Transition Matching Distillation for Fast Video Generation
Abstract: Large video diffusion and flow models have achieved remarkable success in high-quality video generation, but their use in real-time interactive applications remains limited due to their inefficient multi-step sampling process. In this work, we present Transition Matching Distillation (TMD), a novel framework for distilling video diffusion models into efficient few-step generators. The central idea of TMD is to match the multi-step denoising trajectory of a diffusion model with a few-step probability transition process, where each transition is modeled as a lightweight conditional flow. To enable efficient distillation, we decompose the original diffusion backbone into two components: (1) a main backbone, comprising the majority of early layers, that extracts semantic representations at each outer transition step; and (2) a flow head, consisting of the last few layers, that leverages these representations to perform multiple inner flow updates. Given a pretrained video diffusion model, we first introduce a flow head to the model, and adapt it into a conditional flow map. We then apply distribution matching distillation to the student model with flow head rollout in each transition step. Extensive experiments on distilling Wan2.1 1.3B and 14B text-to-video models demonstrate that TMD provides a flexible and strong trade-off between generation speed and visual quality. In particular, TMD outperforms existing distilled models under comparable inference costs in terms of visual fidelity and prompt adherence. Project page: https://research.nvidia.com/labs/genair/tmd




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a way to make AI systems that turn text into videos much faster without losing much quality. The method is called Transition Matching Distillation (TMD). It takes a slow, high-quality “teacher” video model that needs many tiny steps to make a video, and trains a faster “student” model to do the same job in just a few big steps.
Think of the teacher like an artist who draws a picture by making hundreds of tiny strokes. The student learns to make the same picture using only a handful of smart, well-planned strokes.
What questions are the researchers trying to answer?
They focus on three simple questions:
- How can we make high-quality video generation much faster?
- Can a small number of big steps replace hundreds of small steps without losing detail or motion consistency?
- How do we train a fast model to follow the same “style” and results as a slow, expert model?
How does their approach work?
To make this easier to understand, imagine cleaning a foggy photo until it’s clear:
- Traditional diffusion models “clean” the image a tiny bit at a time—hundreds of times—until it looks real.
- TMD replaces those many tiny clean-ups with a few big clean-ups. Each big step also includes a few quick touch-ups to refine details.
Here’s the idea in everyday terms:
- Split the model into two parts:
- Main backbone: like the “brain” that understands what the video should show (the scene, objects, motion).
- Flow head: like the “hands” that add crisp details and polish the frames. It’s small and fast, so it can run multiple quick refinements inside each big step.
- Two-stage training:
- The team adapts a technique called MeanFlow. Instead of learning every tiny step, the flow head learns to jump from a noisier point to a cleaner point directly—like skipping ahead on a cleaning timeline.
- This makes the flow head good at doing a few precise touch-ups per big step.
- 2) Distillation (learning from the teacher):
- The fast student is trained so its outputs look like the teacher’s outputs overall, not just at every tiny step. This is called distribution matching.
- They improved a known method (DMD2) for videos (their version is “DMD2-v”) by:
- Using a 3D video-aware “discriminator” (a checker that judges if a video looks real and matches the style).
- Carefully warming up with teacher guidance only when doing true one-step training.
- A “timestep shifting” trick that keeps training stable and prevents the model from collapsing to boring results.
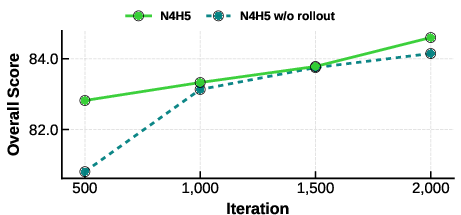
- They also “unroll” the flow head during training, which means they practice the exact same inner refinements they’ll use at test time, reducing training–inference mismatch.
A useful mental model:
- Outer transitions = big leaps from noise to video in a few stages (like big strokes of a drawing).
- Inner flow updates = small, fast refinements inside each big leap (like quick touch-ups to sharpen details).
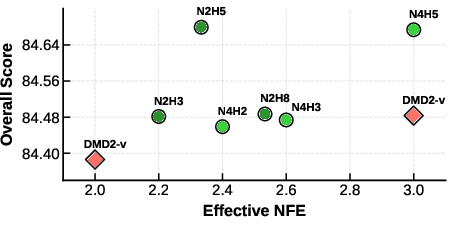
- Effective NFE (number of function evaluations) ≈ how many times you run the heavy parts of the network. Because the flow head is small, you can do multiple touch-ups without paying the full cost of a full pass each time—so you can get “fractional” compute counts.
