Demystifying the Slash Pattern in Attention: The Role of RoPE
Abstract: LLMs often exhibit slash attention patterns, where attention scores concentrate along the $Δ$-th sub-diagonal for some offset $Δ$. These patterns play a key role in passing information across tokens. But why do they emerge? In this paper, we demystify the emergence of these Slash-Dominant Heads (SDHs) from both empirical and theoretical perspectives. First, by analyzing open-source LLMs, we find that SDHs are intrinsic to models and generalize to out-of-distribution prompts. To explain the intrinsic emergence, we analyze the queries, keys, and Rotary Position Embedding (RoPE), which jointly determine attention scores. Our empirical analysis reveals two characteristic conditions of SDHs: (1) Queries and keys are almost rank-one, and (2) RoPE is dominated by medium- and high-frequency components. Under these conditions, queries and keys are nearly identical across tokens, and interactions between medium- and high-frequency components of RoPE give rise to SDHs. Beyond empirical evidence, we theoretically show that these conditions are sufficient to ensure the emergence of SDHs by formalizing them as our modeling assumptions. Particularly, we analyze the training dynamics of a shallow Transformer equipped with RoPE under these conditions, and prove that models trained via gradient descent exhibit SDHs. The SDHs generalize to out-of-distribution prompts.
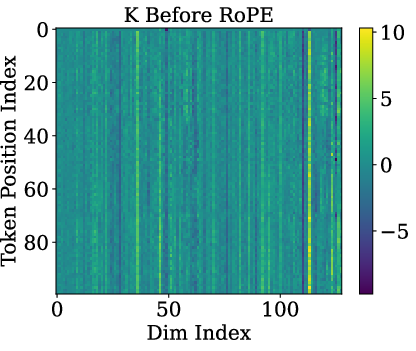
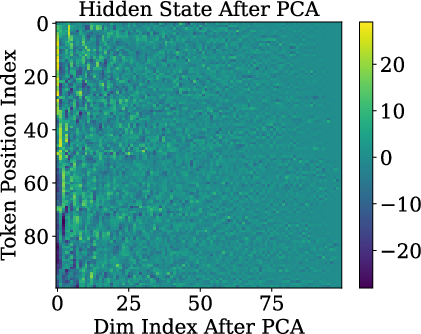
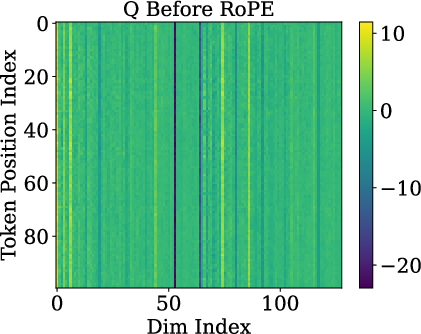
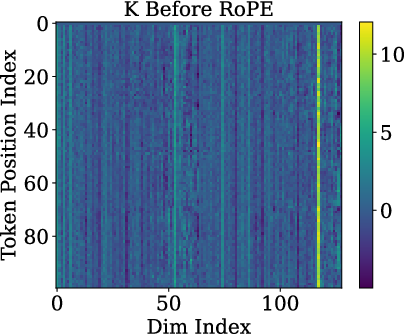

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tries to explain a strange and important pattern inside LLMs called the “slash pattern” in attention. Imagine the model reading a line of words and mostly “looking back” the same number of steps each time. If you drew how much each word looks back at earlier words in a grid, you’d see a bright diagonal line (a “slash”) off the main diagonal. The paper asks: why does this slash pattern show up, and what makes it work so well, even on strange or random inputs?
The authors find that a special way of adding position information, called RoPE (Rotary Position Embedding), combined with the shape of the model’s internal signals, is a big reason these slash patterns appear and work reliably.
What questions did the researchers ask?
In simple terms, they focused on three questions:
- Are slash patterns something that depends on the exact input text, or are they built into how the model is designed?
- What parts inside attention (the “queries,” “keys,” and RoPE) actually cause these slash patterns?
- Can we prove, not just observe, that slash patterns will show up during training under certain conditions?
How did they study it?
The team used two approaches: careful experiments on real models and a matching theory that explains what they saw.
Key ideas and everyday explanations
- Attention: When the model processes a sentence, attention tells each word which earlier words to focus on. Picture a student reading a paragraph and constantly glancing back to certain earlier words that matter.
