- The paper introduces a multiword decomposition framework that extends floating-point arithmetic to support modular matrix multiplication for primes nearly matching the full mantissa size.
- The method decomposes matrices into weighted submatrices, optimizing performance with standard BLAS libraries and GPUs while systematically controlling rounding errors.
- Experimental benchmarks and theoretical analysis demonstrate significant performance gains over traditional single-word and CRT-based approaches for large primes.
Multiword Matrix Multiplication over Large Finite Fields in Floating-Point Arithmetic
Introduction and Motivation
Efficient modular matrix multiplication C=ABmodp is a fundamental computational kernel for computer algebra systems, particularly for problems involving exact linear algebra over large finite fields. Existing floating-point-based approaches to modular arithmetic are severely constrained by the requirement that the modulus p be at most half the floating-point mantissa size—226 for IEEE double precision—due to representability and rounding error limitations. As p approaches this bound, computational efficiency deteriorates rapidly. Practically, this limitation necessitates arbitrary-precision or multimodular approaches, which are slower and less compatible with high-performance BLAS libraries or GPU acceleration.
This paper introduces a framework for modular matrix multiplication that overcomes this bottleneck. The authors propose and analyze a multiword decomposition method that enables computations for primes p with bitsizes nearly equal to the full floating-point mantissa, retaining high throughput on both CPUs and GPUs. The approach generalizes the single "word" representation of finite field elements by expressing matrices as sums of scaled submatrices (multiword decomposition) with systematically controlled coefficient ranges.
Multiword Decomposition: Methodology and Analysis
The core of the method is the decomposition of the input matrices A and B into sums of matrices weighted by powers of carefully chosen scaling factors α and β:
A=i=0∑u−1αiAi,B=j=0∑v−1βjBj
where u and v are the multiword lengths for A and B, respectively, and each Ai (resp. Bj) is chosen so that its entries are bounded and manageable by the floating-point arithmetic. The product AB is recovered as a linear combination:
C=AB=i=0∑u−1j=0∑v−1αiβjAiBjmodp
Key analytical results establish the correctness of this decomposition in floating-point arithmetic, providing explicit bounds on coefficient sizes and systematically accounting for rounding errors. A rigorous condition on p and the block size λ for matrix products is derived, controlling the tradeoff between arithmetic intensity and the number of subproducts required. The (2,2) decomposition is found to offer nearly the full 253-bit range of double-precision arithmetic, a dramatic improvement over the single-word method.
Algorithmic Details and Block Matrix Product Regime
Two main algorithms are introduced. The first (multiword product) computes each AiBj subproduct independently and accumulates them, carefully scaling and reducing at each stage to maintain correctness modulo p. The second (concatenated multiword product) leverages the ability to concatenate Bj blocks to increase the arithmetic intensity of matrix multiplication on unbalanced matrices. Both approaches rely on fused multiply-add and modular inverse computations that are efficient in standard BLAS libraries and on modern CPUs/GPUs with plentiful SIMD/FMA resources.
A critical consideration is tuning u, v (multiword lengths), and λ (block size) adaptively based on p and matrix dimensions to balance the number of matrix multiplications (cost scales with uv) with retention of large, efficient block sizes (which minimize the frequency and cost of modular reductions).
Comprehensive experimental benchmarks were conducted using both CPU and GPU implementations, employing Intel MKL and cuBLAS. Performance was evaluated using "effective Gflops/s" to allow comparison across approaches with differing arithmetic workloads.
For square, large matrices, the traditional single-word algorithm achieves near-peak floating-point performance (e.g., 1200 Gflops/s on CPU, 16000 Gflops/s on GPU) until p nears 224−26, after which performance drops precipitously. In contrast, the multiword algorithms maintain high and predictable performance for larger p, with the (1,2), (1,3), (1,4), and (2,2) variants incrementally increasing the upper bound for p up to 252. Notably, crossover points at which different multiword variants become optimal are clearly observed in the data, validating the theoretical analysis.
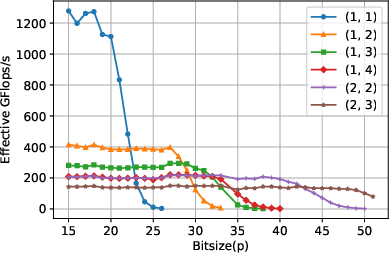
Figure 1: Performance benchmark for square matrices on CPU, matching theoretical crossovers and showing superior throughput for multiword variants at increasing p.
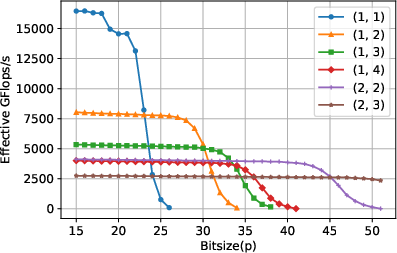
Figure 2: Performance benchmark for square matrices on GPU, illustrating efficient exploitation of hardware by adaptive multiword decomposition.
