- The paper introduces TEMPO, a benchmark that integrates expert-curated queries, LLM-assisted evidence mining, and explicit temporal annotations for enhanced temporal retrieval evaluation.
- It employs step-wise retrieval planning and novel metrics like Temporal Precision@k, Temporal Relevance@k, and Temporal Coverage@k to assess multi-hop evidence synthesis across 13 diverse domains.
- Experimental results reveal that reasoning-enhanced models outperform sparse baselines, yet significant challenges persist in achieving comprehensive cross-period synthesis and effective evidence integration.
TEMPO: A Multi-Domain Benchmark for Temporal Reasoning-Intensive Retrieval
Motivation and Background
Temporal information retrieval and question answering have become central in numerous application domains, especially given the increasing need for systems that can track phenomena, compare states across time periods, and synthesize temporally grounded evidence. Existing temporal QA benchmarks emphasize simple date matching within news corpora, while reasoning-intensive retrieval benchmarks such as BRIGHT and RAR-b lack explicit temporal grounding and do not assess cross-period synthesis. TEMPO directly addresses the gap by targeting temporally grounded, reasoning-intensive retrieval needs through complex queries drawn from expert discussions across 13 diverse domains.
Benchmark Construction and Characteristics
TEMPO contains 1,730 naturally occurring Stack Exchange queries spanning blockchain, social sciences, applied fields, and @@@@10@@@@ disciplines. Queries average ~300 words and are annotated at three levels: query, reasoning steps, and passage. Each query is accompanied by a step-wise retrieval plan and positive/negative documents are curated via combined LLM-assisted mining and expert verification for challenging realism. The positive documents are temporally aligned, addressing both topical and temporal information needs, while hard negatives are topically analogous but temporally incomplete or misaligned.
Figure 1: Overview of TEMPO construction pipeline: expert-curated queries, LLM-assisted evidence mining, and systematic negative sampling ensure temporally challenging retrieval.
Comprehensive temporal annotations include: temporal intent classification, temporal signals, key temporal events, fine-grained reasoning class assignment (ten classes), explicit time anchors, passage-level ISO interval tagging, and gold document mappings for each step in retrieval plans. Multi-hop evaluation supports queries requiring retrieval and synthesis across multiple periods. Annotation rigor is validated via dual-expert review and LLM-based quality metrics—mean alignment scores reach 87.0 (Qwen-72B judge).
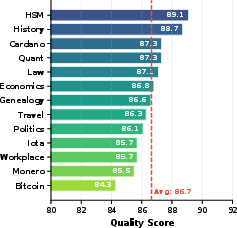
Figure 2: Dataset quality validation using Qwen-72B as LLM judge shows consistent high annotation alignment across domains.
The query distribution reflects extensive temporal diversity, covering Pre-1900 to the present, with a bias toward domains where long-range historical reasoning and technical evolution are prevalent.
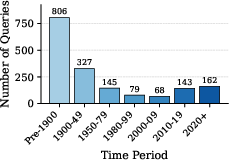
Figure 3: Distribution of query temporal anchors across periods emphasizes cross-epoch coverage crucial for temporal synthesis.
Temporal Reasoning Taxonomy and Dataset Scope
Each query is categorized into one of ten temporal reasoning classes, with Event Analysis and Localization (EAL) and Time Period Contextualization (TPC) dominating, followed by Origin/Evolutionary Comparative (OEC) and Trends/Cross-Period Comparison (TCP).
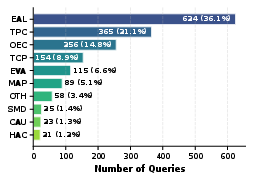
Figure 4: Distribution of temporal reasoning classes indicates a prevalence of localization, context, and comparative synthesis tasks in realistic IR.
Step-wise retrieval planning decomposes queries for multi-hop temporal reasoning, enabling empirical evaluation of whether systems can follow logical evidence synthesis across targeted time periods.