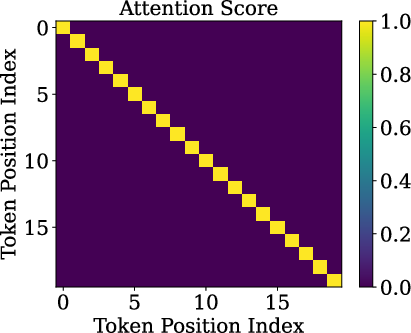
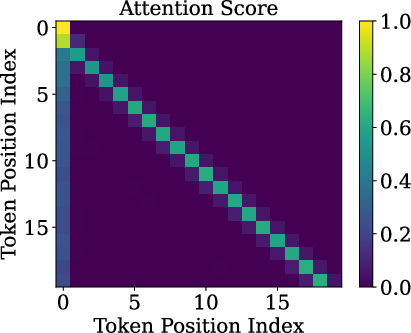
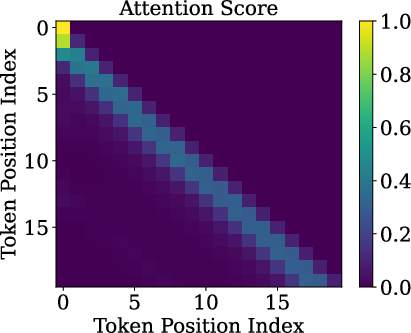
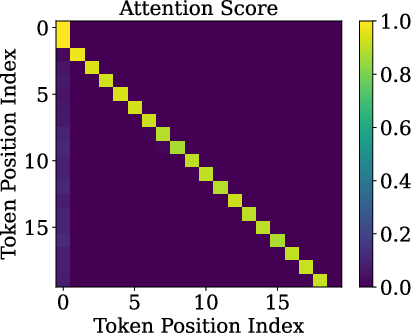
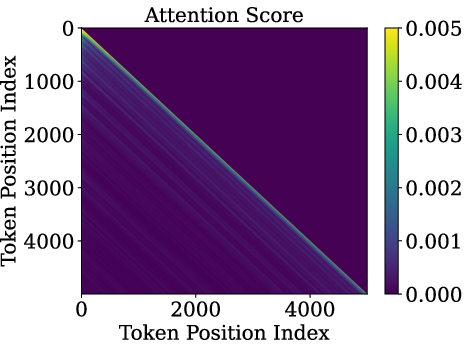
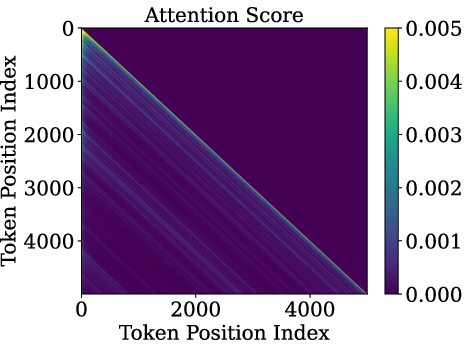
- Slash pattern (Slash-Dominant Head, SDH): A “head” is a small attention unit. In an SDH, each word mostly looks back by the same fixed distance (say, 1 word back, or 2 words back, or 500 words back). If you plot this, it looks like a slanted bright line—a “slash.”
- Queries and keys: Think of each word making a “question” vector (query) and each earlier word making an “answer tag” vector (key). Attention is high when the question matches a tag.
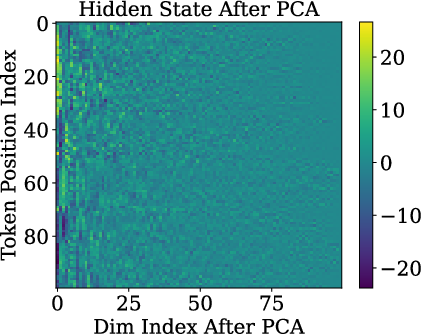
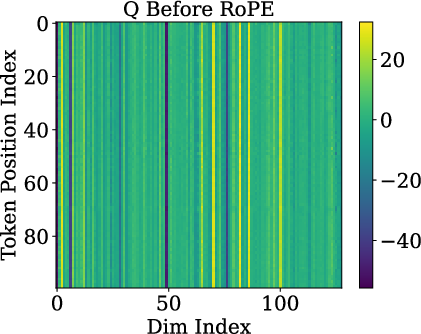
- Low-rank / rank-one: “Rank-one” is math for “almost everything points in the same direction.” Imagine a bunch of arrows that are nearly identical. That means they don’t carry much unique detail from word to word.
