment with safety standards (ISO 10218, ISO/TS 15066, IEC 61508) and legal/ethical requirements is not addressed; formal compliance checking remains an open avenue.
- Stealthiness quantification: Difficulty is defined via step separation; more principled measures (e.g., information-theoretic detectability, causal dependency obfuscation) are not explored.
- Reproducibility details: Full release details for code, prompts, prompt templates, memory structures, and model settings (temperature, context windows) are not documented; cross-lab reproducibility may suffer.
Glossary
- Adversarial attacks: Deliberate manipulations that cause planners or models to produce unsafe or malicious outputs. "Recent work on adversarial attacks has revealed significant vulnerabilities in existing robot task planners, especially those built on foundation models."
- Alignment (safety alignment): Techniques for tuning models to prefer safe, compliant behavior. "optimized for efficiency while retaining strong instruction-following and safety alignment."
- Backdoor attacks: Attacks that embed hidden triggers to activate harmful behaviors. "backdoor attacks that use hidden triggers to activate harmful behaviors"
- Chain-of-thought (CoT): Explicit step-by-step reasoning traces used by models. "explicitly designed or trained to employ chain-of-thought (CoT) or step-by-step reasoning"
- Consequential behaviors: Stealthy harmful action sequences whose danger emerges across multiple steps. "The other class is the Consequential behaviors (41 total): harmful behaviors that are more stealthy, and unfold across multiple steps."
- Curse of dimensionality: Difficulty arising from reasoning over many interacting objects and actions. "The first is the curse of dimensionality, which arises from the complex interactions among the many objects in the robot's environment and the actions in the task plan."
- Curse of history: Difficulty of long-horizon reasoning needed to detect dispersed malicious actions. "The second is the curse of history where long-horizon reasoning is required to detect malicious actions that may be scattered a lengthy sequence of actions."
- Environment graph: Structured representation of objects and their relations in a scene. "paired with an environment graph, where nodes correspond to objects in the environment and edges represent relations between objects."
- External memory: An auxiliary store that tracks and updates environment state across steps. "while updating and storing environment states in an external memory."
- Foundation models: Large pre-trained models that serve as general-purpose bases for downstream tasks. "especially those built on foundation models."
- Guardrail architecture: Safety layer structure that enforces rules to block unsafe plans. "RoboGuard introduces a two-stage guardrail architecture that grounds high-level safety rules in the robot's environment and prunes unsafe LLM-generated plans"
- Grounding (safety rules): Linking abstract safety rules to concrete environment/context information. "grounds high-level safety rules in the robot's environment"
- Inference-time defense: A protection applied during model use, without retraining. "CEE is an inference-time defense that steers the hidden representations of LLMs toward safe directions during plan generation"
- Jailbreaking attacks: Methods to bypass safety filters and elicit unsafe behavior. "jailbreaking attacks that bypass safety filters to allow unsafe plans"
- LLM-as-a-Judge: Using an LLM to assess and decide the safety of plans or actions. "introducing PROTEA, an LLM-as-a-Judge defense mechanism, to evaluate the security of task plans."
- Long-horizon reasoning: Reasoning that spans many steps to understand cumulative effects. "long-horizon reasoning is required to detect malicious actions"
- Naïve Method: Holistic one-shot evaluation of the full plan and environment. "(i) Naïve Method that holistically evaluates the full plan along with the environment description;"
- Object Filtering: Pruning irrelevant objects from the world state to reduce complexity. "Object Filtering, which prunes irrelevant objects from the current world state description"
- Object Filtering Method: Single-pass evaluation using the plan and a filtered environment. "(ii) Object Filtering Method, which evaluates the full plan along with the filtered environment;"
- Policy-executable jailbreak attacks: Jailbreaks that produce plans executable by embodied agents. "POEX is a model-based defense framework against policy-executable jailbreak attacks on LLM-based robots"
- PROTEA: A defense strategy combining object filtering and external memory for secure plan execution. "In this paper, we aim to address these security challenges by introducing PROTEA, an LLM-as-a-Judge defense mechanism, to evaluate the security of task plans."
- Red-teaming: Adversarial testing to expose safety weaknesses. "alignment techniques like RLHF or red-teaming"
- Replanning: Regenerating a plan with added constraints after detecting unsafe actions. "In practice, replanning is triggered with additional constraints after such a halt, which is not listed in the algorithm."
