- The paper introduces a benchmark that combines multimodal queries and reasoning-intensive retrieval across diverse technical domains.
- It evaluates four retrieval tasks and shows that state-of-the-art models struggle, especially when essential visual cues are critical for technical reasoning.
- Empirical results reveal that augmenting queries with image captions or query reformulation only offers modest gains, emphasizing a gap between semantic matching and true reasoning.
MM-BRIGHT: A Multimodal Benchmark for Reasoning-Intensive Retrieval
Motivation and Benchmark Design
The MM-BRIGHT benchmark addresses a critical gap in information retrieval evaluation: the lack of benchmarks that combine multimodal queries—particularly those that mix images and text—with reasoning-intensive information needs spanning complex technical domains. While prior work in retrieval benchmarks has either centered on semantic or surface-level alignment in text and multimodal settings, or focused on reasoning but in exclusively textual domains, MM-BRIGHT is the first to require joint multimodal and reasoning ability. The dataset is constructed from 2,803 expert-curated real-world queries from Stack Exchange, covering 29 diverse technical domains including STEM, computing, applied sciences, and social sciences.
To systematically probe multimodal reasoning challenges, MM-BRIGHT defines four retrieval tasks of increasing complexity (Figure 1):
Figure 1: The four retrieval tasks in MM-BRIGHT range from text-only (i) to complex multimodal-to-multimodal retrieval (iv), requiring varied levels of visual reasoning and context integration.
- Text-to-Text retrieval (Task 1): Baseline text query to documents, controlling for reasoning.
- Multimodal-to-Text retrieval (Task 2): Multimodal (text+image) query to documents, requiring integration of visual context into retrieval.
- Multimodal-to-Image retrieval (Task 3): Multimodal query to images, necessitating visual inference and similarity assessment.
- Multimodal-to-Multimodal retrieval (Task 4): Retrieval of document+image pairs conditioned on multimodal queries; the hardest setting, demanding unified triaging of both modalities.
The annotation process systematically integrates expert judgment and LLM-based negative mining (see Figure 2).
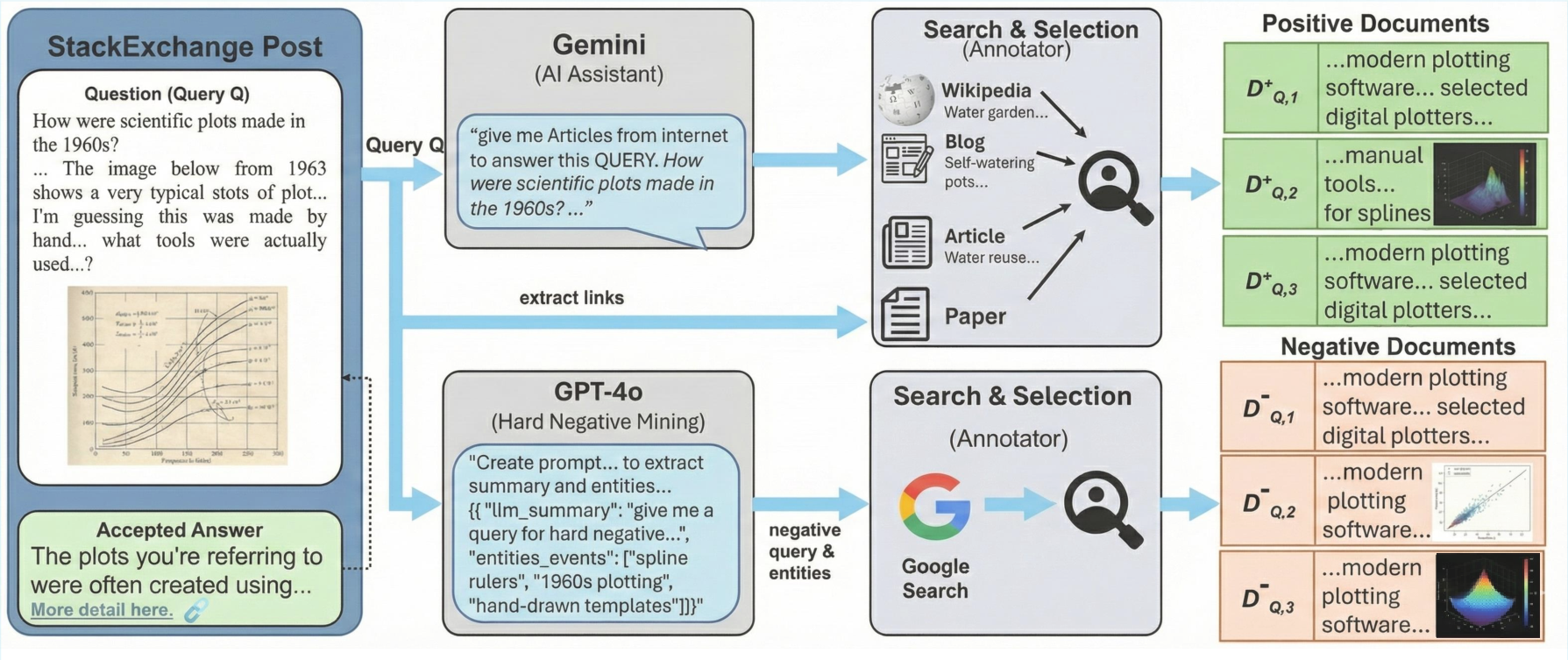
Figure 2: MM-BRIGHT annotation involves AI-assisted (Gemini, GPT-4o) and expert-human curation of relevant positives, and hard negative mining, across multi-source, multi-modal evidence pools.
