Your Group-Relative Advantage Is Biased
Abstract: Reinforcement Learning from Verifier Rewards (RLVR) has emerged as a widely used approach for post-training LLMs on reasoning tasks, with group-based methods such as GRPO and its variants gaining broad adoption. These methods rely on group-relative advantage estimation to avoid learned critics, yet its theoretical properties remain poorly understood. In this work, we uncover a fundamental issue of group-based RL: the group-relative advantage estimator is inherently biased relative to the true (expected) advantage. We provide the first theoretical analysis showing that it systematically underestimates advantages for hard prompts and overestimates them for easy prompts, leading to imbalanced exploration and exploitation. To address this issue, we propose History-Aware Adaptive Difficulty Weighting (HA-DW), an adaptive reweighting scheme that adjusts advantage estimates based on an evolving difficulty anchor and training dynamics. Both theoretical analysis and experiments on five mathematical reasoning benchmarks demonstrate that HA-DW consistently improves performance when integrated into GRPO and its variants. Our results suggest that correcting biased advantage estimation is critical for robust and efficient RLVR training.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper studies how LLMs are trained to reason better using a method called Reinforcement Learning from Verifier Rewards (RLVR). In RLVR, a model answers a question, and an automatic checker (a “verifier”) says pass or fail. A popular family of training methods—like GRPO—compares answers inside a small group for each question and updates the model based on “who did better than the group average.”
The authors discover a core problem: this group-based comparison creates a built-in bias. It makes the model learn too little from hard questions and too much from easy questions. They also offer a fix called HA-DW (History-Aware Adaptive Difficulty Weighting) that reduces this bias and improves results on math reasoning benchmarks.
The paper’s key questions
- Is the common “group-relative advantage” (who did better than the group average) an unbiased and fair way to guide learning?
- If it is biased, how exactly does the bias behave for easy versus hard questions?
- Can we correct this bias so the model explores hard problems more and doesn’t over-focus on easy ones?
- Does the correction actually help real models on real benchmarks?
How the researchers approached the problem
To make the ideas intuitive, think of a classroom quiz:
- For each question, the teacher has the class submit a few answers (say 8).
- The “advantage” of a student’s answer is how much better it did than the class average for that question.
- The teacher uses this advantage to decide how to reward or correct the student.
Here’s what the paper analyzes and proposes:
1) What is “group-relative advantage”?
- For each question (prompt), the model produces a small group of answers (often 8).
- Each answer gets a simple reward: 1 if correct, 0 if wrong.
- The “advantage” of an answer = its reward minus the group’s average reward on that same question. If you did better than the group average, your advantage is positive; worse than average, negative.
This avoids training a separate “critic” model, which is why group-based methods are popular and simple.
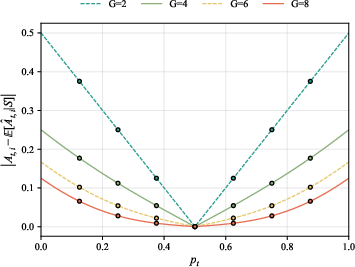
2) Why is it biased? (The main discovery)
- Hard questions: Most answers are wrong. If you manage to get it right, you look only a little better than the group average, because the average is already low but not low enough. Your true value is under-counted.
- Easy questions: Most answers are right. If you get it right, you can look extra good compared to the average, even if it wasn’t that special. Your value is over-counted.
- In short: the estimator underestimates advantage on hard questions and overestimates on easy questions.
- The bias is worst when:
- The question is extremely hard or extremely easy.
- The group size (number of answers per question) is small, which is common because generating many answers is expensive.
The authors back this up with math proofs and probability results. They show the estimator would only be unbiased if the model had a 50% chance of being correct on a question—something that rarely holds across a whole dataset.
