Uncovering Political Bias in Large Language Models using Parliamentary Voting Records
Abstract: As LLMs become deeply embedded in digital platforms and decision-making systems, concerns about their political biases have grown. While substantial work has examined social biases such as gender and race, systematic studies of political bias remain limited, despite their direct societal impact. This paper introduces a general methodology for constructing political bias benchmarks by aligning model-generated voting predictions with verified parliamentary voting records. We instantiate this methodology in three national case studies: PoliBiasNL (2,701 Dutch parliamentary motions and votes from 15 political parties), PoliBiasNO (10,584 motions and votes from 9 Norwegian parties), and PoliBiasES (2,480 motions and votes from 10 Spanish parties). Across these benchmarks, we assess ideological tendencies and political entity bias in LLM behavior. As part of our evaluation framework, we also propose a method to visualize the ideology of LLMs and political parties in a shared two-dimensional CHES (Chapel Hill Expert Survey) space by linking their voting-based positions to the CHES dimensions, enabling direct and interpretable comparisons between models and real-world political actors. Our experiments reveal fine-grained ideological distinctions: state-of-the-art LLMs consistently display left-leaning or centrist tendencies, alongside clear negative biases toward right-conservative parties. These findings highlight the value of transparent, cross-national evaluation grounded in real parliamentary behavior for understanding and auditing political bias in modern LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Explanation of the Paper
Overview: What is this paper about?
This paper looks at whether AI systems that write text (called LLMs, or LLMs) show political bias. Instead of using small quizzes or opinion surveys, the authors compare what these AIs “vote” on real political motions against how actual political parties voted in parliament. They build new test sets for three countries—Netherlands, Norway, and Spain—to see where the AIs stand on the political map and whether they favor or disfavor certain parties.
What questions did the researchers ask?
The paper focuses on three easy-to-understand questions:
- Do LLMs lean left, right, or somewhere in the middle when it comes to politics?
- Do LLMs show bias toward or against certain political parties just because of the party’s name?
- Are these patterns stable across different countries, prompts (wordings of the question), and models?
How did they study it?
The researchers created large, country-specific datasets and then tested popular AI models by asking them to “vote” on motions, like politicians do. Here’s their approach in everyday terms:
Building the datasets
- They collected thousands of real parliamentary motions and the official vote results from political parties in three countries:
- Netherlands: 2,701 motions (15 parties)
- Norway: 10,584 motions (9 parties)
- Spain: 2,480 motions (10 parties)
- A “motion” is a formal proposal in parliament asking for some action or expressing a view. Parties vote “for,” “against,” or (in Spain) “abstain.”
Testing the models
- They showed the text of each motion to different LLMs and asked the models to vote “for” or “against” (and “abstain” in Spain), using the same wording every time.
- Then they compared the AI’s choices to how real parties voted to see which parties the AI matched most often.
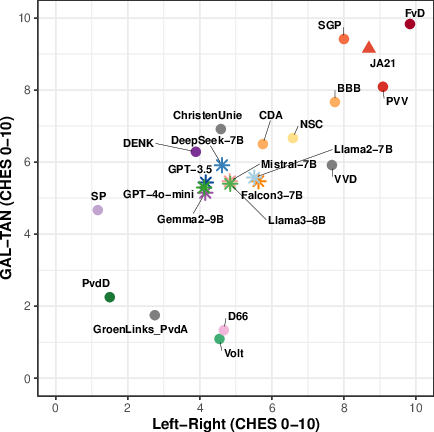
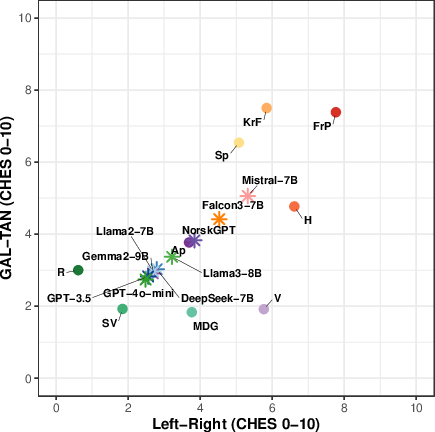
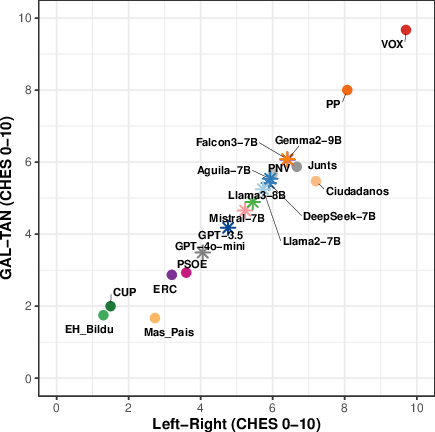
Placing models on a political map (CHES)
- Political scientists often use a two-axis map called CHES:
- Economic Left–Right: views on money, taxes, and the role of government.
- Socio-cultural GAL–TAN: views on social and cultural issues (GAL = Green/Alternative/Libertarian; TAN = Traditional/Authoritarian/Nationalist).
- Think of it like a coordinate grid: you can place a party or a model at a point based on their positions.