What did they find?
They tested TMD on large, popular text-to-video models (Wan2.1 with 1.3B and 14B parameters) and evaluated with VBench (a standard video quality benchmark) and user studies.
Key results:
- Very few steps, strong quality:
- For the big 14B model, TMD achieved an overall VBench score of 84.24 with near-one-step generation (effective NFE = 1.38). That’s fast and competitive with much slower methods.
- For the 1.3B model, TMD reached overall scores around 84.7 with just ~2–3 effective steps, beating or matching other fast methods at similar or even higher cost.
- Better prompt following:
- In user studies, people preferred TMD over a strong baseline (their improved DMD2-v) especially for prompt alignment—meaning TMD’s videos matched the text descriptions better.
- Flexible speed–quality trade-off:
- By controlling how many big steps and how many quick inner refinements they run, TMD lets you dial in how fast you want to generate vs. how much quality you want to keep. Because the flow head is small, you can often add refinement cheaply.
Why this matters:
- It brings high-quality video generation much closer to real-time use, which is important for interactive tools, editing, and simulations.
Why is this important, and what could it lead to?
- Faster creativity: Artists and creators can generate or edit videos more quickly, trying more ideas in less time.
- Better interactive tools: Real-time or near-real-time video responses become more practical for apps and games.
- Training virtual agents/worlds: Faster generation helps build and update training environments on the fly.
- Lower costs: Fewer heavy steps mean less compute, which can make powerful video tools more accessible.
In short, TMD shows a practical way to keep the visual quality and prompt accuracy of big, slow models while making them fast enough for everyday, interactive use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be actionable for future research.
- Data provenance and bias: The distillation dataset comprises 500k videos generated by the Wan2.1 teacher, not real-world footage. It is unclear how training on synthetic teacher outputs impacts generalization, realism, diversity, and bias propagation. Evaluate TMD when trained on real video datasets and mixed real–synthetic corpora.
- Generalization to other backbones: TMD is demonstrated on DiT-style Wan models. Assess portability to other architectures (e.g., U-Net, hybrid autoregressive–diffusion, video transformers with different attention layouts) and different noise schedules without retuning all components.
- Scaling to longer videos and higher resolutions: Experiments focus on ~5s 480p outputs. Quantify performance, stability, and speed at 1080p/4K, higher frame rates, and durations of 30–60s+, including memory footprint and throughput constraints.
- Real-time latency and resource usage: The “effective NFE” metric approximates compute but does not report wall-clock latency, GPU memory, energy, or batch throughput on representative hardware. Provide standardized measurements across settings and compare against baselines under identical deployment constraints.
- Motion and temporal coherence metrics: Evaluation relies on VBench scores and 2AFC preference. Add temporal metrics (e.g., FVD, tLPIPS, identity consistency, trajectory smoothness), scene dynamics benchmarks, and compositional instruction adherence over time.
- Diversity vs. determinism: The inner flow rollout may reduce sample diversity if overly deterministic. Measure intra-prompt diversity and avoidance of mode collapse under varying inner-step counts and stochasticity injections.
- Failure cases and robustness: Document common failure modes (e.g., mode collapse noted under certain timestep settings, coarse artifacts with KD warm-up) and quantify robustness across challenging, compositional, and out-of-distribution prompts.