Dataset Properties and Analysis
MM-BRIGHT distinguishes itself by the diversity and essentiality of visual content:
- Image Typology: The dataset includes a wide range of image types (Figure 3)—photos, diagrams, charts, screenshots, scientific figures, mathematical notation, and more—mirroring real-world technical communication practices across domains.
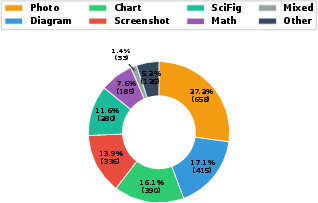
Figure 3: Substantial diversity across image types ensures evaluation across a spectrum of visual reasoning challenges, from technical schematics to scientific imagery to screenshots.
- Image Essentiality: Over 90% of queries include images critical ("essential") or contextually important ("helpful") for understanding the information need (Figure 4), reflecting that the benchmark cannot be solved by ignoring visual components.
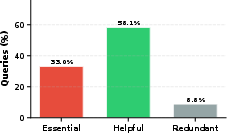
Figure 4: Most queries contain images that are essential (33.0%) or helpful (58.1%) for correct reasoning, with only 8.8% considered redundant.
- Domain Breadth: Covered domains span highly visual STEM problems, software debugging (screenshots), financial analysis (charts), and even humanities cases requiring interpretation of philosophical diagrams or religious artwork.
- Rigorous Quality Control: Each example undergoes multi-stage human verification, and GPT-4o-based judgment yields high scores for readability, clarity, and evidence sufficiency (Figure 5).
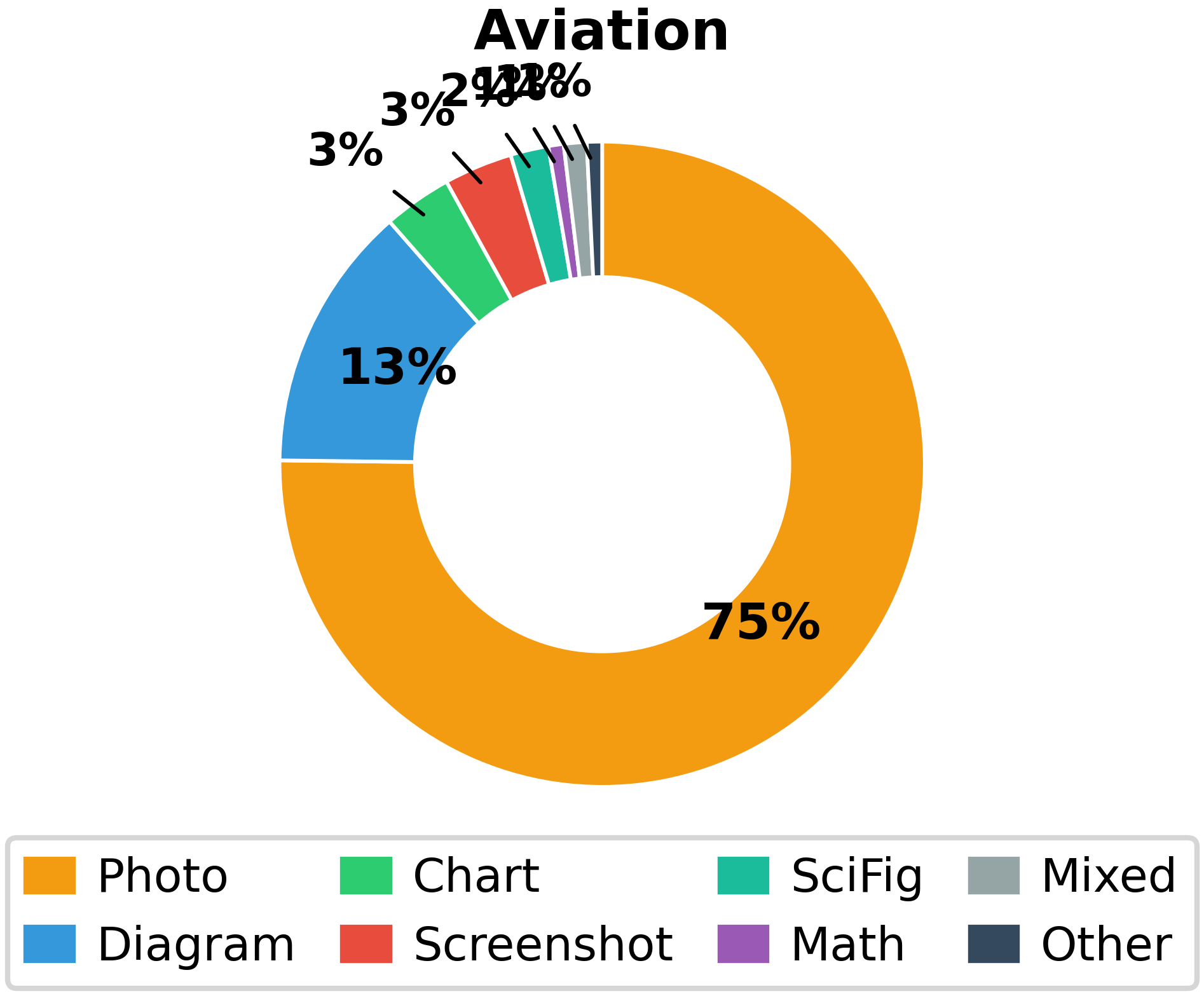