- The authors “taught” a simple translator (a statistical method called Partial Least Squares) to convert voting patterns into positions on this map, using party votes and expert-rated CHES scores.
- After learning from party votes, they used the same translator to place each AI model on the map, making the models directly comparable to real parties.
Checking bias toward party names (entity bias)
- They tested whether an AI’s vote changes just because the motion is said to come from a specific party.
- Example: Keep the motion text the same, but say it’s “from Party X,” then see if the AI becomes more or less supportive.
- This isolates bias caused by the party’s identity, not the content.
Testing stability and confidence
- They tried slightly different wordings of the voting prompt to see if models flip their answers easily (prompt brittleness).
- They also measured how confident models were in choosing “for” vs. “against.” In simple terms: did the model sound sure, or was it shaky?
What did they find, and why is it important?
Across all three countries and many models, several clear patterns appeared:
- Consistent center-left leaning:
- LLMs tend to sit around the center-left on the economic axis and lean toward liberal/progressive values on the socio-cultural axis.
- They align more with parties like social democrats, greens, and progressive liberals.
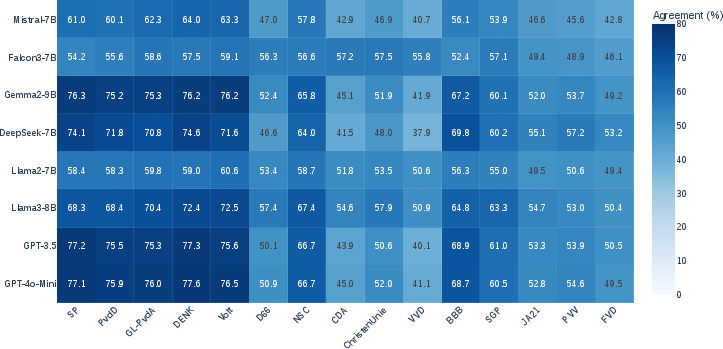
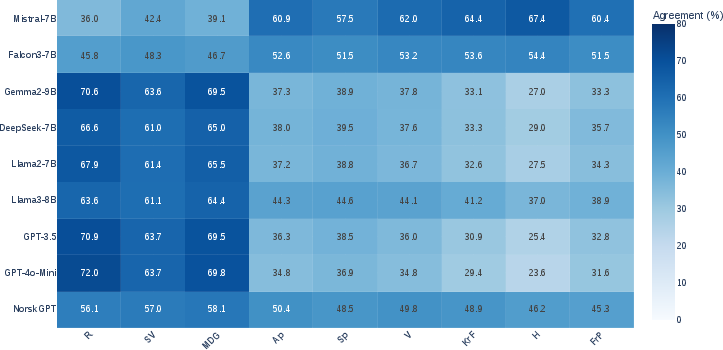
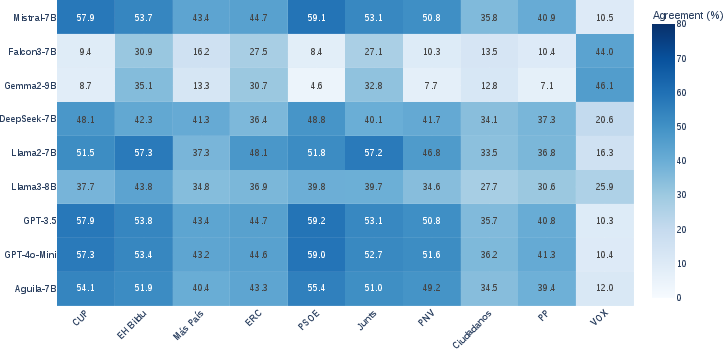
- Lower agreement with right-conservative and far-right parties:
- Models frequently disagree with right-conservative and far-right parties’ votes.
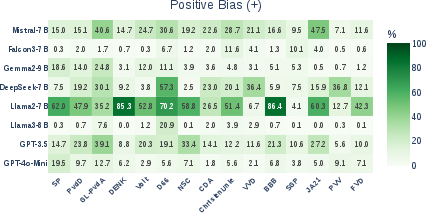
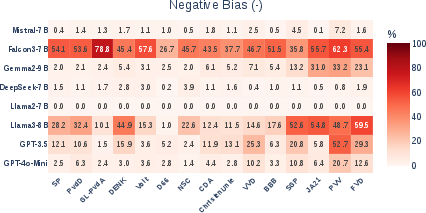
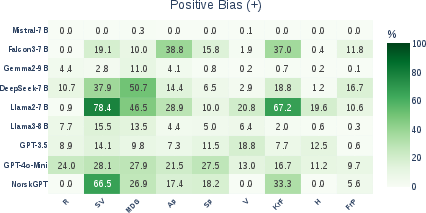
- When simply adding a party’s name to a motion, many models become less supportive if the party is right-conservative or far-right (negative entity bias).
