MoCha:End-to-End Video Character Replacement without Structural Guidance
Abstract: Controllable video character replacement with a user-provided identity remains a challenging problem due to the lack of paired video data. Prior works have predominantly relied on a reconstruction-based paradigm that requires per-frame segmentation masks and explicit structural guidance (e.g., skeleton, depth). This reliance, however, severely limits their generalizability in complex scenarios involving occlusions, character-object interactions, unusual poses, or challenging illumination, often leading to visual artifacts and temporal inconsistencies. In this paper, we propose MoCha, a pioneering framework that bypasses these limitations by requiring only a single arbitrary frame mask. To effectively adapt the multi-modal input condition and enhance facial identity, we introduce a condition-aware RoPE and employ an RL-based post-training stage. Furthermore, to overcome the scarcity of qualified paired-training data, we propose a comprehensive data construction pipeline. Specifically, we design three specialized datasets: a high-fidelity rendered dataset built with Unreal Engine 5 (UE5), an expression-driven dataset synthesized by current portrait animation techniques, and an augmented dataset derived from existing video-mask pairs. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches. We will release the code to facilitate further research. Please refer to our project page for more details: orange-3dv-team.github.io/MoCha





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
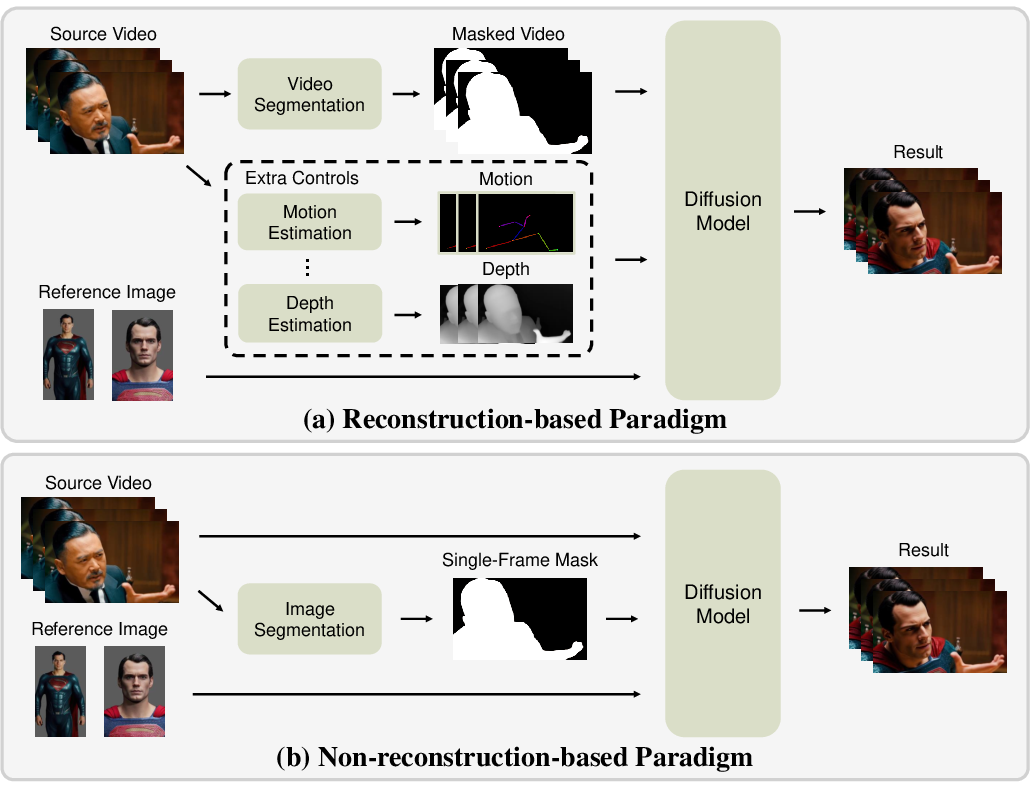
This paper introduces MoCha, a new tool that can replace a person or character in a video with another character while keeping everything else the same—like the background, camera motion, lighting, and the way the person moves and makes expressions. Unlike older methods that need lots of extra information (like a detailed cut-out of the person in every single frame, or a stick-figure skeleton of their pose), MoCha works end-to-end and only needs a single mask from one frame to show which person should be replaced.
What questions is the paper trying to answer?