- RoPE (Rotary Position Embedding): This is how the model encodes “where” a word is in the sequence. RoPE rotates parts of the query and key vectors by angles that depend on position. You can picture each pair of numbers in a vector being “turned” a little, like rotating a 2D arrow. RoPE has many rotation speeds (“frequencies”)—some fast (high frequency), some slow (low frequency).
- Frequency mixing (waves): When many rotation speeds combine, they add up like waves in water. Sometimes peaks line up at a specific distance, creating strong attention at that lag (the “slash”).
What they did in experiments
- They inspected open-source LLMs (like Gemma-7B, Llama3-8B, and Qwen2.5-7B) and measured attention on normal prompts and also on random, nonsense prompts (out-of-distribution or OOD).
- They looked at the raw queries and keys before RoPE acts on them to see their structure.
- They analyzed how different RoPE frequencies (slow/medium/fast) contribute to the attention peaks.
What they did in theory
- They studied a simpler, math-friendly transformer with RoPE and showed that, if two conditions hold, training by gradient descent naturally produces slash heads: 1) Token embeddings (the model’s first layer representations) lie on a “cone” shape, which makes queries/keys almost rank-one (nearly identical across tokens). 2) RoPE’s frequencies are arranged so that their “wave peaks” reinforce attention at a specific distance (a “slash-dominance” condition).
- Under these conditions, they prove the model learns SDHs that also work on random inputs.
What did they find, and why is it important?
Here are the main findings, explained simply:
- Slash heads are intrinsic: The slash pattern doesn’t depend on the exact meaning of the input. It shows up even when the input is random. That means the pattern is built into the model’s structure and training, not just the data.
- Queries and keys are almost rank-one: Before RoPE is applied, the query and key vectors are almost the same direction for different tokens. In other words, they don’t carry much token-specific detail. This happens because token embeddings line up on a cone, and the model’s weights push queries/keys toward the cone’s main axis.
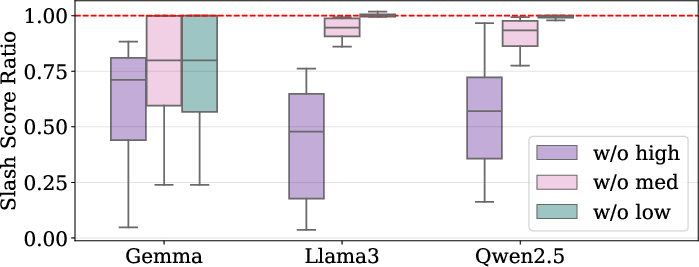
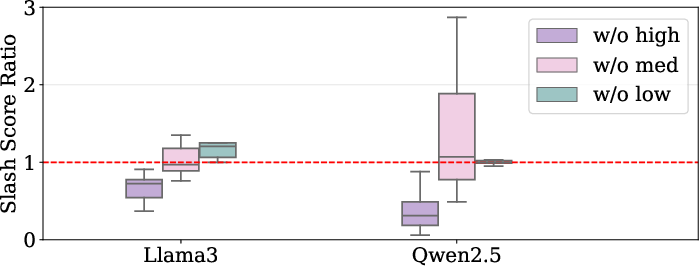
- RoPE does the heavy lifting: Since queries and keys are so similar, the differences in attention mostly come from RoPE’s rotations. RoPE’s medium and high frequencies (the faster “wave” components) combine to create strong peaks at certain offsets—those peaks make the slash lines. Low frequencies help less for this.
- Works in practice and theory: They show these effects in real models and also prove, with math, that the same thing should happen if certain conditions hold during training.
Why this matters:
- It explains a powerful in-context learning trick: The well-known “induction head” (looking back exactly one token to copy/continue patterns) is just a special slash head with Δ = 1. This helps the model remember and repeat structures across a prompt.
- It clarifies RoPE’s role: Instead of just “telling the model where it is,” RoPE’s frequencies actively shape which distances get strong attention, enabling long-range information passing and efficient pattern matching.
What does this mean for the future?
- Better model design: Knowing that medium/high RoPE frequencies drive slash patterns can guide how we choose or tune positional embeddings (e.g., which frequencies to emphasize) for longer contexts or specific tasks.
- Faster long-context inference: Since slash heads focus on specific lags, we can design speed-ups that compute only what matters at those distances, making long-context processing cheaper.
