Motion Attribution for Video Generation
Abstract: Despite the rapid progress of video generation models, the role of data in influencing motion is poorly understood. We present Motive (MOTIon attribution for Video gEneration), a motion-centric, gradient-based data attribution framework that scales to modern, large, high-quality video datasets and models. We use this to study which fine-tuning clips improve or degrade temporal dynamics. Motive isolates temporal dynamics from static appearance via motion-weighted loss masks, yielding efficient and scalable motion-specific influence computation. On text-to-video models, Motive identifies clips that strongly affect motion and guides data curation that improves temporal consistency and physical plausibility. With Motive-selected high-influence data, our method improves both motion smoothness and dynamic degree on VBench, achieving a 74.1% human preference win rate compared with the pretrained base model. To our knowledge, this is the first framework to attribute motion rather than visual appearance in video generative models and to use it to curate fine-tuning data.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Motion Attribution for Video Generation”
1) What is this paper about?
This paper looks at how AI models that make videos learn how things move. The authors introduce a tool they call MOTIVE (short for “MOTIon attribution for Video gEneration”). MOTIVE helps answer a simple but important question: which training clips teach the model good motion, like smooth movement and realistic physics, and which ones make it worse?
In short, they show how to trace the motion you see in an AI‑generated video back to the specific training clips that most influenced that motion. Then, they use that information to pick better training data and improve the model’s movement.
2) What questions are they trying to answer?
They focus on easy-to-understand questions like:
- Which training videos most affect how the AI moves objects and the camera in new videos?
- How can we separate motion (how things move over time) from appearance (how things look in a single frame)?
- Can choosing the right training clips make the model’s motion smoother and more realistic, even if we use less data?
3) How did they study it? (Methods explained simply)
Think of training an AI video model like teaching a robot to draw movies. The robot watches lots of clips and learns patterns. MOTIVE figures out which clips taught the robot to move well.
Here’s how it works in everyday terms:
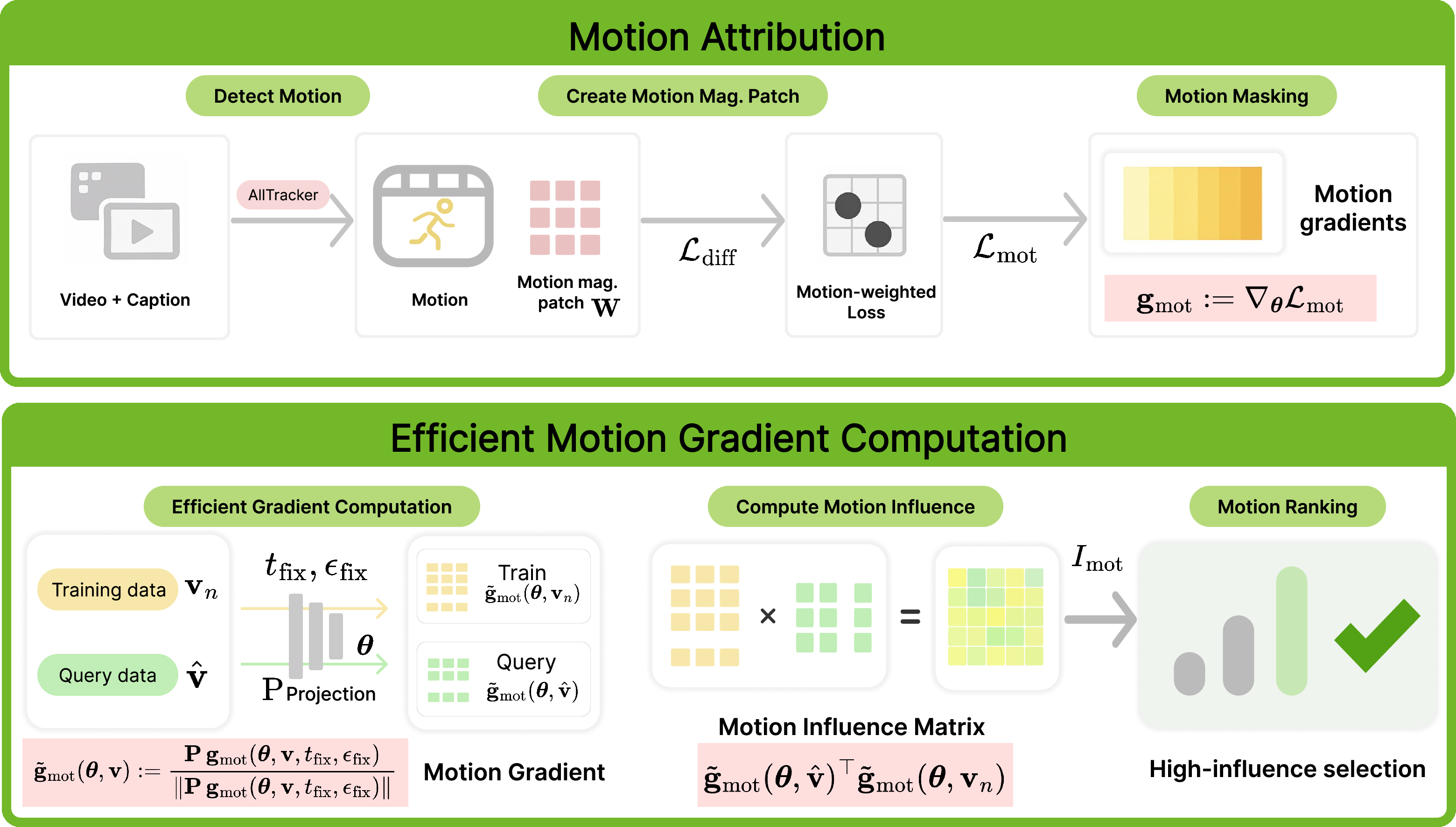
- Diffusion video models: These models start with noisy videos (like TV static) and learn to clean them up step by step until a clear, moving scene appears. The model learns by comparing what it produced with what a real video looks like and adjusting itself to do better next time. Those adjustments are called “gradients,” which you can think of as tiny arrows pointing the way the model should change.