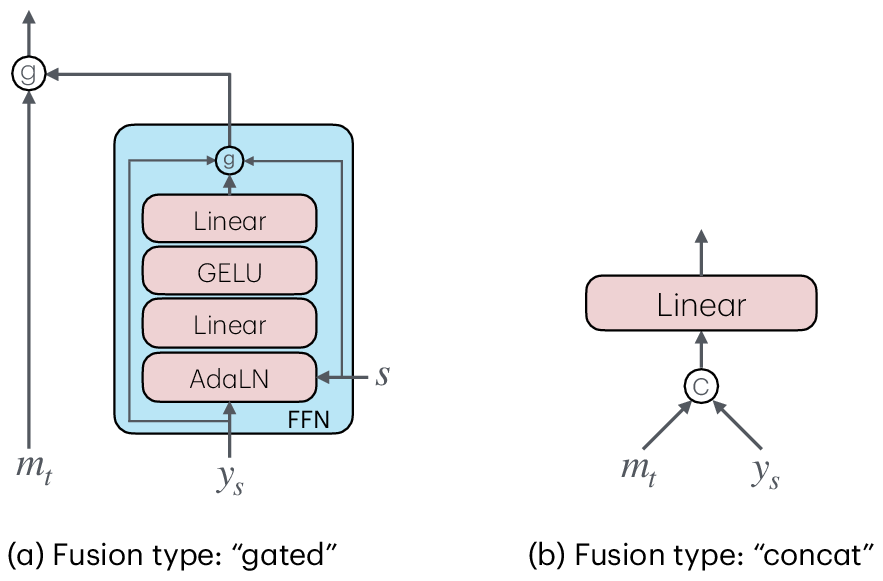
- Fusion mechanism design: The time-conditioned gating fusion (main backbone features with noisy inner-flow targets) is adopted without systematic comparison. Explore alternative fusion mechanisms (e.g., cross-attention, FiLM, residual adapters) and their impact on quality/efficiency.
- Flow-head target choice: The DTM target x1 − x is preferred over sample prediction, but the rationale is empirical. Characterize when each target is optimal (by noise schedule, task, architecture) and provide theoretical guidance.
- Selection of head depth and inner steps: Provide principled criteria or automated procedures for choosing the number of flow-head blocks H and inner steps N to hit specific quality/speed targets, including sensitivity analyses and scaling laws.
- Inner velocity estimation: The paper notes the lack of direct inner-flow velocity access and defers deriving it from teacher velocity for future work. Develop accurate, efficient inner velocity estimators and analyze their impact on training stability and sample fidelity.
- JVP approximation: Finite-difference JVP substitutes for forward-mode autodiff due to system constraints. Quantify the approximation error, its training impact, and whether improved JVP implementations (e.g., custom kernels) materially enhance convergence or quality.
- DMD2-v design choices: Timestep shifting (γ), GAN discriminator architecture (Conv3D), and KD warm-up are chosen heuristically. Systematically study these hyperparameters’ effects, provide selection guidelines, and analyze why KD warm-up harms multi-step distillation.
- Discriminator architecture space: Conv3D improves results, but attention-based and hybrid discriminators were limited. Explore richer architectures (e.g., video ViTs, multiscale patch discriminators, temporal coherence critics) and their effect on adversarial stabilization.
- One- vs. multi-step regimes: TMD improves one-step performance significantly but does not consistently beat strong two-step baselines for 14B. Investigate conditions under which TMD is superior or inferior (teacher size, prompt class, motion complexity) and adapt training accordingly.
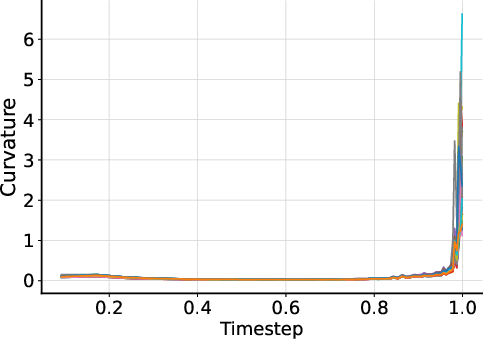
- Training stability and convergence: While rollout helps, no formal analysis is given. Provide stability diagnostics (loss landscapes, gradient norms, curvature), convergence criteria, and early-stopping strategies tailored to inner–outer loop interactions.
- Mismatch handling between train and inference: Rollout closes part of the gap, but behavior under different inner-step counts or head depths at inference is not studied. Test generalization when using fewer/more inner steps than trained.
- Integration with systems optimizations: The paper proposes combining TMD with feature caching and efficient attention but offers no empirical validation. Implement and benchmark integrated pipelines to quantify compounded speedups and memory savings.
- Applicability beyond T2V: Evaluate TMD on video editing, conditional generation (image/video conditioning), inpainting, camera/control trajectories, and multimodal inputs (audio), including changes needed in architecture and training losses.
- Distributional alignment beyond VSD+GAN: Explore alternative distillation objectives (e.g., Wasserstein distances, sliced score matching, Stein discrepancies) and their trade-offs in sample fidelity and stability for videos.
- Safety and content moderation: Distilling from a teacher risks inheriting undesirable behaviors. Audit safety, content policy adherence, and controllability, and develop mitigation strategies specific to distilled video generators.