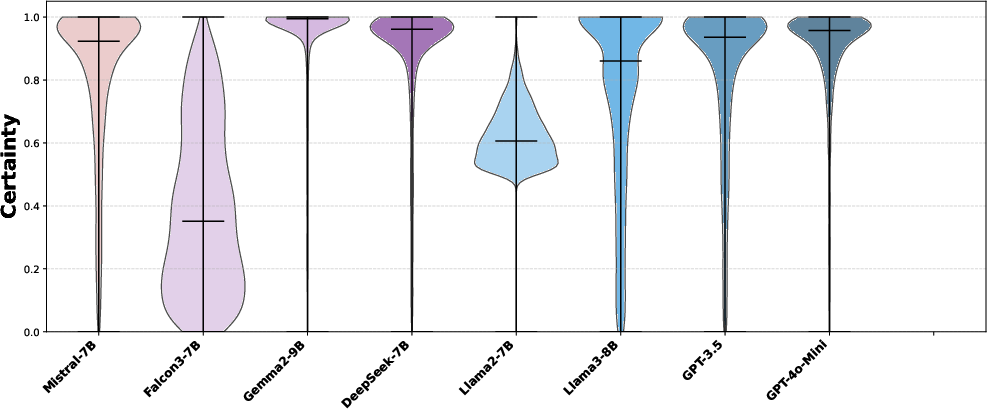
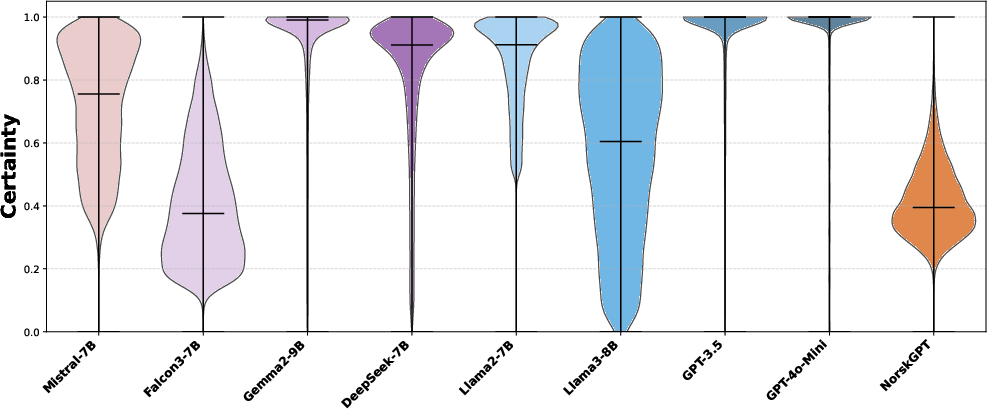
- Confidence and stability:
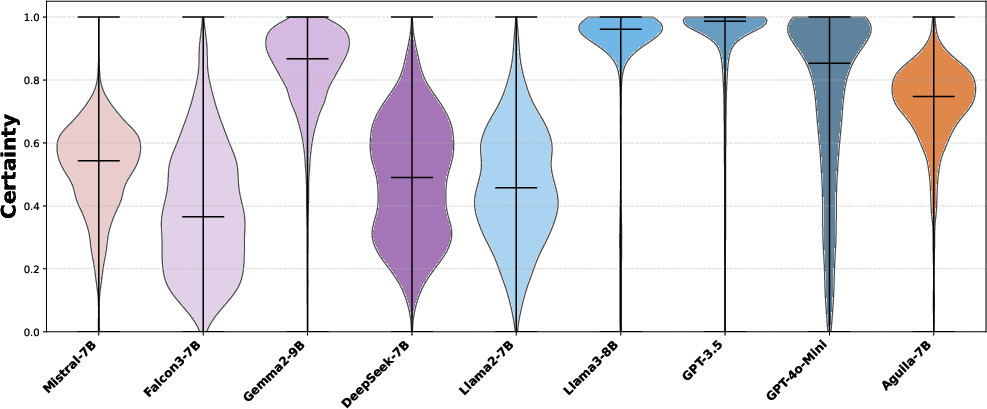
- GPT models (like GPT-3.5 and GPT-4o-mini) are very confident and stable in their votes and show a tight cluster on the political map.
- Smaller open-source models vary more, sometimes changing answers with slight rewording and showing lower confidence.
- Robust across countries and prompts:
- The same broad bias patterns show up in the Netherlands, Norway, and Spain.
- Even when the prompt is rephrased, the overall left-leaning tendency remains.
Why this matters:
- LLMs are used for answering questions, summarizing news, and even giving advice. If they consistently lean toward certain political views, they could influence what people read and think, especially when they present a single, confident answer.
- Understanding and measuring these biases helps make AI systems fairer, more trustworthy, and better for democratic societies.
What’s the impact and what comes next?
This work offers a transparent, scalable way to check political bias using real-world voting, not just small quizzes. It can be expanded to more countries and updated over time to track how models change. The approach can guide:
- Audits of political bias in new and existing AI models.
- Better training and safety methods to reduce unfair bias.
- Public and policy discussions about how AI should be used in political information and decision-making.
In short, the paper shows a reliable way to place AI models on a well-known political map and reveals a strong pattern: today’s LLMs tend to be center-left and liberal on social issues, with clear negative bias toward right-conservative parties. This is important to know if we want AI tools that are balanced and fair for everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper and could guide future research:
- External validity across political systems: The benchmark covers three Western European, multi-party democracies. It does not test two-party systems (e.g., U.S.), non-European contexts, or legislatures with different procedures (unicameral vs. bicameral, authoritarian settings). Evaluate whether the observed center-left tendency generalizes beyond these settings.
