- The paper introduces a benchmark that employs dual-scale memory modeling with anchors and attractors to enhance scientific reasoning in LLMs.
- It details a SAPM annotation process that curates 2,198 rigorously selected problems from mathematics, physics, and chemistry.
- The study demonstrates significant accuracy gains and reduced inference latency through a HybridRAG framework that integrates precise memory activation.
Memory-Driven Scientific Reasoning: The A3-Bench Benchmark
Motivation and Conceptual Framework
The A3-Bench initiative introduces a memory-centric evaluation paradigm for scientific reasoning in LLMs, addressing the gap where existing benchmarks measure answer correctness and stepwise process but largely ignore underlying mechanisms for knowledge retrieval and activation. Human expertise in scientific problem solving critically depends on selectively activating prior knowledge—both foundational concepts ("anchors") and solution-guiding schemas ("attractors")—in the context of a given query. The A3-Bench operationalizes this dual-scale memory mechanism, allowing for precise assessment of how LLMs navigate, activate, and utilize expert-annotated memories during multi-step inference.
Dual-Scale Memory Modeling: Anchors and Attractors
Anchors serve as the foundational building blocks: definitions, laws, formulas that constrain the problem scope and initial reasoning state. Attractors provide procedural guidance—abstract templates and episodic exemplars—steering actual solution paths through the attractor basin in the reasoning state space. Formally, this mechanism maps input queries to internal states influenced by activated anchors and attractors, with inference trajectories governed by attractor-driven dynamics and the minimization of a free-energy–like objective.
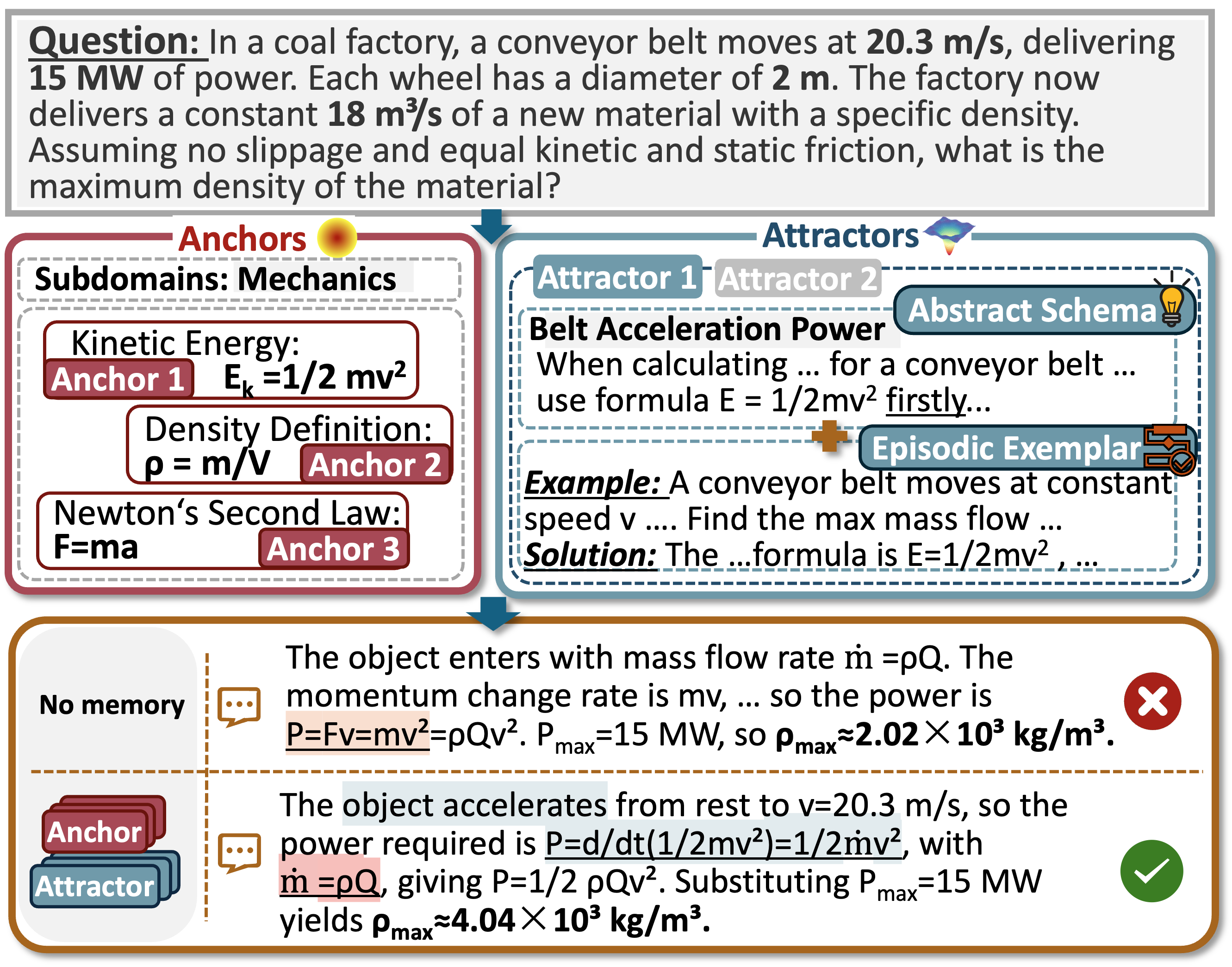
Figure 1: Comparison of reasoning paths on OlympiadBench. Activating anchors and attractors corrects the derivation path relative to no memory.
SAPM Annotation and Dataset Construction
The SAPM process—Subject, Anchor/Attractor, Problem, Memory development—structures the annotational pipeline for the A3-Bench dataset, which comprises 2,198 rigorously curated problems across mathematics, physics, and chemistry. Problems are selected and refined based on model failure across three LLMs (GPT-5, DeepSeek-V3.2, Qwen-30B), ensuring challenging content. Expert annotation then links each question to 2–6 anchors and 2–4 attractors, providing both declarative and procedural signals. Hierarchical subject taxonomies align with international standards (AMS for mathematics, IP/IUPAC for physics and chemistry).