- Data efficiency and scaling laws: Report how performance scales with the number/quality of distillation pairs, and identify minimal data requirements for acceptable results. Compare synthetic vs. real supervision efficiency.
- Theoretical guarantees: Provide analysis of TMD’s approximation error (outer transition plus inner flow rollout), conditions for distributional convergence, and how discretization choices affect bias/variance.
- Reproducibility and openness: Important training details (e.g., weighting functions w(t), precise schedules, hyperparameters) are not fully specified. Release code, configs, and trained models, and include ablation tables sufficient for exact replication.
- Evaluation fairness: Baseline teachers differ across methods (e.g., VideoCrafter2, Seaweed-7B variants). Ensure fair, apples-to-apples comparisons by distilling the same teacher across all baselines and reporting standardized compute budgets.
Practical Applications
Overview
The paper introduces Transition Matching Distillation (TMD), a framework that distills large text-to-video (T2V) diffusion models into efficient few-step generators by decoupling the backbone into a semantic feature extractor and a lightweight, recurrent flow head. A two-stage training strategy (Transition Matching MeanFlow pretraining + Distribution Matching Distillation with flow-head rollout) delivers near-one-step video generation with strong visual fidelity and prompt adherence. Below are practical applications derived from these findings, organized by immediacy and connected to relevant sectors, workflows, and dependencies.
Immediate Applications
These applications can be deployed now, assuming access to a suitable teacher model (e.g., Wan2.1), GPU resources, and standard engineering integration.
- Creative tools: real-time text-to-video inside professional editors
- Sector: media/entertainment, software
- Use case: “Prompt-to-preview” in Adobe Premiere/After Effects or DaVinci Resolve to instantly generate B‑roll, animatics, and quick storyboards using TMD-N4H5 one-step (Effective NFE≈1.3–1.5).
- Tools/workflows: timeline-integrated TMD API, live prompt editing with fractional NFE scheduling (e.g., preview at NFE≈1.2, finalize at NFE≈2.7).
- Assumptions/dependencies: licensing for teacher weights, 480p/5s output constraints as per paper, guardrails for brand and copyright.
- Rapid previsualization and virtual production previews
- Sector: media/entertainment
- Use case: directors and VFX teams iterate on set design and camera moves with near-real-time video drafts, reducing storyboard cycles.
- Tools/workflows: “ViewPort Gen” plugin that ties shot metadata and text cues to a TMD backend; batch prompts for scene variants.
- Assumptions/dependencies: acceptance of 480p previews; pipeline decoding latency; integration with production asset management.
- Creative ad variant generation at scale
- Sector: advertising/marketing, finance
- Use case: generate dozens of targeted variants per prompt (different locales, slogans, styles) for A/B tests in minutes, not hours.
- Tools/workflows: campaign orchestration that auto-adjusts NFE by tier (preview vs. publish), DMD2-v discriminator tuning for fidelity.
- Assumptions/dependencies: brand-safety review, content moderation, prompt adherence validated by VBench or equivalent.
- Social media “instant reels” apps
- Sector: consumer software
- Use case: mobile apps offering prompt-to-clip generation; server-side TMD-distilled 1.3B model for low latency.
- Tools/workflows: REST API for video.generate(prompt, speed_tier), CDN-backed decoding.
- Assumptions/dependencies: throughput constraints, content filters, rate limiting.
- Synthetic data for perception pretraining and domain randomization
- Sector: robotics/autonomous systems
- Use case: large-scale generation of varied scenes (e.g., weather, traffic layouts) to augment training datasets quickly.
- Tools/workflows: data pipeline that programmatically seeds TMD with scenario templates; domain randomization using prompt libraries.
- Assumptions/dependencies: visual realism suffices for perception tasks; physics correctness may be limited (non-physically grounded).
- Interactive agent environments for prototyping “world modeling”
- Sector: AI/agent research, academia
- Use case: agents receive synthetic video stimuli while learning perception/action policies; fast regeneration allows frequent resets.
- Tools/workflows: LLM agent orchestration calling TMD for scenario generation; quality tiers per episode stage.
- Assumptions/dependencies: alignment with task semantics; consistent temporal coherence under few steps.
- Cost and energy reduction in T2V pipelines
- Sector: cloud/infrastructure, energy/sustainability
- Use case: replace multi-step teacher sampling with TMD few-step generation to reduce GPU-hours, queue times, and carbon footprint.
- Tools/workflows: rollout-aware inference engine; NFE telemetry; autoscaling based on requested quality tier.