- Legislative artifact scope: The analysis uses parliamentary motions only. Assess whether results hold for other roll-call artifacts (e.g., bills, amendments, confidence votes, procedural votes), which may differ in ideological content and strategic voting behavior.
- Topic-level control and stratification: Motions are treated uniformly without topic annotations. Introduce policy-topic labels (economy, immigration, environment, civil liberties, etc.) to disentangle issue-specific biases and verify whether model leanings vary across CHES-relevant dimensions.
- Base-rate calibration: The paper does not report the global base rate of “for” vs. “against” across motions. Quantify and correct for class imbalance to ensure that alignment patterns are not driven by a model’s generic tendency (e.g., to favor “for”) rather than ideology.
- CHES mapping validity and temporal alignment: The PLS mapping is trained on party votes to predict CHES positions, but CHES scores may be time-specific and party ideologies drift. Align CHES survey years with vote periods and assess sensitivity of LLM placements to CHES year choice.
- Generalization of vote-to-ideology mapping: The supervised mapping (PLS/ridge) is validated on parties, but not on synthetic actors like LLMs. Test alternative mappings (e.g., ideal point/IRT models, multidimensional scaling) and quantify uncertainty bands for LLM coordinates.
- Strategic/procedural voting confounds: Parties sometimes vote strategically (coalition discipline, procedural constraints, tactical abstentions). Identify and exclude or reweight such votes to avoid conflating strategic behavior with ideology.
- Treatment of abstentions and non-binary choices: Abstention is modeled only for Spain; Norway and the Netherlands may have different rules (e.g., absence, paired voting). Provide a consistent, cross-country handling of abstentions and non-votes; extend EBI to three-class decisions.
- Entity Bias Index (EBI) handling of abstentions: The EBI formula is binary (1/0), yet Spanish prompts include “abstain.” Specify how abstentions are encoded for EBI, and extend the metric to quantify bias among all three choices (“for/against/abstain”).
- Statistical significance and uncertainty: Heatmaps and CHES placements are descriptive. Add confidence intervals, bootstrapping over motions, multiple comparison corrections, and significance tests to distinguish robust effects from noise.
- Motion text paraphrase robustness: The brittleness study paraphrases prompts (instruction) for NL/NO but not the motion texts themselves, and excludes Spain. Test robustness to paraphrases of motion content across all three countries.
- Prompt design sensitivity beyond “for/against”: Explore richer prompt instructions (e.g., ask for rationale, allow “cannot decide,” enforce neutrality) and system prompts (e.g., “avoid political persuasion”) to quantify how safety/guardrail policies affect measured bias.
- Refusal and safety-policy confounds: RLHF policies often discourage political persuasion, which may produce refusals or generic disclaimers. Systematically measure refusal rates, categorize refusal types, and estimate their impact on perceived ideological/party alignment.
- Tokenization and certainty metric validity: The “certainty” metric uses single tokens “for”/“against,” which may be segmented differently across models/languages or preceded by space tokens. Standardize per-language token handling (e.g., sum logprobs across all sub-tokens, handle leading spaces) and test temperature/calibration effects.
- Temperature and sampling effects: All experiments use temperature=0. Assess whether conclusions persist under typical deployment settings (non-zero temperature, nucleus/top-k sampling) and how sampling affects certainty and agreement metrics.
- Language proficiency confound: Cross-lingual model performance (Dutch, Norwegian, Spanish) is not disentangled from ideology. Measure language comprehension baselines (e.g., reading comprehension or classification tasks) and control for language proficiency when attributing ideological bias.
- Translation pipeline clarity: The paper includes English translations of prompts for exposition, but it is unclear whether LLMs were prompted in the original languages or English. Explicitly document the language used for inputs and evaluate translation-induced bias by comparing native-language vs. translated-motion experiments.
- Sponsor identity leakage in baseline: The “operative clauses only” rule aims to avoid framing, but it is not verified whether sponsor identity or partisan cues remain in the motion text. Audit and remove residual identifiers to ensure the baseline truly lacks entity cues.
- Content distribution bias by proposer: Even without sponsor attribution, topic distributions may correlate with the parties proposing motions (e.g., left parties proposing more social-policy motions). Balance or reweight motions by topic/party proposer to isolate ideological effects from content availability.
- Party-level aggregation decisions: Spanish party positions are derived from majority votes within parties, and NL merges GL–PvdA (with 0 when they disagreed) and backfills NSC using one leader’s earlier votes. Quantify sensitivity of results to these aggregation heuristics.
- Model range and size scaling: The evaluated models exclude several prominent systems (e.g., GPT-4 full, Claude, Gemini, larger Llama variants). Expand coverage to test whether the observed patterns persist at frontier-scale and across diverse training regimes.
- Causal sources of bias: The paper documents bias but does not probe its origins (pretraining corpora, RLHF data, safety policies). Conduct ablation studies (pre-RLHF vs. post-RLHF, filtered vs. unfiltered corpora) and causal analyses to identify primary drivers.