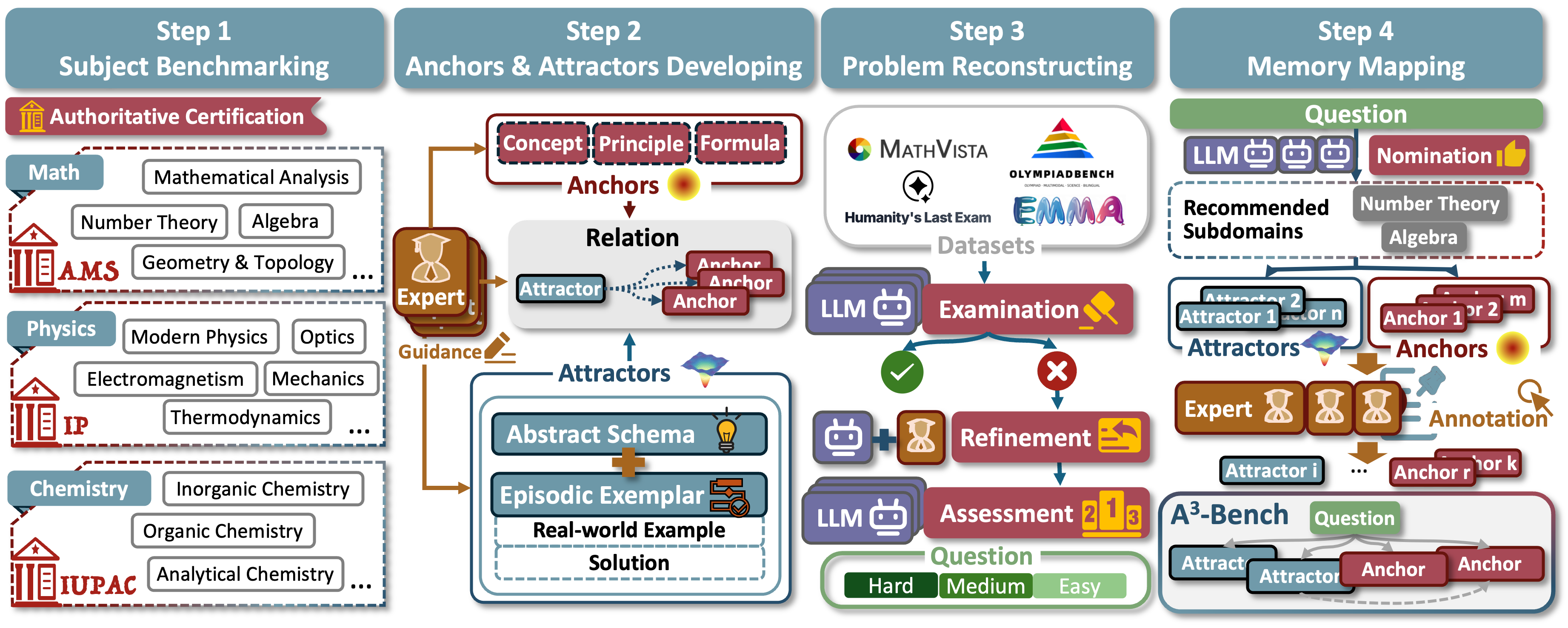
Figure 2: The SAPM annotation pipeline: subdomain benchmarking, anchor/attractor development, dataset refinement, and problem-memory mapping.
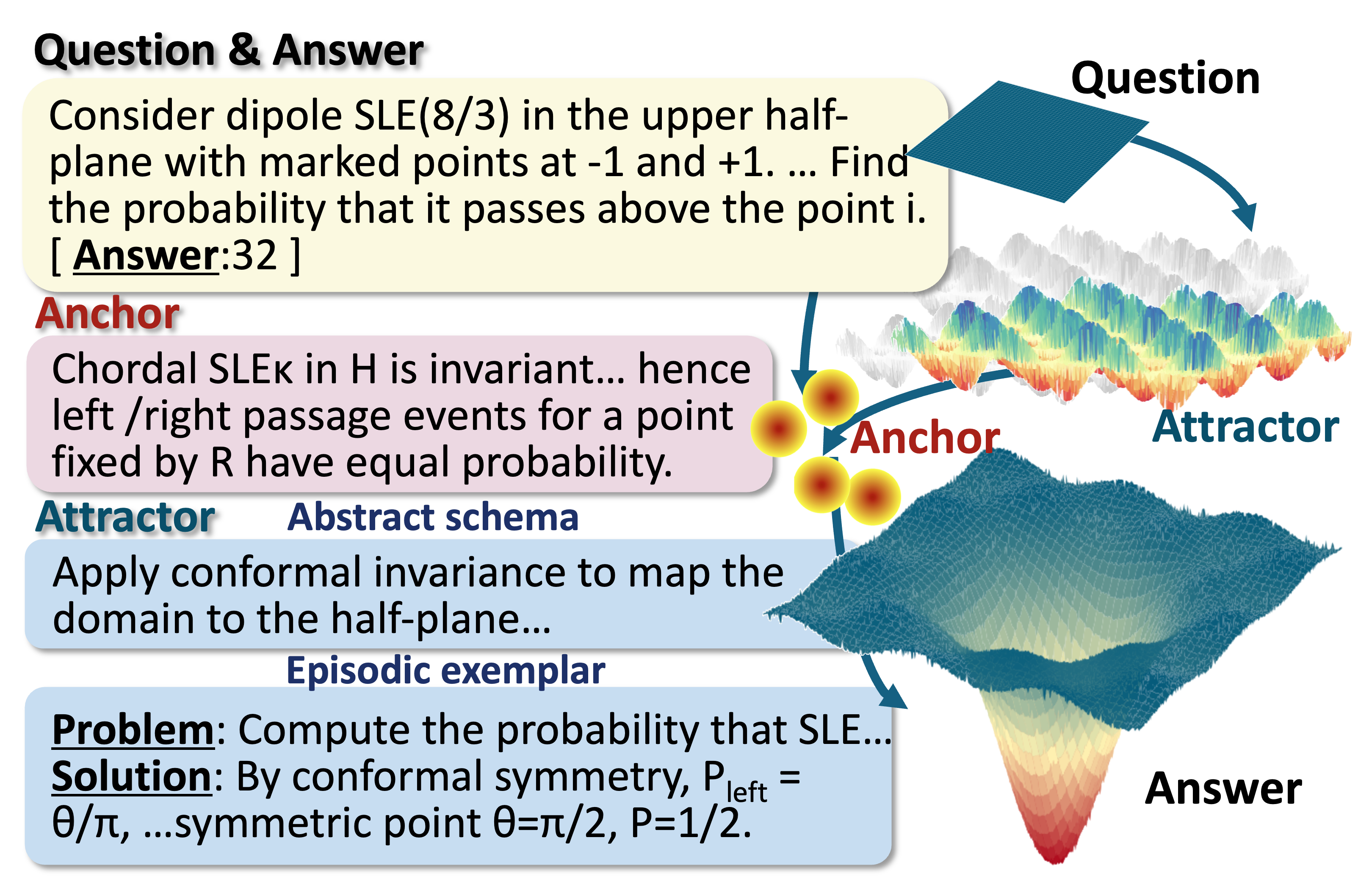
Figure 3: Example of a math problem annotated for A3-Bench.