- Can we swap a character in a video while keeping the original motion, expressions, background, and lighting—without using complicated extra inputs?
- Is it possible to guide a powerful video generation model using minimal hints (a single-frame mask and a few reference images) so it learns to track and replace the right person across the whole video?
- Can we make the replaced face look more like the target identity, consistently across frames?
- How can we train such a system if there aren’t many perfect “paired” videos (where the same motion is performed by two different characters) available in the real world?
How MoCha works (in everyday language)
Think of a video like a flipbook: a stack of pictures that create motion when you flip through them. MoCha takes the original flipbook and a few sample photos of the new character you want to insert. It also gets one “sticky note” (a mask on one frame) that points to which person to replace. Then it generates a new flipbook where the chosen person is swapped, but everything else—in the scene and the motion—stays consistent.
Here are the key ideas behind MoCha:
- Video diffusion modeling: This is a way computers “paint” videos by starting from random noise and gradually turning it into a realistic sequence, step by step—like carving a statue from a rough block, refining it over time.
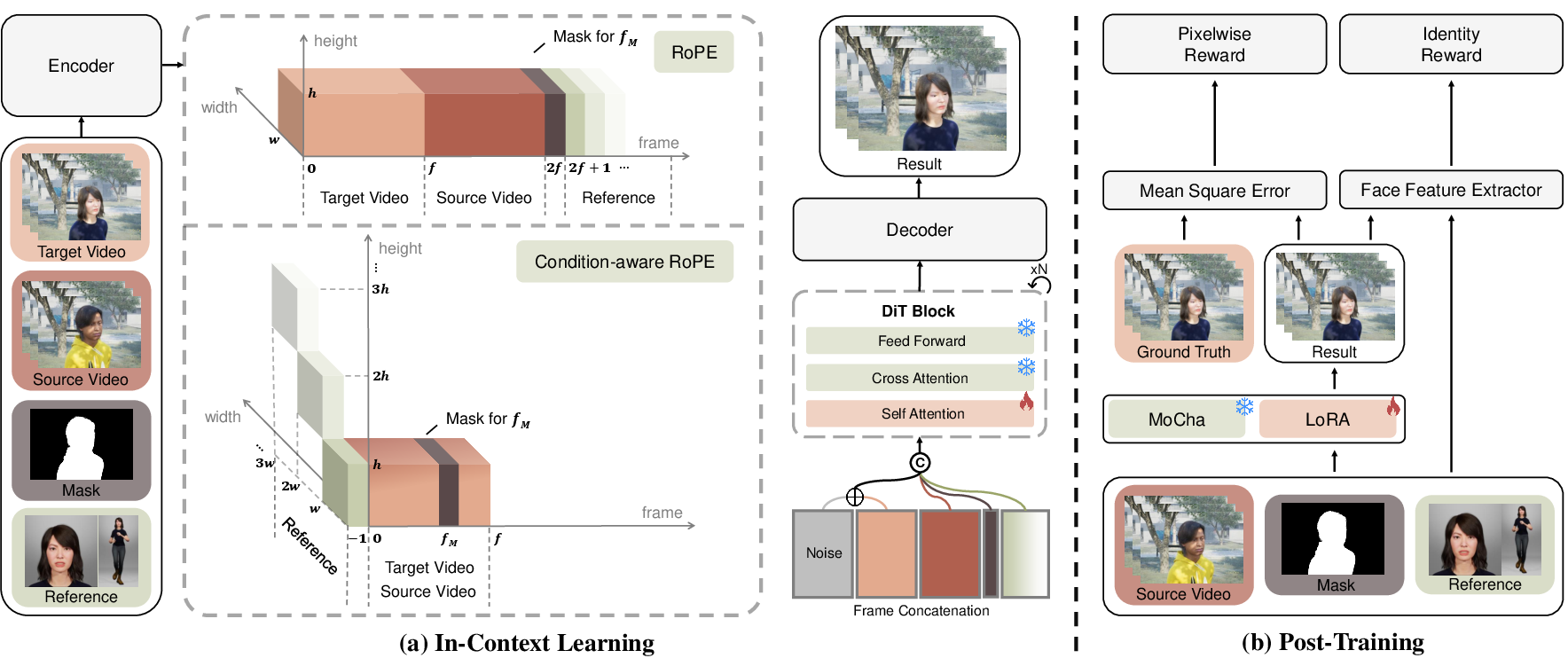
- In-context learning: Instead of giving the model strict rules, MoCha feeds it all the helpful clues at once: the source video, the single-frame mask, and reference images of the new character. By seeing these together, the model learns how to copy the motion and expressions from the source and apply them to the new identity, while keeping the background and lighting intact.