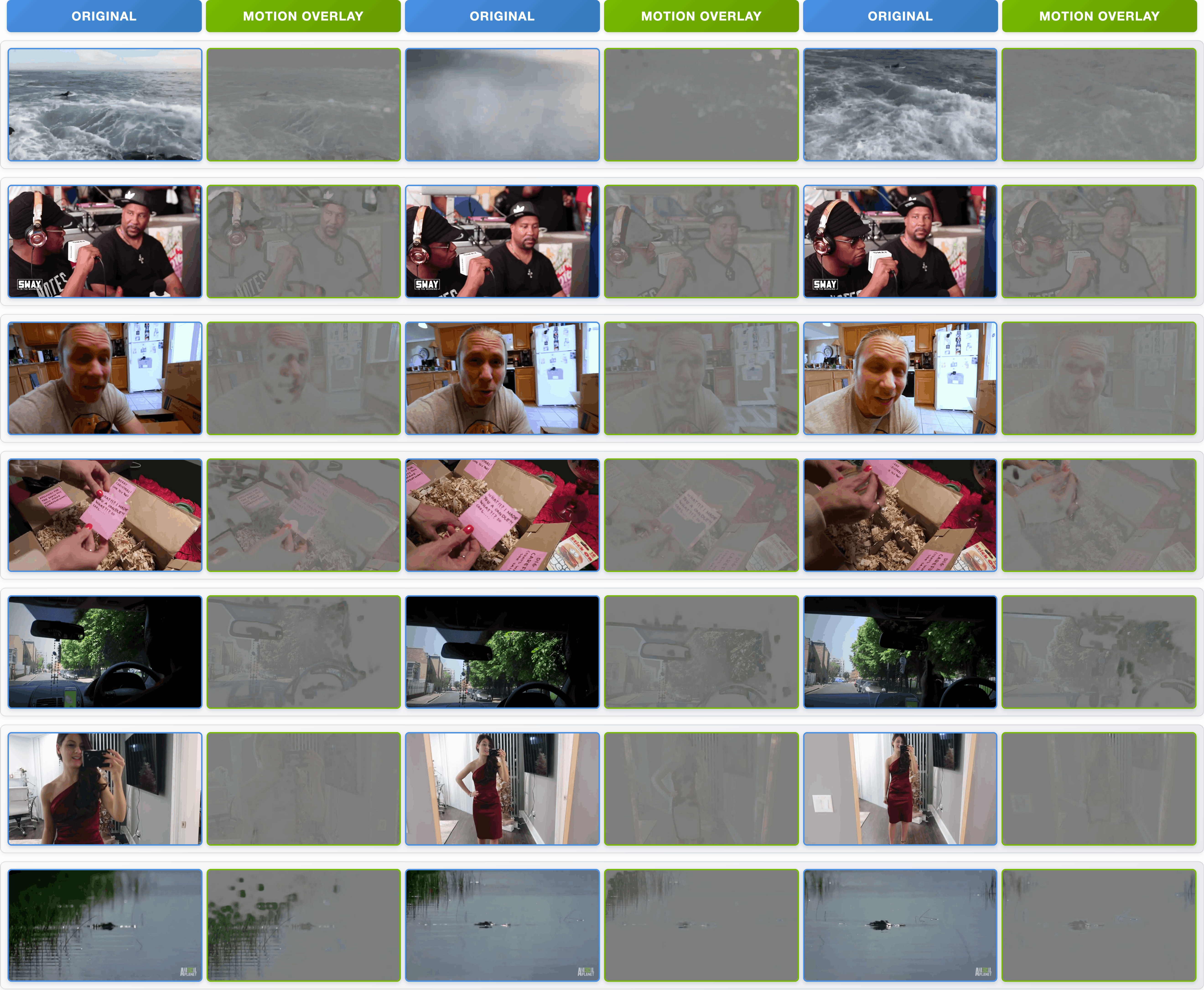
- Motion vs. appearance: If you only look at whole frames, you might confuse “what it looks like” with “how it moves.” MOTIVE instead puts a spotlight on the parts of the video where things are actually moving and dims the static background. It does this with motion masks.