HybridRAG Framework for Memory Activation
For experimental validation, a HybridRAG architecture supports dual retrieval over memories: the Memory Twin-Needle Activator utilizes both dense (semantic similarity) and graph-based (logical relation) retrieval across the anchor–attractor graph; the Context Fabric Composer serializes and integrates activated memory with the problem statement for prompt construction. This design is engineered for interpretable, efficient, and cognitively aligned activation and composition.
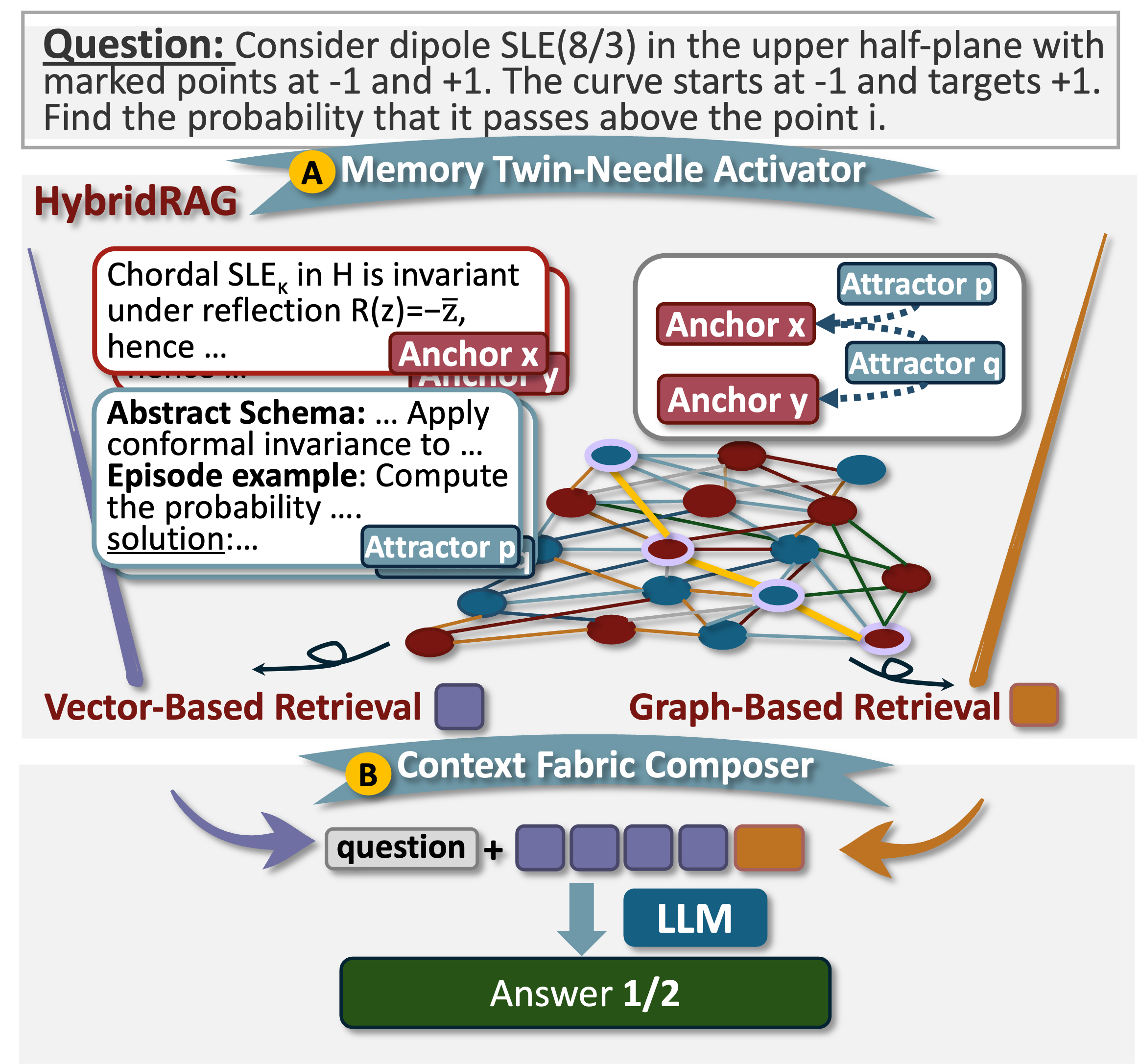
Figure 4: Schema of the A3-Bench dataset in HybridRAG, showing the twin-needle retrieval modules and context composition workflow.