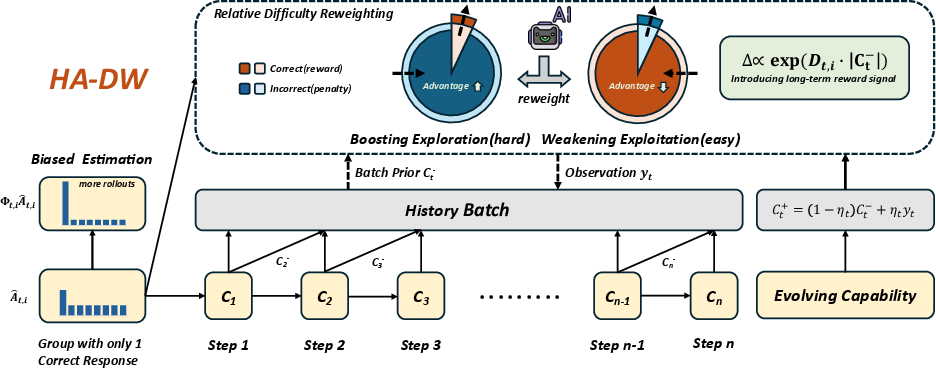
3) The fix: HA-DW (History-Aware Adaptive Difficulty Weighting)
HA-DW has two parts:
- An evolving “difficulty anchor” that tracks the model’s overall skill over time:
- Think of it as a running belief about how capable the model currently is (like a moving average of past performance). It updates a little faster when the model’s performance is changing quickly, and slower when things are stable. This helps separate “What’s hard for the model right now?” from random noise.
- Adaptive reweighting of advantages based on difficulty:
- For each new question, compare the question’s current group success rate to the anchor (the model’s current ability).
- If the question looks harder than the model’s ability, boost the advantage (so the model learns more from rare wins on hard problems).
- If the question looks easier than the model’s ability, shrink the advantage (so the model doesn’t over-exploit easy wins).
- This directly counters the bias found in group-relative advantage.
The authors also provide theory showing that, with reasonable settings, HA-DW moves the estimated advantage closer to the true advantage on average.
Main findings and why they matter
Here are the main takeaways, stated simply:
- The common group-based training signal is biased:
- It under-rewards successes on hard questions.
- It over-rewards successes on easy questions.
- The bias is strong when you use only a few answers per question (like 8), which most systems do to save compute.
- The proposed fix (HA-DW) reliably helps:
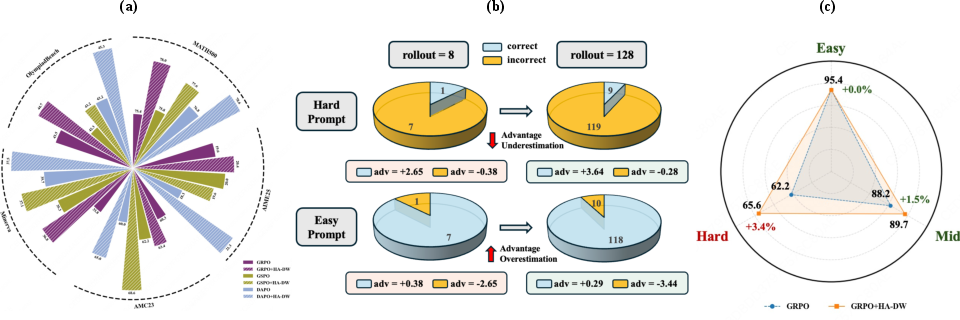
- It improved results across five math reasoning benchmarks (MATH500, AIME25, AMC23, Minerva, OlympiadBench) on several models (Qwen3-4B, Qwen3-8B, LLaMA-3.2-3B).
- It especially helped on harder questions, where better exploration matters most.
- Even compared to running the old method with more answers per question, HA-DW with the same small group often did better—so it’s both effective and efficient.
- Training behavior looked healthier:
- Models trained with HA-DW earned higher rewards over time and produced longer, more thoughtful reasoning chains, which often correlates with better problem solving.
What this could change going forward
- Better reasoning with the same compute: Since HA-DW is a “plug-in” that works with popular methods like GRPO, it can make training smarter without requiring much extra cost.
- Fairer learning across difficulties: Correcting the bias means models won’t ignore hard problems (which are often the most educational) or get stuck chasing easy wins.
- More stable, generalizable training: By balancing exploration (learn from hard tasks) and exploitation (use what you already do well), HA-DW can lead to models that perform better not just on training-like questions, but also on new, challenging ones.
- Broader lesson: When we compare results within small groups, we must watch out for hidden biases. Even simple statistical choices (like using the group average as a baseline) can tilt learning in unintended ways. Fixing these can unlock meaningful gains.
In short, the paper shows that a widely used training trick has a hidden bias and provides a simple, theory-backed way to fix it—leading to stronger reasoning performance in practice.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research:
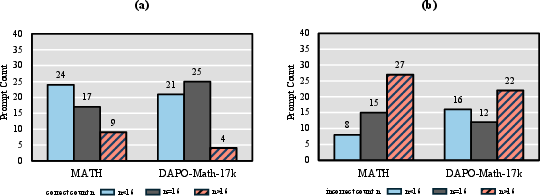
- Quantify the impact of discarding degenerate groups (R=0 or R=G) on learning dynamics, sample efficiency, and bias, and develop methods to learn from these groups rather than ignoring them.
