- The paper introduces SRT, a tree-structured cache that accelerates on-policy RL by speculative rollout, achieving up to a 2.08× speedup in rollout time.
- It integrates cache-based speculative decoding into various RL algorithms without deviating from the on-policy distribution, ensuring stable convergence.
- The method leverages both online and run-ahead cache updates to reduce redundant computation and lower per-token inference costs in LLM training.
SRT: Accelerating On-Policy RL in LLMs via Speculative Rollout and Tree-Structured Caching
Introduction and Motivation
This paper presents Speculative Rollout with Tree-Structured Cache (SRT), a framework for accelerating on-policy reinforcement learning (RL) in LLMs through an efficient, purely model-free speculative decoding procedure employing a per-prompt, tree-structured cache. The work addresses major bottlenecks in RL training for LLMs, particularly the extreme compute cost and latency of autoregressive rollout—where generating responses dominates wall-clock time, often more than 65% of the total, as measured across various RL algorithms. The inefficiencies arise not only from the inherently memory-bound, sequential token generation in transformer models but are exacerbated by long-tailed length distributions of responses in batched decoding, which induce substantial GPU underutilization.
Further empirical analysis reveals that, for the same prompt, responses generated by RL-trained LLMs across different policy checkpoints tend to have high overlap, especially when sampled in large numbers (e.g., in DAPO or GRPO). This statistical redundancy signals a largely untapped opportunity: much of the expensive rollout computation is recapitulating previously generated, near-identical subsequences.
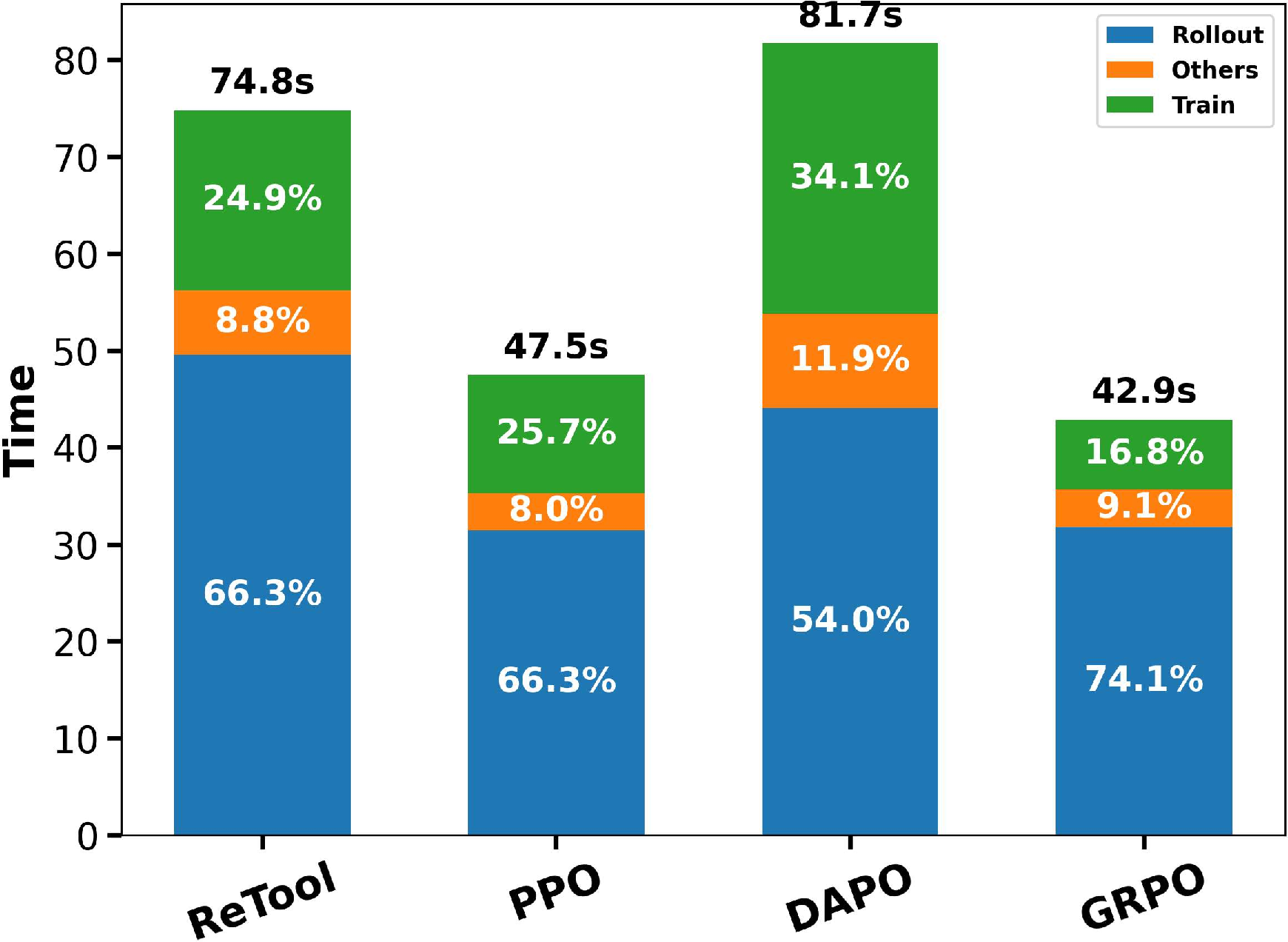
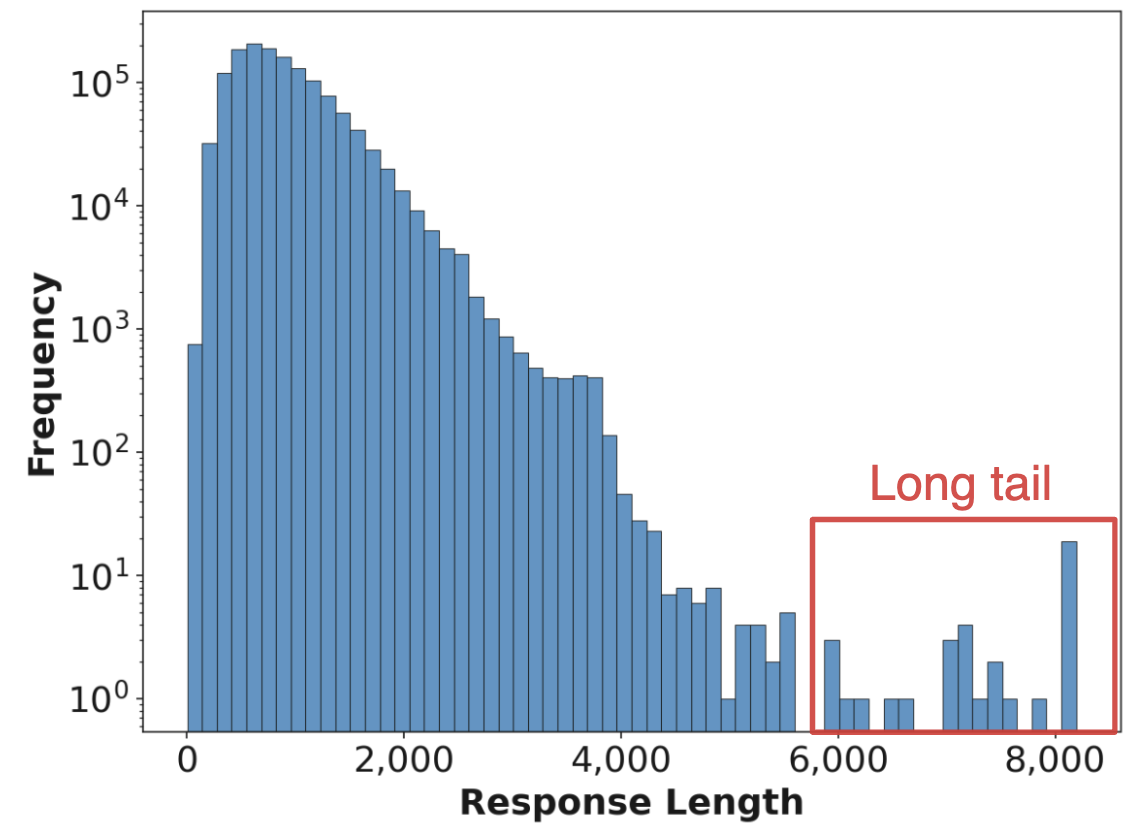
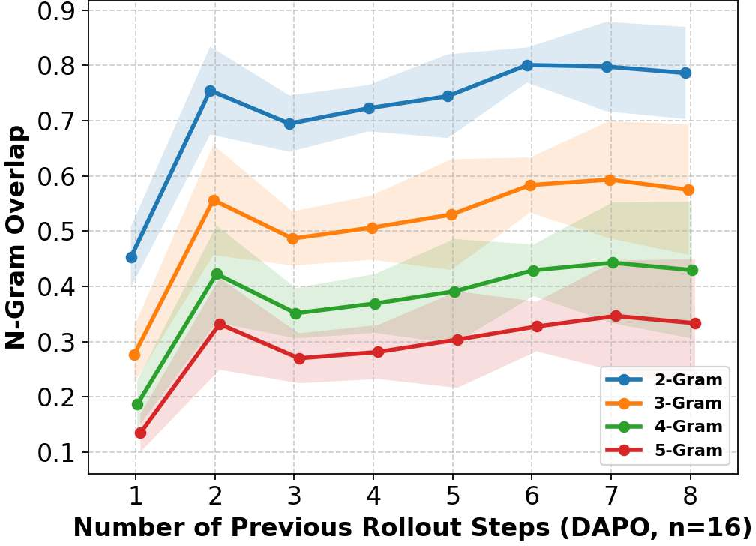
Figure 1: (a) Time breakdown across RL algorithms, emphasizing rollout cost; (b) Long-tailed output length distribution; (c) Substantial N-gram overlap in prompt responses across steps.