Experimental Design and Paradigms
Benchmarking is performed under three memory paradigms: (i) Vanilla—no external memory, parametric knowledge only; (ii) Anchor {content} Attractor Activation—unfiltered activation from the full annotated memory; (iii) Annotated Activation—restricted, human-verified memory snippets. A new metric, AAUI (Anchor–Attractor Utilization Index), quantifies semantic memory activation for each answer.
Quantitative and Error-Type Analysis
Across ten leading LLMs including Grok-4-Fast, Qwen3-30B, DeepSeek-V3.2, Claude-Haiku-4.5, and others, consistent increases in accuracy are observed—from 34.71% (Vanilla) to 48.19% (Annotated Activation, +13.48). Gains are most pronounced on hard instances, indicative of memory activation's role in enabling complex multi-step solutions and narrowing the difficulty gap. AAUI shows strong correlation with model accuracy and error reduction: models with high AAUI (Grok-4-Fast, Qwen3-30B) realize substantial performance and error mitigation on challenging problems, confirming the diagnostic value of memory activation metrics.
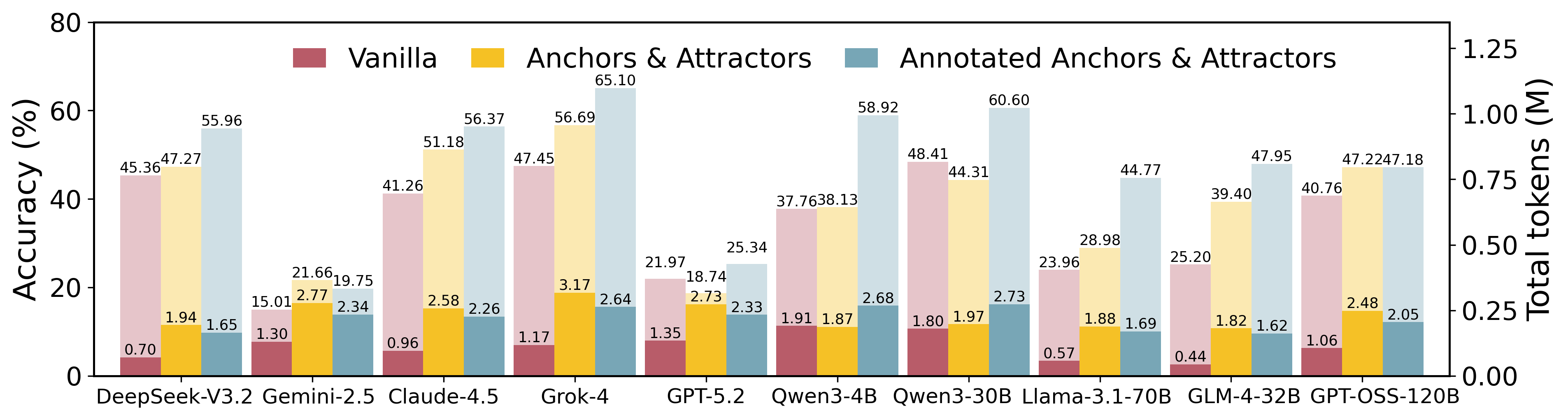
Figure 5: Performance and token utilization across ten LLMs for three memory paradigms: Vanilla, Anchor {content} Attractor, and Annotated Activation.
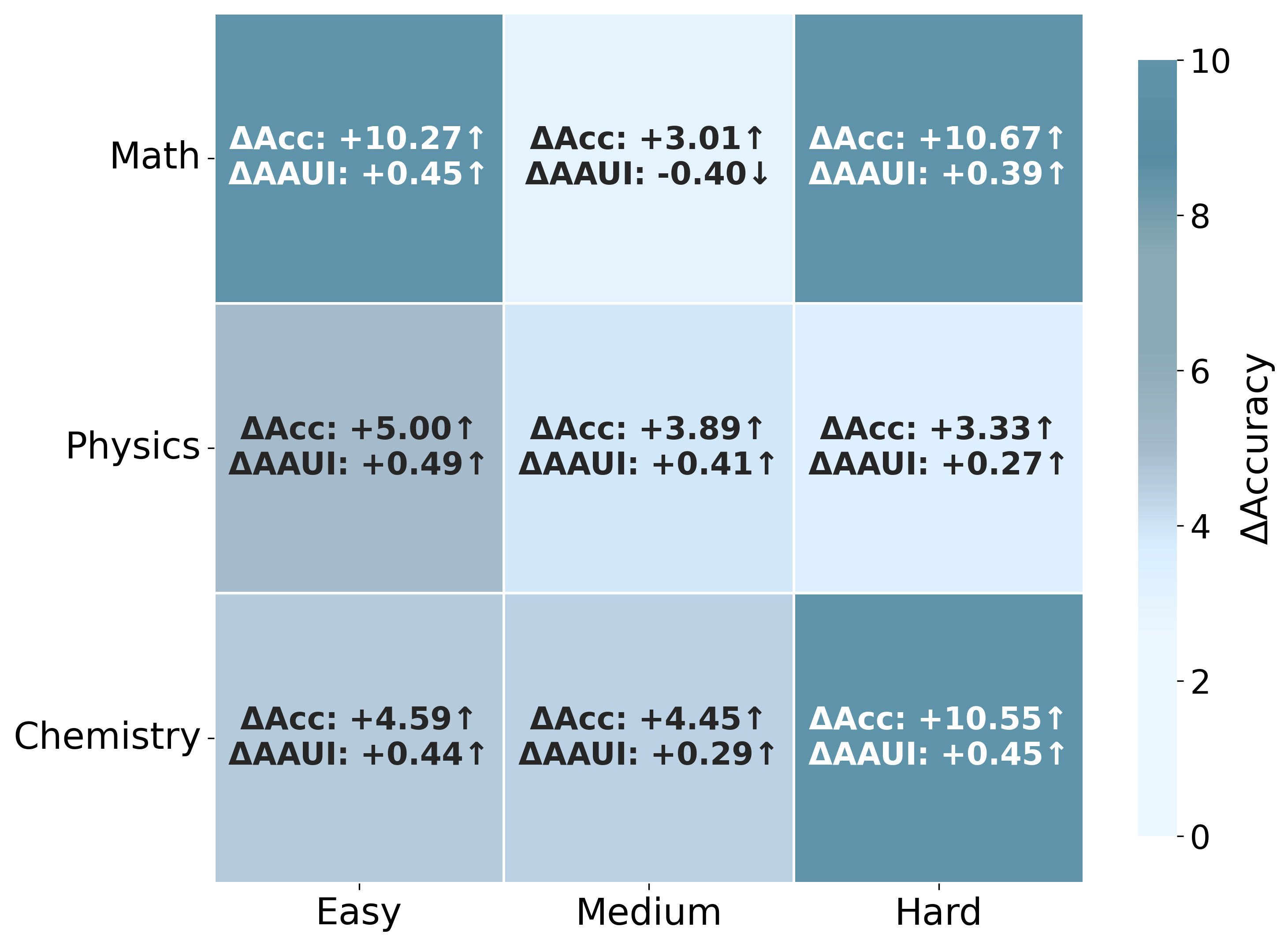
Figure 6: Heatmap of accuracy and AAUI gains across subject domains and difficulty levels (Grok-4-Fast, Annotated versus Both modes).