- Robust behavior on strange inputs: Because slash patterns are intrinsic, models can keep passing information reliably even on out-of-distribution prompts, which may help stability and safety.
- Mechanistic interpretability: This gives a clearer, testable picture of how attention heads coordinate to move information through text, improving our understanding of how LLMs “think.”
In short, the paper shows that slash attention patterns aren’t just a curiosity—they are a built-in effect of how queries/keys line up and how RoPE’s rotations “tune” attention to certain distances. This insight helps us interpret, improve, and speed up LLMs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points summarize what remains missing, uncertain, or left unexplored, framed to guide actionable future research:
- Scope limited to decoder-only Transformers with RoPE; behavior under other positional embeddings (e.g., ALiBi, absolute/learned PE, p-RoPE, YaRN, LongRoPE) and encoder–decoder architectures is untested.
- Slash-Dominant Head (SDH) identification depends on specific choices (context length 6000, threshold κ=0.1, excluding positions 1–4); sensitivity analyses over κ, context length, masking choices, and head-level normalization are absent.
- OOD generalization is evaluated only with i.i.d. uniform random tokens; generalization to realistic OOD domains (different languages/scripts, code, math, structured inputs, multi-modal) and varied tokenization schemes remains unknown.
- Functional generalization is not assessed: persistence of SDHs is shown in attention maps, but impact on task performance (e.g., ICL, copying, algorithmic tasks) under OOD inputs is not measured.
- “Queries/keys are almost rank-one” is suggested but not comprehensively quantified across layers/heads/models; necessity (vs. sufficiency) of low-rankness for SDHs, and its prevalence across the model depth, are open.
- Causal mechanism for low-rank Q/K is not established: the link from cone-shaped token embeddings and WQ/WK alignment to rank-one Q/K lacks controlled interventions (e.g., reorienting WQ/WK, altering embedding geometry) to validate causality.
- Role of normalization and architectural components (layer norm locations, attention biases as in Qwen, residual connections, MLP blocks) in producing/maintaining low-rank Q/K is not analyzed.
- RoPE frequency dominance is observed qualitatively; systematic ablations or reparameterizations of frequency spectra (e.g., varying base frequencies, gaps, interpolation schemes) to verify effects on SDH formation are missing.
- The Fourier-like logit decomposition assumes near-invariant amplitudes/phases across tokens due to rank-one Q/K; empirical quantification of amplitude/phase variability across positions, prompts, and heads is not provided.
- Influence of value vectors V and output mixing on effective information transfer is not studied; attention patterns alone may not guarantee semantic forwarding—alignment of V with SDH mechanisms remains unexplored.
- Theoretical guarantees are proven for a shallow, attention-only model on ICL regression with specific assumptions; extension to deep, multi-head models with MLPs, residuals, layer norms, and practical optimizers (Adam, weight decay, dropout) is an open direction.
- Necessity of the “slash-dominance frequency condition” is not established; an actionable diagnostic (computable criterion) for checking/inducing this condition in arbitrary models is not provided or empirically validated across diverse LLMs.
- Large-Δ SDHs (>1000) are noted with very small average slash scores; their mechanism, stability across sequence lengths, and functional utility are not characterized or linked to tasks.
- Interaction with other attention patterns (antidiagonal, vertical, block-sparse) and multi-head circuits (coordination/competition among heads) is not examined; how SDHs integrate into broader algorithmic structures remains unclear.
- Practical control and exploitation are not demonstrated: methods to tune RoPE frequencies or head parameters to target desired Δ (for acceleration or improved generalization) and trade-offs with semantic retention are unstudied.
- Stability under fine-tuning, instruction tuning, RLHF, and domain adaptation is unknown: do SDHs persist, shift, or degrade post-tuning, and how does this affect OOD generalization?
- Cross-scale and cross-architecture generality is unverified: results are shown on ~7–8B models; behavior in larger (e.g., 70B), MoE, grouped/multi-query attention, and other variants is unaddressed.
- Measurement choices may mask input-dependent variability: averaging attention maps across prompts could hide dynamics; per-token, per-position analyses and variance across prompts/heads are not reported.
- Exclusion of early positions (1–4) is heuristic; whether early-token artifacts fundamentally shape slash-dominance statistics and how to robustly correct for them is not resolved.
- Links from observed attention patterns to downstream behavior (e.g., copying bigrams, induction circuits with RoPE) are not causally tested via interventions (e.g., frequency ablation, head suppression/enhancement).