- Analyze the unconditional bias of group-relative advantage (without conditioning on the non-degenerate event) and compare it to the conditional bias results reported here.
- Provide closed-form expressions or tight bounds for the expected magnitude of advantage bias as a function of group size G and success probability p, not just probability-of-error bounds.
- Characterize how the bias behaves under realistic, non-uniform distributions of prompt difficulty p (e.g., skewed or heavy-tailed), rather than assuming p is uniform.
- Extend and rigorously validate the theoretical results beyond Bernoulli rewards to widely used non-binary, shaped, or multi-signal verifiers (e.g., partial credit, step-level scoring), with proofs in the main text and stronger empirical coverage.
- Study the effect of noisy or imperfect verifiers on the bias (e.g., false positives/negatives in programmatic checking) and propose robust corrections when verifier noise is present.
- Analyze dependence between rollouts (e.g., due to shared nucleus sampling settings, caching, or decoding heuristics) and its effect on bias and variance of the group baseline estimator.
- Investigate how group-relative bias interacts with on-policy distribution shift across updates (changing p within training), including quantifying bias accumulation across steps.
- Provide a principled, data-driven procedure to set or adapt the HA-DW scaling parameter λ_scale to satisfy the theoretical conditions (currently dependent on unknown quantities like c_low/c_high), including online tuning or guarantees.
- Analyze gradient variance and stability under HA-DW’s exponential reweighting (risk of exploding/vanishing weights) and propose safe clipping or normalization strategies with theoretical guarantees.
- Examine the interaction of HA-DW with PPO/GRPO-style clipping, KL penalties, and trust-region constraints to ensure monotonic improvement or bounded policy divergence.
- Compare HA-DW against learned-critic baselines (value functions, advantage critics) and alternative bias-reduction strategies (e.g., shrinkage estimators, control variates, doubly robust estimators) in both theory and practice.
- Explore per-prompt or per-skill difficulty tracking (beyond a single global capability belief C_t), including skill-level anchors, curriculum schedules, or cluster-wise anchors.
- Model the belief update for C_t with explicit uncertainty (e.g., Bayesian or Kalman models with identifiable noise parameters) rather than a heuristic “Kalman-style” update; quantify how η_t and window size m affect bias correction and stability.
- Correct for selection bias in the belief update C_t when the prompt distribution or sampling strategy shifts over time (e.g., prioritized sampling of “hard” prompts).
- Evaluate HA-DW on broader RLVR tasks beyond mathematical reasoning (e.g., code generation, tool use, safety alignment, long-form QA) to test generality and robustness.
- Test scalability on larger model sizes (>8B), MoE models, and distributed training regimes to assess stability, throughput, and wall-clock/sample efficiency trade-offs.
- Systematically study the compute-performance trade-off between increasing G versus applying HA-DW, including token budget implications from longer responses induced by HA-DW.
- Investigate potential side effects such as over-emphasizing very hard prompts (e.g., reward hacking, excessively long chains-of-thought, or reduced performance on easy prompts) and propose balancing mechanisms.
- Provide comprehensive ablations on hyperparameters (η, m, λ_scale, difficulty anchor variants), and release tuning heuristics or default schedules with sensitivity analyses.
- Examine how HA-DW interacts with decoupled clipping (DAPO), sequence-level ratios (GSPO), and other GRPO variants at the objective level, including conditions where reweighting may hinder their intended stability benefits.
- Develop methods that reduce the need for discarding groups by introducing cross-prompt or historical baselines when within-group variance is zero (all-correct/all-wrong cases).
- Extend analysis to off-policy or replay-based RLVR (e.g., retrospective replay, offline buffers) where group-relative baselines are computed from non-current policies, and quantify the induced bias.
- Analyze the asymptotic behavior as G grows large (with and without conditioning on non-degeneracy), including rates at which bias vanishes and practical thresholds where bias becomes negligible.
- Evaluate out-of-distribution generalization (new domains/difficulties) and how HA-DW’s history-aware anchor adapts under domain shifts, including failure modes and recovery strategies.
- Improve reproducibility: detail verifier implementations, release code for HA-DW and experimental configs, and report broader training diagnostics (e.g., gradient norms, KL, variance of advantages) to facilitate independent validation.