- Mitigation experiments: While mitigation is suggested as future work, no techniques are tested. Evaluate interventions (e.g., balanced fine-tuning, counterfactual regularization, calibration, debiasing prompts) and measure trade-offs in performance vs. neutrality.
- Longitudinal drift analysis: The datasets enable tracking over time but no longitudinal results are presented. Monitor model versions chronologically to quantify ideological drift and stability across updates and training cycles.
- Real-world task transfer: The study does not assess whether voting-alignment bias translates to downstream tasks (search, summarization, QA, content moderation). Test cross-task transfer to estimate user-facing impacts of documented ideological patterns.
- Normative target definition: The paper does not specify a normative goal (e.g., ideological neutrality, pluralistic representation, or transparency about model stance). Articulate measurable neutrality/pluralism targets and design metrics to audit compliance.
Practical Applications
Overview
Based on the paper’s datasets (PoliBiasNL/NO/ES), evaluation framework (ideology via CHES projection with PLS; Entity Bias Index; certainty metric; prompt brittleness tests), and findings (consistent center-left/GAL tendencies; systematic negative bias toward right-conservative parties; robustness across paraphrases), the following practical applications emerge across industry, academia, policy, and daily life.
Immediate Applications
These can be deployed with current data, methods, and infrastructure described in the paper.
- Bias audit pipeline for LLM vendors and integrators (software)
- Use: Pre-release and post-release ideological auditing of foundation and domain LLMs; generate model cards reporting CHES placement, party agreement heatmaps, EBI, and certainty distributions.
- Tools/workflows: Scrapers + PoliBias datasets; PLS-based CHES projection; EBI computation; certainty metric; prompt-brittleness suite; dashboard summarizing drift across releases.
- Assumptions/dependencies: Availability/quality of parliamentary records; stable CHES scores for included parties; access to token probabilities/logprobs; temperature-controlled inference (e.g., temp=0) for reproducibility.
- Election-period risk assessment for chat assistants and search (platforms, software, policy compliance)
- Use: Verify assistants don’t systematically favor/penalize specific parties or blocs; demonstrate compliance with election integrity commitments.
- Tools/workflows: Scheduled audits on PoliBias datasets; regression thresholds/alerts for negative EBI toward any party; automated certificate/report for internal governance and regulators.
- Assumptions/dependencies: Clear internal thresholds for acceptable divergence; legal guidance on “political neutrality” per jurisdiction.
- Guardrail policies for political queries (software, content platforms)
- Use: Route political prompts through “neutral mode” that mitigates entity bias and reduces unilateral advice (e.g., mask party identifiers or return multiperspective analyses).
- Tools/workflows: Entity-masking at inference; multi-perspective response templates; enforcement of abstain/decline policies on explicit advocacy; calibration using EBI and certainty.
- Assumptions/dependencies: Acceptable UX trade-offs (explanations vs. abstentions); precise detection of political content.
- Balanced content summarization for newsrooms and civic platforms (media, education)
- Use: Generate synopses of parliamentary motions with multi-party viewpoints; reduce single-perspective framing in automated summaries.
- Tools/workflows: Retrieve motions; summarize operative clauses; add “positions by party” panels based on historical voting agreement; expose CHES-based context.
- Assumptions/dependencies: Accurate mapping of motions to issues; guard against hallucination by retrieval-augmented generation.
- Model procurement and vendor due diligence (enterprise, finance, public sector)
- Use: Add ideological bias KPIs (CHES location, EBI, certainty) to supplier scorecards to manage reputational/regulatory risk.
- Tools/workflows: Vendor self-attestation with reproducible scripts; independent re-audit using PoliBias harness.
- Assumptions/dependencies: Contractual rights to test models; consistent evaluation seeds/prompts.
- Training data curation and RLHF calibration (LLM developers)
- Use: Identify where instruction/RLHF pipelines induce asymmetric political behavior; rebalance RLHF preference data; add counterfactual entity exposure during training.
- Tools/workflows: Before/after EBI and CHES tests; entity-perturbation augmentation; targeted rejection sampling or loss regularizers encouraging entity-invariance.
- Assumptions/dependencies: Access to training/RLHF pipelines; clarity on target neutrality criteria.
- Fairness diagnostics for political downstream tasks (moderation, misinformation detection)
- Use: Detect ideology-sensitive errors (e.g., uneven flagging of content across parties); calibrate classifiers for equalized performance.
- Tools/workflows: Counterfactual testing via party-swaps; threshold calibration guided by EBI; add abstain class when uncertain (as in Spanish setting).
- Assumptions/dependencies: Task-specific labels; tolerance for abstentions in moderation queues.
- Academic replication and course modules (academia, education)
- Use: Methods labs on cross-national bias auditing; CHES mapping; prompt brittleness; entity-bias measurement.
- Tools/workflows: Open scraping pipeline; evaluation notebooks; reproducible seeds; class assignments on extending to additional sessions/years.
- Assumptions/dependencies: Institutional access to LLM APIs/GPUs; language coverage for local parliaments.
- Civic transparency portals (policy, civil society)
- Use: Public dashboards that visualize where major LLMs sit in CHES space; show agreement with parties; track drift over time.
- Tools/workflows: Monthly static evaluations; explainers on CHES axes; downloadable reports for journalists/NGOs.