- Condition-aware RoPE (positional clues): Computers don’t naturally know “what comes first” or “which token belongs to which frame.” MoCha uses special positional tags (like time-and-place labels) to tell the model:
- These tokens belong to the source video and target video and should line up frame-by-frame.
- This token is the mask that marks the person to replace (on a specific frame).
- These tokens are reference images of the new character (they get a special “reference” label).
- This structured tagging helps the model understand how to combine all the inputs correctly.
- Identity-Enhancing post-training (reward-based fine-tuning): After the main training, MoCha gives itself a “score” for how similar the generated face is to the reference identity, using a face-recognition tool (ArcFace). It then tweaks its behavior to improve that score. To avoid “cheating” (like pasting the reference photo directly onto the video), it also checks that the overall video still looks natural and close to the ground truth, and only adjusts the later steps where fine details appear.
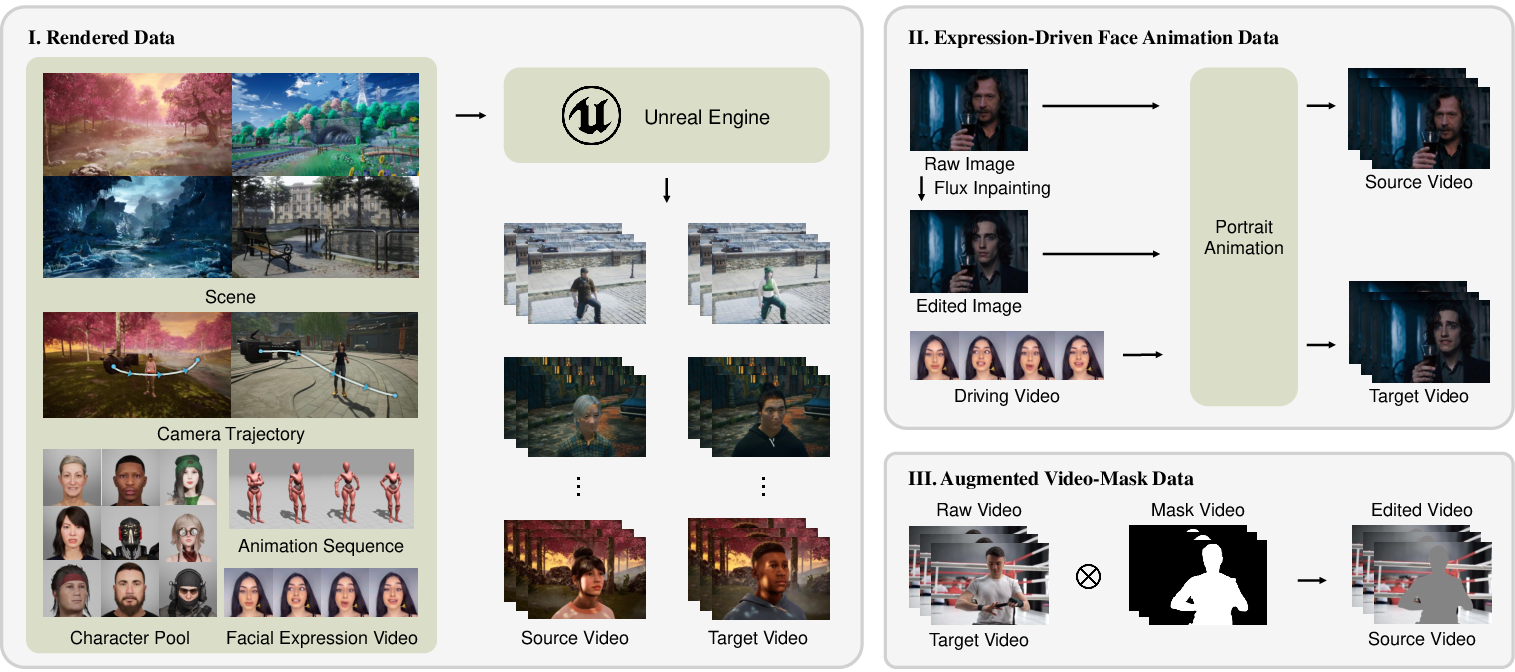
- Smart training data creation: Perfect training pairs are rare (we want two videos with exactly the same motion in the same scene, but different characters). So the authors built their own:
- High-quality rendered pairs using Unreal Engine 5: They create scenes where different characters perform the exact same motion with the same camera and lighting.