Algorithmic Framework
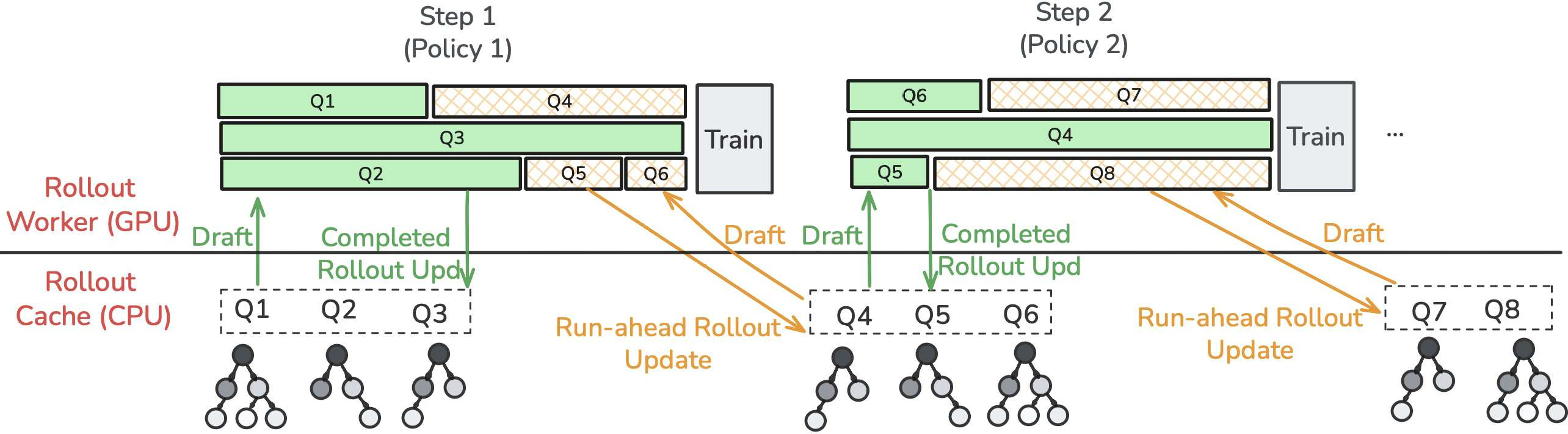
SRT integrates into the standard on-policy RL loop for LLMs, which alternates between (1) generation ("rollout") of K samples per prompt from the current policy πθ and (2) parameter updates using policy gradient objectives based on task-specific rewards. The core innovation is the introduction of a per-prompt rollout cache Tp, maintained as a tree-shaped prefix trie storing all previously generated token substrings for prompt p.
During rollout, SRT exploits this cache for speculative decoding, akin to retrieval-augmented inference but operating purely model-free, without an explicit draft model. Generation proceeds as follows:
- For a partial continuation y1:t, locate the longest matching suffix in Tp.
- From the corresponding node, greedily assemble a maximal chain of likely tokens by following the most frequent child at each depth, as captured by empirical conditional probabilities.
- Propose the resulting subsequence as "draft" tokens, which are then batch-verified by the current policy's logits using the standard speculative decoding verification phase. Accepted tokens are emitted up to the first policy mismatch.
This modular cache-based acceleration can be seamlessly integrated with policy gradient variants, including PPO, GRPO, and DAPO.
The cache is dynamically and proactively enriched by two mechanisms:
Experimental Results and Empirical Analysis
SRT is evaluated on the Qwen2.5-1.5B model using four RL algorithms (PPO, GRPO, DAPO, and ReTool), with experiments conducted on canonical mathematics and reasoning datasets. The main outcome measures are rollout (generation) latency, RL step latency, and per-token inference cost.
Key results:
- SRT achieves up to 2.08× speedup in wall-clock rollout time, outperforming both conventional decoding and existing speculative decoding schemes such as SuffixDecoding (Oliaro et al., 2024).
- Latency improvements are robust to the choice of RL algorithm and hold for both single-turn and multi-turn settings.