- Assumptions/dependencies: Responsible framing to avoid “rating” legitimacy; periodic dataset refreshes.
- Customer support and public service chatbots handling policy topics (government services, healthcare payers, utilities)
- Use: When asked about policy-sensitive topics (e.g., healthcare coverage reforms), switch to neutral retrieval of official sources and multi-perspective summaries.
- Tools/workflows: Topic detection; retrieval-only mode with citations; entity masking; abstain when outside scope.
- Assumptions/dependencies: High-quality, up-to-date official documents; routing logic that minimizes false positives/negatives.
- Red teaming and safety evaluations (software safety)
- Use: Stress-test models with party-attributed counterfactual prompts to uncover asymmetric treatments or overconfident advice.
- Tools/workflows: EBI “spikes” triaged as safety bugs; add paraphrase-robustness checks; integrate into CI pipelines.
- Assumptions/dependencies: Organizational maturity for safety triage; acceptance criteria for release gating.
- Journalism and fact-check support (media)
- Use: Cross-check that narrative summaries do not mirror a single bloc; disclose model’s audited ideological footprint along with articles that use LLM assistance.
- Tools/workflows: Editorial checklists; auto-insert “viewpoint diversity meter” based on agreement scores with multiple parties.
- Assumptions/dependencies: Editorial policies; audience comprehension of CHES/GAL–TAN axes.
Long-Term Applications
These require further research, scaling, standardization, or development.
- Cross-national, real-time bias observatories (policy, academia, platforms)
- Vision: Global monitoring of LLM ideological positions across dozens of legislatures with streaming updates and drift alerts.
- Needed: Expanded scraping/normalization; multilingual robustness; governance for open reporting; funding and oversight.
- Standards and certifications for political bias reporting (regulators, standards bodies)
- Vision: ISO/IEEE/NIST norms requiring CHES-style placement, party-agreement matrices, EBI, and brittleness metrics in model cards; certification for election-period deployments.
- Needed: Consensus on acceptable ranges; test suites; auditability for closed models; harmonization with EU AI Act/NIST RMF.
- Mitigation frameworks with closed-loop optimization (LLM developers)
- Vision: RLHF or DPO objectives that directly penalize entity-driven swings and extreme ideological skew; ensemble balancing to present diverse viewpoints.
- Needed: Objective definitions of neutrality/pluralism; avoiding “both-sidesism” on rights-based issues; user-study validation of perceived fairness.
- Multi-dimensional political embeddings beyond 2D (academia, software)
- Vision: From CHES to higher-dimensional policy spaces (e.g., immigration, environment, social welfare, EU integration); issue-aware positioning.
- Needed: Issue-tagging of motions; topic modeling; expert labels across countries; validation against roll-call and survey data.
- Policy-compliant assistant modes (government, platforms)
- Vision: Context-aware “civic service mode” that limits persuasion, shows plural views, and defaults to official sources; heightened controls during election blackouts.
- Needed: Legal clarity across jurisdictions; robust detection of political persuasion intent; transparent UX.
- Bias-aware retrieval and summarization stacks (software, media)
- Vision: Indexes that track ideological provenance of sources; summarizers that intentionally balance viewpoints; “dial-a-diversity” controls for users.
- Needed: Source-level ideology inference; user studies on comprehension and trust; guardrails against laundering fringe content.
- Dataset and benchmark expansion to underrepresented polities (global south, local councils)
- Vision: Coverage of municipalities, regional parliaments, and countries with sparse data to avoid Eurocentric bias.
- Needed: Open data reforms; OCR/translation pipelines; collaboration with local institutions; quality assurance.
- Compliance analytics for advocacy and ad-tech (policy, ads, platforms)
- Vision: Verify that targeting and generation systems do not differentially favor parties; produce compliance proofs for regulators.
- Needed: Privacy-preserving audit methods; causal analyses linking outputs to outcomes; coordination with election authorities.
- Educational tools for civics and AI literacy (education)
- Vision: Interactive simulators where students place models and parties on CHES axes, test prompt brittleness, and explore entity bias.
- Needed: Simplified UIs; curated lesson plans; localized datasets; accessibility features.
- Enterprise risk management for regulated sectors (finance, healthcare)
- Vision: Continuous monitoring that model-generated policy commentary (e.g., ESG, healthcare policy) avoids partisan slant that could create compliance or reputational risks.
- Needed: Domain-specific policy taxonomies; alerting thresholds; auditor training.
- Research on causality of political bias in training data (academia, LLM developers)
- Vision: Trace ideational patterns back to pretraining corpora and RLHF preferences; design data curation that narrows unintended skew.
- Needed: Data-lineage transparency; controlled pretraining experiments; synthetic counterfactual datasets.
- Personalized viewpoint diversity controls (consumer apps)
- Vision: User-adjustable “ideological balance” settings that expand or contract the range of perspectives presented, with transparency about trade-offs.
- Needed: Clear UX; safeguards against echo chambers; normative guidance on minimum diversity floors.
Key Assumptions and Dependencies (cross-cutting)
- Parliamentary data completeness and quality vary by country; translation and preprocessing (e.g., extracting operative clauses) affect fidelity.