- Universality of cone-shaped embedding geometry across vocabularies/languages/scripts and across layers (beyond 0th embedding layer) is unverified; conditions under which cone geometry fails or changes are unknown.
- Effects of training data distribution/curriculum on SDH emergence are unexplored: can SDHs be promoted/suppressed via data or objectives, and under what regimes do they not arise?
- Context-length generalization beyond 6000 tokens (especially extremely long contexts) and the interplay with RoPE modifications for long-range attention are not empirically assessed.
- Guidance for leveraging SDHs in long-context acceleration methods (referenced prior work) is theoretical; end-to-end evaluations demonstrating practical speed/performance gains are missing.
Glossary
- ALiBi: A positional encoding method that adds linear biases to attention based on token distance, serving as an alternative to RoPE. "either vanilla one-hot \ac{pe}~\citep{nichani2024transformers} or ALiBi~\citep{wang2024transformers} and its variants~\citep{chen2024unveiling,ekbote2025one}."
- Attention logit: The unnormalized pre-softmax score computed from (rotated) queries and keys that determines attention strengths. "the pre-softmax {attention logit} from position attending to position admits a Fourier-like decomposition."
- Attention-only transformer: A transformer variant that uses only attention (without feed-forward layers) to process sequences. "a shallow attention-only transformer equipped with \ac{rope}, which is trained on \ac{icl} regression tasks."
- Causal mask operator: A masking function enforcing autoregressive attention by preventing tokens from attending to future positions. "Here, is a causal mask operator such that for any matrix , (A)_{i,j}A_{i,j}i \geq j-\infty$ otherwise."</li> <li><strong>Causal Self-Attention (CSA)</strong>: The autoregressive self-attention mechanism used in decoder-only transformers. "A key component of each transformer block is the Causal Self-Attention (CSA) mechanism."</li> <li><strong>Decoder-only transformer</strong>: A transformer architecture that generates outputs autoregressively using only a stack of decoder blocks (no encoder). "We consider decoder-only transformer models, which are composed of three main parts:"</li> <li><strong>Fourier-like decomposition</strong>: Expressing attention logits as a sum of sinusoids determined by RoPE frequencies. "the pre-softmax {attention logit} from position $ij$ admits a Fourier-like decomposition."</li> <li><strong>In-context Learning (ICL)</strong>: The ability of a model to learn behaviors from examples in the prompt without updating parameters. "they enable \ac{icl} via the induction head circuit"</li> <li><strong>Induction head circuit</strong>: A two-head mechanism (forwarding and feature-matching) that copies and matches features to enable ICL. "First introduced by \citet{elhage2021mathematical,olsson2022context}, induction head circuit is a specialized cascade of attention heads in transformer models that play a central role in in-context learning."</li> <li>LLM: A high-parameter transformer-based model trained on large corpora, capable of general-purpose text generation and reasoning. "LLMs often exhibit slash attention patterns, where attention scores concentrate along the $\Delta\Delta$."</li> <li><strong>Out-Of-Distribution (OOD)</strong>: Inputs sampled from a distribution different from the model’s training or in-distribution data. "SDHs are intrinsic to models and generalize to out-of-distribution prompts."</li> <li><strong>Position Embedding (PE)</strong>: A method to encode token positions so attention mechanisms can utilize order information. "became the default PE in many LLMs~\citep{yang2025qwen25,yang2024context,team2024gemma,grattafiori2024llama}."</li> <li><strong>p-RoPE</strong>: A modified variant of RoPE designed to improve performance by adjusting positional rotations. "and further proposed a modified variant (p-RoPE) that improves performance."</li> <li><strong>Rotary Position Embedding (RoPE)</strong>: A positional encoding scheme that rotates query and key components by position-dependent angles to induce relative positional sensitivity. "Proposed by \citet{su2024roformer}, \ac{rope} introduced multiplicative ``rotations'' on queries and keys so attention implicitly depends on relative positions, and became the default PE in many LLMs~\citep{yang2025qwen25,yang2024context,team2024gemma,grattafiori2024llama}."</li> <li><strong>Slash pattern</strong>: An attention structure where scores concentrate along a fixed sub-diagonal (lag) of the attention matrix. "the slash pattern, where the attention score concentrates along the $\Delta\Delta \in \mathbb{N}$, is particularly intriguing."</li> <li><strong>Slash-Dominant Head (SDH)</strong>: An attention head whose scores concentrate on a specific sub-diagonal (lag Δ), forming a “slash” pattern. "We refer to attention heads exhibiting slash patterns as \acp{sdh}."</li> <li><strong>Slash-dominance frequency condition</strong>: A quantitative requirement on RoPE frequencies that ensures constructive interactions at a desired lag, yielding slash patterns. "We propose a slash-dominance frequency condition that quantitatively characterizes the frequency interactions and show that the condition is satisfied by pretrained \acp{LLM}."</li> <li><strong>Softmax operator</strong>: The normalization function that converts logits into probabilities by exponentiation and normalization. "Moreover, $\mathrm{softmax}(\cdot)$ is the softmax operator, which is applied in a row-wise manner."
