OpenDecoder: Open Large Language Model Decoding to Incorporate Document Quality in RAG
Published 13 Jan 2026 in cs.CL, cs.AI, and cs.IR | (2601.09028v1)
Abstract: The development of LLMs has achieved superior performance in a range of downstream tasks, including LLM-based retrieval-augmented generation (RAG). The quality of generated content heavily relies on the usefulness of the retrieved information and the capacity of LLMs' internal information processing mechanism to incorporate it in answer generation. It is generally assumed that the retrieved information is relevant to the question. However, the retrieved information may have a variable degree of relevance and usefulness, depending on the question and the document collection. It is important to take into account the relevance of the retrieved information in answer generation. In this paper, we propose OpenDecoder, a new approach that leverages explicit evaluation of the retrieved information as quality indicator features for generation. We aim to build a RAG model that is more robust to varying levels of noisy context. Three types of explicit evaluation information are considered: relevance score, ranking score, and QPP (query performance prediction) score. The experimental results on five benchmark datasets demonstrate the effectiveness and better robustness of OpenDecoder by outperforming various baseline methods. Importantly, this paradigm is flexible to be integrated with the post-training of LLMs for any purposes and incorporated with any type of external indicators.
The paper introduces an explicit decoding mechanism that integrates external quality indicators into LLM-based RAG to mitigate noisy and irrelevant retrievals.
It employs a systematic attention modulation technique using aggregated scores from retriever relevance, semantic ranking, and QPP to guide token probability distributions.
Robust training across diverse noise regimes demonstrates significant improvements in F1 and Exact Match on multiple QA benchmarks, highlighting practical resilience.
OpenDecoder: Modulating LLM Decoding via Explicit Document Quality Indicators in RAG
Introduction
The paper "OpenDecoder: Open LLM Decoding to Incorporate Document Quality in RAG" (2601.09028) introduces a principled decoding optimization mechanism for LLM-based Retrieval-Augmented Generation (RAG) that incorporates explicit document-level quality signals directly into the computation of model attention. This approach diverges from conventional methods, which rely on internal relevance judgment via the LLM's network and instructions, by externally modulating the attention distribution based on retrieved document characteristics such as external relevance scores, LLM-based semantic evaluation, and query performance prediction (QPP).
This explicit modulation aims to enhance robustness to noisy or irrelevant retrieved evidence, a persistent challenge in RAG settings where the retriever may return contextually unsuitable documents. The proposed framework adapts the generative pathway to actively ignore or downweight irrelevant input during answer construction and can be flexibly extended to any external indicator for model post-training and downstream customization.
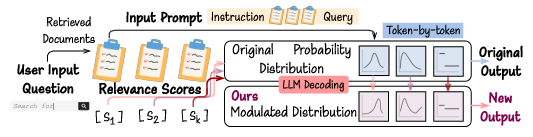
Figure 1: OpenDecoder modifies the token probability distribution by integrating explicit external relevance signals, contrasting the default LLM decoding protocol.
Methodology
Framework Overview
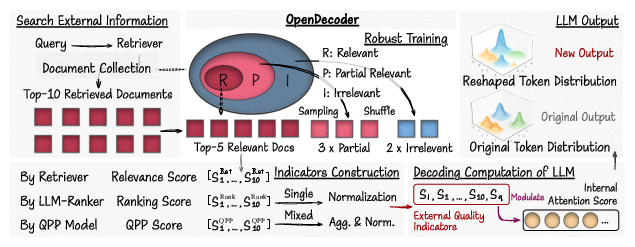
OpenDecoder operates in four stages:
Document Retrieval and Quality Scoring: Top-k documents are retrieved and annotated with multiple explicit quality indicator scores.
Feature Construction: Quality scores (retriever relevance, LLM semantic ranking, QPP) are aggregated and normalized to form a token-level guidance matrix.
Attention Modulation: The indicator matrix systematically modulates the model's internal attention computation, directly reshaping the token probability distribution used in decoding.
Robust Training: Fine-tuning is conducted with varied, noisy contexts using different document relevance distributions to maximize noise tolerance.
Figure 2: OpenDecoder architecture incorporating explicit score features into the decoding pathway alongside robustness training mechanisms.