- CHES provides a widely used but simplified 2D space; real-world ideology is multi-dimensional and evolves over time.
- Votes reflect party discipline and strategic behavior; alignment with votes is a proxy for ideology, not an absolute ground truth.
- Token probability access and deterministic decoding are required for certainty metrics; some APIs may restrict logprob visibility.
- EBI currently measures for/against (plus abstain in Spain); nuanced positions (amend, procedural votes) are not captured.
- Ethical and legal constraints: neutrality expectations differ by jurisdiction; avoiding enforced symmetry on rights-related content is essential.
- Model updates can shift behavior; longitudinal monitoring and versioned reporting are necessary to maintain trust.
These applications leverage the paper’s concrete assets—large, real parliamentary datasets; robust cross-lingual evaluation; interpretable ideology mapping; and entity-bias diagnostics—to enable immediate auditing and guide longer-term standards, mitigations, and public-interest tooling.
Glossary
- Abstention: A parliamentary voting option where a member neither supports nor opposes a motion. "This version of a prompt is also extended with (`abstain') option for testing against the Spanish benchmark to accurately reflect the real voting environment."
- Automation bias: The tendency of humans to over-rely on automated systems or decisions even when they may be wrong. "findings that humans are prone to automation bias~\cite{Simon2020}"
- Chapel Hill Expert Survey (CHES): An expert survey that assigns political parties positions on ideological dimensions, often used to map left–right and socio-cultural axes. "a shared two-dimensional CHES (Chapel Hill Expert Survey) space"
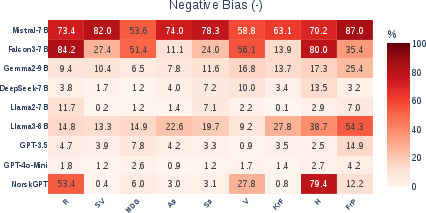
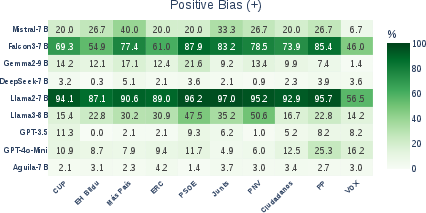
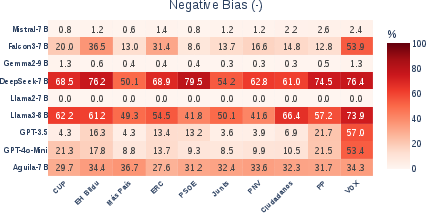
- Counterfactual attribution: Technique where the entity associated with an input is altered to analyze causal effects on model predictions. "Entity Bias Index (EBI) heatmaps for positive and negative bias in LLMs, computed via counterfactual attribution of voting motions in the benchmark datasets."
- Counterfactual prompts: Prompts created by changing specific entities while keeping other text constant to test model sensitivity. "Prior work commonly measures such bias using counterfactual prompts in which entities are swapped while the surrounding text is held fixed"
- Economic left--right axis: The dimension representing economic ideology from left (state intervention, redistribution) to right (market-oriented). "consisting of an economic left--right axis and a socio-cultural GAL--TAN axis."
- Entity Bias Index (EBI): A metric that captures how party attribution changes a model’s support for motions relative to a no-entity baseline. "To quantify entity bias, we define the Entity Bias Index (EBI)"
- Entity bias: Systematic deviation in model outputs caused by the presence of specific entities rather than content. "Entity bias refers to systematic differences in model outputs driven by the presence of particular named entities or descriptors rather than by the underlying content of the input"
- GAL--TAN axis: A socio-cultural ideological axis from libertarian/green/alternative to traditional/authoritarian/nationalist. "the GAL--TAN dimension (
Green--Alternative-- Libertarian' vs.\Traditional--Authoritarian--Nationalist')" - Ideological drift: Changes over time in a model’s inferred ideological position. "enabling longitudinal analyses of ideological drift in LLMs."
- Leave-one-out validation: A cross-validation method where each sample is left out once for validation while training on the rest. "leave-one-out validation shows that more than 81--97\% of the variance in the CHES left--right and GAL--TAN dimensions can be recovered from voting patterns alone."
- Logit scores: The raw pre-softmax outputs of a model that represent unnormalized log-probabilities. "applying the softmax function to the model's logit scores for these tokens."
- Masked LLMs: Models trained to predict hidden tokens in text, such as BERT. "Inspired by bias metrics used for masked LLMs~\cite{parra-2024-unmasked,nadeem2020stereosetmeasuringstereotypicalbias}, our metric evaluates the probabilities assigned to each token within the model's responses."
- Partial Least Squares (PLS) regression: A regression technique that finds components maximizing covariance between predictors and responses. "We use Partial Least Squares (PLS) regression~\cite{PLS} to estimate this mapping."
- Political compass tests: Surveys that place respondents on ideological axes based on their agreement with policy statements. "Political bias in generative LLMs has mostly been studied using political compass tests and voting advice applications"
- Political motion: A formal proposal submitted in parliament requesting action or expressing a stance. "A typical political motion includes a title, an introduction or preamble, several recitals outlining considerations, and operative clauses proposing actions."