Practical Applications
Immediate Applications
Below are concrete ways the paper’s findings can be used today, along with sectors, potential tools/workflows, and feasibility notes.
- SDH-aware sparse long-context inference
- Sectors: software/systems, cloud, enterprise AI platforms
- Tools/workflows: attention kernels that prioritize sub-diagonals; mask-and-skip non-slash regions; SDH-guided block-sparse/flash attention variants; caching/value reuse at dominant offsets Δ
- Why it works: SDHs are intrinsic and OOD-stable; attention mass concentrates along a few sub-diagonals
- Assumptions/dependencies: model uses RoPE; access to per-head attention or offline SDH profiling; potential head/task variability across layers
- Head pruning and compression guided by SDHs
- Sectors: software, on-device AI, model compression
- Tools/workflows: identify non-SDH heads; prune/quantize them more aggressively; distill SDH behavior to smaller students
- Why it works: many heads contribute little to dominant slash patterns; Q/K are near rank-one on SDH heads
- Assumptions/dependencies: requires accuracy audits per task; pruning may need brief finetuning to recover quality
- Parameter-efficient finetuning targeting Q/K low-rank structure
- Sectors: MLOps, applied ML
- Tools/workflows: rank-1 (or very low-rank) LoRA on Q/K; adapters that selectively change amplitudes of frequency components that drive SDHs; small Δ-specific adapters
- Why it works: pre-RoPE Q/K are almost rank-one; amplitudes determine which RoPE frequencies dominate
- Assumptions/dependencies: intended tasks should benefit from preserved/adjusted SDH behavior; verify no semantic loss
- Frequency-aware RoPE tuning for context extension
- Sectors: software, long-context applications
- Tools/workflows: choose/interpolate RoPE frequencies (e.g., base scaling, YaRN/LongRoPE-like methods) to preserve medium/high-frequency components that sustain SDHs; regression tests using SDH metrics after extension
- Why it works: SDHs arise from constructive interference of RoPE’s medium/high frequencies
- Assumptions/dependencies: frequency retuning can shift behavior; must revalidate downstream tasks
- RAG and context layout optimization using SDH offsets
- Sectors: software (search/RAG), healthcare, finance, legal, education
- Tools/workflows: place key evidence/examples at distances aligned with dominant Δ for target heads; insert separators/sentinels to adjust relative positions; “Δ-aware” chunk ordering policies
- Why it works: tokens at distance i−j=Δ receive higher attention; improves retrieval effectiveness and in-context learning
- Assumptions/dependencies: need per-model/head Δ profiling; document structure may constrain reordering; benefits vary by task
- Robustness diagnostics via OOD probing
- Sectors: academia, policy/safety, enterprise QA
- Tools/workflows: random-token (uniform) probe to confirm SDH stability; dashboards that track average slash score per head across distributions; regressions during finetuning
- Why it works: SDHs are OOD-generalizable; deviations can indicate regressions or distributional brittleness
- Assumptions/dependencies: attention access/logging; cost of periodic probes during training/serving
- Prompt and template engineering leveraging Δ=1/2 heads
- Sectors: developer tooling, education, coding assistants
- Tools/workflows: few-shot templates that keep exemplar→query adjacency to exploit Δ=1 (induction) and small Δ heads; structured delimiters to preserve effective relative positions
- Why it works: forwarding/feature-matching emerge as SDHs; adjacency boosts correct copying/matching
- Assumptions/dependencies: tokenization and formatting must preserve intended lags; model uses RoPE-based positional encoding
- Training and finetuning monitors for SDH emergence
- Sectors: MLOps, research
- Tools/workflows: during training, track average slash scores per head and Δ; early-stopping/learning-rate schedules conditioned on SDH formation; head-wise health checks
- Why it works: theory shows SDHs emerge under gradient descent with identifiable conditions; practical signal for progress
- Assumptions/dependencies: compute cost for monitoring; shallow-theory-to-deep-model extrapolation is empirical
- Safety and privacy controls to mitigate unintended copying
- Sectors: policy/safety, legal, healthcare, finance
- Tools/workflows: detect heads with high slash scores in data-sensitive contexts and attenuate/reweight them; use SDH-aware red teaming to test copying risks
- Why it works: SDHs facilitate positional copying; awareness enables targeted mitigation
- Assumptions/dependencies: careful balance to avoid harming task performance; requires per-application policy definitions
Long-Term Applications
These applications likely need further research, scaling, or ecosystem maturation before broad deployment.