Novel Temporal Metrics
Conventional IR metrics such as NDCG@10 fail to capture temporal appropriateness and cross-period synthesis. TEMPO introduces:
- Temporal Precision@k (TP@k): Position-weighted metric for temporally relevant document ranking.
- Temporal Relevance@k (TR@k): Proportion of top-k results judged temporally pertinent by LLM-as-judge.
- Temporal Coverage@k (TC@k): Measures fraction of required periods covered, critical for trend/cross-period queries.
- NDCG|Full Coverage@k: Conditional ranking metric for queries where all necessary periods are covered.
Both cross-period and single-period annotations are enforced via LLM-driven protocols, with robust meta-evaluation confirming that metrics penalize blindly high NDCG scores on temporally incorrect outputs.
Experimental Results
12 retrieval architectures—spanning sparse (BM25), dense (BGE, Contriever, E5, SFR), and reasoning-enhanced (DiVeR, ReasonIR, Rader)—are evaluated. Dense and reasoning models outperform sparse retrieval by wide margins (BM25: 10.8 NDCG@10; DiVeR: 32.0 NDCG@10). However, absolute scores remain low due to the temporal synthesis difficulty, with top temporal coverage near 71.4% at rank 10. Reasoning models show greater consistency across reasoning classes, but trends/cross-period (TCP) queries remain the most challenging (avg. 17.9 NDCG@10).
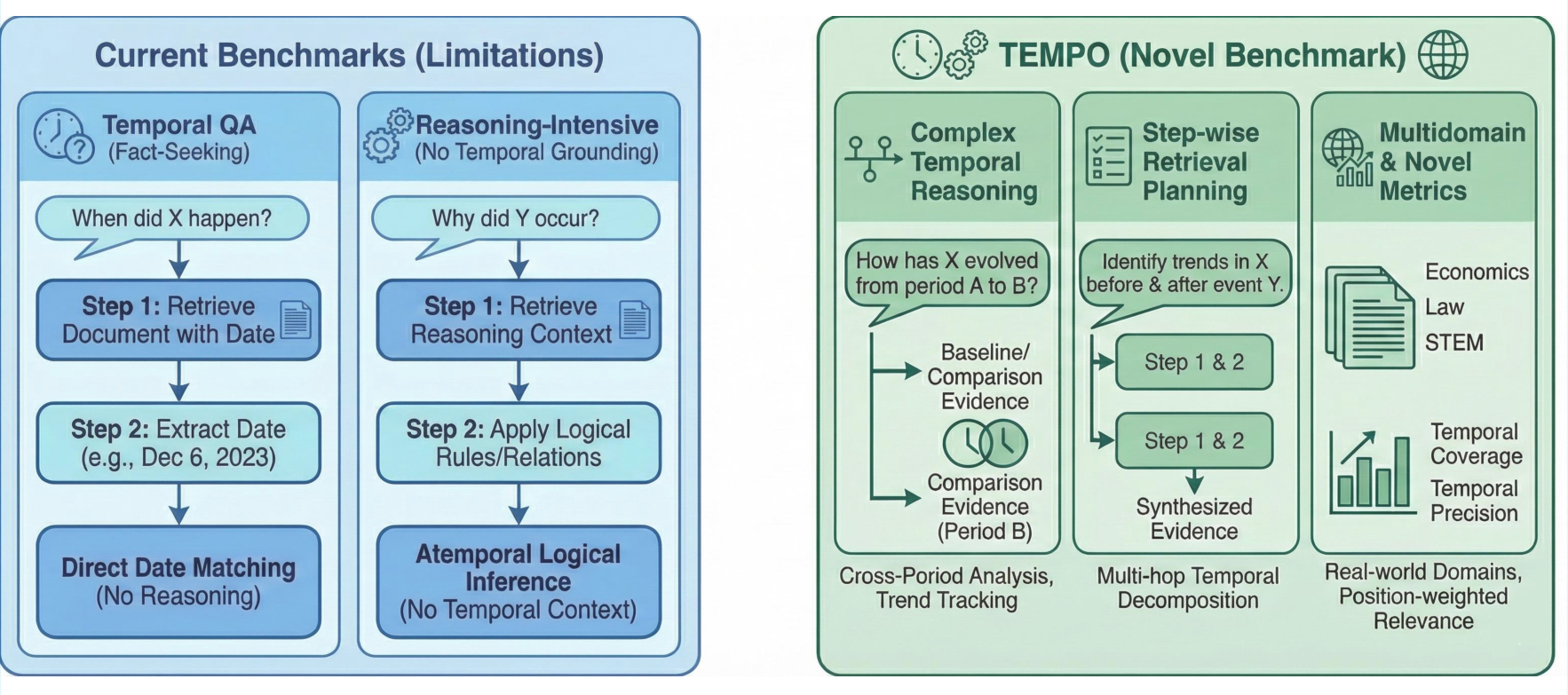
Figure 5: TEMPO design integrates complex temporal reasoning, step-wise retrieval, and bespoke temporal metrics for multi-domain challenges.
