Parallel Context-of-Experts Decoding for Retrieval Augmented Generation
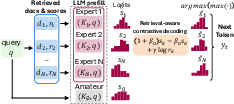
Abstract: Retrieval Augmented Generation faces a trade-off: concatenating documents in a long prompt enables multi-document reasoning but creates prefill bottlenecks, while encoding document KV caches separately offers speed but breaks cross-document interaction. We propose Parallel Context-of-Experts Decoding (Pced), a training-free framework that shifts evidence aggregation from the attention mechanism to the decoding. Pced treats retrieved documents as isolated "experts", synchronizing their predictions via a novel retrieval-aware contrastive decoding rule that weighs expert logits against the model prior. This approach recovers cross-document reasoning capabilities without constructing a shared attention across documents.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Parallel Context‑of‑Experts Decoding (PCED) — A simple explanation
What this paper is about (overview)
This paper tackles a common problem in “retrieval‑augmented generation” (RAG), where a LLM looks up documents and then writes an answer. If you stuff many documents into one long prompt, the model can, in theory, connect facts across them—but it gets slow to start and often gets confused. If you keep documents separate to make things faster, the model struggles to combine information across them.
The authors propose PCED, a new, training‑free way to generate answers that treats each retrieved document like a separate “expert.” At every word the model writes, these experts “vote” on the next word in parallel. PCED then picks the word that has the strongest support from the most relevant expert—recovering cross‑document reasoning without building one huge prompt.
What the researchers wanted to find out (key questions)
- Can we keep the speed benefits of handling documents separately, but still let the model combine facts from different documents?
- Can we do this without retraining the model?
- Can we use document relevance scores (from retrieval/reranking) to trust the right document at the right time, and ignore distractors?
How it works (methods in everyday language)
Think of answering a question as consulting a panel:
- Each retrieved document is an “expert.”
- There’s also an “amateur”—the model’s own guess without any documents (its built‑in knowledge).
Here’s the approach, step by step:
- Preparing “notes” in advance
- For every document in a library, the system precomputes a fast‑to‑reuse summary of how the model would read it (called a “KV cache”).
- This is like having quick reference notes ready, so you don’t reread the whole document each time.
- Finding documents and scoring them
- When a question comes in, the system retrieves the top N documents and gives each one a relevance score (how likely it is to help).
- These scores come from standard retrievers and rerankers and are scaled to 0‑1.
- Parallel “expert” suggestions at each word
- The model runs all experts (each with its own document notes) plus the amateur in parallel.
- Each expert proposes a distribution over the next word (its “confidence” for each word). These confidence numbers are called “logits”—you can think of them as how strongly each expert believes each word is the right next step.
- Comparing to the amateur and using relevance (contrastive decoding)
- PCED boosts an expert’s suggestion when it offers helpful evidence beyond what the amateur would say, and when the document’s relevance score is high.
- This “retrieval‑aware contrastive decoding” means:
- If an expert strongly supports a word and the amateur doesn’t, and the document is relevant, that word gets a bigger push.
- If a document is probably irrelevant, its influence is turned down.
- Choosing and moving forward
- The system picks the single best‑supported next word across all experts.
- That chosen word is added to the shared history for all experts so they stay in sync (this helps the model “stitch” evidence across different documents as it writes the full answer).
- Repeat for the next word.
No training is needed; this is all done at decoding (generation) time.
What they found (main results and why they matter)
On benchmarks with many documents and multi‑step questions (like LOFT and LongBench, including HotpotQA, MuSiQue, NQ, and QAMParI), PCED:
- Beats previous “parallel” methods that try to merge separate document caches (KV‑merging like APE), especially on tasks that require combining facts across multiple documents.
- Often matches or beats the classic “put all documents in one long prompt” approach—without paying the cost of a long, slow prefill.
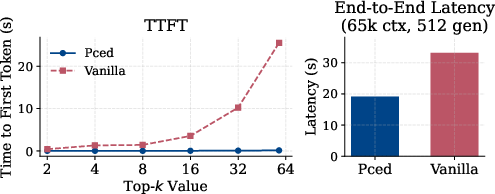
- Is much faster to start generating: time‑to‑first‑token is reported to be over 180× faster in some settings, and overall end‑to‑end time is lower (around 1.7× faster for long contexts), because the heavy lifting (document reading) is done offline and reused.