- SDH-optimized transformer architectures and kernels
- Sectors: hardware/software co-design, cloud providers
- Tools/products: native banded/slash attention primitives; compile-time head scheduling; memory hierarchies that cache Δ neighborhoods
- Dependencies: standardized SDH profiling; widespread RoPE-like usage; kernel/hardware support
- Learned positional embeddings with controllable SDH behavior
- Sectors: research, model providers
- Tools/products: RoPE variants or frequency schedulers that enforce desired Δ patterns per layer/task; p-RoPE-like designs tuned by SDH metrics
- Dependencies: training from scratch or extensive finetuning; evaluation of trade-offs between controllability and general performance
- Data curricula to shape algorithmic circuits via SDHs
- Sectors: education tech, coding assistants, program synthesis
- Workflows: staged training that elicits specific Δ (e.g., Δ=1 for induction, larger Δ for long-range copying/matching)
- Dependencies: large-scale training; careful curriculum design to avoid overfitting to positional heuristics
- Extreme context scaling (e.g., 1M tokens) while preserving SDH stability
- Sectors: enterprise document analytics, legal/finance compliance, scientific literature assistants
- Tools/products: frequency-design frameworks that maintain constructive interference at large lags; SDH-aware context-extension recipes
- Dependencies: stability of optimization at scale; new evals that include SDH-preservation criteria
- Cross-modal extensions of SDH principles
- Sectors: healthcare (ECG, EEG), energy (load forecasting), finance (time-series), robotics (trajectory planning), speech/audio
- Tools/products: RoPE-like encodings and frequency control for lag-specific attention in temporal/modal signals; Δ-aware forecasting/planning heads
- Dependencies: modality-specific architectures; validation on domain datasets; careful handling of causality in streaming
- Governance standards and audits centered on architecture-intrinsic behaviors
- Sectors: policy/regulation, certification bodies
- Tools/workflows: SDH metrics as part of transparency and robustness reporting; OOD probing protocols for certification
- Dependencies: consensus on metrics; access to model internals or standardized probing interfaces
- Model watermarking/fingerprinting via SDH signatures
- Sectors: security, IP protection
- Tools/products: embed characteristic SDH frequency/Δ profiles as model fingerprints; detection tools for provenance
- Dependencies: robustness against finetuning and distillation; risk of spoofing/adversarial manipulation
- External memory controllers aligned to SDH dynamics
- Sectors: software systems, robotics, agent frameworks
- Tools/products: Δ-addressed memory buffers where controller reads/writes align with dominant slash offsets; scheduling policies that synchronize memory hops with SDH heads
- Dependencies: reliable per-task Δ estimation; interface between transformer layers and memory modules
Common assumptions and dependencies across applications
- RoPE positional encoding: Findings hinge on RoPE; models using ALiBi or absolute PEs may not exhibit the same SDH dynamics.
- Near rank-one Q/K on SDH heads: Empirically observed in Gemma-7B, Qwen2.5-7B-Instruct, Llama3-8B-Instruct; not guaranteed for all models/layers.
- Frequency sensitivity: Medium/high-frequency components drive SDHs; context-extension or RoPE reparameterization can alter behavior.
- Theory-to-practice gap: Proofs use a shallow attention-only setting; transfer to deep multi-block LLMs is supported empirically but not guaranteed.
- Observability: Many workflows require access to attention patterns or head-wise hooks; closed APIs may limit deployment.
- Safety-critical domains: Improvements in efficiency/robustness do not substitute for domain validation, compliance, and monitoring.
Collections
Sign up for free to add this paper to one or more collections.