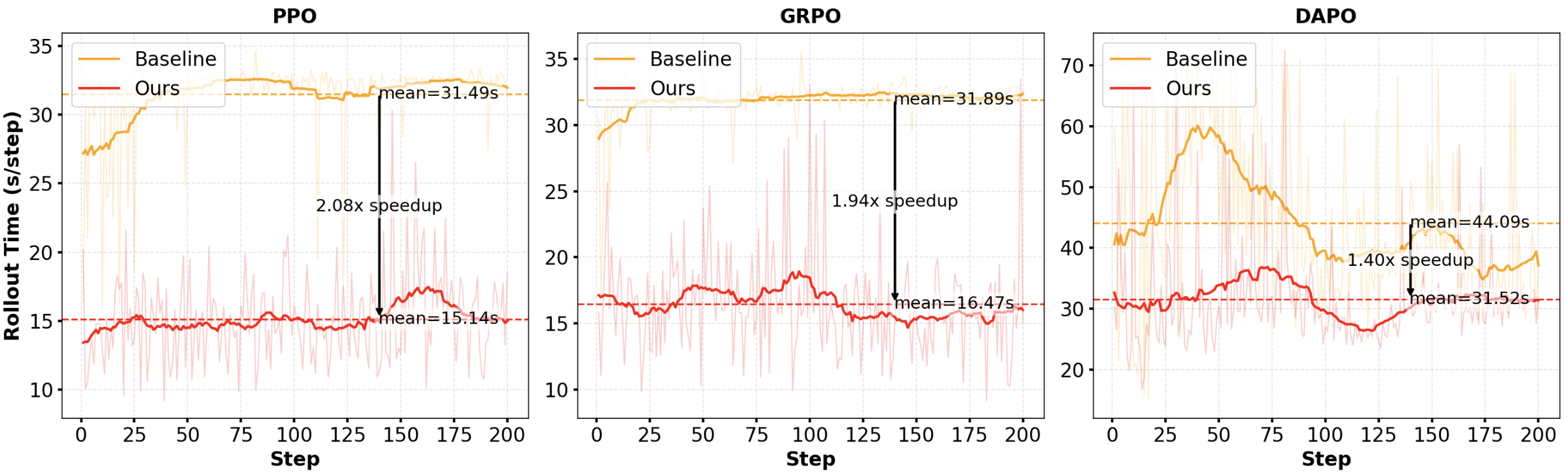
Figure 3: SRT achieves substantial speedup in rollout time across PPO, GRPO, DAPO, and ReTool algorithms on Qwen2.5-1.5B.
Detailed analysis correlates the degree of speedup with the similarity of rollouts; algorithms (e.g., DAPO, GRPO) generating more responses per prompt see larger gains due to higher cache hits and greater n-gram overlap (see Figure 2c). Run-ahead speculative generation further increases mean accepted tokens per verification, driving further reductions in end-to-end cost.
SRT contrasts with recent asynchronous rollout methods (e.g., AReaL (Fu et al., 30 May 2025), RLHF stage fusion (Zhong et al., 2024)) that boost hardware throughput by relaxing strict on-policy constraints, often at the potential expense of training convergence or sample quality. SRT, by leveraging only previous on-policy rollouts as speculative drafts, maintains rigorous policy correctness with no distributional shift.
A closely related line is RhymeRL (He et al., 26 Aug 2025), which asynchronously caches completed responses from older epochs but does not perform online or run-ahead cache enrichment, leading to cold-start and lower cache utility for new prompts. SRT directly addresses this limitation with on-the-fly cache updates and anticipatory draft generation during idle compute.
Speculative decoding has been successfully deployed for inference acceleration in LLMs using smaller draft models or retrieval-based candidates (Miao et al., 2023, Oliaro et al., 2024), but SRT is the first to adapt purely model-free, rollout-based speculative decoding for RL training, preserving the on-policy property vital to stable convergence.
Theoretical and Practical Implications
SRT highlights the high degree of redundant computation in RL-based LLM training and offers a general, lossless acceleration mechanism that trades modest additional memory for substantial speedup. The scheme maintains strict consistency with the on-policy distribution, ensuring the statistical properties essential for RL training are unchanged.
Practically, SRT can be adopted in existing RLHF and policy optimization pipelines with minimal changes, leveraging commodity CPU-side cache and native speculative decoding primitives on LLM accelerators. Memory and compute costs scale gracefully with the number of prompts and cache depth, well within the regime of current large-scale LLM infrastructure.
Theoretically, SRT sets a precedent for model-free, experience-based draft strategies for accelerating token-level operations, suggesting future work in hierarchical cacheing, adaptive run-ahead, and dynamic draft selection as RL algorithms and LLMs continue to scale.
Conclusion
SRT provides an effective, scalable solution to a major RL efficiency bottleneck for LLMs by leveraging per-prompt, tree-structured caches for speculative rollout. With empirically validated gains—over 2x reduction in rollout cost in on-policy RL—the method offers practical utility and a straightforward path toward more efficient, scalable LLM RL training regimes. Its design principles and cache-based speculative execution are likely to inform future research in efficient RL and adaptive inference for next-generation LLMs.