- Motion masks: The authors use a tool called AllTracker to find motion between frames. Imagine placing tiny arrows on each pixel that show how it moved from one frame to the next. Bigger arrows mean stronger motion. MOTIVE uses these arrows to build a “motion mask” that highlights only the moving regions. Then, it measures how training clips affect the model’s learning mostly in those highlighted areas.
- Measuring influence with gradients: To see which training clip matters for motion, MOTIVE looks at how much the model’s internal “change arrows” (gradients) line up between a test video (the video you care about) and a training video (a clip from the training set). If they point in similar directions, that training clip helped the model learn the kind of motion in the test video.
- Fairness for clip length: Longer videos naturally produce bigger numbers when you add things up. MOTIVE avoids giving longer clips an unfair advantage by dividing by the number of frames, so short and long clips are compared fairly.
- Making it fast and practical: Full gradients are huge (think millions or billions of numbers). The authors shrink each gradient into a small “fingerprint” using a clever random projection technique (Fastfood), which keeps the important shape of the information but takes much less space. They also share the same test settings across clips to reduce randomness, which makes rankings more stable and faster to compute.
- Picking data to fine-tune: Once they have influence scores for lots of training clips, they rank them and pick the top ones. If they have several test motions (like rolling, bouncing, spinning), they use a simple “majority vote” idea: a training clip gets selected if it was influential for many of those motions.
4) What did they find and why is it important?
Main results:
- Better motion with less data: Using only the top 10% of training clips (chosen by MOTIVE), the model’s motion looked more dynamic and realistic than using random clips—and even beat the model fine-tuned on all the data in some motion metrics.
- Measured improvements: On the VBench evaluation (a standard test set), MOTIVE boosted “dynamic degree” (how lively and noticeable motion is) to about 47.6%, compared to 41.3% with random selection and 43.8% with motion‑unaware methods. It also kept motion smoothness and visual quality high.
- People preferred it: In human tests where participants watched pairs of generated videos and picked the one with better motion, MOTIVE’s results won about 74% of the time against the original base model. It also won more than half the time against the full fine‑tuned model.
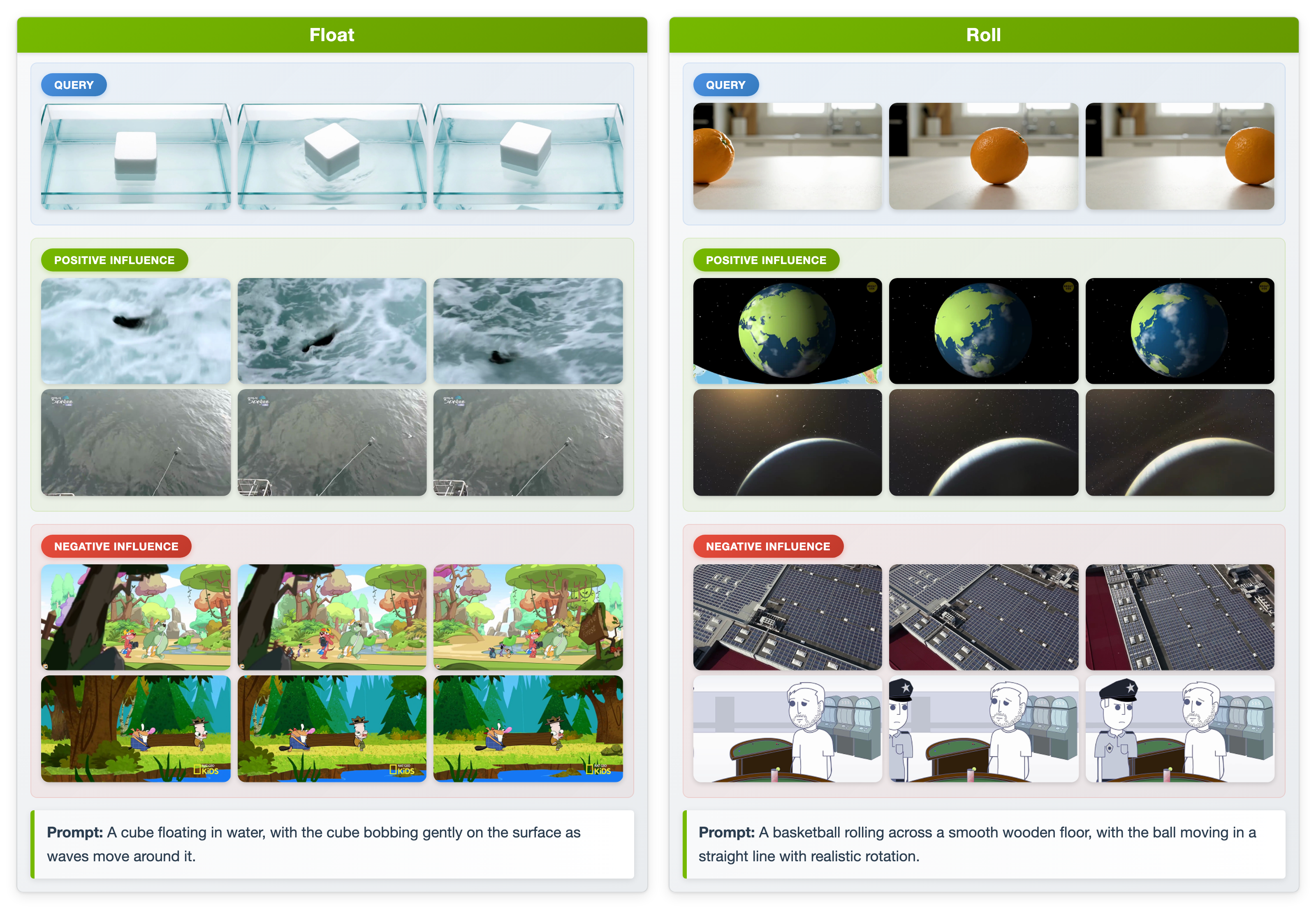
- It picks the right clips: MOTIVE tends to rank training clips that show clear, physical motion (like rolling or floating) highly, and it pushes down clips that don’t teach useful motion (like mostly static shots, only camera movement, or simplistic cartoons).
Why this matters:
- Motion is the heart of video. It’s not enough for videos to look pretty—they need to move in believable ways. MOTIVE shows we can improve motion by carefully choosing the right training data, not just by changing the model.