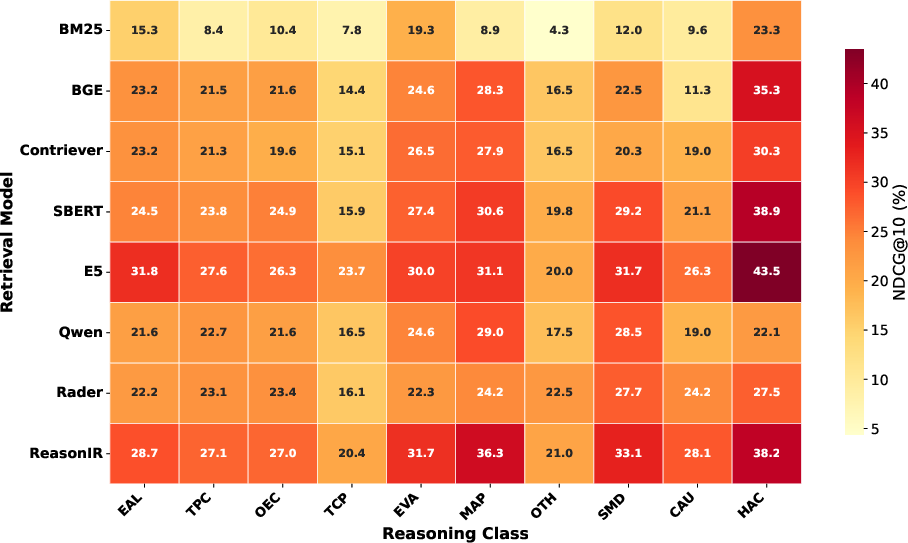
Figure 6: Heatmap visualizing strong model-class interaction effects—DiVeR and ReasonIR show uniformity, BM25 has high class sensitivity.
Performance variation by domain reflects technical and historical complexity: policy/legal and STEM (HSM) queries allow higher temporal coverage, while blockchain and quantitative domains show more fragmentation.
Step-wise retrieval planning yields gains for reasoning models: ReasonIR improves >18 points with step-wise augmentation; conversely, BM25 cannot leverage decomposition and is hampered by dilution of lexical signals.

Figure 7: Query-augmented retrieval (Query+Step, Query+All) consistently surpasses isolated step strategies across most dense/LLM architectures.
Ablation studies show that removing temporal signals induces only modest performance degradation, but stripping topical context devastates temporal-only query performance. Explicit normalization of temporal intent dramatically boosts performance for instruction-tuned reasoning models.
Augmenting queries with LLM-generated reasoning steps substantially improves reasoning-aware retrievers (ReasonIR +11 NDCG@10 with GPT-4o reformulation), while sparse retrieval is consistently harmed. DiVeR's performance remains stable, suggesting internalized reasoning robustness.