Practical Applications
The paper identifies a systematic bias in group-relative advantage estimation used by popular RLVR methods (e.g., GRPO/variants) and proposes History-Aware Adaptive Difficulty Weighting (HA-DW) to correct it. Below are practical applications that follow from the theory, method, and empirical results.
Immediate Applications
- LLM post-training pipelines for reasoning (industry, academia; sectors: software, education)
- Use case: Integrate HA-DW into existing group-relative RLVR training (GRPO, GSPO, DAPO) to improve stability and accuracy on math/formal reasoning with the same or fewer rollouts.
- Tools/workflows: Plug-in module for VeRL, TRL, OpenRLHF; add the evolving difficulty anchor C_t, per-prompt pass-rate baseline ˆp_t, and reweight advantages via Φ = λ_scale·exp(D·M); log difficulty-stratified metrics.
- Assumptions/dependencies: Verifier reward available (binary preferred, bounded rewards supported); group-based on-policy rollouts (G typically 2–8); hyperparameter tuning for η, m, λ_scale; reward non-stationarity monitored.
- Compute-efficient training under tight budgets (industry, academia; sectors: AI platform, cloud/edge)
- Use case: Replace “more rollouts” (e.g., G=16) with HA-DW at smaller G (e.g., 8) to reach equal or better performance.
- Tools/workflows: Rollout scheduler switches to HA-DW at small G; training dashboards show accuracy vs compute.
- Assumptions/dependencies: Same verifier pipeline; careful calibration of λ_scale to avoid overcompensation.
- Code generation with unit-test verifiers (industry; sector: software engineering/DevOps)
- Use case: Train/code-tune LLMs with pass/fail unit tests; HA-DW upweights hard failing cases and downweights trivial passes to improve generalization and reduce flaky overfitting.
- Tools/workflows: CI-integrated verifier harness (pytest, coverage); “HardCase Booster” training step that computes per-batch C_t and reweights advantages per test suite.
- Assumptions/dependencies: Reliable test oracle; representative test coverage; stable batching by repository/domain.
- Math tutors and EdTech assistants (industry, academia; sector: education)
- Use case: Fine-tune small/medium LLMs for step-by-step solutions; HA-DW improves hard problem performance and encourages longer, more complete chains-of-thought.
- Tools/workflows: Dataset sampler with difficulty-aware logging; evaluation stratified by problem levels (e.g., AIME, MATH500 tiers).
- Assumptions/dependencies: Verifier or solution checker (pass/fail) available; guardrails for content quality.
- Difficulty-aware evaluation and monitoring (industry, academia; cross-sector)
- Use case: Add difficulty-stratified reporting to training/eval to detect “easy-prompt exploitation” and under-learning on hard prompts.
- Tools/workflows: Dashboard tracking C_t, σ_t, ˆp_t histograms, and advantage bias gaps; alerts when bias or σ_t drift spikes.
- Assumptions/dependencies: Difficulty anchor calibrated; held-out difficulty labels or proxy estimators.
- Data curriculum and sampler reweighting (industry, academia; cross-sector)
- Use case: Use C_t and ˆp_t to reweight or resample prompts so harder items are surfaced more during RLVR, complementing advantage reweighting.
- Tools/workflows: Dataloader with difficulty-aware sampling weights; periodic rebalance by anchor drift.
- Assumptions/dependencies: Reasonable stationarity per data bucket; prevention of catastrophic forgetting of easy prompts.
- Open-source framework extensions (community; cross-sector)
- Use case: A PR/plugin adding HA-DW and difficulty dashboards to widely used RLHF/RLVR repos.
- Tools/workflows: Reference implementation in VeRL/TRL; config flags for η, m, λ_scale; tests with small G.
- Assumptions/dependencies: Community datasets with verifiers; reproducible seeds and logging standards.
- Internal governance for training fairness across difficulty (policy inside orgs; cross-sector)
- Use case: Training policies that mandate difficulty-stratified metrics and bias mitigation (e.g., HA-DW) to avoid misleading headline gains from easy prompts.
- Tools/workflows: SOPs and checklists; periodic audits of group size G, degenerate groups (R∈{0,G}), and bias indicators.
- Assumptions/dependencies: Organizational buy-in; consistent data taxonomy for difficulty.
Long-Term Applications
- Generalization beyond binary verifiers and to learned reward models (industry, academia; sectors: software, robotics, agents)
- Use case: Apply bias-aware correction when rewards are continuous, sparse, or learned (RMs); extend theory and practice to these settings.
- Tools/workflows: Calibrated reward bounds; critic-augmented variants using HA-DW as a prior.
