- The paper introduces the Min-Seek method that enhances accuracy and stability in large reasoning models by retaining only critical elements of the KV cache.
- Min-Seek leverages a dynamic strategy that omits position embeddings in the KV cache to reduce computational complexity and avoid reasoning instability.
- Experimental results on tasks like AIME 2024 and MMLU-Pro highlight Min-Seek's superior performance in maintaining normalized accuracy and efficient resource usage.
"Thinking Long, but Short: Stable Sequential Test-Time Scaling for Large Reasoning Models"
Introduction
The paper introduces a novel approach to enhancing the accuracy and stability of large reasoning models (LRMs) through a method called Min-Seek, designed for sequential test-time scaling. Current methods to improve LRM accuracy often involve increasing the reasoning length, leading to instability and accuracy degradation beyond a certain threshold. Min-Seek addresses these issues by focusing on retaining only critical components of past reasoning sequences, thereby enabling more reliable and extended reasoning processes without training modifications.
Sequential Test-Time Scaling Challenges
Sequential test-time scaling offers a method to extend reasoning capabilities at test time without additional training, leveraging strategies to expand the duration of reasoning. Traditional methods often fall victim to degradation beyond an optimal reasoning length, due to an overload on the model's attention mechanisms leading to repetitive and unstable outputs. The proposed Min-Seek method targets this instability by adapting the management of past reasoning information within the model's knowledge base.
Methodology: Min-Seek
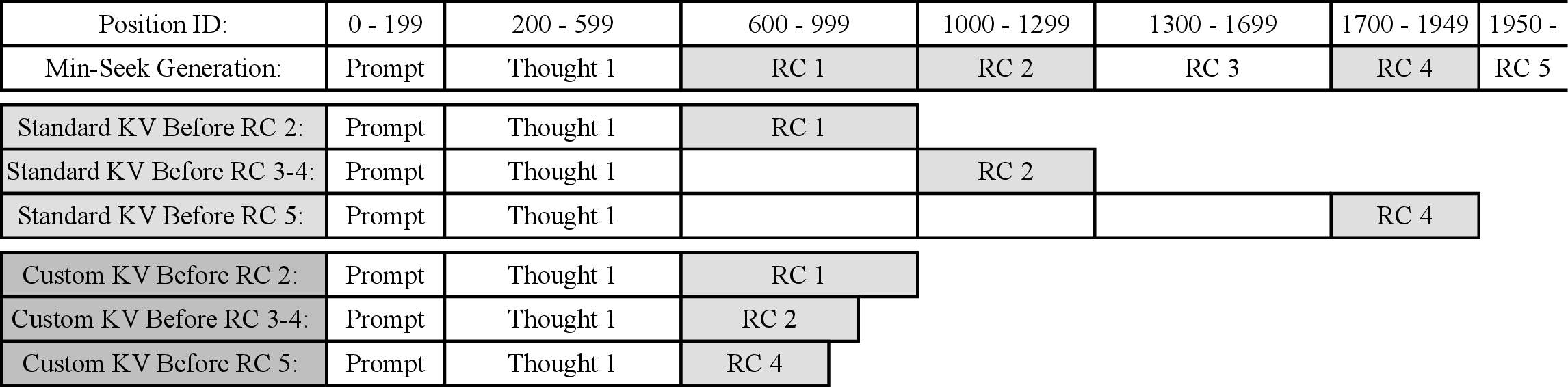
Min-Seek is engineered to manage the key-value pairs (KV cache) representing past reasoning cycles. By dynamically encoding these data structures and selectively maintaining only those associated with shorter, more cogent reasoning sequences, Min-Seek essentially cleanses the reasoning process of convoluted and erroneous paths. The objective is to filter out flawed reasoning logic often characterized by longer thought sequences that detract from accuracy.
KV Cache Strategy: Min-Seek introduces an enhancement to the KV cache, storing keys without position embeddings to facilitate unbounded reasoning capabilities beyond the model's maximum context length. This approach allows the model to focus on fewer induced thoughts, specifically maintaining the shortest reasoning cycle, thereby reducing computational complexity and improving decision coherence over extended reasoning periods.
Experimental Analysis
Experiments conducted using DeepSeek-R1 and its variants demonstrate Min-Seek's superiority over existing Budget Forcing methods in maintaining stability and accuracy across various reasoning tasks such as AIME 2024 and MMLU-Pro. Min-Seek consistently performed better as seen in:
Implications and Future Directions
Min-Seek provides a path toward more effective deployment of LRMs in tasks requiring extensive reasoning, offering benefits in both accuracy and computational efficiency. By integrating this method, LRMs can achieve more stable outputs over potentially infinite reasoning cycles, bypassing inherent context limitations. Future research could explore hybrid models combining both training-based and training-free enhancements for optimized performance across diverse AI applications.
Conclusion
Min-Seek emerges as a strong candidate in the repertoire of sequential test-time scaling methods, correcting traditional limitations through an innovative KV cache management technique. Its ability to maintain accuracy and stability over extended reasoning durations without additional training interventions highlights its practicality and potential for integration into next-generation LRMs.
The paper concludes that Min-Seek's framework could set a new precedent for sequential reasoning processes, reducing complexities and enhancing model responsiveness in dynamic reasoning environments.