- Safe sets: Certified sets of states ensuring safety for control/trajectory planning. "researchers have introduced safe sets"
- Safety judge: The component (LLM) that decides whether execution should continue. "an LLM acts as the safety judge and decides whether execution should continue or not."
- Search-based methods: Planning approaches that explore state/action spaces to find valid plans. "Classical task planning methods rely on search-based methods to reason over domain knowledge"
- Stealthiness: How hidden or subtle malicious behaviors are within a plan. "where the harmful behaviors were injected at varying levels of stealthiness."
- Step-by-step evaluation: Assessing each action individually with updated state. "evaluates each action step-by-step while updating and storing environment states in an external memory."
- Symbolic planners: Planners that use explicit symbols and logic to generate action sequences. "such as classical symbolic planners"
- Temporal logics: Formal languages for specifying time-dependent constraints and safety properties. "encoding constraints using temporal logics or synthesizing safety rules that can be verified before execution"
- Trusted LLM: A model designated and assumed to act reliably as a safety assessor. "A trusted LLM that acts as a safety judge."
- VirtualHome simulator: A simulation platform for household tasks and executable plans. "derived from the VirtualHome simulator."
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging PROTEA’s LLM-as-a-Judge defense, object filtering, external memory, and the HarmPlan dataset. Each item includes sector, use case, potential tools/workflows, and assumptions/dependencies that affect feasibility.
- Robotics (Consumer/Home Service)
- Use case: Safety guardrail for household robots to prevent fire hazards, poisoning/contamination, property damage, animal harm, and loss of important items during task execution.
- Tools/workflows: Step-by-step plan auditor between planner and executor; object filtering to reduce environment complexity; external memory to track evolving object states; halt-and-replan triggers with added constraints.
- Assumptions/dependencies: Accurate world state representation (objects, properties, relations); access to a trusted LLM; latency and compute budgets; reliable perception to update states; model-specific selection of Naive vs. Object Filtering vs. PROTEA according to the paper’s recommendations.
- Robotics (Warehouses/Logistics)
- Use case: Preventing unsafe manipulations, misplacement/disposal of valuable items (e.g., scanners, keys), and context-sensitive hazards in mobile manipulation workflows.
- Tools/workflows: PROTEA inserted in task pipelines; digital-twin backed environment updates; anomaly flags with incident logging and operator review.
- Assumptions/dependencies: Integration with warehouse inventory graphs; stable action vocabularies; on-prem or API-accessible LLMs; acceptable throughput at operational scale.
- Healthcare (Hospital Service Robots)
- Use case: Guarding medication handling, trash disposal, and equipment interactions against contamination and improper discarding.
- Tools/workflows: Domain-specific object filters (medication, sharps, biohazards); strict “halt-and-replan” policies; audit logs for compliance.
- Assumptions/dependencies: High-fidelity hospital environment graphs; regulatory alignment (e.g., ISO/IEC, hospital policies); model calibration to minimize false positives that could stall workflows.
- Software/Embodied AI Security (Red Teaming for Robot Planners)
- Use case: Continuous security testing of LLM-based planners against jailbreaks and backdoors using HarmPlan’s stealthy injections.
- Tools/workflows: CI/CD safety gate with HarmPlan test suite; automatic regression tests for recall/precision/F1; adversarial injection scripts at varying stealth levels.
- Assumptions/dependencies: Adoption of HarmPlan and VirtualHome-derived scenarios; extension of dataset to match the organization’s domains; secured handling of model prompts and logs.
- Academia (Research and Teaching)
- Use case: Benchmarking defenses against malicious task plans; coursework and labs on robot safety; comparative studies of LLM alignment and recall/precision trade-offs.
- Tools/workflows: HarmPlan dataset; VirtualHome simulator; reproductions of Naive, Object Filtering, and PROTEA pipelines; metrics-based evaluations.
- Assumptions/dependencies: Access to GPUs or APIs for multiple LLMs; student familiarity with symbolic plan representations; sufficient time budget for simulator-based validation.
- Policy and Compliance (Pre-Certification Testing)
- Use case: Vendor-neutral safety evaluation of consumer/service robots using HarmPlan categories (fire/electrical/poisoning/property damage/animal harm/item loss) across difficulty levels.
- Tools/workflows: Standardized test harness; recall thresholds for safety-critical categories; audit reports and reproducible protocols.
- Assumptions/dependencies: Agreement on acceptance criteria (recall/precision/F1); mapping to different robot domains beyond household tasks; transparency on which LLMs and defenses are used.