- Assumptions/dependencies: Reliable reward calibration; robust critic training.
- Adaptive rollout allocation per prompt (industry, academia; cross-sector)
- Use case: Use the difficulty anchor to dynamically choose group size G (more rollouts for hard prompts) while correcting bias with HA-DW.
- Tools/workflows: Scheduler optimizing (G, Φ) jointly under compute budgets; bandit-style allocation across difficulty bins.
- Assumptions/dependencies: Real-time cost/latency constraints; stability safeguards for non-stationary C_t.
- Safer deployment in high-stakes domains (industry, regulators; sectors: healthcare, finance, legal)
- Use case: With strong, audited verifiers (clinical checklists, compliance rules), use HA-DW to reduce overconfidence on easy cases and improve coverage on hard, rare scenarios.
- Tools/workflows: Risk-tiered training with gated promotion; post-hoc calibration and human-in-the-loop review; stratified stress tests by difficulty.
- Assumptions/dependencies: Verified, validated reward oracles; domain approvals; rigorous monitoring to prevent reward hacking.
- Multimodal and embodied reasoning (industry, academia; sectors: robotics, autonomy, geospatial)
- Use case: Train language-planning policies with success/failure verifiers (simulation or hardware) using bias-corrected advantages to improve exploration on challenging tasks.
- Tools/workflows: Simulator-in-the-loop verifiers; curriculum transfer from sim to real with difficulty tracking; safety shields.
- Assumptions/dependencies: Sim2real gap management; reliable pass/fail metrics; cost of rollouts.
- Standards and disclosures for RLVR training (policy; cross-sector)
- Use case: Require reporting of group size G, degenerate-group handling, difficulty-stratified results, and any bias mitigation (e.g., HA-DW) in research and product model cards.
- Tools/workflows: Template reporting schemas; third-party auditing.
- Assumptions/dependencies: Community consensus; alignment with existing model governance frameworks.
- Training observability and MLOps products (industry; sector: AI tooling)
- Use case: Commercial monitoring that surfaces difficulty dynamics (C_t, σ_t, ˆp_t), estimator-bias indicators, and recommended λ_scale adjustments.
- Tools/workflows: SDKs that instrument RLVR loops; autosuggestions for reweighting and sampler policies.
- Assumptions/dependencies: Access to training telemetry; privacy/compliance constraints.
- New algorithmic families for bias-aware policy optimization (academia; cross-sector)
- Use case: Design estimators that fuse per-prompt baselines, cross-batch priors, and critics; off-policy corrections that account for group-relative bias.
- Tools/workflows: Doubly-robust extensions for RLVR; theoretical bounds linking bias to generalization.
- Assumptions/dependencies: Stronger theory under non-i.i.d. batches; scalable implementations.
- Fairness across task difficulty and population subgroups (academia, policy; cross-sector)
- Use case: Study and mitigate interactions between difficulty bias and data subpopulations (e.g., curriculum artifacts); ensure equitable gains on “hard” cases relevant to underserved users.
- Tools/workflows: Joint stratification by difficulty and subgroup; counterfactual data augmentation.
- Assumptions/dependencies: Availability of ethical annotations; careful governance of subgroup definitions.
Notes on feasibility and dependencies shared across applications:
- HA-DW relies on verifiable rewards (ideally binary pass/fail), small group sizes (common in practice), and stable logging to maintain the evolving capability anchor C_t.
- Hyperparameters η, m, λ_scale materially affect performance; auto-tuning or conservative defaults may be needed to avoid over/under-correction.
- Concept drift can miscalibrate C_t; the dynamic forgetting factor (η_t = η·σ_t) should be validated, and alarms added when σ_t or anchor drift spikes.
- For safety-critical applications, additional verification, human oversight, and domain-specific evaluation standards are prerequisites before deployment.
Glossary
- Behavior (reference) policy: The policy that generated the data and serves as the fixed reference during optimization. "where π{θ{old} denotes the reference (behavior) policy."
- Bernoulli random variable: A binary-valued random variable used to model pass/fail rewards per response. "it is natural to model the reward associated with each response as a Bernoulli random variable:"
- DAPO: A GRPO-family variant designed to stabilize training with decoupled clipping and dynamic sampling. "Common variants include GSPO \citep{DBLP:journals/corr/abs-2507-18071}, DAPO \citep{DBLP:journals/corr/abs-2503-14476}, Dr.GRPO \citep{DBLP:journals/corr/abs-2503-20783} and GMPO \citep{DBLP:journals/corr/abs-2507-20673}."