- Is more robust to distractors (irrelevant documents). Because each document is an isolated expert weighted by relevance, noisy documents don’t overwhelm useful ones.
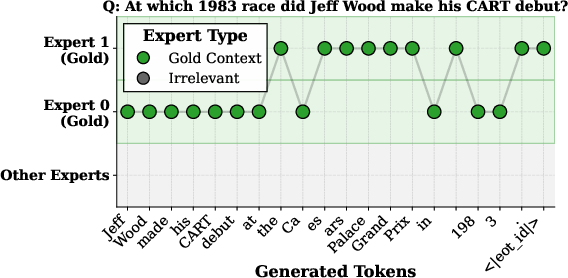
- Works by “expert switching”: during generation, the model naturally hops between the most helpful documents at different steps, allowing it to solve multi‑hop questions.
Ablation tests (turning features on/off) showed that both parts are important:
- Contrastive comparison with the amateur helps avoid blindly trusting context.
- Relevance weighting helps ignore unhelpful documents.
Why this is useful (implications and impact)
- Faster answers with better focus: You don’t need to cram everything into a giant prompt, so the model starts responding much quicker while staying accurate.
- Scales to lots of documents: Instead of being limited by the model’s context window, you can treat more documents as separate experts and let decoding combine them.
- Training‑free and model‑agnostic: Works with existing open models without retraining.
- Practical for real‑world RAG: Especially helpful when you have many candidate documents and some are noisy or only partially relevant.
A few caveats to keep in mind:
- It needs access to detailed model outputs (“logits”), which many closed APIs don’t provide.
- It still depends on good retrieval—if the right document isn’t found or is scored low, it may be underused.
- Storing precomputed caches takes space; this is best for stable, read‑heavy collections (like enterprise knowledge bases).
Overall, PCED offers a neat way to get both speed and smarts: it lets the model “listen” to multiple documents like a panel of experts, choosing the right advice word‑by‑word—without building a huge, slow prompt.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow-up work:
- Theory of equivalence: No formal analysis of when decode-time expert fusion approximates or recovers the behavior of joint cross-document attention. Specify conditions (e.g., independence assumptions, sparsity of attention, agreement among experts) under which the proposed max-of-experts rule is guaranteed to be faithful to a long-context attention baseline.
- Aggregation rule design: The method uses a hard max over experts’ logits; alternatives (e.g., temperature-scaled weighted sums, product-of-experts, mixture-of-experts with uncertainty-aware weights, hysteresis to reduce oscillation) are not explored systematically. Identify regimes where soft vs. hard aggregation is preferable.
- Amateur fallback gap: The amateur (no-context prior) influences experts only via contrastive subtraction but is not included as a candidate in the final argmax. Evaluate and, if beneficial, add explicit fallback to the amateur expert when all retrieved experts are weak or irrelevant.
- Retrieval-prior calibration: The prior adds a token-invariant bias via γ log r_k. Study calibration of retrieval/reranker scores across datasets/models (e.g., Platt/Isotonic scaling), robustness to miscalibrated or distribution-shifted scores, and whether score normalization functions (log, temperature, clipping) materially change outcomes.
- Hyperparameter adaptation: β is adapted only at the first token and γ is fixed. Explore per-token or per-query adaptation of β and γ driven by online measures (e.g., divergence between experts, entropy/uncertainty, agreement metrics).
- Token-level robustness: Analyze risks of expert “thrashing” (frequent switching) and design stabilizers (e.g., momentum, sticky experts, switch penalties, beam-level consistency checks) to avoid incoherent outputs.
- Conflict handling: No mechanism to detect or resolve contradictions among experts. Add contradiction detection, cross-document consistency checks, or consensus filtering to prevent aggregating mutually inconsistent evidence.
- Adversarial/noisy retrieval: Evaluate robustness when retrieved documents are adversarial, heavily noisy, or intentionally misleading; design defenses (e.g., adversarial reranking, trustworthiness scores, document-level uncertainty) to mitigate malicious experts.
- Scale with number of experts (N): While TTFT improves, the per-step decode cost scales with N. Quantify GPU memory/throughput limits, and develop dynamic pruning (e.g., top-m experts by running likelihood), early stopping for weak experts, and batched scheduling policies.