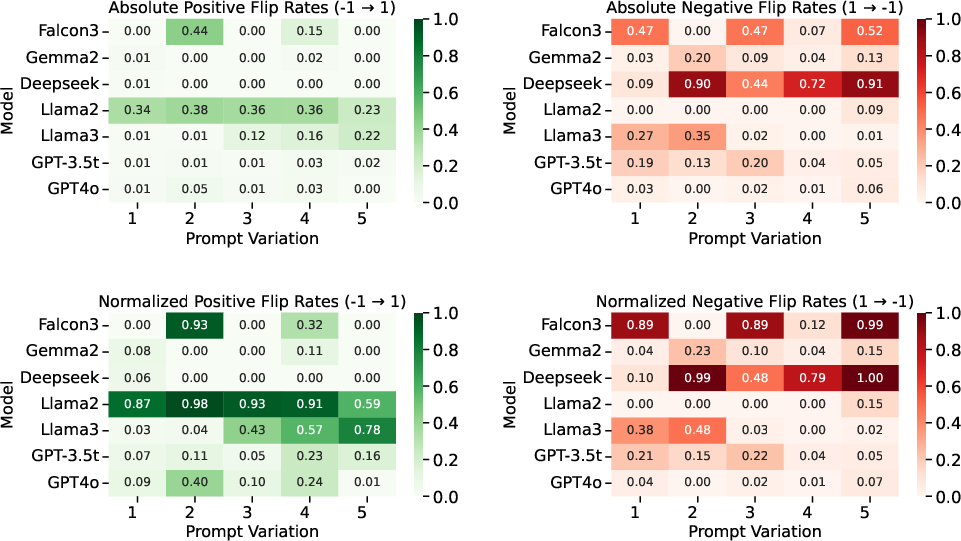
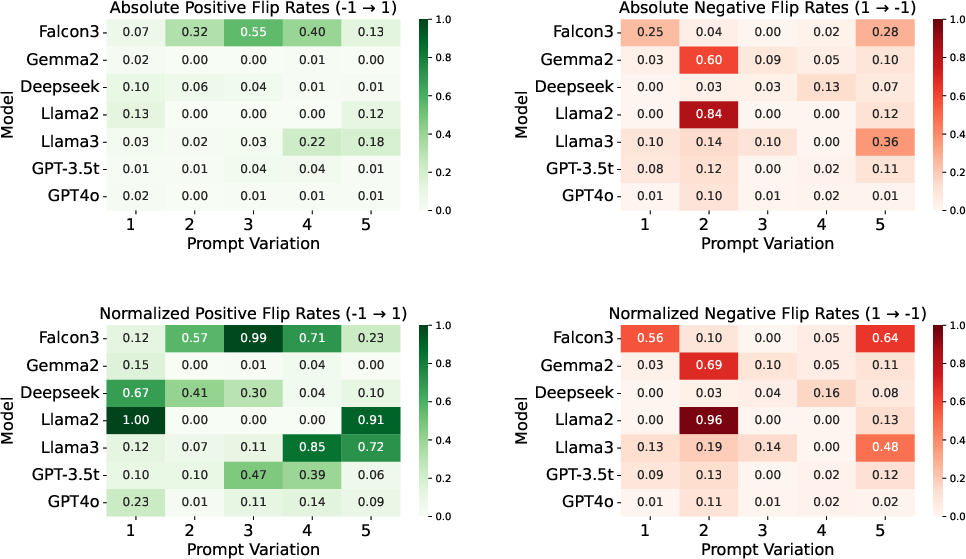
- Prompt brittleness: Sensitivity of model outputs to minor changes in prompt wording. "we observe that smaller models exhibit moderate prompt brittleness, occasionally flipping their predictions across variants"
- Reinforcement learning from human feedback: Training method where models are optimized using feedback from human evaluators. "Mitigation strategies, including reinforcement learning from human feedback and related techniques, have been explored but remain only partially effective"
- Ridge regression: A linear regression with L2 regularization to prevent overfitting. "We also trained a ridge regression model~\cite{ridge} as an alternative supervised mapping."
- Roll-call-based approach: An analysis method using recorded votes (roll calls) to study behavior or ideology. "our roll-call-based approach shows that similar tendencies persist across the full breadth of real-world legislative decisions"
- Softmax function: A function that converts a vector of logits into a probability distribution. "we compute the probabilities of the tokens
for' andagainst' by applying the softmax function to the model's logit scores for these tokens." - Supervised mapping: Learning a function from inputs to outputs using labeled data. "Recovering CHES positions from voting behaviour can be formulated as a supervised mapping problem"
- Temperature parameter: A control in generative models that affects randomness in sampling. "we set the temperature parameter to 0 for every model evaluated."
- Violin plots: A visualization combining box plot and kernel density to show distribution. "The violin plots in Fig.~\ref{fig:violin_plot} illustrate the distribution of normalised probabilities"
- Voting advice applications (VAA): Tools that advise voters on party alignment based on questionnaire responses. "political compass tests and voting advice applications"
- Zero-shot approach: Using a model to perform a task without task-specific training examples. "employing a zero-shot approach to prompt an LLM."
Collections
Sign up for free to add this paper to one or more collections.