- Saves time and compute: Training on better‑chosen clips means you can get good motion with fewer examples, saving resources.
- Makes models more understandable: MOTIVE gives a way to explain “why does the model move like this?” by pointing to specific training clips.
5) What’s the bigger picture?
Implications and impact:
- Smarter data curation: Instead of throwing every video into training, teams can use MOTIVE to pick the clips that will teach the model the motions they want (like smooth spins, realistic bounces, or consistent slides).
- More realistic physics: With better motion learning, AI‑generated videos can follow natural movement rules more closely, which helps everything from animation to robotics simulations and educational content.
- Scales to big models: The method is designed to work at modern, large‑model scales, where storing full gradients is impossible. The “gradient fingerprint” trick keeps it practical.
- Limitations and future work: MOTIVE relies on motion tracking, which can struggle with occlusions (when objects block each other) or very subtle movement. Camera‑only motion is also tricky to separate. Better trackers and extra signals (like camera pose) could help in the future.
In summary, MOTIVE is a practical, motion‑focused way to discover which training clips teach a video model to move well, and it uses that knowledge to make AI‑generated videos smoother, more consistent, and more physically believable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of gaps the paper leaves unresolved that future work could address to strengthen motion attribution for video generation and its impact on fine-tuning.
- Causal validation of attribution: The study demonstrates improvements using top-ranked subsets but does not quantify per-clip causal effects. Design controlled inclusion/exclusion experiments to measure effect sizes of individual clips on motion metrics and assess calibration of attribution scores to actual causal impact.
- Disentangling camera vs. object motion: Motion masks are computed from optical flow magnitude and do not separate egomotion from scene/object motion. Integrate camera pose estimation, video stabilization, or SLAM-based egomotion to partition influence scores by motion type and evaluate attribution fidelity for each.
- Sensitivity to the motion tracker: Motion saliency relies solely on AllTracker. Systematically compare alternative flow/trackers (e.g., RAFT, GMFlow, FlowFormer, TAPIR) and quantify how tracker failures (occlusion, transparency, low texture) propagate to influence rankings; incorporate tracker uncertainty/confidence into weighting.
- Directionality and kinematics beyond magnitude: Masks use flow magnitude, ignoring direction, velocity profiles, acceleration, periodicity, and interactions. Extend weighting to kinematic features (e.g., direction fields, acceleration estimates, trajectory smoothness) and interaction indicators (contact/collision events) to better capture motion semantics and physical plausibility.
- Use of tracker confidence/visibility: AllTracker provides visibility/confidence channels, but the method does not leverage them in weights. Incorporate these signals to attenuate unreliable regions and improve robustness of motion-weighted gradients.