- Storage footprint/compression: Beyond noting the linear storage cost of KV caches, investigate compression (quantization, sparsification, tensor factorization), cache sharing across similar chunks, and selective-layer caching to reduce GB/TB-scale footprints.
- Cache maintenance for dynamic corpora: Provide algorithms for incremental cache updates, invalidation, eviction strategies, and consistency under frequent corpus changes; report update costs and service-level impacts.
- Chunking granularity: The impact of chunk length, overlaps, and segmentation policy on expert quality and multi-hop coverage is not studied. Run controlled experiments to determine optimal chunking under different tasks.
- Decoding strategy compatibility: Results are with greedy decoding only. Evaluate interaction with sampling, temperature, top-k/p, beam search, and contrastive sampling; measure whether Pced maintains or degrades diversity/faithfulness trade-offs.
- Multilingual and cross-domain generalization: Benchmarks are English-centric. Test on multilingual RAG, domain-specific corpora (legal, medical), and noisy web data to assess generalization of retrieval priors and expert fusion.
- Comparative completeness: Methods like KVLink, other cache-merging/bridging approaches, and multi-document contrastive decoding (e.g., DvD) are not empirically compared. Provide head-to-head comparisons under matched retrieval pools and settings.
- Attribution and citations: Although an expert trace is shown, there is no principled mechanism to output document-level citations or token/span attributions. Develop and evaluate citation extraction from token-level expert selections.
- End-to-end latency accounting: TTFT excludes retrieval/reranking costs. Report full pipeline latency (including retrieval/reranking and cache I/O), and study overlapping/streaming strategies for realistic service deployments.
- Limits of decode-time synthesis: Assess tasks requiring joint synthesis across many documents (where MapReduce sometimes wins). Identify failure cases and propose hybrid strategies combining Pced with summarization/verification/reduction passes.
- Prompt and cache compatibility: Clarify and evaluate how instruction/system prompts interact with document-only caches. Study prompt normalization or prompt-robust caching to prevent distribution mismatch between cache encoding and generation.
- Numerical stability: Define precise score mappings to (0,1) and handling of r_k≈0 (e.g., ε-clipping) to avoid −∞ priors; study stability under extreme γ or ill-conditioned logits.
- Token-specific priors: The retrieval prior is token-invariant. Explore token-aware priors (e.g., lexical overlap, BM25/ColBERT token alignments, saliency from cross-encoders) to more precisely bias supported tokens.
- Lookahead and reconsideration: Early token decisions can steer generation irreversibly. Investigate limited lookahead, speculative decoding with expert branching, or retroactive expert reweighting for error correction.
- Dynamic expert pruning: Introduce compute-saving criteria (e.g., sustained low relative likelihood, low cumulative support) to drop experts during decoding and quantify accuracy–latency trade-offs.
- Privacy/security of cached states: Precomputed KV caches may leak sensitive content. Analyze threat models and propose encryption, access control, and per-tenant isolation for cache stores.
- Distractor stress tests: Current long-context robustness adds only K=2 distractors. Systematically scale distractors and adversarial distractors to map degradation curves and identify breakpoints.
- Human and factuality evaluations: Add human judgments and factuality metrics (e.g., AlignScore, Faithfulness, ECE/Brier for calibration) and conduct granular error analyses to characterize failure modes.
- Closed-source/API applicability: Explore approximations when only limited logprobs are available (e.g., top-k logprobs, surrogate amateurs, two-pass distillation to a local proxy) to broaden applicability.
- Hybrid agentic integration: Design decision policies to switch between Pced and MapReduce (or combine them) based on signals like expert disagreement, entropy, or retrieval diversity.
- Beyond logit-level fusion: Investigate feature-level or per-layer training-free fusion (e.g., linear probes, adapters) and compare against purely logit-level aggregation.
- Probability calibration: Because selection is via argmax over unnormalized expert logits, study output calibration and develop methods to recover calibrated probabilities for downstream decision-making.
- Reproducibility gaps: Code and appendices are not provided (marked TODO). Release code, configs, seeds, and full ablation details (β, γ, aggregation rules, top-k/N sweeps) to enable independent verification.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed today using the paper’s training-free Parallel Context-of-Experts Decoding (Pced) with precomputed per-document KV caches and retrieval-aware contrastive decoding. Each item includes sectors, potential tools/workflows, and feasibility notes.