- Assumptions/dependencies: acceptable drop in quality for certain tiers; carbon accounting methodology for reporting.
- Classroom and e-learning video generation
- Sector: education
- Use case: instructors create short explanatory clips on-demand (e.g., physics demonstrations, historical moments) within seconds.
- Tools/workflows: LMS plugins with curated prompt templates; moderation of sensitive topics; fractional NFE for quick previews.
- Assumptions/dependencies: educational accuracy verification; licensing for wide deployment.
- Fast text-guided video editing/refinement
- Sector: software, media/entertainment
- Use case: apply style or minor content edits with the flow head’s inner steps, treating the input video as a noisy target to refine.
- Tools/workflows: text-instructed inpainting and style transfer using the conditional flow map; two-step refinement for subtle edits.
- Assumptions/dependencies: adaptation of conditioning to accept frames/video; alignment between teacher features and edited content.
- Research acceleration
- Sector: academia
- Use case: reproduce and extend TMD with ablations (e.g., Conv3D discriminator vs. alternatives, timestep shifting), generate benchmarks.
- Tools/workflows: open-source training scripts using finite-difference JVP approximation; VBench evaluation at fractional NFEs.
- Assumptions/dependencies: access to GPUs; reproducible seeds; datasets (VidProM or equivalents).
Long-Term Applications
These applications require further research, scaling to higher resolutions/durations, improved controllability/physics, on-device optimization, or policy infrastructure.
- Real-time co-creative conversational video agents
- Sector: software, media/entertainment
- Use case: assistants that iteratively generate and revise video during a dialogue, incorporating user feedback mid-generation.
- Tools/workflows: LLM+TMD orchestration with multi-turn editing, low-latency decoding, session state management.
- Assumptions/dependencies: robust editability and temporal coherence; scalable to HD/4K and longer clips.
- AR/VR generative worlds and digital twins
- Sector: XR/VR, robotics
- Use case: stream generative scenes to headsets for training, simulation, or entertainment; rapid scene changes based on user intent.
- Tools/workflows: foveated rendering combined with TMD; scene graph integration; physics plug-ins.
- Assumptions/dependencies: high-res generation, frame pacing, physics grounding and controllability beyond current TMD scope.
- On-device mobile/edge video generation
- Sector: mobile/edge computing
- Use case: phones or embedded devices generating short videos locally for privacy or low-latency needs.
- Tools/workflows: quantized TMD backbones; hardware-aware flow heads; memory-frugal decoders.
- Assumptions/dependencies: aggressive model compression; dedicated accelerators; battery/thermal constraints.
- Closed-loop world models for agent training
- Sector: AI/agent research, robotics
- Use case: agents act in a generative environment that updates based on agent actions; faster cycles enable richer training curricula.
- Tools/workflows: control-conditioned TMD with structured prompts; reward shaping; simulators fused with generative video.
- Assumptions/dependencies: controllable dynamics, causal consistency, physics; safety evaluation.
- Production-grade virtual production and post
- Sector: media/entertainment
- Use case: TMD as a core generator for final shots, with color pipelines, camera-matching, and asset continuity.
- Tools/workflows: color-managed rendering, asset linkage, provenance and watermarking.
- Assumptions/dependencies: 4K fidelity; legal clearance; strong prompt adherence across long durations.
- Policy and governance for synthetic video at scale
- Sector: policy/regulation
- Use case: standards for provenance (watermarks, metadata), labeling, rate-limiting, and audit trails as generation throughput rises.
- Tools/workflows: “VBench for governance” framework; industry consortium to set thresholds; detector models tuned to few-step outputs.
- Assumptions/dependencies: cross-industry adoption; legal mandates; privacy/compliance integration.
- Healthcare education and therapy content
- Sector: healthcare
- Use case: personalized explainer videos (procedures, rehab routines) and therapeutic content tailored to patients.
- Tools/workflows: clinical review pipeline; content validation; accessibility adaptations.
- Assumptions/dependencies: medical accuracy and approvals; risk management; cultural sensitivity.
- Real-time ad marketplaces and dynamic pricing
- Sector: advertising/marketing, finance
- Use case: auctions where creatives are generated on-the-fly to match inventory and audience; performance-linked pricing.
- Tools/workflows: bid managers driving TMD; brand safety scoring; attribution analytics.
- Assumptions/dependencies: reliable prompt alignment; content compliance; integration with demand-side platforms.