- Text conditioning effects: Motion attribution is computed in the presence of text conditioning but does not attribute the role of text tokens/metadata (e.g., fps) on dynamics. Develop conditioning-aware attribution that decomposes influence into data and text components; assess how prompt semantics modulate motion influence.
- Generalization across architectures and objectives: Experiments focus on Wan2.x DiT-style latent diffusion. Evaluate the method on diverse generators (3D U-Nets with temporal convolutions, autoregressive video models, rectified flow/consistency training) to test architectural robustness.
- Scalability to pretraining-scale corpora: Attribution is demonstrated on 10k subsets; feasibility at millions of clips during pretraining remains unclear. Explore streaming/incremental projections, batched common randomness, and scalable storage/indexing to maintain stability and throughput at full-dataset scale.
- Risk of overfitting/forgetting: Motion-targeted fine-tuning may degrade other capabilities (appearance fidelity, compositionality, long-horizon coherence). Measure cross-metric trade-offs and catastrophic forgetting, and develop regularization or multi-objective selection strategies.
- Timestep selection criterion: The single fixed timestep (t=751) is chosen heuristically. Provide a principled, model/data-dependent criterion for timestep selection or learned timestep weighting, and analyze bias–variance trade-offs vs. multi-timestep averaging.
- Projection dimension and seed sensitivity: While 512-D Fastfood projections preserve rankings moderately, the link to downstream fine-tuning gains is not quantified. Study how projection dimension and random seeds affect final performance and derive guidelines for selecting projection parameters.
- Frame-rate and temporal scaling: The pipeline standardizes videos to 16 fps and 81 frames; sensitivity to fps mismatches and temporal resampling is not explored. Develop fps-aware normalization and assess influence stability under varying frame rates and temporal scaling.
- Diversity and redundancy in selection: Majority-vote aggregation may favor near-duplicate clips and miss diverse exemplars. Incorporate diversity-aware criteria (e.g., submodular optimization, determinantal point processes) to ensure coverage of motion variations without redundancy.
- Negative influence handling: Negative examples are identified qualitatively, but the paper does not formalize removal strategies. Evaluate data filtering based on negative scores and quantify gains from excluding detrimental clips (and the risk of excluding useful edge cases).
- Objective physical plausibility metrics: VBench’s dynamic degree and smoothness do not directly evaluate physics (e.g., acceleration continuity, contact dynamics, conservation properties). Introduce physics-based metrics and test whether attribution-guided selection improves physical correctness.
- Long-horizon and complex interaction motion: Queries target short, isolated motions; attribution for multi-object interactions, scene changes, and long-horizon (>81 frames) dynamics is untested. Extend attribution to longer windows and interaction-aware masks (e.g., object-centric tracking/segmentation).
- Component-wise influence: Fine-tuning updates only the DiT backbone. Analyze the influence distribution across modules (VAE, temporal attention, text encoder) and compare full vs. partial/LoRA tuning to identify where motion learning is most sensitive.
- Checkpoint dynamics of influence: Influence is computed at the final checkpoint only. Track how influence rankings evolve during fine-tuning to determine when selection is most predictive and whether early-attributed subsets differ from late-attributed ones.
- Cross-domain robustness: Attribution behavior across domains (cartoons, egocentric, sports, medical, low-light) is not evaluated. Quantify domain-specific biases and adapt motion masks/selection to domain characteristics.
- Mask–latent alignment: Bilinear downsampling maps pixel-space motion to latent-space grids without accounting for VAE distortions. Assess alignment errors and consider latent-aware motion estimation or learned pixel–latent warp compensation.
- Conditioning-aware aggregation across queries: Majority vote with percentile thresholds is heuristic. Optimize per-query thresholds, weight queries by relevance, and calibrate cross-query scores to improve selection across mixed motion targets.
- Robustness to common randomness: Sharing noise/time across train/test stabilizes rankings but may introduce coupling artifacts. Report confidence intervals across multiple noise seeds and test robustness of rankings and downstream gains.
- Retrieval or guidance at inference: The paper focuses on fine-tuning; it does not explore inference-time retrieval/guidance using high-influence exemplars (e.g., exemplar-conditioned generation). Investigate whether attribution-selected references can improve motion without additional training.
- Compute and storage at scale: Attribution for 10k samples requires 150 GPU-hours per A100; practical strategies for millions of samples (e.g., hierarchical indexing, sketching with refresh, distributed pipelines) are not specified. Develop scalable system designs and cost models for industrial-scale datasets.
- Adaptive budget selection: The top-10% cutoff is fixed. Study adaptive budget selection (e.g., elbow methods, score-thresholding with risk control) to balance performance gains and compute cost.
- Trade-offs in visual quality: Imaging quality and aesthetic scores are not consistently improved across baselines. Analyze why motion-centric selection sometimes trades off image quality and propose balanced selection objectives or post-hoc reweighting.