External Indicator Integration
Three indicator modalities are utilized: (1) retriever relevance score (SRet), (2) LLM-based document ranking score (SRank), and (3) QPP score (SQPP). These are aggregated with prescribed weighting and normalized for integration. The constructed score distribution Snorm interfaces directly with the attention network:
This explicit modulation amplifies or attenuates the influence of individual context tokens according to external evidence quality, a design not previously explored in RAG literature.
Robustness Training Protocol
Training incorporates systematic context corruption: irrelevant documents are substituted into the prompt, position-order of inputs is shuffled, and evaluation covers normal, noisy, and extreme-noisy regimes. This design instructs the LLM to preferentially attend to high-scoring input and ignore detrimental context, as determined by the provided indicators.
Experimental Evaluation
Performance Across Datasets and Noise Levels
Extensive benchmarking was conducted on five QA datasets (NQ, TriviaQA, PopQA, HotpotQA, 2Wiki) with diverse domain coverage and multi-hop requirements. Three contamination regimes (normal, noisy, extreme noisy) test noise resilience.
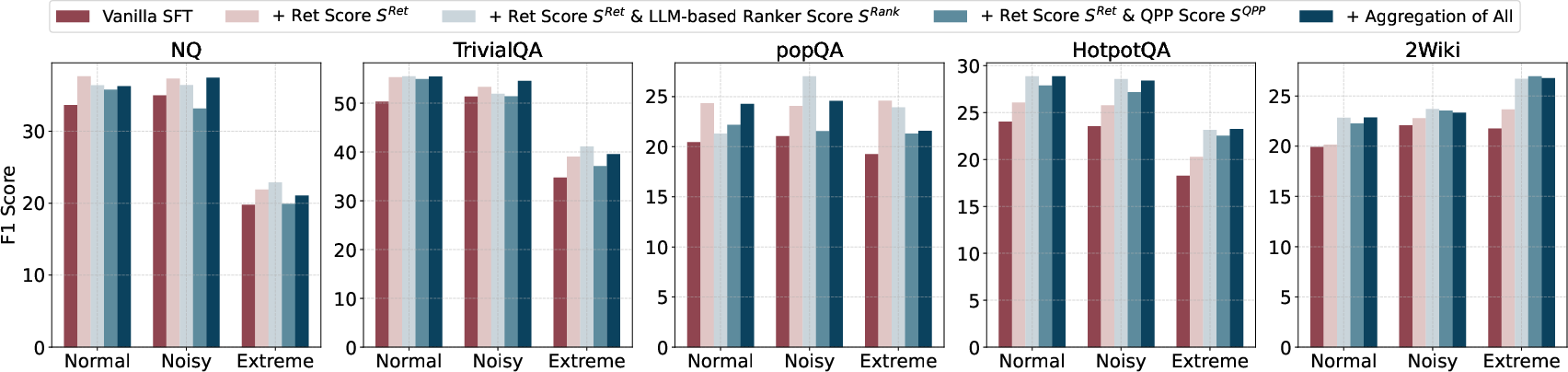
OpenDecoder yields substantial improvements in F1 and Exact Match versus vanilla RAG and SFT, as well as recent robust RAG methods (RobustRAG, AstuteRAG, InstructRAG, RbFT). In extreme-noisy conditions, OpenDecoder maintains notably higher performance, demonstrating its capacity to downweight corrupted context and revert to parametric knowledge when necessary.
Ablation and Feature Analysis
Ablation demonstrates that explicit guidance incorporation overwhelmingly accounts for improved robustness, while score aggregation and document order randomization further stabilize performance.
Figure 3: Aggregating diverse score features as guidance improves accuracy across evaluation scenarios.