- Expression-driven pairs: They swap a face in a photo (using an inpainting model) and then animate both the original and the swapped image with the same expression video, so the motion matches but the identity differs.
- Augmented real video data: They add real videos with character masks (from public datasets) and carefully filter and improve them, so the model learns from real-world textures and lighting too.
What did they find?
- MoCha beats other state-of-the-art methods in how well it keeps the person’s identity, how smooth the motion looks over time, and how accurately expressions are reproduced.
- It maintains original lighting and background details better than methods that “reconstruct” the character region with heavy guidance.
- MoCha works even in hard cases: occlusions (when people or objects overlap), unusual poses (like acrobatics), and multi-person interactions (like hugging or fighting).
- The model can track the chosen character across the entire video with only a single-frame mask. This shows that modern video diffusion models have strong built-in “tracking” ability.
- Adding real-human data and the reward-based post-training both noticeably improve realism and face consistency.
Why this matters:
- It reduces the amount of extra input and manual work (no need for a perfect per-frame cut-out or pose skeletons).
- It makes character replacement more robust and practical for real-world editing.
What’s the potential impact?
MoCha can simplify and speed up many tasks:
- Film and TV post-production: replacing actors or avatars while preserving performance, camera work, and scene lighting.
- Personalized advertising and digital avatars: swapping in a customer’s face or a brand character while keeping natural motion.
- Virtual try-on and face swapping: editing clothes or faces in videos more realistically.
- Research: It shows that video diffusion models can do reliable tracking and identity transfer with minimal guidance, pointing to future tools that are easier to use and more flexible.
In short, MoCha shows that with smart conditioning and training, we can cleanly replace characters in videos using just a single-frame hint and a few reference photos—keeping everything else believable and consistent.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated to guide future research:
- Sensitivity to the single-frame mask: how performance degrades with imperfect masks (coarse, off-target, low IoU, wrong frame) and whether weaker inputs (points, boxes, scribbles) or automatic mask selection could suffice.
- Ambiguity with multiple similar subjects: reliability of single-frame masking to consistently track the intended target when multiple look-alike characters appear or re-enter the scene.
- Multi-target replacement: ability to replace several characters in the same video (simultaneously or sequentially), required architectural or training changes, and dataset construction for multi-subject supervision.
- Long-form and multi-shot videos: robustness across shot boundaries, hard scene cuts, large time gaps, and re-identification after occlusions or exits/entries; need for shot detection and per-shot reconditioning strategies.
- Extreme motions and viewpoints: systematic evaluation on rare poses (e.g., acrobatics), rapid motion, motion blur, extreme scale/zoom, and large viewpoint changes beyond training lengths.
- Temporal identity drift: quantitative analysis of identity consistency over long durations and under heavy occlusion; potential need for temporal identity constraints or memory mechanisms.
- Lighting preservation quantification: lack of photometric or physically grounded lighting metrics; propose evaluating estimated illumination (e.g., SH coefficients), reflectance consistency, and relighting-invariance.
- Physical plausibility without explicit structure: risks of limb/body interpenetration and contact violations in interactions; explore contact-aware losses, depth reasoning, or learned 3D priors to improve physical realism.
- Audio and lip-sync: handling speaking subjects, audio-driven mouth motion preservation, and audiovisual synchronization during replacement.
- Condition-aware RoPE ablation: missing comparisons against alternative positional schemes (learned relative positions, rotary variants, explicit temporal alignment, gating between conditions) and analysis of generalization to arbitrary lengths.
- Frame-index mapping for the mask (
f_M = (F-1)//4 + 1): rationale, sensitivity, and failure modes for long sequences; whether learned or continuous time encodings would be more robust. - Conditioning design and efficiency: full self-attention over concatenated tokens is O(T2); investigate sparse attention, cross-attention to conditions, or key-value caching to reduce memory/latency at inference.