- Ethical/data governance uses: Attribution could audit motion biases in datasets (e.g., underrepresented motions, unsafe dynamics), but such analyses are absent. Define protocols to use motion attribution for dataset governance and fairness.
Glossary
- 3D U-Net: A neural network architecture using 3D convolutions to jointly model spatial and temporal dimensions in videos. "3D U-Nets or 2D U-Nets augmented with temporal attention, causal or sliding-window context, and factorized space-time blocks"
- AllTracker: A video tracking model that provides optical flow, visibility, and confidence maps used to detect and weight motion. "Motion-specific overhead primarily stems from AllTracker mask extraction with complexity"
- Bilinear downsampling: A resampling method that reduces resolution using bilinear interpolation for alignment between pixel and latent grids. "We obtain latent-aligned weights by bilinear downsampling"
- Denoising diffusion: A class of generative models trained to predict injected noise at each timestep to reverse a noising process. "Denoising diffusion~\citep{ho2020denoising} trains a network (z,c,t) to predict the injected noise:"
- DiT backbone: The Diffusion Transformer core network used in text-to-video models that is fine-tuned while other components are frozen. "During fine-tuning, we update only the DiT backbone while freezing the T5 text encoder and VAE."
- Dynamic degree: A VBench metric quantifying the extent or magnitude of motion in generated videos. "Motion smoothness and dynamic degree are our primary targets for temporal dynamics"
- Fastfood: A structured random projection technique that efficiently implements the Johnson–Lindenstrauss transform. "we apply a JohnsonâLindenstrauss projection via Fastfood \citep{le2014fastfood} and then normalize."
- Flow matching: A generative training objective that learns a time-dependent vector field to match the instantaneous velocity of a chosen interpolant. "Flow matching~\citep{lipman2022flow,albergo2023stochastic} learns a time-dependent vector field"
- Frame-length normalization: A correction that removes bias from gradient magnitudes caused by varying numbers of frames in a video. "Impact of Frame-Length Normalization on Motion Attribution."
- Influence functions: A technique from robust statistics to estimate how upweighting a training sample changes a model’s prediction on a test point. "A classic approach to data attribution is to use influence functions~\citep{koh2017understanding}."
- Inverse Hessian: The matrix inverse of the loss Hessian; it captures curvature and appears in influence-function computations, but is infeasible to compute at scale. "where the inverse Hessian captures the curvature of the loss landscape"
- Johnson–Lindenstrauss projection: A dimensionality reduction method that approximately preserves distances via random projections. "we apply a JohnsonâLindenstrauss projection via Fastfood \citep{le2014fastfood} and then normalize."
- Latent space: The compressed representation space (e.g., produced by a VAE) where diffusion or flow-matching models operate and compute gradients. "Both objectives train time-indexed predictors over the latent space by integrating over t and ε"
- Latent-video VAE: A variational autoencoder tailored to videos that encodes frames into a temporally aware latent representation. "often trained in a latent-video VAE that compresses frames while preserving temporal cues."
- Loss-space motion masks: Masks applied to the loss (not the forward pass) to reweight gradients toward dynamic regions, isolating motion influence. "apply loss-space motion masks to focus gradients on dynamic regions."
- Majority voting: A score aggregation strategy that selects training clips consistently influential across multiple queries using percentile thresholds and votes. "we adopt the majority voting approach from ICONS~\citep{wu2024icons}"
- Motion attribution: Attribution that isolates how training data influence temporal dynamics rather than static appearance. "Motion attribution examples."
- Motion smoothness: A VBench metric assessing temporal coherence and continuity of motion across frames. "Motion smoothness and dynamic degree are our primary targets for temporal dynamics"
- Motion-weighted loss: A loss that weights per-location errors by motion magnitude to emphasize dynamic regions in attribution gradients. "and define the motion-weighted loss by averaging over frames and latent spatial locations:"
- Noise scheduler: The mechanism that supplies time-dependent coefficients controlling signal and noise scales during diffusion training. "A noise scheduler supplies time-dependent coefficients (, ) controlling signal and noise scales,"
- Optical flow: A per-pixel displacement field between consecutive frames representing motion as horizontal and vertical components. "We represent motion via optical flow between consecutive frames:"
- Rademacher matrix: A diagonal matrix with ±1 entries used within the Fastfood transform to implement structured random projections. "B is a diagonal Rademacher matrix"
- Spearman correlation: A rank-based correlation metric used to evaluate how well projected-gradient rankings match full-gradient rankings. "Spearman correlation between projected and full gradients shows rapid improvement with projection dimension"
- Temporal attention: Attention mechanisms applied along the time dimension to capture dependencies across frames. "2D U-Nets augmented with temporal attention, causal or sliding-window context, and factorized space-time blocks"
- TRAK: A practical data-attribution method approximating influence via gradient feature projections. "TracIn~\citep{pruthi2020estimating} and TRAK~\citep{park2023trak}) approximate influence via gradient inner products or gradient feature projections."