- Degenerate groups: Sample groups with all-zero or all-one rewards that yield zero advantages and no updates. "such degenerate groups do not contribute to learning and are either explicitly discarded or implicitly ignored by GRPO-style algorithms."
- Dr.GRPO: A GRPO variant that removes heuristic normalizations to produce more stable, less biased updates. "Dr.GRPO removes heuristic normalizations to obtain more stable, less biased updates."
- Empirical group baseline: The average reward within a sampled group used as a baseline for advantage computation. "The empirical group baseline is given by ."
- Evolving difficulty anchor: A history-aware reference of model capability used to adaptively adjust advantages. "an evolving difficulty anchor incorporates cross-batch historical information by propagating the model’s prior through a history buffer"
- Expected advantage: The difference between a rollout’s reward and the true expected reward for a prompt under the current policy. "The expected advantage is defined as:"
- Exploration–exploitation balance: The trade-off between trying harder prompts and leveraging easier ones during learning. "enables a more principled balance between exploration and exploitation in RL training."
- Forgetting factor: A coefficient that controls how strongly new observations update the capability belief versus historical information. "The forgetting factor controls the influence of historical information"
- GMPO: A GRPO-family variant proposed to improve stability and performance. "Common variants include GSPO \citep{...}, DAPO \citep{...}, Dr.GRPO \citep{...} and GMPO \citep{...}."
- GRPO: Group Relative Policy Optimization; a widely adopted RL algorithm that uses group baselines instead of learned critics. "GRPO \citep{DBLP:journals/corr/abs-2402-03300} has gained increasing popularity after PPO"
- Group-PO objective: The formal objective for group-relative policy optimization using importance ratios and advantage terms. "The group-relative policy optimization (Group-PO) objective is defined as:"
- Group-relative advantage estimator: The estimator that subtracts the group’s average reward from each rollout’s reward to compute advantage. "the group-relative advantage estimator is inherently biased relative to the true (expected) advantage."
- GSPO: A GRPO variant that uses sequence-level ratios and clipping for stability and efficiency. "Common variants include GSPO \citep{DBLP:journals/corr/abs-2507-18071}, DAPO \citep{...}, Dr.GRPO \citep{...} and GMPO \citep{...}."
- HA-DW (History-Aware Adaptive Difficulty Weighting): An adaptive reweighting scheme that corrects biased group-relative advantages using a history-aware difficulty anchor. "we propose History-Aware Adaptive Difficulty Weighting (HA-DW)"
- History-based prompt difficulty: The difficulty measure derived from the difference between the empirical reward and the evolving capability belief. "we define the history-based prompt difficulty as:"
- Importance sampling ratio: The ratio between current and reference policy probabilities used to reweight updates. "Here, denotes a function applied to the importance sampling ratio"
- Kalman-style update: A smoothing update that blends prior belief and current observation to form a posterior capability belief. "via a Kalman-style update"
- Non-degenerate event: The subset of groups with mixed rewards (neither all-zero nor all-one) that contribute nonzero gradients. "This corresponds to the non-degenerate event"
- Posterior belief: The updated capability belief after incorporating current batch observations. "The posterior belief serves as the prior belief for the next batch:"
- Prior belief: The capability belief carried into the next batch before observing new data. "The posterior belief serves as the prior belief for the next batch:"
- Rectified group baseline: A reweighted empirical baseline () designed to reduce estimation bias. "Let be the rectified group baseline."
- Reinforcement Learning from Verifier Rewards (RLVR): An RL paradigm for LLM post-training that uses automated verifier signals as rewards. "Reinforcement Learning from Verifier Rewards (RLVR) has emerged as a widely used approach for post-training LLMs on reasoning tasks"
- Rollouts: Multiple sampled responses per prompt used to estimate rewards and advantages. "the algorithm generates only a small number of rollouts"
- Scaling constant λ_scale: A multiplicative factor in HA-DW that controls the strength of advantage reweighting. "where $\lambda_{\mathrm{scale}$ is a scaling constant"
- Sequence-level ratios: Probability ratios computed over entire sequences, used by GSPO for stability and efficiency. "GSPO uses sequence-level ratios and clipping to improve stability and efficiency, especially for large and MoE models."
- Verifier outcomes: Binary pass/fail signals produced by programmatic verifiers that define rewards in RLVR. "particularly those using hard verifier outcomes"
Collections
Sign up for free to add this paper to one or more collections.