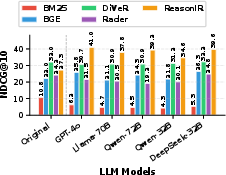
Figure 8: LLM-based reformulation increases performance for reasoning models but dilutes retrieval for term-matching baselines.
Retrieval-augmented generation (RAG) using best-in-domain retrievers does not yet surpass parametric QA—temporal incompleteness in retrieved evidence actively degrades downstream generation, as seen by RAG scores trailing the no-retrieval baseline. Oracle retrieval yields a substantial headroom (+3.2 points over the generator), revealing persistent limitations in evidence integration, particularly for temporal and comparative synthesis.
Temporal Distribution and Domain Profiling
Domain-wise decomposition highlights unique temporal signatures: blockchain queries are concentrated post-2010; social sciences and STEM emphasize historical depth; applied domains are bimodal. This breadth ensures robust coverage and evaluation of temporal reasoning patterns.
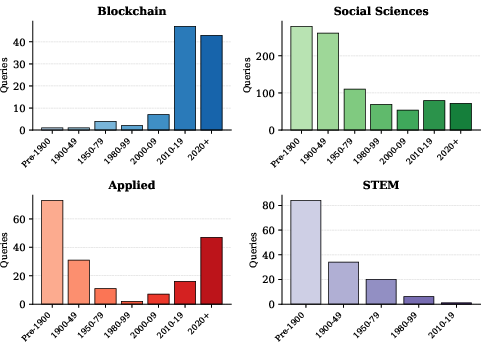
Figure 9: Distinct anchor period distributions by domain illustrate the diverse temporal profiles captured in TEMPO.
Implications and Future Directions
TEMPO’s empirical results demonstrate that current retrieval and RAG systems are limited in handling temporally complex, cross-period queries. Precision-oriented dense and specialized reasoning architectures show measurable gains, but significant gaps remain for synthesis tasks and evidence integration. The introduction of multi-level temporal annotations and LLM-as-judge metrics sets a new standard for evaluation, suggesting future research directions in architecture, fine-grained supervision, and metric robustness for temporal IR and RAG.
A logical avenue for future extension involves expansion to non-English domains, integration of long-range and multidomain temporal histories, and architectural innovations expressly targeting step-wise evidence synthesis and causal-temporal reasoning. Recognition of temporal coverage and multi-hop evidence selection is essential for moving beyond date matching toward holistic retrieval and generation systems.
Conclusion
TEMPO establishes a rigorous multi-domain challenge for temporal reasoning-intensive retrieval, representing an overview of expert-level technical queries, realistic evidence mining, and sophisticated temporal evaluation. The benchmark and analysis reveal that progress in temporal IR and RAG is non-trivial; both model design and evaluation protocols must evolve to address the full complexity of real-world temporally grounded information needs.
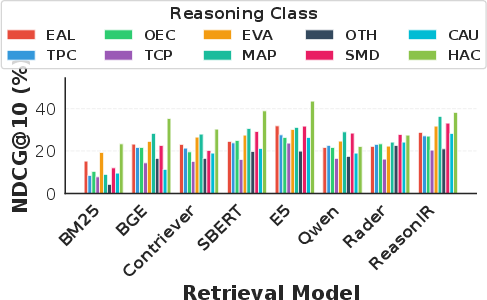
Figure 10: Performance by reasoning class—trend and cross-period comparison consistently present maximum retrieval difficulty, reflected in suppressed NDCG@10 scores regardless of model.
Figure 6: Model/class heatmap confirms broad variance with high performance consistency only in reasoning-enhanced architectures.
TEMPO will serve as an indispensable testbed for advancing system-level capabilities in temporally aligned retrieval, multi-hop reasoning, and evidence-grounded RAG, with broad implications for downstream AI tasks in technical, scientific, and societal domains.