- TracIn: A gradient-based influence estimator that scores training samples by their gradient inner products with test examples. "TracIn~\citep{pruthi2020estimating} and TRAK~\citep{park2023trak}) approximate influence via gradient inner products or gradient feature projections."
- VAE (Variational Autoencoder): A generative model that encodes data into a continuous latent distribution and reconstructs it, used here to provide video latents. "We operate in VAE latents: h=E(v) and train a denoiser or velocity field on noisy latents."
- VBench: A benchmark suite for evaluating video generation quality across multiple dimensions, including motion and consistency. "We evaluate our attribution using VBench~\citep{huang2024vbench} metrics across six dimensions"
- Vector field: A function mapping latent states and time to velocities, used in flow-matching objectives. "learns a time-dependent vector field f(z_t,c,t) that matches the instantaneous velocity"
- V-JEPA: A self-supervised spatiotemporal representation (Video JEPA) used to select videos representative of motion patterns. "V-JEPA embeddings (selects most representative videos of motion patterns using self-supervised spatiotemporal V-JEPA~\citep{assran2025v} features, capturing high-level motion semantics)"
- Walsh–Hadamard matrix: An orthogonal matrix enabling fast transforms within the Fastfood projection. "Q is the Walsh–Hadamard matrix"
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s motion-centric attribution, scalable gradient computation, and motion-aware data selection for fine-tuning.
Industry (media, entertainment, gaming, advertising, social platforms, MLOps)
- Motion-centric data curation for fine-tuning
- Use the motion-weighted influence scores to rank training clips and select the most impactful 5–10% for temporal dynamics, improving motion smoothness, dynamic degree, and perceived physical plausibility with less data and compute.
- Tools/products/workflows: dataset selection scripts integrated into existing T2V training pipelines (e.g., DiffSynth-Studio/Wan), CI hooks that refresh selections per release, cached projected gradients for repeated queries.
- Dependencies/assumptions: white-box access to model gradients; a reliable motion estimator (e.g., AllTracker) and standardized frame counts; compute budget for one-time per-example gradient extraction (parallelizable); appropriate licensing for training data.
- Motion-specialist adapters/models
- Train compact LoRA/adapters or specialist fine-tunes for specific motion categories (e.g., roll, float, spin) using the paper’s majority-vote aggregation across motion queries.
- Tools/products/workflows: a bank of motion-style adapters selectable at inference time by prompt; adapter routing heuristics for prompt-to-motion mapping.
- Dependencies/assumptions: adapter or fine-tuning support in the base model; evaluation with VBench motion metrics to prevent regressions; maintenance of a motion query set.
- Negative-influence filtering to reduce artifacts
- Identify and downrank/remove clips that degrade temporal coherence (e.g., camera-only motion, low-physics cartoons), mitigating flicker, identity drift, and implausible trajectories in downstream generations.
- Tools/products/workflows: “negative set” filters and dashboards; automated pre-fine-tuning checklist that flags high-influence-but-harmful clips for review.
- Dependencies/assumptions: human-in-the-loop review for borderline content; domain-relevant motion queries.
- Motion-quality regression testing and dataset audits
- Track influence rankings and VBench motion metrics across releases to detect dataset drift or motion regressions before deployment.
- Tools/products/workflows: motion influence diffs between model versions; automated VBench runs keyed to motion categories; alerting when dynamic degree drops.
- Dependencies/assumptions: stable evaluation prompts; reproducible gradient projection state (Fastfood seed); versioned datasets.
- Cost and carbon reduction via selective fine-tuning
- Achieve near full-dataset fine-tuning motion quality using ~10% data, reducing GPU hours and energy usage.
- Tools/products/workflows: budget-aware selection (percentile K); parallel attribution across GPUs; gradient reuse across multiple selection queries.
- Dependencies/assumptions: reliable ranking preservation with projected gradients (e.g., dimension ~512); single-timestep common-randomness estimator.
- Prompt-to-dataset routing at inference time
- Route prompts to the most relevant motion-specialist adapter or model based on historical influence derived from similar queries.
- Tools/products/workflows: a small service that maps prompt → motion tags → best adapter; caching of prompt-to-influence metadata.
- Dependencies/assumptions: taxonomy that maps text prompts to motion types; prebuilt specialist adapters.
Academia (ML, vision, graphics)
- Causal analysis of motion learning from data
- Use motion-weighted influence to study how clip-level dynamics (e.g., acceleration patterns, camera vs. object motion) shape generator behavior.
- Tools/products/workflows: public motion query sets per category; ablations of tracker choice, timestep, projection dimension; open-source notebooks for influence-vs-performance curves.
- Dependencies/assumptions: access to datasets and training code; standardized evaluation (VBench, human studies).
- Motion-aware benchmark curation and distillation
- Construct compact, balanced motion datasets and distilled subsets tailored to temporal coherence without sacrificing aesthetics or subject consistency.