- Sustainability metrics and procurement standards
- Sector: energy/sustainability, enterprise IT
- Use case: quantify CO2 savings by reducing NFE and GPU-hours; inform “Green Gen Video” procurement decisions.
- Tools/workflows: standardized measurement for per-video energy; dashboards and SLAs for quality vs. energy.
- Assumptions/dependencies: accepted measurement methodology; verifiable reporting.
- Security and deepfake mitigation
- Sector: security, policy
- Use case: detection tools adapted to few-step generative signatures; watermarking schemes integrated into the flow head/backbone.
- Tools/workflows: forensic signals derived from fake score/discriminator features; provenance infrastructure.
- Assumptions/dependencies: robust watermarks under editing; attack-resilient detection; legal frameworks for enforcement.
Cross-cutting assumptions and dependencies
- Model access and licensing: Applications depend on access to the teacher model (e.g., Wan2.1) and permissions to distill/deploy.
- Compute and latency: While TMD reduces NFEs, decoding and system-level overheads still matter (e.g., 480p→832×480 decode, 81 frames).
- Quality-resolution-duration tradeoffs: Current results are at 480p and ~5s; scaling to HD/4K and longer durations requires further optimization.
- Safety and compliance: High-throughput generation magnifies content risks; watermarking, moderation, and provenance must be embedded.
- Dataset and domain alignment: Strong prompt adherence depends on prompt/data distributions; domain-specific fine-tuning may be needed.
- Physics and controllability: For robotics/simulation, TMD’s visual realism may not imply physical correctness; hybrid pipelines are required.
Glossary
- Autoregressive–diffusion hybrids: Models that combine causal autoregressive generation with diffusion to reduce temporal attention costs by generating frames sequentially. "Autoregressiveâdiffusion hybrids achieve this by training causal models that generate frames sequentially instead of predicting the entire sequence at once"
- Backward simulation: A training view in DMD2 where generation is interpreted as simulating the reverse-time process, used here without gradient detachment. "In the terminology of DMD2, this can be viewed as \enquote{backward simulation}~\citep{yin2024improved} of the inner flow, but without detaching the gradient computation."
- Classifier-free guidance (CFG): A technique that improves conditional generation by interpolating between conditioned and unconditioned model outputs. "use classifier-free guidance (CFG) (adapting the conditional velocity ), drop the text condition with a certain probability, and (3) use adaptive loss normalization."
- Conditional flow: A flow-based update that is conditioned on auxiliary features (e.g., semantic backbone outputs) to refine samples. "where each transition is modeled as a lightweight conditional flow."
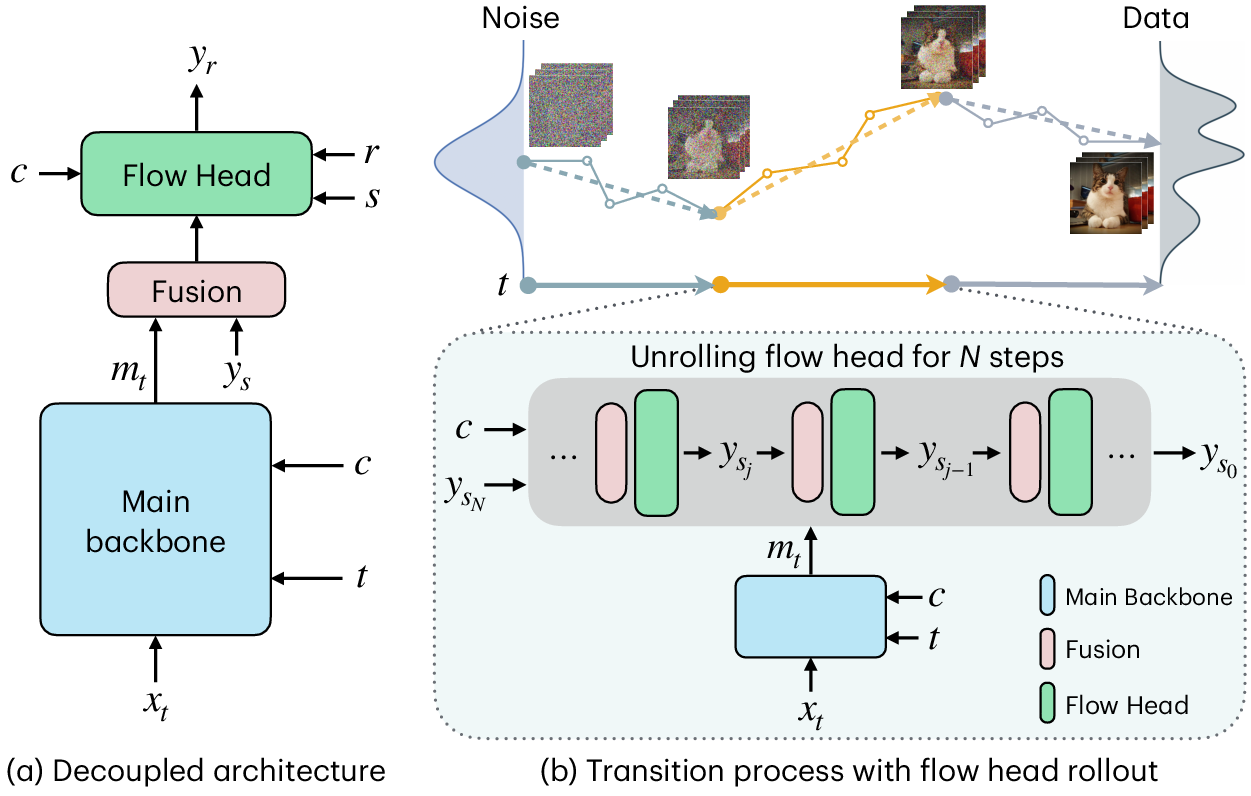
- Conditional flow map: A mapping that takes a point at one inner-flow time and produces its counterpart at an earlier time, conditioned on backbone features. "convert the flow head into a conditional flow map"