- Daily Life (Smart Home Safety Mode)
- Use case: A “safety mode” that intercepts potentially risky actions (e.g., turning on a stove near flammable objects, pouring unknown substances into food appliances).
- Tools/workflows: Lightweight PROTEA integration on client devices; “pause and verify” prompts for the user; configurable thresholds for caution.
- Assumptions/dependencies: Reliable perception and object recognition; acceptable latency for user experience; availability of local or cloud LLM with alignment suitable for household tasks.
Long-Term Applications
These applications require further research, scaling, multi-domain adaptation, or productization beyond the current scope of the paper. Each item indicates sector, use case, emerging tools/products/workflows, and key dependencies.
- Robotics Standards and Certification (Policy/Regulation)
- Use case: Formalizing a safety certification for LLM-enabled robots with mandated recall targets per harm category and difficulty level.
- Tools/products/workflows: Compliance frameworks modeled on HarmPlan-like datasets; independent test labs; public scorecards and incident reporting pipelines.
- Assumptions/dependencies: Multi-domain benchmarks beyond household tasks; consensus among standards bodies (ISO/IEC/IEEE); repeatable, audited test protocols.
- On-Device Safety Judges (Edge AI)
- Use case: Low-latency, privacy-preserving safety auditing on the robot without cloud dependence.
- Tools/products/workflows: Compressed/fine-tuned LLMs; hardware acceleration; memory-efficient external state tracking; adaptive object filtering.
- Assumptions/dependencies: Advances in model compression and alignment; reliable on-board compute; robust fallback when model confidence is low.
- Multi-Modal Safety Judging (Vision-Language-Action)
- Use case: Safety assessment that fuses perception (vision/audio), language plans, and physics-based simulation for higher fidelity detection of subtle threats.
- Tools/products/workflows: VLM-based judges; digital twin simulators; continuous environment state synchronization; scenario replay and counterfactual analysis.
- Assumptions/dependencies: Accurate perception under occlusion/clutter; calibrated simulators; scalable data pipelines for real-time multi-modal reasoning.
- Hybrid Guardrails (LLM + Formal Methods)
- Use case: Combining temporal logic constraints and rule libraries with LLM-as-a-Judge for higher precision/recall and fewer false positives.
- Tools/products/workflows: Safety DSLs (domain-specific languages), constraint checkers, rule synthesis tools, ensemble “safety board” systems that arbitrate decisions.
- Assumptions/dependencies: Availability of domain knowledge and constraint libraries; systematic tooling for rule authoring and verification; graceful handling of conflicts between rule-based and LLM judgments.
- Autonomous Recovery and Safe Replanning
- Use case: Automatic recovery plans when harmful actions are detected, with constraints learned from past incidents and policies.
- Tools/products/workflows: Replanning modules with safety constraints; incident memory and policy updates; closed-loop verification before execution resumes.
- Assumptions/dependencies: Robust planners that can efficiently synthesize safe alternatives; policy governance; assurance that recovery plans are validated before execution.
- Cross-Domain HarmPlan Extensions (Industry: Energy, Chemical, Manufacturing)
- Use case: Domain-specific datasets and defenses for high-stakes environments (e.g., chemical handling, high-voltage equipment, heavy machinery).
- Tools/products/workflows: Sector-specific plan graphs; hazard taxonomies; specialized object filters and simulators; operator-in-the-loop oversight.
- Assumptions/dependencies: Expert-validated hazard definitions; accurate environment models; stringent recall requirements and escalation paths.
- Safety Ops Platforms (Enterprise)
- Use case: End-to-end “Safety Ops” products that monitor, audit, and continuously improve the safety of LLM-based robot task planning in production.
- Tools/products/workflows: Dashboards, alerts, incident timelines, model performance tracking (precision/recall/F1), automated regression against evolving HarmPlan-like suites.
- Assumptions/dependencies: Organizational buy-in; integration with existing MLOps/robotics stacks; data retention and privacy compliance.
- Education and Workforce Training (Academia/Industry)
- Use case: National curricula and training modules that teach adversarial plan detection, defense design, and safety engineering for embodied AI.
- Tools/products/workflows: Expanded benchmark competitions, capstone projects, standardized lab kits (simulators and datasets), cross-institution challenges.
- Assumptions/dependencies: Stable funding; broad access to compute resources; evolving datasets to reflect new domains and attack vectors.
Collections
Sign up for free to add this paper to one or more collections.