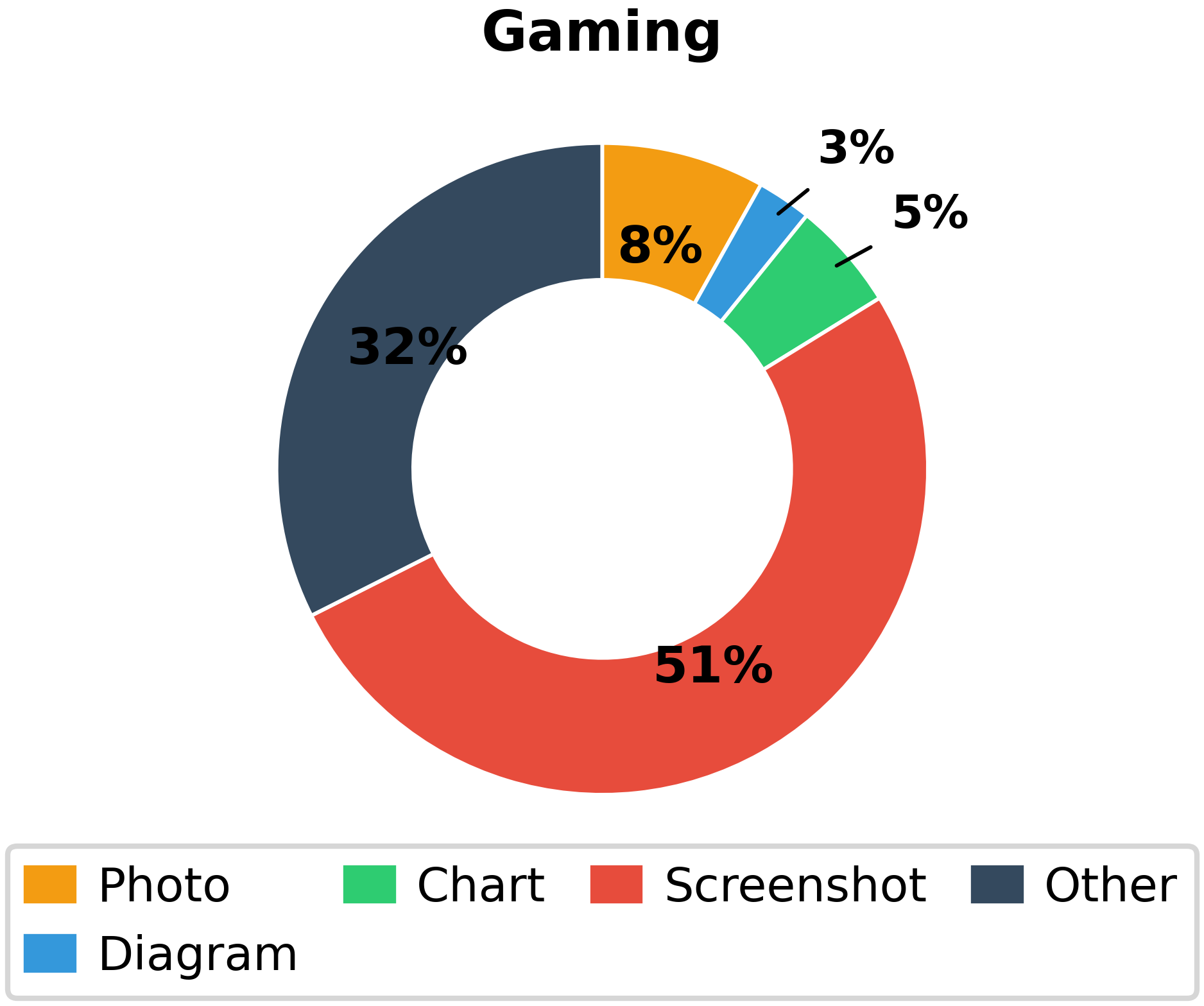
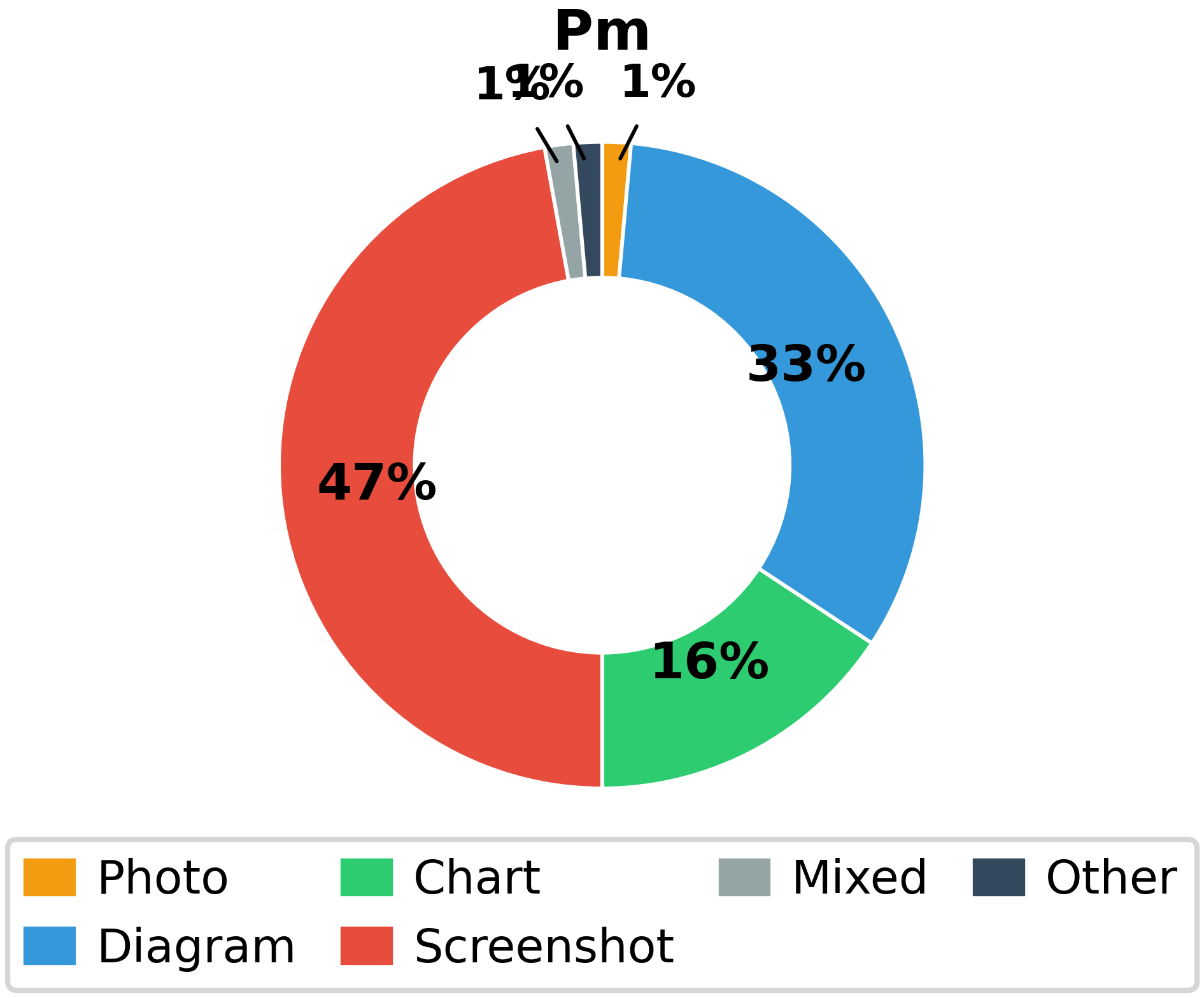
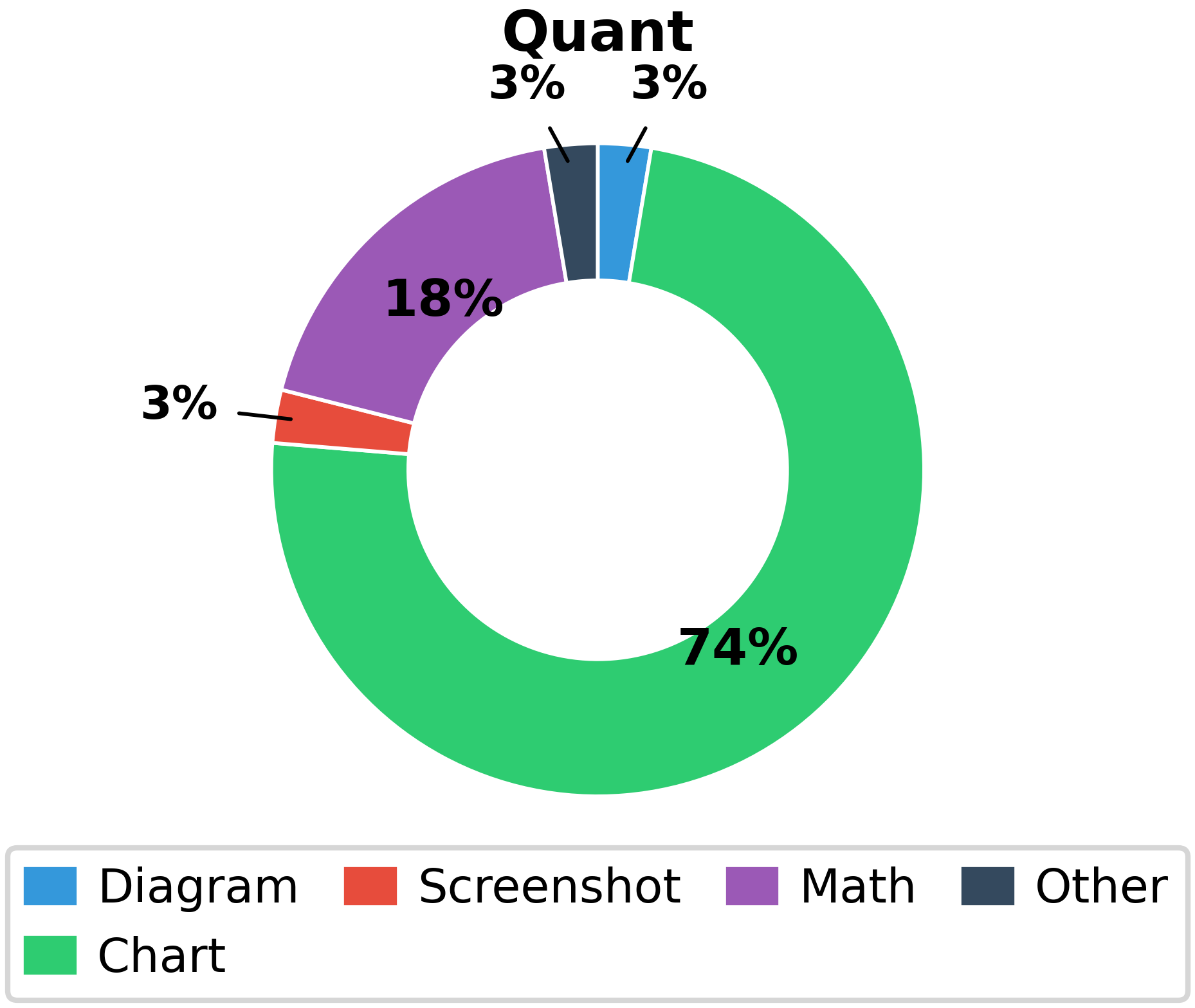
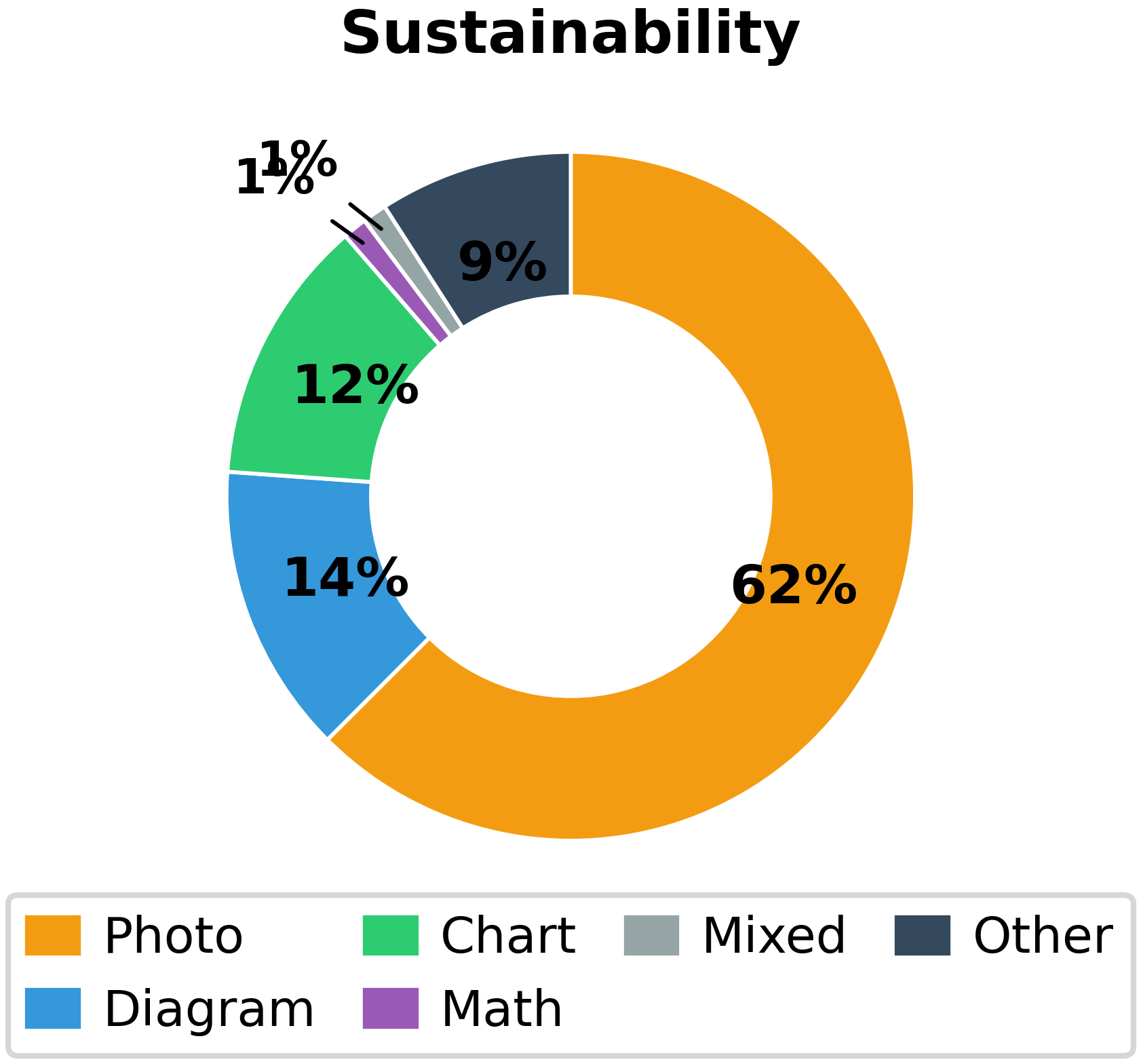
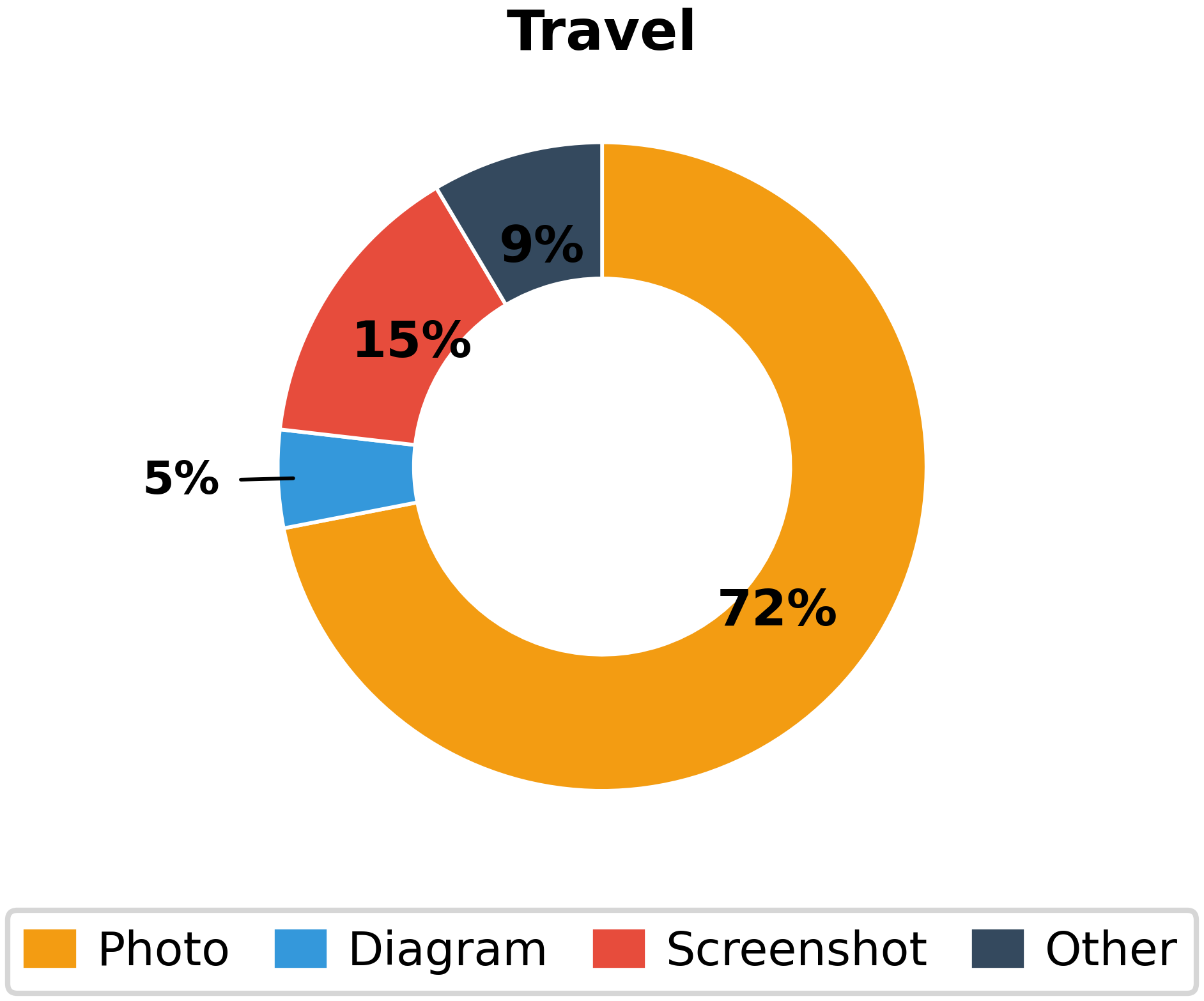
Figure 5: LLM-judged dataset quality: queries are clear, evidence is typically sufficient, but the benchmark remains reasoning-intensive.
Model Evaluation and Numerical Results
Eighteen strong baseline retrievers (sparse, dense, reasoning-enhanced, multimodal) were evaluated. Key findings:
- Reasoning Bottleneck, Not Semantics: On Task 1 (text-to-text), BM25 achieves only 8.5 nDCG@10, while the best reasoning-focused retriever, DiVeR, reaches 32.2. This is substantially lower than typical BEIR-style benchmarks, indicating the challenge requires true inference beyond semantics.
- Multimodality Degrades, Not Improves, Performance: Unexpectedly, adding images to the queries (Task 2) hurts retrieval quality relative to text-only strong baselines: the best multimodal model, Nomic-Vision, attains 27.6 nDCG@10—below DiVeR on text-only (32.2). Other multimodal models also fail to exploit visual data effectively, with some (e.g., BGE-VL) devolving to BM25-level scores.
- Visual Retrieval Outperforms Joint Retrieval: For image retrieval (Task 3), GME-2B reaches 45.6 nDCG@10, benefiting from visual similarity, but this performance is not mirrored in the fully joint multimodal retrieval (Task 4), where the best performance (CLIP: 28.0) again falls short, highlighting a modality alignment gap.