- Enterprise knowledge-base chat with sub-second TTFT
- Why it matters: Pced cuts time-to-first-token by up to 180× versus long-context concatenation while matching or exceeding answer quality, enabling responsive enterprise assistants even with large document pools.
- Sectors: Software/SaaS, Enterprise IT, HR, Sales Enablement
- Tools/Products/Workflows: vLLM or similar server with PagedAttention; Faiss/Elasticsearch + reranker; “KV Cache Datastore” that stores (document, embedding, precomputed KV); Pced decoding head for inference; continuous batching for high throughput
- Assumptions/Dependencies: Open/self-hosted LLM with full logits; static or slowly changing corpora; storage budget for caches; high-quality retriever + reranker and relevance scores
- Customer support and help center agents over manuals and FAQs
- Why it matters: Multi-document queries (troubleshooting steps, cross-product compatibility) benefit from token-level expert switching; retrieval-aware gating reduces distractor noise.
- Sectors: Consumer Electronics, Telecom, Automotive, E-commerce
- Tools/Products/Workflows: Ingestion pipeline (chunk, embed, rerank), KV cache preparation per document; Pced inference; “expert trace” logging to show which document supported each step
- Assumptions/Dependencies: Access-controlled on-prem deployment for proprietary docs; monitoring retrieval drift; cache invalidation on product updates
- Legal Q&A and eDiscovery triage
- Why it matters: Pced stitches evidence across clauses/attachments without concatenating long filings, improving multi-hop reasoning and response latency.
- Sectors: Legal Services, Compliance, Insurance
- Tools/Products/Workflows: Contract/evidence repository indexing; cross-encoder reranking; KV cache store; Pced Q&A and clause comparison; token-level provenance trace for audit
- Assumptions/Dependencies: Confidentiality and data residency; model access to logits; strong retrieval/reranking tuned to legal text; regular cache refresh/versioning
- Clinical guideline and policy navigator
- Why it matters: Answers often require integrating multiple guidelines, policies, or trials; Pced reduces distractor-induced errors and speeds triage.
- Sectors: Healthcare, Public Health, Payers
- Tools/Products/Workflows: Curated guideline repository with embeddings and caches; clinician-facing Q&A with Pced; evidence highlight and source links
- Assumptions/Dependencies: Medical safety and human-in-the-loop review; domain-tuned retrieval; on-prem or VPC deployment; disclaimers and governance
- Financial research copilot across filings and reports
- Why it matters: Cross-document analysis of 10-K/10-Q, earnings transcripts, and broker notes benefits from Pced’s expert isolation and decoding-time aggregation.
- Sectors: Finance, Asset Management, Equity Research
- Tools/Products/Workflows: SEC EDGAR and internal research ingestion; dense retriever + reranker; KV cache warehouse; Pced with token-level source attributions; notebook plug-ins
- Assumptions/Dependencies: Timely ingestion and cache refresh; governance for MNPI; GPU memory and storage sizing
- Codebase Q&A and completion for large repositories
- Why it matters: Repo-wide understanding (API usages across files, refactor impact) aligns with Pced’s strong results on code tasks and multi-file reasoning.
- Sectors: Software Engineering, DevOps
- Tools/Products/Workflows: Index source files and docs; per-file KV caches; Pced answering in IDE/chat; cross-file autocompletion and “why” explanations (expert trace)
- Assumptions/Dependencies: Frequent code changes require cache invalidation strategies; language-aware chunking; tokenization and context length management
- Education: multi-document study assistants and exam prep
- Why it matters: Pced improves multi-source reading comprehension and reduces distraction from near-miss materials.
- Sectors: Education, EdTech
- Tools/Products/Workflows: Course packet ingestion; example selection (ICL) + Pced decoding; explainable answers showing document hops
- Assumptions/Dependencies: Quality of retrieval and reranking; alignment and safety filters for students
- Newsroom research and fact-checking
- Why it matters: Low-latency synthesis across many sources; Pced handles distractors better than full concatenation.
- Sectors: Media, Journalism
- Tools/Products/Workflows: Wire feeds + archive ingestion; streaming retrieval + periodic cache updates; Pced-assisted briefs with cited sources
- Assumptions/Dependencies: Freshness strategies for caches; disinformation filters; editorial review
- Regulatory and compliance copilots
- Why it matters: Map internal controls to evolving regulations by aggregating clauses across multiple texts; token-level provenance aids audits.