- Conditional velocity: The velocity field used for supervised training, computed as the difference between noise and a partially denoised sample under conditioning. "the instantaneous velocity is approximated by conditional velocity "
- Context parallelism: A distributed training strategy that parallelizes sequence context across devices to scale large transformers. "compatible with large-scale training for video generation (e.g., flash attention~\citep{dao2022flashattention}, Fully Sharded Data Parallel (FSDP)~\citep{zhao2023pytorch}, or context parallelism~\citep{jacobs2023deepspeed})"
- Decoupled architecture: A design that separates a main semantic feature extractor (backbone) from a lightweight head to enable efficient few-step refinement. "Decoupled architecture for TMD student, where the main backbone takes the noisy sample , timestep and text conditioning as inputs and outputs the main feature "
- Difference Transition Matching (DTM): A transition-matching variant that predicts the difference between noise and data to update states across discretized times. "For instance, Difference Transition Matching (DTM) considers"
- DiT blocks: Transformer blocks in Diffusion Transformers; here, a subset is reused as a lightweight head for inner refinement. "for instance, if we choose 5 final DiT blocks from a 30-block DiT and unroll 2 steps, it adds less than 17\% extra computation in updating the student network's parameters."
- Distribution Matching Distillation (DMD2): A distillation method that aligns student and teacher output distributions using VSD and GAN losses instead of regressing trajectories. "DMD2 was originally proposed for distilling image diffusion models."
- Distribution-based distillation: Techniques that train a student to match the teacher’s output distribution (via adversarial or VSD losses), rather than its full trajectory. "distribution-based distillation, encompassing adversarial~\citep{sauer2024adversarial,sauer2024fast} and variational score distillation~\citep{yin2024one,zhou2024score,yin2024improved} methods that align the student and teacher distributions."
- DMD2-v: An adapted version of DMD2 tailored for video, improving discriminator design, KD warm-up usage, and timestep sampling. "We identify three key factors that improve DMD2 for videos (termed DMD2-v)"
- Fake score: A model initialized from teacher parameters to estimate the student’s score function during distillation, trained on student samples. "Since we do not have access to the score of the student distribution, a so-called fake score is initialized with the teacher parameters and trained on data from the student using flow matching."
- Flash attention: An efficient attention implementation that reduces memory and increases speed in large transformer training. "compatible with large-scale training for video generation (e.g., flash attention~\citep{dao2022flashattention}, Fully Sharded Data Parallel (FSDP)~\citep{zhao2023pytorch}, or context parallelism~\citep{jacobs2023deepspeed})"
- Flow head: The lightweight final layers of the model that perform multiple inner refinement steps conditioned on backbone features. "a flow head, consisting of the last few layers, that leverages these representations to perform multiple inner flow updates."