- Reference image requirements: how many, which viewpoints/expressions, and what quality are needed; automatic selection/curation, active prompting, or retrieval strategies to cover pose/lighting diversity.
- Copy-paste avoidance beyond MSE: evaluate more principled anti-copy objectives (e.g., patch-level contrastive penalties, identity-preserving but pose-invariant constraints) to prevent literal reference imprinting.
- RL post-training side effects: thorough analysis of reward hacking, background degradation, oversharpening, and identity overfitting; ablate number of optimized steps K, reward scales, and alternative face-identity rewards.
- Reward design and normalization: the loss mixes
(1 - ArcFace similarity)and pixel MSE without reported weighting; examine scaling, normalization, and composition to stabilize optimization and trade-offs. - Identity metrics at evaluation: include explicit face-ID similarity (ArcFace/CosFace), temporal face-ID stability, and re-ID scores (e.g., IDF1) instead of relying primarily on SSIM/LPIPS/PSNR/VBench.
- Generative video quality metrics: add FVD and long-horizon temporal coherence measures; report per-attribute breakdowns (motion, identity, background consistency) to pinpoint failure modes.
- Fair quantitative comparison to closed-source systems: design reproducible human studies or controlled small-batch evaluation for tools like Kling to avoid selection bias.
- High-resolution scalability: current training/evaluation at 480×832; assess 1080p/4K via tiling, latent upscalers, or multi-scale schemes, and quantify identity/temporal trade-offs at higher resolutions.
- Runtime and resource footprint: report training/inference latency, memory, and cost; study speed–quality trade-offs, batching strategies, and deployability on commodity GPUs.
- Dataset realism and coverage: synthetic-heavy paired data and proxy “paired” real data may underrepresent real-world complexities (loose clothing, hair, accessories, crowded scenes); expand with curated, consented real paired sets and annotate difficult attributes (occlusion types, contacts).
- Demographic, stylistic, and domain bias: quantify performance across skin tones, ages, genders, body shapes, non-human/stylized subjects; analyze base-model and reward bias (e.g.,
ArcFacebias to frontal faces). - Non-human and cross-domain replacement: systematically benchmark on pets, fantasy/CG characters, and objects; identify failure patterns and required adaptations (category-specific priors or rewards).
- Robustness to heavy occlusion and interactions: controlled tests for hand-object and body-body contacts; measure physical plausibility and identity retention under complex interplays.
- Multi-reference usage policy: study how different combinations (frontal vs profile, close-up vs full-body) affect outcomes; design learned reference fusion or dynamic reference memory over time.
- Generalization to other base models: portability of
condition-aware RoPEand the training recipe to different T2V architectures (e.g., CogVideoX, HunyuanVideo) and smaller backbones. - 3D consistency under camera motion: assess view-consistent identity across significant parallax and camera moves; consider integrating monocular geometry cues or 3D-aware diffusion.
- Automatic or interactive mask acquisition: explore point/box prompts with SAM2, uncertainty-aware mask refinement, and user-in-the-loop corrections; quantify sensitivity to mask errors.
- Failure case documentation: provide a taxonomy of typical failures (mis-tracking, identity drift, lighting mismatch, limb artifacts), with diagnostics and suggested mitigations.
- Reproducibility details: specify missing hyperparameters (e.g., exact K for RL steps, reward scaling, RoPE offsets), dataset splits, seed control, and code/data licensing (film image legality).
- Safety and misuse prevention: add consent workflows, watermarking, provenance, deepfake detection compatibility, and policy controls to mitigate identity misuse in deployment scenarios.
Practical Applications
Practical Applications Derived from MoCha
Below is a structured synthesis of practical uses that stem from MoCha’s findings, methods, and innovations, organized by time-to-deploy horizon and linked to relevant sectors. Each item includes potential tools/workflows and assumptions or dependencies that affect feasibility.
Immediate Applications
- High-fidelity character replacement for post-production
- Sector: Film/TV, VFX
- What: Swap an actor or character in a shot while preserving background, lighting, motion, occlusions, and interactions using only a single-frame mask and a set of reference images.
- Tools/Workflows: NLE plugin for Premiere/DaVinci; SAM2-assisted single-frame mask capture; multi-reference library management; batch rendering; QA with SSIM/LPIPS/VBench.
- Assumptions/Dependencies: GPU access; licenses/consents for likeness usage; robust reference images; integration with studio asset pipelines.