- Sectors: Financial Services, Pharma, Energy, Government
- Tools/Products/Workflows: Regulation corpus + internal policy KB; KV caches and Pced Q&A; “explain your evidence” mode using expert traces
- Assumptions/Dependencies: On-prem or restricted cloud; robust security; model governance and explainability needs
- Security incident-response knowledge assistant
- Why it matters: Rapid lookup across runbooks, playbooks, and prior tickets with low TTFT during incidents.
- Sectors: Cybersecurity, SRE/Operations
- Tools/Products/Workflows: Ingest runbooks/tickets; per-document caches; Pced for targeted step guidance; source-linked actions
- Assumptions/Dependencies: Strict access controls; quick cache refresh for evolving playbooks; high recall retrieval
- LLMOps: Pced as a RAG acceleration plugin
- Why it matters: Off-the-shelf enhancement to existing RAG stacks to reduce prefill bottlenecks and improve robustness to distractors.
- Sectors: MLOps/Platform, Cloud Providers
- Tools/Products/Workflows: “Pced Router” library for vLLM/TGI; cache lifecycle manager; observability of expert-switch patterns; autoscaling for parallel experts
- Assumptions/Dependencies: API needs logits (not just sampled tokens or top-k logprobs); infrastructure for cache storage and retrieval
- Field/edge deployments with intermittent connectivity
- Why it matters: Precompute caches and answer locally with minimal online compute; ideal for static manuals and SOPs.
- Sectors: Manufacturing, Energy, Mining, Defense
- Tools/Products/Workflows: Edge server with KV caches; Pced inference; local retriever with compact reranker
- Assumptions/Dependencies: Sufficient storage; model fits on device; periodic offline updates
Long-Term Applications
These opportunities require additional research, scaling, or ecosystem changes (e.g., API capabilities, standardized cache formats, training).
- End-to-end models natively trained for parallel experts
- What: Train LLMs to accept multiple independent “expert” inputs and learn token-level expert selection, reducing dependence on external retrieval scores.
- Sectors: Foundation Models, Research, Healthcare
- Dependencies: Training data/infrastructure; architectural interfaces for parallel expert streams; evaluation on multi-hop reasoning
- Standardized KV cache formats and distributed cache stores
- What: Interoperable cache schema and lifecycle APIs enabling cross-service reuse, delta updates, and memory-tiering (GPU/CPU/disk).
- Sectors: MLOps, Cloud/Infra
- Dependencies: Community standards; cache compression/quantization; privacy-aware retention policies
- Pced for closed-source/API models
- What: Vendor support for per-token logits or richer logprob APIs to enable retrieval-aware contrastive decoding with multiple experts.
- Sectors: Cloud AI Platforms
- Dependencies: API evolution; privacy and rate-limit considerations; server-side batching
- Secure and privacy-preserving cache serving
- What: Encrypted KV caches, secure enclaves/TEEs, and differential privacy to protect sensitive corpora while retaining latency gains.
- Sectors: Healthcare, Finance, GovTech
- Dependencies: Cryptographic protocols; performance-preserving security; compliance audits (HIPAA, GDPR)
- Streaming/real-time corpora and “living caches”
- What: Continuous cache refresh for news markets, fraud, and threat intel, with background re-embedding and reranking.
- Sectors: Media, FinTech, Cybersecurity
- Dependencies: Low-latency retrievers; incremental cache updates; cache invalidation and versioning
- Multimodal context-of-experts
- What: Extend experts to images, tables, code ASTs, telemetry, and graphs; decode-time fusion across modalities.
- Sectors: Healthcare (imaging + text), Manufacturing (manuals + schematics), Autonomous Systems
- Dependencies: Multimodal encoders with KV export; fusion policies; task-specific evaluation
- Hybrid agentic workflows: Pced + MapReduce + tool calls
- What: Use Pced for token-level evidence fusion, augmented with summarization/retrieval agents when global synthesis is needed.
- Sectors: Knowledge Work Automation, Legal, Consulting
- Dependencies: Orchestration frameworks; cost/latency trade-off tuning; reliability and fallback policies
- Hardware and compiler support for expert-parallel decoding
- What: Specialized batching, page management, and memory schedulers optimized for parallel per-document caches.
