- The paper introduces IKE, a learning-free binary embedding method that compresses dense LLM embeddings with minimal loss in retrieval accuracy.
- It employs data-dependent isolation kernels via iForest and Voronoi strategies, achieving up to 16.7× speedup and 8–16× storage reduction.
- The approach supports adjustable code-length for plug-and-play indexing in large-scale retrieval tasks without retraining, outperforming CSR and LSH baselines.
Motivation and Background
Dense text representations derived from LLMs such as LLM2Vec, Qwen Embedding, and Llama2Vec set the state of the art for retrieval and semantic search. However, their high-dimensional floating-point embeddings (often 4096 dimensions, 32-bit each) pose scalability challenges in both memory footprint and retrieval latency. Downstream tasks involving large-scale retrieval—such as RAG, QA, or recommender systems—demand more efficient representations with minimal loss in retrieval accuracy.
Current solutions bifurcate into adaptive-length embeddings, such as Matryoshka Representation Learning (MRL), and sparsifying approaches like Contrastive Sparse Representation (CSR). MRL's full-model retraining requirement and non-trivial performance degradation for short codes, as well as CSR's transformation overhead and code length rigidity, motivate alternative approaches.
Isolation Kernel Embedding (IKE) exploits data-dependent, learning-free partitioning to produce compact, binary codes directly from pretrained LLM embeddings. The design is grounded in theoretical properties—full space coverage, maximum entropy, bit independence, and, crucially, diversity of base partitioners—that past learning-based and hashing methods incompletely address.

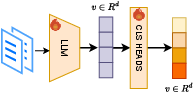
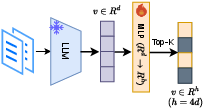
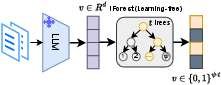
Figure 1: MRL (Learning-based), CSR (Learning-based), and IKE (No Learning): IKE efficiently maps LLM embeddings to binary codes through random partitions, circumventing the need for model retraining.
Isolation Kernel: Theory and Construction
The Isolation Kernel (IK) computes similarity by partitioning the space and measuring co-occurrence of two points in the same partition. A partition is defined over a sampled subset of data; the probability that two points share a cell across an ensemble of such partitions serves as the kernel. In practical estimation, t partitions (with each partition typically implemented as an iTree or Voronoi-based cell structure) suffice for high-fidelity approximation.
The inner mechanics admit two main implementation strategies:
- Isolation Forest (iForest): Partitions are formed by recursively splitting along random features and values, yielding binary trees with diverse, data-dependent cells.
- Voronoi Diagram-based (VD): Anchor points define cells; for VD, randomness is enhanced by sampling both subspaces and anchors, promoting diversity among partitions.
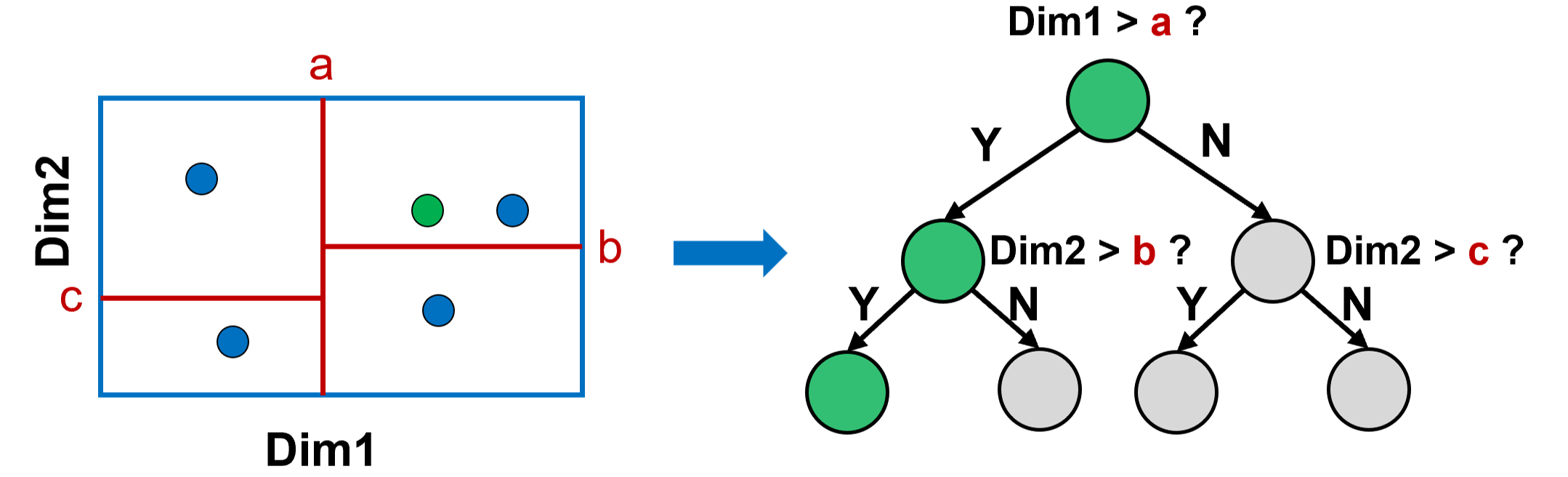
Figure 3: iForest partitions space via random axis-aligned splits, generating diverse, hierarchical regions suitable for robust hashing.
