- The paper introduces a two-pronged framework combining PAIR for physics-aware interaction retargeting and D-STAR for decoupled spatio-temporal policy learning.
- The paper achieves state-of-the-art results with a contact-preservation F1 score of 0.841 and a 75.4% success rate on contact-sensitive tasks.
- The paper demonstrates effective real-world deployment using a Unitree G1 and monocular RGB-based SMPL pose estimation for live human-humanoid interaction.
Whole-Body Human-Humanoid Interaction Learning from Human-Human Demonstrations
Introduction and Motivation
Physical human-humanoid interaction (HHoI) is an outstanding challenge in robotics, requiring nuanced capabilities far beyond single-agent motor proficiency. The central barrier is the lack of rich and diverse interaction data, as direct robot data acquisition is expensive, risky, and limited in coverage. While large-scale human-human interaction (HHI) datasets exist, leveraging them is nontrivial due to significant morphological and control discrepancies between humans and humanoid robots. The naive application of motion retargeting techniques to transfer HHI to HHoI commonly fails, as essential physical contacts—key to the semantics and safety of the interaction—are not preserved (Figure 1).
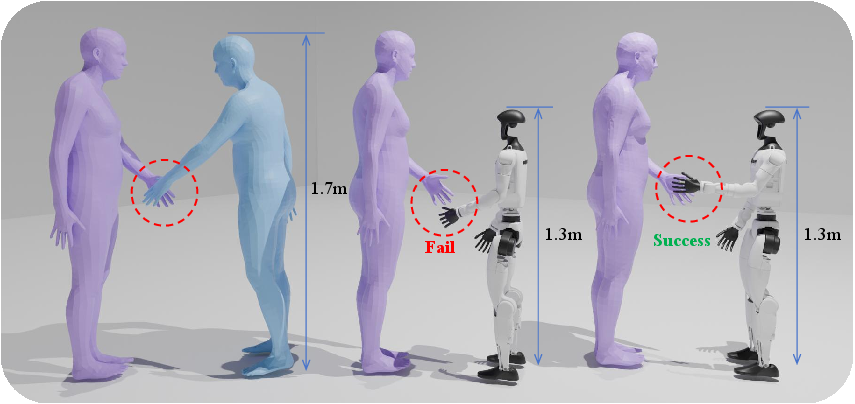
Figure 1: PAIR (right) preserves physical contact in retargeted HHoI where naive kinematics-based retargeting (center) breaks essential handshake contact.
To address data and policy limitations, this work introduces a two-pronged framework: Physics-Aware Interaction Retargeting (PAIR) for dataset generation and Decoupled Spatio-Temporal Action Reasoner (D-STAR) for hierarchical policy learning. Together, these components enable the synthesis and deployment of responsive, robust, and physically consistent interaction behaviors in high-DoF humanoids using only human demonstration data.
Physics-Aware Interaction Retargeting (PAIR)
PAIR targets the core challenge of translating HHI sequences to HHoI in a manner that explicitly preserves the geometry and timing of contacts, going beyond simple kinematic or pose similarity. The method formulates retargeting as a multi-objective optimization problem defined over both the human (partner) and the humanoid, incorporating:
- Kinematic similarity loss: Preserves overall motion style relative to a morphologically matched human skeleton.
- Interaction-contact preservation loss: Enforces global pairwise spatial structure between agent keypoints (not just individual point contacts), maintaining semantic integrity of interactions.
- Human motion fidelity loss: Allows graduated upper-body adaptation of the human partner to accommodate robot morphology while preventing unnatural deviation.
- Regularization: Ensures physical plausibility and smoothness in the generated robot motion.
Critically, PAIR employs a coarse-to-fine two-stage optimization: kinematic alignment provides a feasible initialization, followed by an increased emphasis on contact preservation to ensure actual physical consistency, thus mitigating local minima that plague single-stage approaches. This is essential for realistic downstream use in policy learning.
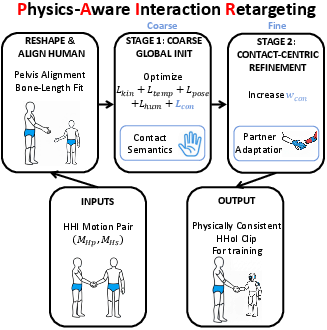
Figure 2: PAIR's two-stage retargeting pipeline. From HHI to HHoI while preserving interaction semantics, even across significant morphological disparities.
Empirical results demonstrate that PAIR surpasses standard baselines (e.g., MSE-based, IK-based, orientation-based, and SOTA unsupervised retargeting [Yan et al., ImitationNet 2023]) in both contact-preservation F1 scores and motion smoothness—without sacrificing kinematic accuracy. Ablation reveals all terms (human adaptation, contact objective, and staged optimization) are critical for optimal performance.
Large-Scale HHoI Dataset Generation
PAIR is used to create a novel, large-scale HHoI dataset by systematically retargeting diverse HHI sequences (contact-rich, gestural, and social) from Inter-X to the robot domain. The approach features:
This dataset forms the basis for training data-driven HHoI policies that go beyond simple motion mimicry.