- Dependencies/assumptions: diverse raw datasets; reproducible frame-length normalization.
Policy and governance
- Dataset documentation and motion influence reports
- Produce data sheets documenting which portions of the training corpus most affect motion behavior, for transparency and internal risk review.
- Dependencies/assumptions: organizational policy permitting per-example influence analysis; retained provenance of training clips.
- Pre-release motion risk audits
- Identify datasets that induce physically implausible dynamics (e.g., “slippery” motion drift) and mitigate via filtered selection prior to launch.
- Dependencies/assumptions: curated “red flag” motion queries; human oversight for critical domains.
Daily life (creators, educators)
- Creator-friendly motion controls
- Offer a “motion tuning” option that chooses a small, relevant fine-tuning set behind the scenes to improve smoothness and realism for a creator’s target style.
- Dependencies/assumptions: hosted fine-tuning service; UI surfacing motion categories.
- Physics education content generation
- Generate clearer demonstrations of physical motions (bounce, free fall, spin) by training small motion-specialist models for teaching materials.
- Dependencies/assumptions: vetted datasets; teacher-defined prompts and constraints.
Long-Term Applications
These applications are enabled by the paper’s approach but require further research and engineering (e.g., 3D awareness, closed-loop data selection, cross-domain trackers, policy frameworks).
Robotics and autonomous systems
- Motion-curated data for world models and simulators
- Use motion influence to curate videos with physically accurate, diverse dynamics for training world models or video-based simulators used in robotics and AV testing.
- Potential products: “motion data refinery” for sim2real pipelines; continuous selection loops that update training sets based on policy failures.
- Dependencies/assumptions: integration with 3D/pose estimation (camera disentanglement); domain trackers robust to occlusion; validation against real-world metrics.
- Generative augmentation for policy learning
- Improve data efficiency by generating realistic dynamic scenarios targeted to a robot’s failure modes, selected via motion-aware influence.
- Dependencies/assumptions: safety evaluation; closed-loop RL training with generative augmentation; domain-specific constraints.
Healthcare
- Surgical/clinical motion modeling
- Curate surgical videos exhibiting stable instrument and tissue dynamics to train procedural video generators (simulation, training aids) or motion assessment tools.
- Dependencies/assumptions: privacy and compliance (HIPAA/GDPR); domain-adapted trackers that handle occlusion, fluids, and specularities; clinical validation.
Finance, insurance, security
- Scenario testing with synthetic but realistic motion
- Generate surveillance/claims scenarios with plausible motion to stress-test detection systems and train anti-fraud models.
- Dependencies/assumptions: strict governance and ethics review; risk of bias amplification; domain-specific motion queries and evaluation.
Education and scientific communication
- Data-driven physics visualizations
- Blend data-curated motion patterns with minimal physics priors to create accurate, engaging demonstrations for STEM education.
- Dependencies/assumptions: better disentanglement of camera vs. object motion; validation against analytic dynamics.
Policy and ecosystem
- Motion-aware data valuation and licensing
- Extend data valuation (e.g., Shapley/influence) to motion, enabling compensation or licensing based on a clip’s contribution to a model’s dynamics.
- Dependencies/assumptions: standardized, auditable influence pipelines; legal frameworks recognizing per-example influence; robust variance controls.
- Standards and disclosures for generative motion
- Incorporate motion-influence summaries into model cards/datasheets; regulators or industry bodies may require audits demonstrating physically plausible motion within domains of use.
- Dependencies/assumptions: community consensus on motion metrics and audit procedures; interoperable APIs and benchmarks.
Tools/products/workflows
- Closed-loop, motion-aware active data selection
- Online systems that monitor deployment prompts, attribute motion needs, and automatically refresh fine-tuning subsets to maintain temporal quality in the wild.
- Dependencies/assumptions: streaming attribution infrastructure; safe, continuous fine-tuning.
- Hardware/software acceleration for attribution-at-scale
- Specialized kernels for Fastfood projections and per-example gradient extraction; standardized “OpenMotionAttribution” API usable across model families.
- Dependencies/assumptions: vendor support; alignment on projection dimensions and seeds for reproducibility.
- Richer motion disentanglement and multi-modal extensions
- Integrate camera pose estimation, depth/scene flow, and 3D representations to separate camera vs. object motion; extend to audio-visual sync (e.g., lip motion, footsteps).
- Dependencies/assumptions: reliable 3D/pose pipelines across domains; compute budget; improved trackers.
- Motion-specialist marketplace and orchestration
- Ecosystem of vetted motion adapters per category/industry (e.g., sports replays, product spins, ocean waves), with automated orchestration based on prompt and use-case.
- Dependencies/assumptions: curation standards, IP/usage rights, quality verification services.
Collections
Sign up for free to add this paper to one or more collections.