IKE Vector Database Construction
Embedding and Partitioning
A fixed LLM encoder generates d-dim floating-point embeddings for all documents and queries. A random subset of corpus points seeds the construction of t isolation forests, each over ψ sampled points. Each iTree's internal nodes split on randomly chosen features and split points, while leaves correspond to isolated data elements.
Each data point is mapped to an index vector specifying the leaf reached in each of the t iTrees. This index list, with each item stored as ⌈log2(ψ)⌉ bits, forms a highly compact representation—dramatically smaller than the raw dense embedding.
Truncation and Adaptability
Because iTrees are constructed independently, the code length (number of trees/partitions t) is fully adjustable post-hoc. Retaining only the first t′ code positions yields a dimensionally truncated embedding, supporting application-tailored trade-offs between accuracy, throughput, and storage, without retraining.
Retrieval and Similarity Computation
For a query, the index representation is computed as above. Candidate scores (exact or ANN) are computed via efficient bitwise operations over the index strings, exploiting byte alignment and SIMD-friendly routines for population counting and comparison.
Empirical Results
Memory and Latency
Empirical evaluation across six retrieval datasets (including HotpotQA, Istella22, TREC DL 23) reveals:
- Storage: 8–16× reduction over the raw LLM embeddings.
- Retrieval Latency: 2.5–16.7× acceleration for exhaustive search.
- Accuracy: MRR@10 and nDCG@10 at 98–101% and 96–100% of raw embedding baselines, respectively, indicating near-lossless performance.
Approximate Nearest Neighbor (ANN) Retrieval
Integrating IKE codes with ANN engines (IVF, HNSW) further improves query throughput. On HotpotQA, HNSW+IKE achieves 4–5× higher QPS than HNSW on LLM embeddings at comparable MRR@10. IVF indexing in the IKE space reaches 6–8× speedups.
Figure 2: QPS vs. MRR@10 for four ANN methods on HotpotQA: IKE-based retrieval consistently yields superior efficiency–accuracy trade-offs.
Comparison with CSR and Learning-Free Baselines
Against CSR (sparse, MLP-adapted codes), IKE attains one order of magnitude lower retrieval time with similar or better accuracy, as all mapping and search operations are highly optimized and learning-free. Unlike CSR and PQ/LSH, IKE codes do not require expensive matrix multiplications at query time, nor model retraining for code length adjustment.
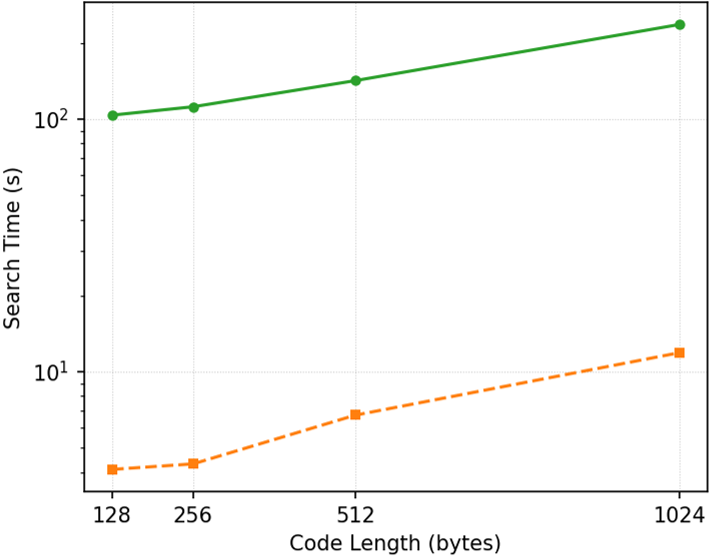
Figure 4: Comparison of retrieval accuracy and search time between CSR and IKE illustrates IKE's superior efficiency with matching accuracy.