The D-STAR Policy: Decoupled Spatio-Temporal Action Reasoner
The policy challenge in HHoI is not simply to imitate average demonstrated motion, but to coordinate when to act (temporal intent) and where to act (spatial precision) in response to dynamic humans. Imitation learning directly on trajectories, even with modern architectures (Transformers, Diffusion Policies), fails to yield robust or synchronous interaction, as it entangles phase reasoning with spatial targeting.
D-STAR addresses this by explicit architectural decoupling. The policy comprises:
- Phase Attention (PA): Dedicated to inferring the temporal segment (Preparation, Act, Follow-up) for the current interaction, employing specialized self-attention blocks and supervised by manual phase annotations.
- Multi-Scale Spatial Module (MSS): Encodes proximity-aware geometric features (relative positions, orientations, distance zones) for precise contact generation.
- Fusion by conditional Diffusion: A global conditioning vector flows into a diffusion-based planning head, which produces future action anchors, enabling synchronized, whole-body responses nontrivially aligned to human behavior, not average motion.
Hierarchical control is realized by executing diffusion-planned actions through a robust, distilled whole-body controller (WBC) in both simulation and real-world settings.
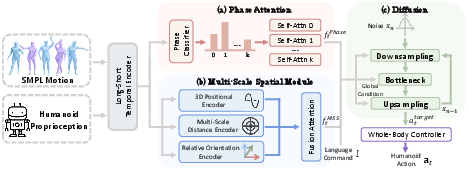
Figure 4: D-STAR policy architecture—Phase Attention (when to act) and Multi-Scale Spatial (where to act) modules, fused by diffusion model and closed by WBC.
Perception and Sim-to-Real Execution
Deployment is validated on a Unitree G1 with asynchronous monocular RGB-based SMPL human pose estimation and robust extrinsic calibration. The perception stack, employing 4D-Humans for mesh estimation, supports live, embodied interaction without reliance on robot-side teleoperation or privileged state input.

Figure 5: Monocular RGB perception pipeline for real-robot deployment. (a) G1 platform with camera; (b) input frame; (c) SMPL mesh estimation mapped to robot frame.
Experiments and Results
Dataset and Retargeting Quality
PAIR achieves a micro-averaged contact-preservation F1 of 0.841 at a 0.35 m threshold, a 67.5% improvement over best preexisting methods, with best-in-class smoothness (69% reduction in jerk). All components significantly contribute, with staged optimization preventing “near-miss” artifacts.
Policy Success and Generalization
On six challenging tasks, D-STAR delivers 75.4% average success rate—substantially outperforming TCN (49.2%), Transformer (64.3%), and even Diffusion Policy (58.7%), all under unified controllers and datasets. The improvement is especially pronounced on contact-sensitive tasks (e.g., Handshake: 61.3% for D-STAR vs 32.3% for Transformer). Ablations confirm necessity of the decoupling: removing either the PA or MSS module consistently degrades performance in temporally or spatially demanding subtasks.
Robustness evaluations under systematic variation in human scale and speed further confirm that the D-STAR architecture does not merely memorize specific motion instances, but acquires a generalizable, embodiment-aware interaction model that adapts to variable partners.
Implications and Outlook
By coupling interaction-aware data generation with a policy architecture specialized for joint spatio-temporal reasoning, this approach breaks the imitation barrier in HHoI. It enables data-efficient, scalable, and physically accurate interactive skill learning on high-DoF platforms using only human demonstrations, thus obviating the need for expensive or unsafe robot-side data collection. As shown, the architecture can be integrated with modern perception pipelines and standard whole-body controllers for practical execution.
Future work will extend to broader social behaviors, multi-partner interaction, and adaptive scene dynamics, leveraging the same philosophy of explicit representation and decoupled reasoning. The principles underlying PAIR and D-STAR can also inform robust policy designs in other high-dimensional, contact-rich domains, accelerating generalization and transfer in humanoid learning.
Conclusion
This work systematically addresses fundamental barriers in data acquisition and policy expressiveness for whole-body HHoI. PAIR enables large-scale, contact-faithful dataset construction from standard HHI, and D-STAR achieves robust, generalizable policies that synchronize temporal and spatial reasoning for embodied interaction. The demonstrated pipeline sets a new standard for truly interactive human-robot collaboration, merging scalable data generation with hierarchically structured, phase-aware policies.
References
- "Learning Whole-Body Human-Humanoid Interaction from Human-Human Demonstrations" (2601.09518)
- Yan et al., "ImitationNet: Unsupervised human-to-robot motion retargeting via shared latent space" (Humanoids 2023)
- Goel et al., "Humans in 4D: Reconstructing and Tracking Humans with Transformers" (ICCV 2023)
- Xu et al., "Inter-X: Towards versatile human-human interaction analysis" (CVPR 2024)
- Chi et al., "Diffusion Policy: Visuomotor policy learning via action diffusion" (IJRR 2023)