Memory Paradigm Robustness and Interaction
Isolating anchors or attractors reveals complementary performance dependencies. Attractor-only activation typically outperforms anchor-only, especially for procedural domains; however, neither achieves the dual paradigm's effectiveness, and each memory type's benefit varies across models and subject domains. Significance testing (McNemar's test) confirms combined activation as essential for maximal scientific reasoning fidelity.
Inference Latency and Efficiency
Memory activation, particularly with annotated selection, reduces average inference latency by 2.1 seconds/question while increasing accuracy, demonstrating not just cognitive alignment but computational efficiency. Larger models show greater improvements, suggesting superior utilization of structured memory context during inference.
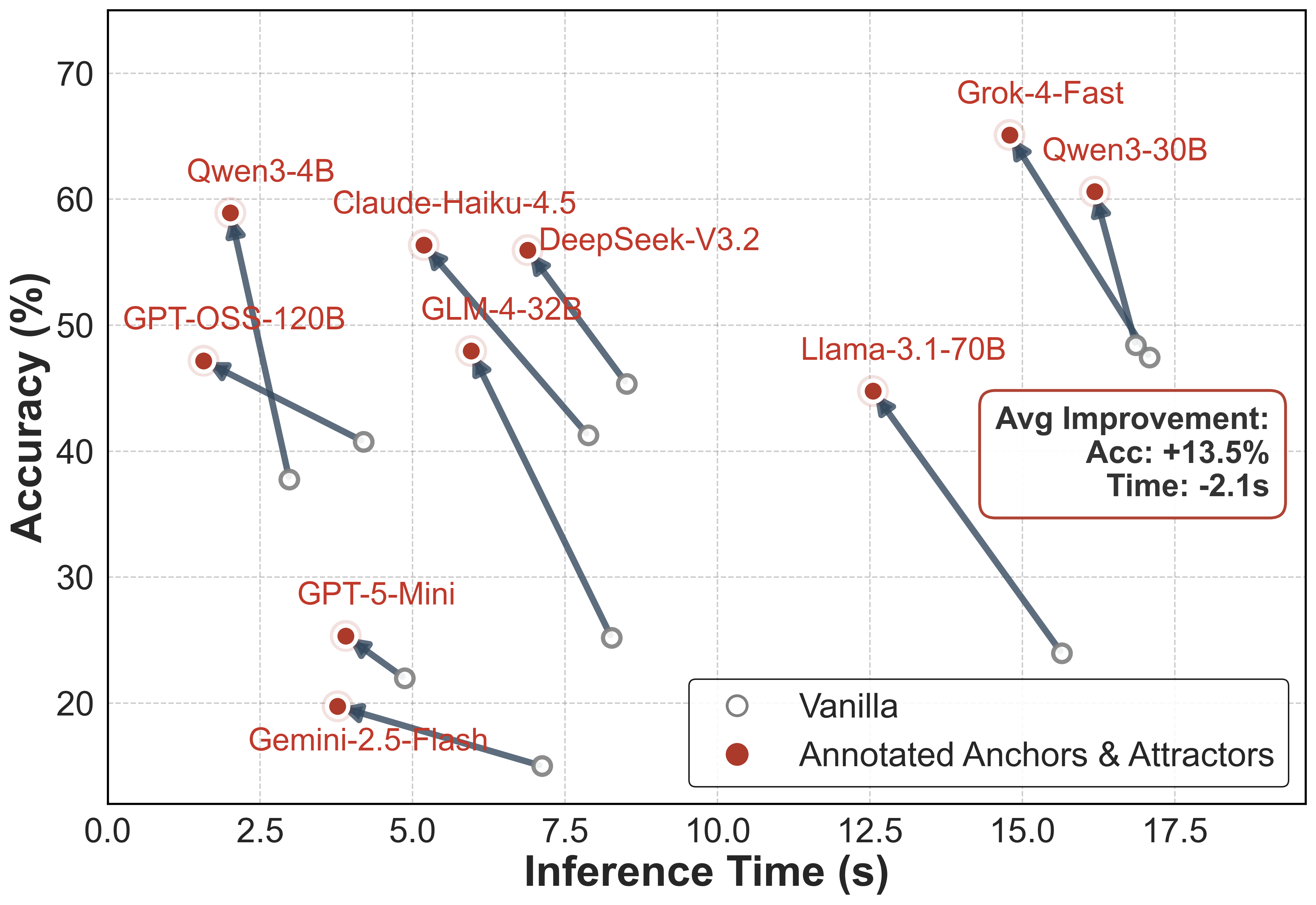
Figure 7: Shift in accuracy vs. average inference time under annotated anchor/attractor activation.