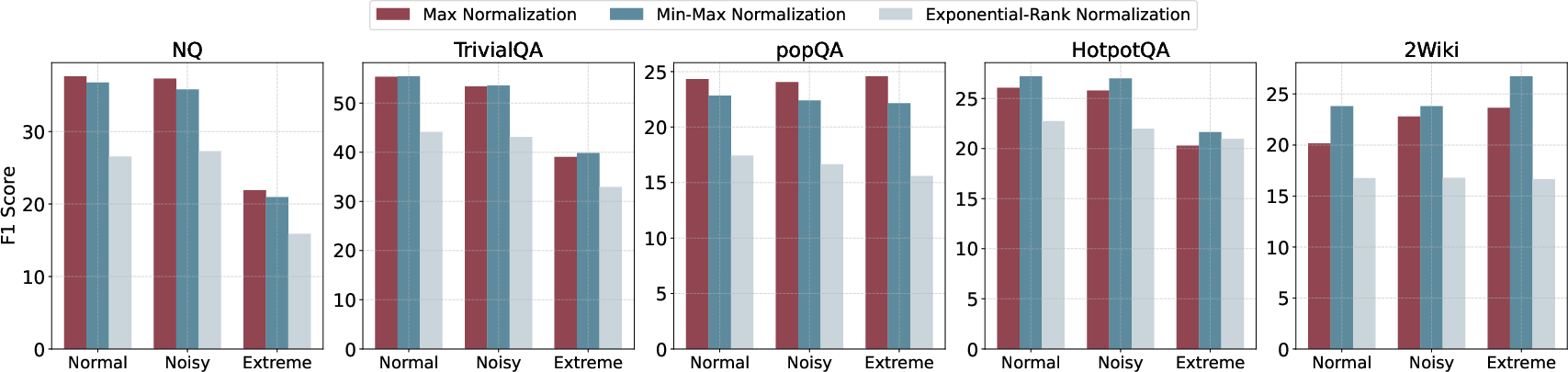
Normalization strategies substantially influence effectiveness: Max normalization generally outperforms alternatives (Min-Max, Exponential Rank) on general QA, whereas multi-hop QA tasks benefit from more nuanced normalization.
Figure 4: Normalization approach choice modulates the impact of external scores on model performance.
Top-K Sensitivity and Model Scaling
Analysis of top-k document inclusion reveals non-monotonic trends: higher k increases answer coverage but also risk of introducing noise. OpenDecoder consistently exhibits better tolerance and stable performance across varying k.
Figure 5: Optimal top-k varies by dataset, but OpenDecoder demonstrates improved noise tolerance compared to SFT.
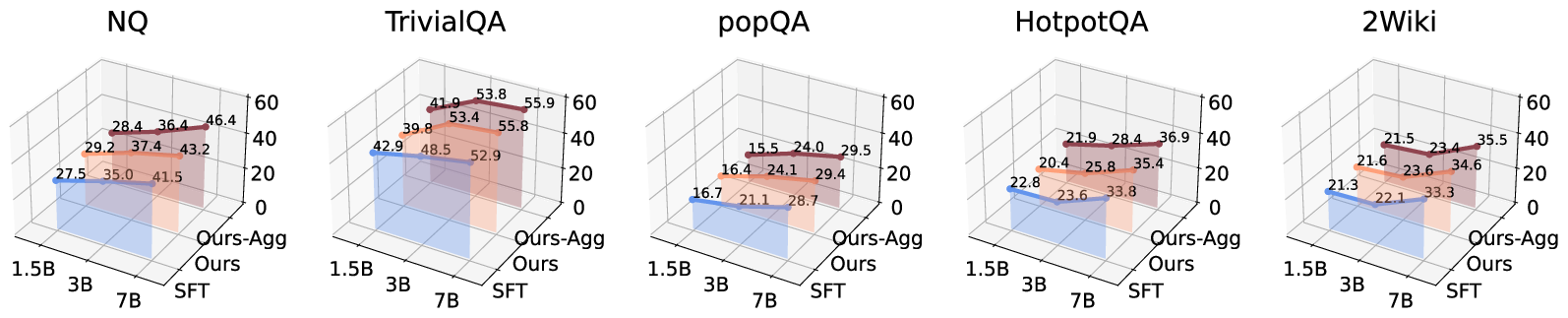
Investigation into backbone model scaling reveals that larger LLMs synergize with explicit indicator integration, enhancing both robustness and generalization. This is especially pronounced for multi-hop and complex QA settings.
Figure 6: In noisy conditions, OpenDecoder outperforms SFT across scale and dataset varieties.