- Sectors: AI Hardware, Systems
- Dependencies: Compiler/runtime advances; GPU memory virtualization; NUMA-aware cache placement
- Auditable, regulation-ready explainability via expert traces
- What: Standardize “evidence per token” logging and reporting for regulated domains, enabling right-to-explanation audits.
- Sectors: Finance, Healthcare, Public Sector
- Dependencies: Provenance standards; secure logging; human-in-the-loop review processes
- Content-provider–hosted caches and “knowledge CDNs”
- What: Publishers expose KV caches for their corpora to reduce latency for downstream apps (with licensing/usage control).
- Sectors: Publishing, Legal Databases, Scientific Libraries
- Dependencies: Licensing models; API and cache distribution standards; trust and integrity guarantees
- Continual learning from expert-switch telemetry
- What: Use observed expert-switch patterns to auto-tune retrievers/rerankers and adapt relevance gating parameters over time.
- Sectors: MLOps, Recommender Systems
- Dependencies: Feedback loops; offline evaluation pipelines; drift detection and guardrails
- Domain-specific Pced-tuned retrievers/rerankers
- What: Optimize retrieval signals r_k and fusion (e.g., harmonic mean weighting vs learned gating) for domains like law, medicine, code.
- Sectors: LegalTech, MedTech, DevTools
- Dependencies: Domain corpora and labels; evaluation suites; potential light fine-tuning for rerankers
- Edge-first industrial copilots
- What: Robust, low-latency assistants for plant operations combining sensor manuals, maintenance logs, and SOPs as experts.
- Sectors: Energy, Manufacturing, Transportation
- Dependencies: Multimodal integration (text + tables/diagrams); ruggedized hardware; offline update channels
Common assumptions and dependencies that impact feasibility
- Logit access: Pced requires per-token logits for all expert streams; closed APIs that expose only sampled tokens or limited logprobs are insufficient unless vendors extend capabilities.
- Retrieval quality: The approach hinges on high recall in retrieval and accurate reranking; missing or mis-scored documents degrade performance.
- Storage vs. compute trade-off: Precomputing and hosting per-document KV caches increases storage requirements; quantization/compression may be needed at scale.
- Corpora dynamics: Static or slow-changing corpora are ideal. Frequent updates require efficient cache invalidation and refresh pipelines.
- Infrastructure: Benefits amplify with batch-parallel inference servers (e.g., vLLM with PagedAttention), fast vector stores (Faiss/ScaNN), and continuous batching.
- Governance and safety: For sensitive domains, enforce access control, data residency, safety filters, and human-in-the-loop review; expose provenance via expert traces.
Glossary
- AdaCAD: An adaptive decoding method that adjusts contrast strength based on the degree of conflict between contextual and parametric knowledge. "We compute dynamically as in AdaCAD~\citep{wang-etal-2025-adacad} for the first generated token"
- Agentic aggregation (MapReduce): A pipeline that summarizes each document separately and then aggregates the summaries to answer queries. "Agentic aggregation (MapReduce) performs per-document summarization (map) followed by a final QA aggregation step (reduce)~\citep{zhou-etal-2025-llmxmapreduce}."
- Amateur expert: The no-context model stream treated as a prior, used to calibrate contextual experts during decoding. "one amateur expert with an empty cache (model prior)"
- bge-m3: A retrieval embedding model used to compute document relevance signals for weighting experts. "These variants differ only in the relevance signal extracted from bge-m3 to weight experts in Eq.~\ref{eq:contrastive-retrieval-bias-wrapped}."
- Classifier-free guidance: A diffusion-model technique that guides generation by mixing conditional and unconditional predictions, related to contrastive adjustments in decoding. "and classifier-free guidance in diffusion models"
- ColBERT: A late-interaction dense retrieval architecture used here as a scoring variant for weighting experts. "We evaluate three scoring variants: Sparse, Dense, and ColBERT."