Error Distributions and Memory Relevance
Memory-driven paradigms substantially reduce reasoning and knowledge errors. The effect is sensitive to memory signal relevance—noise injection experiments show monotonic performance degradation as relevant annotated memory is replaced by irrelevant content. This underscores that raw memory volume is insufficient; precise matching and composition are critical.
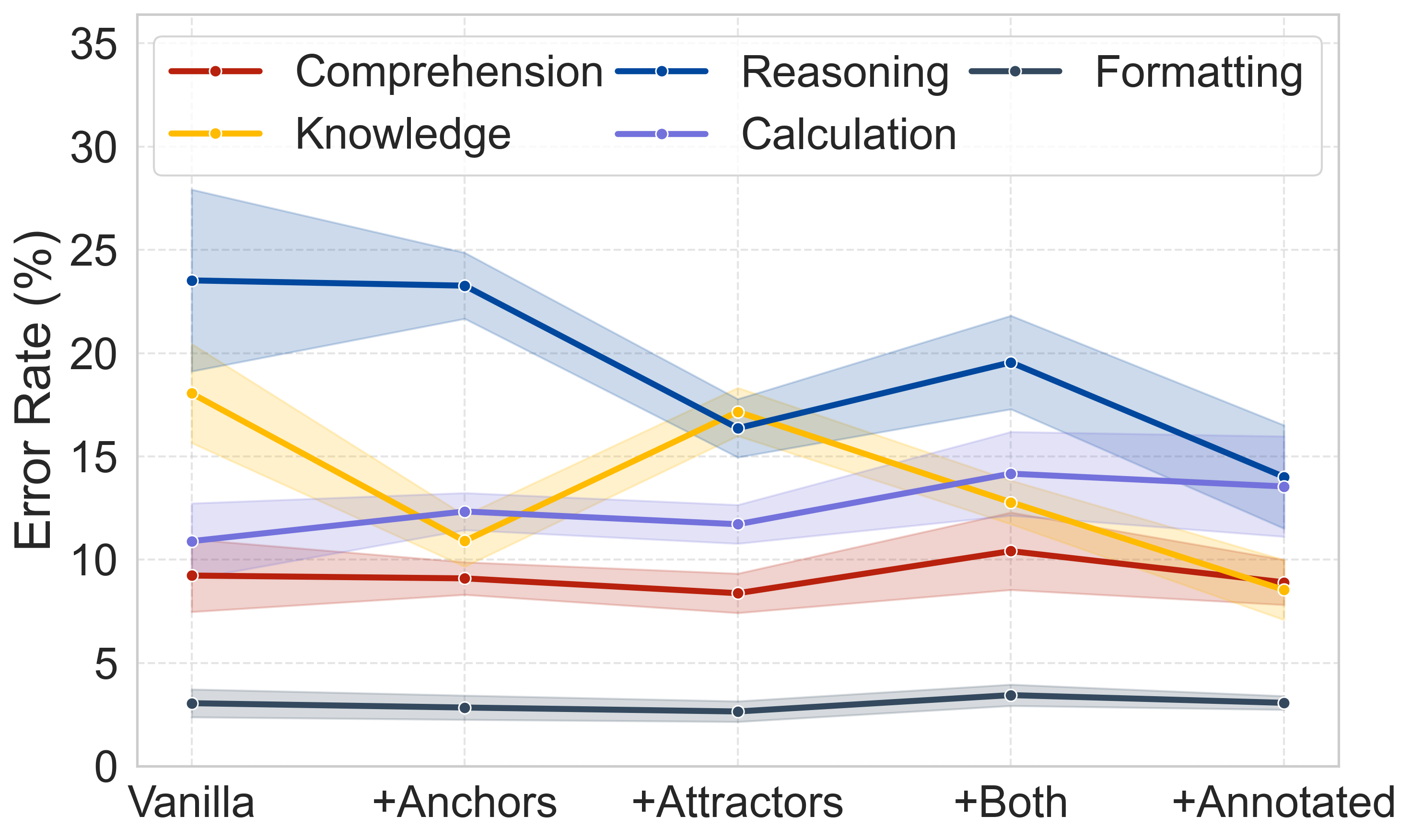
Figure 8: Evolution of error distributions across paradigms: reasoning, knowledge, calculation, formatting, and comprehension errors.