For highly unbalanced (tall-and-skinny) matrices, performance is naturally limited by the reduced arithmetic intensity. However, the concatenated variant provides substantial gains by enabling larger effective block sizes in the key matrix dimension, thus partially mitigating this limitation.
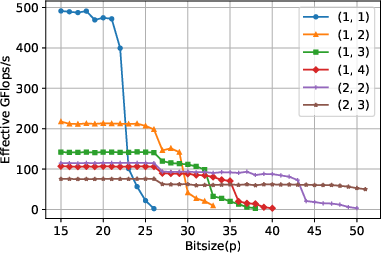
Figure 3: Performance benchmark for unbalanced matrices on CPU, multiword variants outperform the single-word routine for moderately large primes.
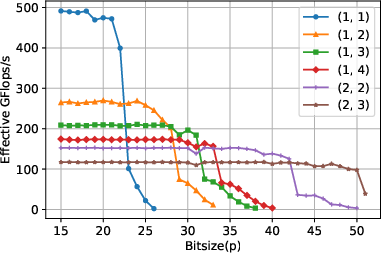
Figure 4: Performance benchmark for unbalanced matrices on CPU, with concatenation, highlighting the marked improvement in arithmetic intensity for multiword methods.
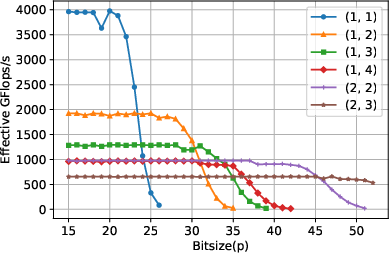
Figure 5: Performance benchmark for unbalanced matrices on GPU; multiword approaches allow efficient use of device for larger p.
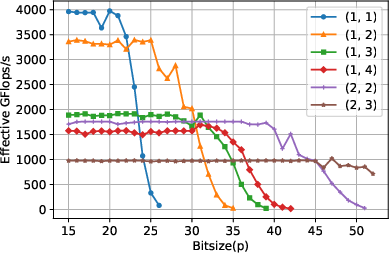
Figure 6: Performance benchmark for unbalanced matrices on GPU, with concatenation, showing further enhancements for batched/concatenated computation.
Comparison with Multimodular and Precision Emulation Approaches
The multiword decomposition approach is compared analytically and, where possible, empirically with existing state-of-the-art multimodular (CRT-based) algorithms. For primes p with bitsizes between roughly half and the full floating-point mantissa, the multiword method provably requires strictly fewer modular matrix products than the CRT-based approach. This is especially true for (u,v) decompositions where u+v≤4 (e.g., (1,2), (2,2)), which dominate in practical scenarios. The method also offers easier integration and parallelism due to compatibility with dense BLAS kernels, and the concatenation trick is specifically advantageous for batched computations involving tall/skinny matrices—something CRT approaches cannot exploit.
A link is also established with mixed-precision "emulation" strategies from recent floating-point linear algebra research. The multiword modular approach both benefits from (and generalizes) these ideas but maintains mathematical exactness, in contrast with inexact emulation schemes.
Practical and Theoretical Implications
This work fills a critical gap in the computational algebra landscape by enabling exact modular matrix computation modulo large primes using efficient floating-point hardware. Practically, it unlocks the use of BLAS libraries and GPU acceleration for previously intractable operands, substantially improving the performance of symbolic computation pipelines, such as those involving block Wiedemann algorithms for polynomial solving and rational reconstruction via CRT.
Theoretically, the multiword decomposition establishes a tight tradeoff curve between the number of words (and hence products) and the size of p, revealing a clear, structured way to select decomposition parameters adaptively for optimal performance. The analysis tightly bounds rounding errors and representability at all computation stages.
Future developments may include extending the approach to even lower precision arithmetic (e.g., half/fp16 or integer tensor cores), exploiting batched and parallelized matrix multiplication kernels, and further integration within broader computer algebra systems. Another avenue is optimizing for memory bandwidth and storage when operating with large numbers of decomposition words.
Conclusion
This paper presents a robust and scalable framework for modular matrix multiplication over large finite fields, using multiword decomposition to fully harness floating-point hardware while ensuring mathematical exactness. The adaptive selection of decomposition parameters, coupled with proof-based analysis and extensive empirical validation, demonstrates both the practical viability and theoretical soundness of the approach. The results have immediate implications for scientific computing, symbolic computation, and the efficient deployment of modular linear algebra on modern multi- and many-core architectures.