- Identity-preserving face swap for influencer marketing and social media
- Sector: Advertising, Creator Economy
- What: Rapidly customize short-form videos with brand ambassadors or campaign-specific avatars, maintaining expression and lighting realism.
- Tools/Workflows: Mobile app/API; multi-reference image support; automated watermarking/provenance metadata.
- Assumptions/Dependencies: Explicit consent; misuse safeguards; platform policies for synthetic media disclosure; reliable ArcFace identity signal across demographics.
- Localization of video content via actor replacement
- Sector: Media localization, Entertainment
- What: Replace on-screen talent in localized versions while keeping motion and scene dynamics intact.
- Tools/Workflows: Localization Studio pipeline; per-market reference sets; single-frame mask capture; paired audio dubbing/ADR.
- Assumptions/Dependencies: Talent IP/licensing; audio-lip sync handled by separate modules; legal compliance with local deepfake laws.
- Privacy-preserving video anonymization
- Sector: Security/Privacy, Compliance
- What: Replace identifiable faces with approved synthetic avatars instead of blurring, preserving action context for training, audits, and public sharing.
- Tools/Workflows: “Privacy Masker” service; SAM2 for mask selection; identity/consent ledger; secure watermarking and audit logs.
- Assumptions/Dependencies: Organizational policy alignment; demographic bias audits for ArcFace; governance for reversibility and chain-of-custody.
- Virtual try-on in video
- Sector: Retail/Fashion, E-commerce
- What: Replace face or apparel via edited reference images (e.g., outfit swaps) to showcase products in motion under real lighting.
- Tools/Workflows: Product image editing with Flux/other image editors; MoCha inference; catalog-aware batching; conversion analytics.
- Assumptions/Dependencies: Clothing dynamics not explicitly modeled; style/fit realism depends on reference quality and scene complexity; brand approvals.
- Game machinima and mod content creation
- Sector: Gaming, UGC
- What: Swap character skins/NPC identities in recorded gameplay videos without per-frame masks.
- Tools/Workflows: “Modder’s Studio” app; single-frame mask selection; multi-reference input; batch exports.
- Assumptions/Dependencies: Game EULA/IP rights; compute availability; content disclosure for synthetic edits.
- Personalized educational and corporate training videos
- Sector: Education, Enterprise L&D
- What: Replace presenters with localized avatars or inclusive representations while preserving gestures/facial expressions.
- Tools/Workflows: Presenter Swap pipeline; TTS/voice dubbing; QA checks for motion smoothness and temporal flicker (VBench).
- Assumptions/Dependencies: Compliance with institutional policies; lip sync handled externally; stakeholder acceptance and disclosure guidelines.
- Shot continuity fixes and archival restoration
- Sector: Post-Production, Restoration
- What: Replace or adjust talent in archival or continuity-challenged footage while keeping original lighting and background intact.
- Tools/Workflows: Single-frame mask workflows; curated reference retrieval; version control and editorial review.
- Assumptions/Dependencies: Ethical review; rights clearance; model behavior on degraded footage.
- Multi-character crowd edits for event videography
- Sector: Event Production, Security
- What: Replace or remove specific individuals in multi-person scenes with occlusions/interactions handled robustly.
- Tools/Workflows: Per-subject single-frame mask; attention visualization for tracking; batch replacements with review gates.
- Assumptions/Dependencies: Scalability when many subjects are edited; operational throughput; consent and privacy requirements.
- Reproducible dataset pipelines for research and product teams
- Sector: Academia, Applied Research
- What: Adopt the UE5 rendered paired dataset, expression-driven animation (Flux + LivePortrait), and augmented video-mask pipelines to train/evaluate custom models.
- Tools/Workflows: UE5 asset orchestration; procedural camera trajectories; YOLO-based filtering; ArcFace reward-based LoRA post-training.
- Assumptions/Dependencies: Asset licensing (UE5/MetaHuman/Mixamo); reproducibility of composition scripts; balanced real/synthetic data to avoid artifacts.
Long-Term Applications
- Real-time character replacement for live broadcasts and streaming
- Sector: Media/Live Events
- What: Near-real-time swaps during live shows, sports, or concerts with broadcast-grade stability.
- Tools/Workflows: Model distillation/quantization; hardware acceleration; streaming inference servers; low-latency mask capture.