Broader benchmarking against LSH, ScaNN, and PQfs affirms IKE (paired with HNSW) as the most balanced solution, with up to 10× higher throughput under identical code-length constraints.
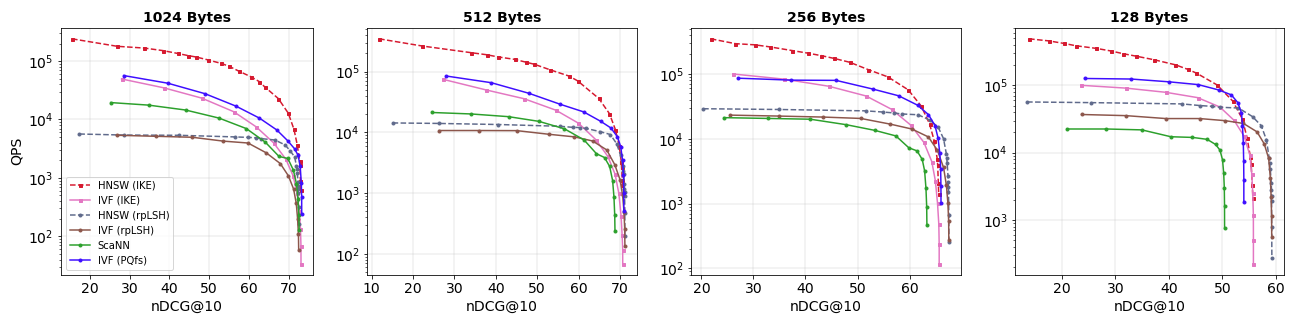
Figure 5: On HotpotQA (LLM2Vec), HNSW (IKE) consistently achieves optimal efficiency-accuracy across code lengths.
Hyperparameter Sensitivity
Increasing the number of iTrees t yields incrementally better accuracy but incurs linear growth in latency and storage. However, returns diminish beyond moderate t (e.g., t > 3000 for LLM2Vec), facilitating principled resource–performance balancing.
Diversity Advantage
Rigorous analysis demonstrates that the diversity of partitions—maximized in IKE via axis/value randomization in iForest—significantly reduces estimator variance, directly translating into retrieval robustness. This is notably superior to VDeH and its non-diverse variants.
Theoretical Insights
IKE achieves:
- Full space coverage: Guaranteed assignment for any input.
- Entropy maximization: Each code position partitions data near-uniformly.
- Bit independence: High mutual independence among code bits.
- Partition diversity: Ensemble variance rapidly vanishes, enabling accurate kernel approximation with moderate t.
Critically, diversity emerges as an essential fourth property for scaling to LLM embedding spaces with complex data geometry.
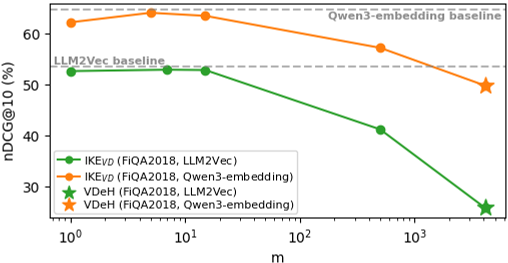
Figure 6: Effect of parameter m in VD: Optimal diversity (small m) avoids performance collapse seen in VDeH (m=d).
Practical Implications and Future Prospects
Practically, IKE offers a scalable path for vector database deployment, especially where retrieval latency and infrastructure cost are primary constraints (e.g., RAG, search engines, recommendation). Its learning-free nature obviates costly retraining and supports plug-and-play code length adaptation. Unlike quantization and hashing-based alternatives, IKE maintains retrieval accuracy even in extreme compression regimes, including million-scale corpora.
Future research directions include:
- Cross-modal and cross-domain retrieval: Exploring limitations due to modality gap, especially for image/text dual embeddings.
- Subspace partitioning schemes: Enhanced randomization/control strategies and hybridization with learned indexes.
- Integration with hierarchical and disk-based vector stores for even larger scales.
Conclusion
IKE represents a substantial advance in compact, efficient LLM embedding compression. By leveraging partition diversity and learning-free transformation, it achieves strong empirical and theoretical guarantees: up to 16.7× compression and acceleration, negligible accuracy loss, and easy adaptability. These properties position IKE as a preferred solution for high-throughput, low-resource, and large-scale retrieval in modern AI systems.
Reference:
"LLMs Meet Isolation Kernel: Lightweight, Learning-free Binary Embeddings for Fast Retrieval" (2601.09159)