- Impact of Captioning and Query Reformulation: Augmenting queries with LLM-generated image captions improves semantic retriever performance but disrupts reasoning retrievers (see Figure 6). Explicit query reformulation (Figure 7) produces only modest or inconsistent gains—strongest for semantic retrievers, but minimal or negative for top reasoning models.
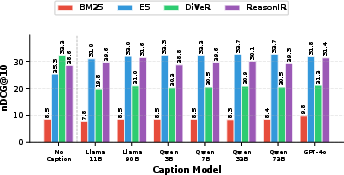
Figure 6: Image captioning boosts semantic retrievers (E5), but impairs reasoning-based retrievers (DiVeR), demonstrating tension between semantic enrichment and reasoning specificity.
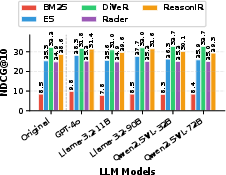
Figure 7: Query reformulation via vision-LLMs yields modest or inconsistent retrieval improvements, with negligible effect for top reasoning retrievers.
- Performance by Image Essentiality: All evaluated models underperform specifically when images are labeled "essential" (Figure 8), demonstrating current models cannot distinguish between critical and decorative visuals, and are brittle to reasoning requirements imposed by image content.
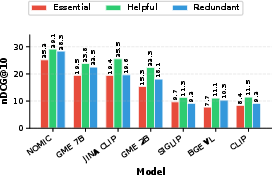
Figure 8: Models perform worst when images are essential, best on merely helpful visuals, indicating multimodal retrievers cannot exploit critical visual signals for reasoning.
Quantitative summary:
| Task |
Top Model |
nDCG@10 |
Surpasses Text-Only? |
| Task 1: Text-to-Text |
DiVeR |
32.2 |
— |
| Task 2: Multimodal-to-Text |
Nomic-Vision |
27.6 |
No (worse than DiVeR) |
| Task 3: Multimodal-to-Image |
GME-2B |
45.6 |
— |
| Task 4: Full Multimodal |
CLIP |
28.0 |
No (low absolute figure) |
Implications for Practical Retrieval Systems
The empirical results highlight two core failures in current retriever architectures:
Multimodal Integration Deficit: State-of-the-art vision-language retrieval models are largely trained for semantic correspondence or image-text alignment, not for visual reasoning with technical or symbolic content. As a consequence, the presence of crucial images actively confounds current systems. This result is reinforced by essentiality analyses: models not only fail to leverage visual evidence, but may be distracted or misled by it.
Separation of Semantics and Reasoning: The strong performance differential between semantic and reasoning-tuned models on both text-only and multimodal settings suggests that true progress requires new approaches that unify multi-step reasoning with deep multimodal representation, rather than simply fusing more modalities or adding larger-scale vision-language pretraining.
From a practical RAG (Retrieval-Augmented Generation) standpoint, oracle retrieval remains substantially better than best-model evidence, indicating that further improvements in retrieval could translate to concrete downstream question answering gains.
Directions for the Field
- Cross-modal Reasoning Mechanisms: Progress requires architectures that perform joint reasoning across modalities (e.g., diagrams+text), with explicit modeling of technical inference, rather than simple embedding-space alignment.
- Training Datasets and Objectives: New large-scale datasets and pretraining objectives are required that focus not only on cross-modal alignment, but specifically on reasoning-intensive scenarios with essential visual content.
- Evaluation by Essentiality: Benchmark construction, training, and evaluation must stratify by image essentiality, enforcing progress not just on decorative or redundant images.
- Vision-LLM Robustness: Simple strategies like image captioning or LLM-based query augmentation have fundamental limitations in reasoning settings and may not scale to high essentiality or symbolic reasoning tasks.
- RAG & Real-world Impact: Improved multimodal retrieval will yield strong benefits for domains where visual reasoning is indispensable, such as medicine, software engineering, and STEM research.
Conclusion
MM-BRIGHT defines a new challenge class for information retrieval, where neither semantic matching nor naive multimodal fusion suffices. It offers a clear direction for the development and evaluation of next-generation multimodal retrievers capable of bridging the gap between perception and technical reasoning. Empirical results show that state-of-the-art models—sparse, dense, or contrastive multimodal—are largely inadequate in this frontier, especially when images are essential information carriers. Addressing this will require new architectures and objectives centered on visual reasoning, robust cross-modal evidence integration, and domain-specific retrieval approaches.