- Assumptions/Dependencies: Significant model optimization; strict latency budgets; robust tracking under motion blur and lighting changes.
- Personalized casting for on-demand entertainment
- Sector: Streaming Platforms, Interactive Storytelling
- What: Viewers choose who plays each role; platform renders personalized versions preserving scene dynamics and acting motion.
- Tools/Workflows: Likeness licensing marketplace; scalable identity libraries; per-viewer batch pipelines; usage disclosures.
- Assumptions/Dependencies: IP/rights frameworks; compute cost management; ethics and user safety policies.
- Dynamic, contextual advertising overlays in live and recorded content
- Sector: Advertising, Sports Media
- What: Replace spokespersons, apparel, or branded items contextually while maintaining lighting and motion realism.
- Tools/Workflows: Context-aware scheduling; sponsor asset libraries; broadcast integration; automated QC.
- Assumptions/Dependencies: Regulatory constraints; content provenance/watermark requirements; high reliability under occlusions.
- Licensed synthetic actors and consent-aware identity management
- Sector: Legal/Policy, Creator Economy
- What: Standardized workflows to license and insert digital likenesses with traceable provenance and disclosure.
- Tools/Workflows: Consent registries; rights/usage contracts; embedded provenance signals; detection and audit services.
- Assumptions/Dependencies: Harmonized regulations across regions; platform adoption; robust detection against misuse.
- Telepresence and AR with motion-preserving avatars
- Sector: Communications, AR/VR
- What: Replace user identity in teleconferencing or AR video with stylized avatars that follow real motion and expressions.
- Tools/Workflows: Single-mask capture at session start; device-side accelerated inference; avatar customization.
- Assumptions/Dependencies: On-device compute or edge acceleration; integration with AR frameworks; acceptable latency and battery constraints.
- Automated studio-grade post-production pipelines
- Sector: VFX/Studios
- What: End-to-end pipelines that include single-mask detection (SAM2), condition-aware RoPE orchestration, project-specific LoRA reward tuning, and automated QC.
- Tools/Workflows: MLOps for model versioning; data curation; identity reward monitoring; failure mode dashboards.
- Assumptions/Dependencies: Organizational MLOps maturity; standardized QC metrics; staff training and process integration.
- Platform-scale privacy compliance for UGC
- Sector: Social Platforms, Policy
- What: Default anonymization options (face replacement) for minors or protected identities, preserving video utility.
- Tools/Workflows: Consent-aware toggles; redaction-at-upload pipelines; provenance watermarking; audit trails.
- Assumptions/Dependencies: False positive/negative management; user transparency and opt-in/out; evolving regional regulations.
- Personalized learning content at scale
- Sector: EdTech
- What: Swap instructors with familiar local avatars across thousands of lessons, retaining gesture realism and classroom context.
- Tools/Workflows: LMS integration; avatar libraries; automated dubbing/lip-sync; student-facing disclosure UI.
- Assumptions/Dependencies: Acceptance by institutions; rigorous evaluation of cultural fairness; audio-visual syncing.
- Forensic redaction that preserves scene semantics
- Sector: Public Safety, Legal
- What: Replace identities rather than blur to maintain context for analysis while respecting privacy.
- Tools/Workflows: Evidence chain management; reversible transformations under court order; dual-provenance exports.
- Assumptions/Dependencies: Legal standards and admissibility; strict access controls; bias and accuracy audits.
- Cross-subject replacement beyond humans
- Sector: Marketing, Conservation/Education
- What: Replace non-human subjects (animals, products) in educational or promotional videos, keeping scene physics and lighting.
- Tools/Workflows: Domain-specific reference collections; non-human identity encoders; QA for motion plausibility.
- Assumptions/Dependencies: Training data coverage for non-human subjects; adaptation of identity reward signals; validation of ecological messaging accuracy.
Glossary
- ArcFace: A deep face recognition method that produces discriminative embeddings for measuring identity similarity via cosine distance. "cosine similarity between the Arcface~\cite{deng2019arcface} embeddings of the generated video and the reference images."
- Condition-aware RoPE: A customized extension of rotary positional embeddings that assigns coherent spatiotemporal indices to different input conditions (source, target, mask, references) to fuse them effectively. "we propose a condition-aware RoPE, an extension of the original 3D RoPE~\cite{rope, wan2025} mechanism."