- Contrastive decoding: A test-time strategy that adjusts token probabilities by contrasting model outputs with and without certain conditions (e.g., context). "it is related to contrastive decoding~\citep{li-etal-2023-contrastive}"
- Continuous batching: An inference technique that dynamically batches requests over time to improve throughput. "All results use a high-throughput setup with continuous batching and PagedAttention~\citep{10.1145/360(0006.36131)65} for both methods"
- Context-aware decoding (CAD): A decoding approach that increases probability mass for tokens supported by the provided context to improve faithfulness. "Context-aware decoding (CAD)~\citep{shi-etal-2024-trusting} improves faithfulness by shifting probability mass toward tokens supported by context"
- Cross-document attention: Attention mechanisms that allow interaction across multiple documents in a shared context. "removing cross-document attention during encoding can substantially degrade performance on multi-hop and reasoning-intensive queries~\citep{10.1145/3689031.3696098}."
- Cross-encoder reranker: A model that jointly encodes query–document pairs to rescore and reorder retrieved candidates. "followed by a cross-encoder reranker to reorder candidates and maximize precision."
- Distractors: Irrelevant documents added to the context that can dilute or mislead attention. "we concatenate the gold document with uniformly sampled distractors from other test samples"
- DvD: Dynamic Contrastive Decoding, a multi-document decoding method that amplifies selected documents during generation. "DvD~\citep{jin-etal-2024-dvd} extends CAD to multiple documents but collapses them into a single input sequence"
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step without exploration. "Decoding is greedy for all methods."
- Harmonic mean: An averaging method that balances recall and precision signals into a single relevance score. "we fuse them into a single per-document relevance score via the harmonic mean"
- In Context Learning (ICL): The ability of LLMs to perform tasks by conditioning on example demonstrations in the prompt. "We test Pced on RAG, In Context Learning (ICL), and long-context QA with distractors."
- Jensen-Shannon divergence: A symmetric measure of distributional difference used to estimate conflict between contextual and prior distributions. "using the Jensen-Shannon divergence~\citep{61115} between amateur and expert distributions"
- KV cache: Stored transformer key–value activations for a context, enabling reuse to avoid re-encoding during inference. "Parallel KV cache encoding mitigates prefill cost by encoding retrieved documents independently and reusing their cached states at inference time~\citep{yang2025kvlink,yang2025ape}."
- KV cache merging (APE): A method that merges independently encoded caches to approximate joint attention without full sequential prefill. "KV cache merging (APE), prefills each document independently and merges the resulting KV caches."
- Logits: Pre-softmax scores over the vocabulary representing unnormalized token probabilities. "this yields per-expert logits over the vocabulary ."
- Multi-hop: Queries requiring reasoning across multiple pieces of evidence, often from different documents. "degrade performance on multi-hop and reasoning-intensive queries"
- PagedAttention: An attention memory management technique that pages KV caches to improve throughput and scalability. "continuous batching and PagedAttention~\citep{10.1145/360(0006.36131)65} for both methods"
- Parallel Context-of-Experts Decoding (Pced): The proposed training-free framework that aggregates evidence at decode time by treating documents as parallel experts. "We propose Parallel Context-of-Experts Decoding (Pced), a training-free framework that shifts document aggregation from attention to decoding."
- Prefill latency: The time consumed to process the input context before generating the first output token. "making inference dominated by prefill latency"
- Retrieval-aware contrastive decoding: A rule that calibrates expert logits against a prior and weights them using retrieval relevance scores. "via a novel retrieval-aware contrastive decoding rule that weighs expert logits against the model prior."
- Retrieval gating: A control mechanism that scales the influence of retrieval-based priors during decoding. "and controls retrieval gating."
- Subspan Exact Match: An evaluation metric that checks whether the predicted answer matches any contiguous subspan of the gold reference. "Performance is measured via Subspan Exact Match for RAG tasks"
- Time-To-First-Token (TTFT): The latency until the model emits its first token, a key inference efficiency metric. "Pced leverages offline, reusable KV caches to reduce Time-To-First-Token (TTFT)."
- Token-level expert switching: The dynamic selection of different document experts at each generation step to stitch evidence. "token-level expert switching to recover cross-document reasoning via dynamic expert selection at every token step without shared attention;"
- YaRN: A technique for extending an LLM’s context window to long lengths (e.g., 128k tokens). "Qwen3-8B~\citep{yang2025qwen3} extended to 128k tokens with YaRN~\citep{peng2024yarn}."
Collections
Sign up for free to add this paper to one or more collections.