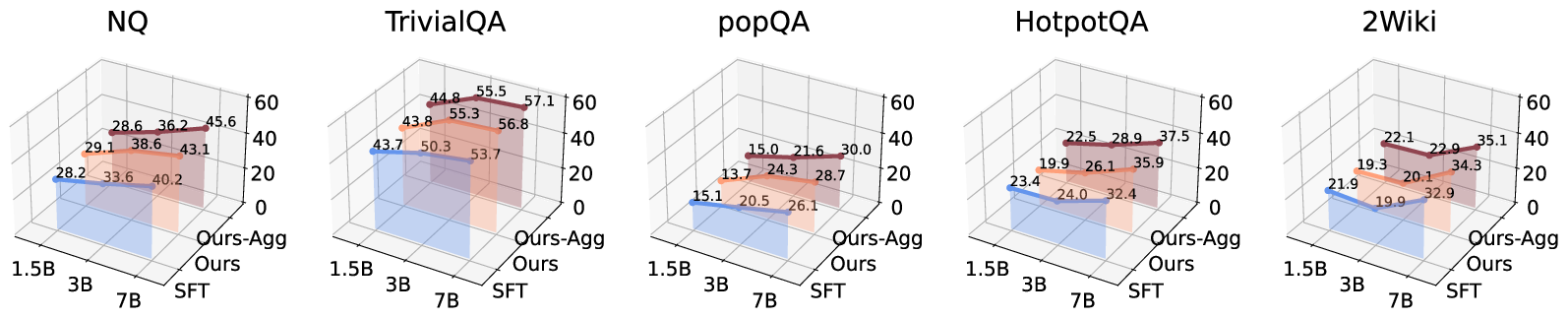
Figure 7: Scaling comparison under normal retrieval environments shows persistent OpenDecoder advantage.
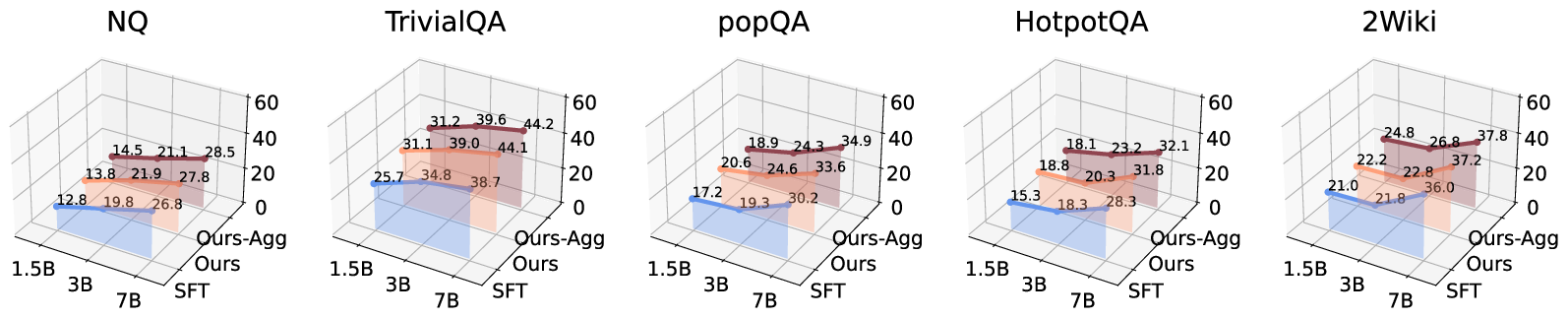
Figure 8: Extreme noisy setting accentuates OpenDecoder's robustness as model scale increases.
Implications and Future Directions
The explicit attention modulation paradigm advanced by OpenDecoder fundamentally shifts RAG architectures toward a dual-mode reasoning protocol: contextual generation can be continuously steered by external, domain-sensitive quality signals, ideally improving accuracy, robustness, and transparency of output.
Immediate practical implications include robust deployment in real-world settings characterized by high retrieval failure rates, adversarial context injection, or noisy semantic environments. Theoretically, this approach opens avenues for decoupling parametric and non-parametric knowledge utilization and integrating richer, multi-modal external indicators during LLM decoding.
Future directions will likely involve development of adaptive indicator weighting, further exploration of aggressive robustness training, targeted application for trustworthiness and faithfulness objectives, and extension to larger, more capable LLM backbones.
Conclusion
OpenDecoder introduces an effective, generalizable mechanism for integrating explicit document-level quality signals into the decoding process of LLMs in RAG, resulting in superior performance and resilience to input noise compared to existing strategies. Its flexible architecture and strong empirical results position it as a robust foundation for future RAG systems focused on reliability and context-sensitive generation.