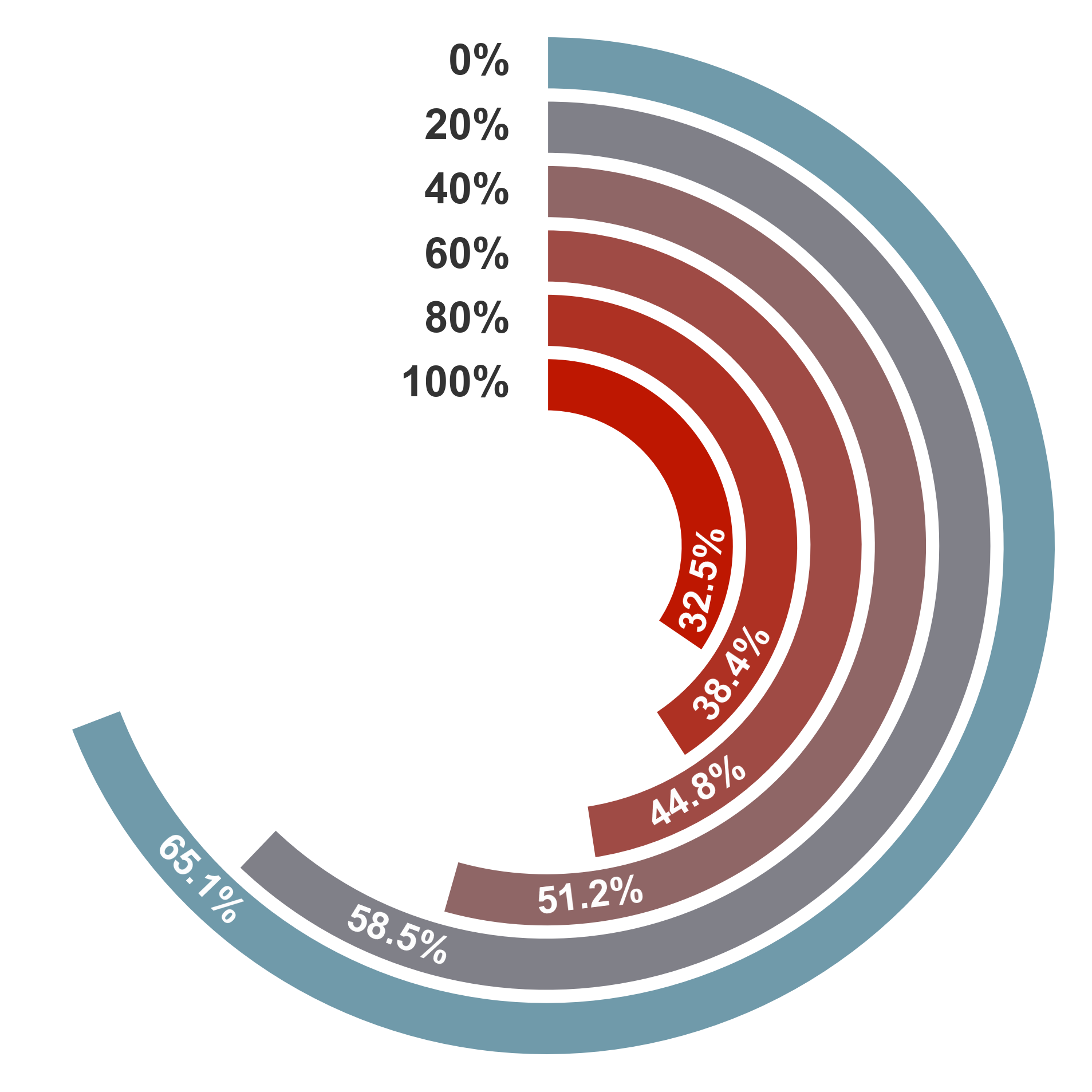
Figure 9: Radial bar chart of accuracy degradation under increasing noise memory replacement ratios (Grok-4-Fast).
Case Studies
Success and failure cases demonstrate the operational mechanism: correct activation of both anchors (definition, formulas) and attractors (reasoning schemas) yields valid multi-step solutions, whereas irrelevant or misaligned memory retrieval leads to incorrect or incoherent reasoning chains.
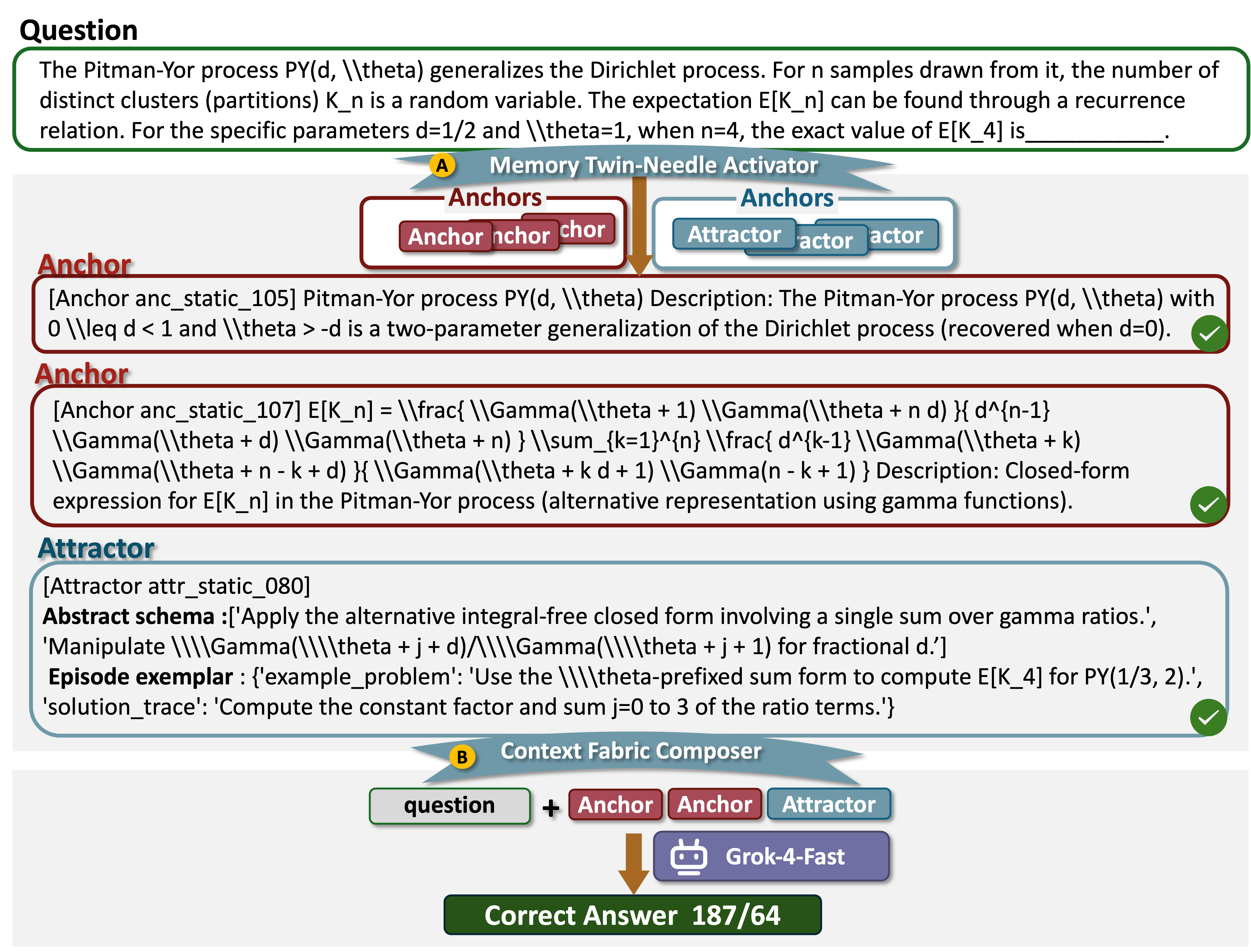
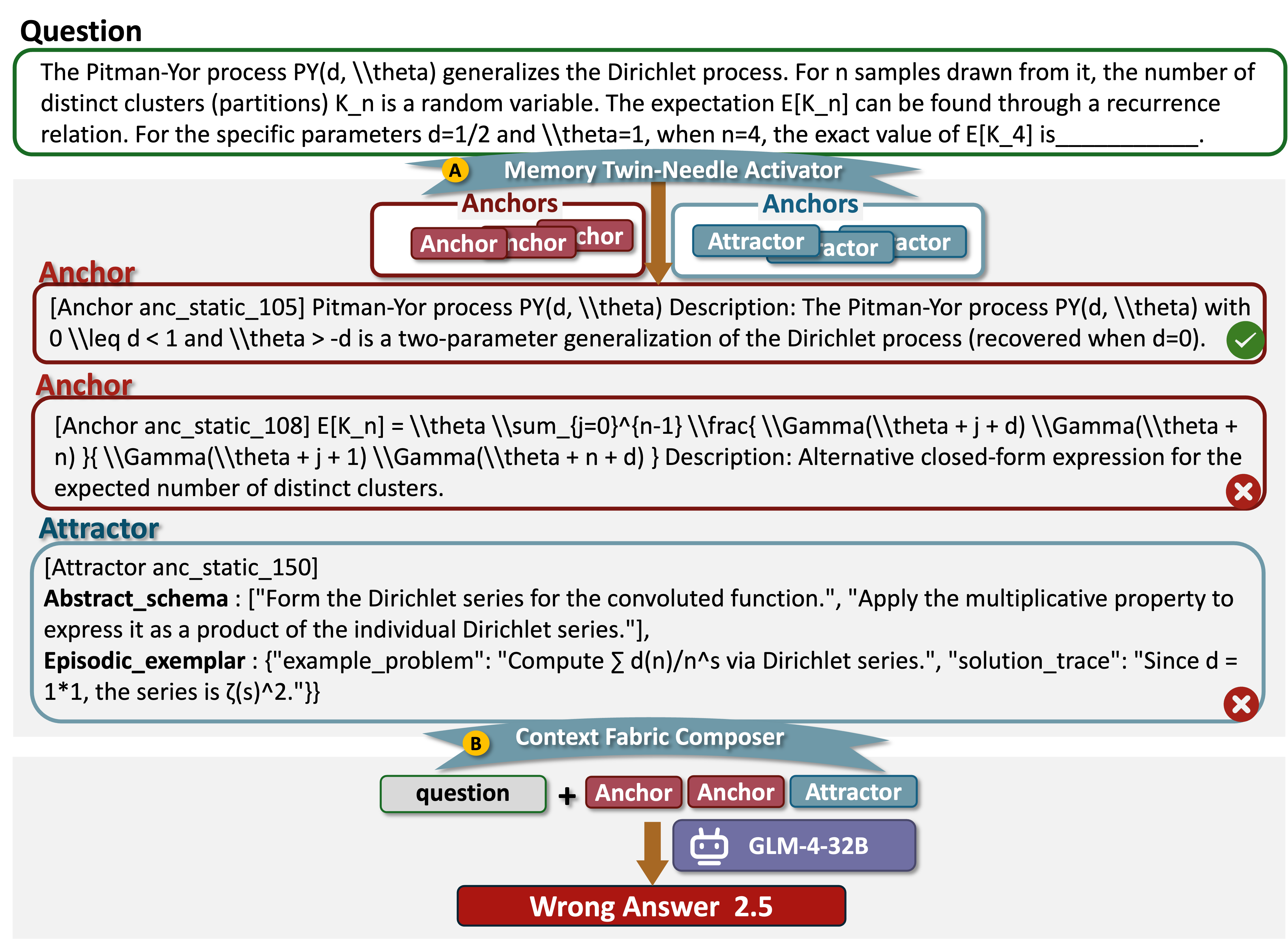
Figure 10: Example of successful activation (TheoremQA, Grok-4-Fast)—relevant memory retrieval and composition yield correct answer.
Implications, Theoretical and Practical
The A3-Bench framework advances the evaluation of LLM scientific reasoning by (1) bridging the gap between final-answer metrics and cognitive process fidelity, (2) enabling fine-grained diagnosis of model limitations in memory utilization, and (3) supporting research in memory composition, context relevance, and agentic alignment. Practically, the benchmark will accelerate progress toward more robust scientific problem-solving agents, and theoretically, it provides the groundwork for future exploration of neural mechanisms mapping anchors and attractors to attractor basin dynamics in model inference.
Conclusion
A3-Bench substantiates the necessity of explicit memory-driven frameworks in the assessment and development of scientific reasoning capabilities in LLMs. By introducing structured dual-scale annotations, actionable memory activation metrics, and cognitively motivated experimental paradigms, it enables rigorous, interpretable, and theoretically grounded evaluation. Future directions include expanding the taxonomy, refining retrieval algorithms for optimal anchor–attractor alignment, and exploring memory-enhanced architectures that natively encode and activate such hierarchical procedural and declarative knowledge.