- Conditional Flow Matching (CFM): A training objective for flow-based generative models that aligns the model’s predicted velocity with a condition-dependent target slope. "We use the Conditional Flow Matching~\cite{CFM} loss to optimize the model:"
- DiT (Diffusion Transformer): A transformer-based diffusion architecture that predicts denoising velocities or scores over latent representations. "During training, is fed to a Transformer-based diffusion model~\cite{Peebles2022DiT} (DiT)."
- Flux inpainting model: A generative inpainting system from the FLUX family used to replace foreground content in images. "We first collect a large set of film images and use the Flux inpainting model \cite{flux2024} to substitute the foreground character."
- Flux Kontext: A FLUX-based latent flow-matching method for in-context image generation and editing, used here to augment poses of reference images. "we augment its pose with Flux Kontext \cite{batifol2025flux}."
- In-Context Learning: Conditioning generation by concatenating inputs (e.g., source video, mask, references) so the model learns to use them implicitly during inference. "through efficient in-context learning by integrating the video content, frame mask, and reference character identity."
- LivePortrait: A portrait animation technique that drives facial expressions to animate images. "Then we use LivePortrait \cite{liveportrait} to animate both images with the same facial-driven video."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank updates into existing model layers to adapt large models without full retraining. "we employ parameter-efficient fine-tuning using Low-Rank Adaptation (LoRA)~\cite{hu2022lora} instead of full model tuning."
- LPIPS (Learned Perceptual Image Patch Similarity): A perceptual similarity metric based on deep features, used to assess visual fidelity beyond pixel-wise errors. "we employ widely-used quantitative metrics, including SSIM~\cite{wang2004ssim}, LPIPS~\cite{zhang2018lpips}, and PSNR."
- PSNR (Peak Signal-to-Noise Ratio): A reconstruction-quality metric that quantifies the ratio between signal power and noise power in generated outputs. "we employ widely-used quantitative metrics, including SSIM~\cite{wang2004ssim}, LPIPS~\cite{zhang2018lpips}, and PSNR."
- Rectified Flow: A flow-based generative modeling framework where the model predicts velocities along a trajectory from noise to data, enabling efficient sampling. "MoCha builds on the pretrained text-to-video latent diffusion model using the Rectified Flow framework~\cite{flow-matching}."
- Reward hacking: An RL failure mode where the model exploits the reward objective in unintended ways (e.g., copying references) rather than learning the desired behavior. "To avoid reward hacking that the model simply pastes the reference image into the generated video, we also use a pixel-wise Mean Squared Error (MSE) loss between the generated video and the GT video to provide dense supervision."
- RoPE (Rotary Positional Embedding): A positional encoding technique that encodes positions via complex rotations, supporting extrapolation and better inductive biases; here used in 3D for spatiotemporal tokens. "However, a naive application of 3D Rotary Positional Embeddings (RoPE) by assigning a different temporal index to each condition would result in inflexible generation, such as being constrained to a fixed output length."
- SAM2 (Segment Anything Model 2): A segmentation model that can produce masks in images and videos with minimal prompting. "For each video, we use SAM2~\cite{sam2} to generate a randomly selected frame mask."
- SSIM (Structural Similarity Index Measure): An image similarity metric that captures structural changes in luminance, contrast, and structure. "we employ widely-used quantitative metrics, including SSIM~\cite{wang2004ssim}, LPIPS~\cite{zhang2018lpips}, and PSNR."
- Unreal Engine 5 (UE5): A real-time 3D rendering engine used to synthesize high-fidelity paired video data with consistent scenes, motions, and lighting. "Specifically, we design three specialized datasets: a high-fidelity rendered dataset built with Unreal Engine 5 (UE5)"
- VAE (Variational Autoencoder): A probabilistic encoder–decoder model that compresses inputs into a latent space for generative modeling. "The input video will first be compressed to a latent through a video variational encoder~\cite{vae} (VAE)."
- VBench: A comprehensive benchmark suite for evaluating video generative models across multiple dimensions (consistency, quality, motion, etc.). "we adopt the comprehensive evaluation suite from VBench~\cite{huang2024vbench} for a thorough comparison."
- YOLOv12: An attention-centric, real-time object detector used here to filter non-human videos in dataset construction. "We apply a YOLOv12 detector \cite{tian2025yolov12} to filter non-human videos."
Collections
Sign up for free to add this paper to one or more collections.