- Flow head rollout: Unrolling the inner flow loop during training and inference so gradients propagate through all inner steps. "flow head rollout is performed during both distillation and sampling."
- Flow map: A function that maps a point along the probability flow ODE trajectory from a later time to an earlier time. "MeanFlow~\citep{geng2025mean} proposes to learn a flow map "
- Flow matching: A training objective that learns the instantaneous velocity field of a rectified flow, typically requiring many small steps for generation. "Flow matching approximates the instantaneous velocity"
- Forward-mode automatic differentiation: An autodiff mode that computes directional derivatives efficiently, used to estimate total derivatives in MeanFlow training. "the total derivative $\frac{\mathrm{d}{\mathrm{d}s} (_{s}, s, r)$ can be computed using either forward-mode automatic differentiation or a finite-difference approximation"
- GAN discriminator: The adversarial component trained to distinguish real from generated samples, here designed with spatio-temporal Conv3D features for videos. "We find that using Conv3D layers in the GAN discriminator outperforms other architectures"
- JVP (Jacobian–vector product): A derivative operation used to compute total derivatives of the flow map objective efficiently. "Since JVP computation in Eq.~\eqref{eq:jvp} requires custom implementations to be compatible with large-scale training for video generation"
- Knowledge distillation (KD) warm-up: An initial training phase that regresses teacher outputs to stabilize one-step distillation before switching to distribution matching. "Knowledge distillation (KD) warm-up. We find that KD warm-up improves the performance in one-step distillation"
- MeanFlow: A method that learns average velocity along ODE segments to map between timesteps, enabling few-step generation. "MeanFlow~\citep{geng2025mean} proposes to learn a flow map "
- Mode collapse: A failure mode where the generator produces limited diversity; mitigated by timestep shifting in this work. "improves the performance and prevents mode collapse."
- Number of function evaluations (NFE): A measure of inference cost defined as effective forward passes through the network, accounting for inner head steps. "see the definition of effective NFE in Eq.~\eqref{eq:nfe}"
- Patch embedding: The initial linear projection from image/video patches to tokens; reused here to minimize disruption when adding the inner flow. "Additionally, we reuse the patch embedding of the main input for the inner flow input ."
- PF-ODE trajectory: The probability flow ordinary differential equation path followed by samples under rectified flow. "maps the point at arbitrary time on the PF-ODE trajectory"
- Rectified flow schedule: A linear interpolation between data and standard normal defining the forward diffusion path used in flow matching. "It uses the rectified flow schedule"
- Reverse KL divergence: A divergence used in VSD to match student to teacher distributions by penalizing mismatches in score functions. "variational score distillation (VSD)~\citep{yin2024one} loss, i.e., reverse KL divergence"
- Transition Matching (TM): A discrete-time generalization of flow matching that learns probabilistic transitions between widely separated noise levels. "Transition matching (TM)~\citep{shaul2025transition} is a continuous-state generative model"
- Transition Matching Distillation (TMD): The paper’s method that distills multi-step diffusion into a few-step transition process with a decoupled backbone and inner flow head. "we propose Transition Matching Distillation (TMD) to distill large video diffusion models into few-step generators"
- Transition Matching MeanFlow (TM-MF): A pretraining algorithm that conditions MeanFlow on backbone features to initialize the flow head for iterative refinement. "our pretraining algorithm, termed Transition Matching MeanFlow (TM-MF), uses a MeanFlow objective as in Eq.~\eqref{eq:mf_objective}, conditioned on the main feature"
- Timestep shifting: A reparameterization of sampled timesteps to stabilize training and avoid collapse by skewing the distribution toward certain ranges. "Timestep shifting. When we sample a timestep for the outer transition step or for adding noise to generated samples in the VSD loss, we find that applying a shifting function with to a uniformly sampled improves the performance and prevents mode collapse."
- Two-alternative forced choice (2AFC): A user study design where raters choose between two options under controlled criteria (quality and alignment). "We perform a blinded two-alternative forced choice (2AFC) user preference study"
- Variational score distillation (VSD): A distillation objective that matches the score function (gradient of log-density) between student and teacher distributions. "variational score distillation (VSD)~\citep{yin2024one} loss, i.e., reverse KL divergence"
- VBench: A benchmark for evaluating video generation on overall, quality, and semantic scores. "To evaluate our method and baselines, we use VBench~\cite{huang2023vbench} (where we report total score, quality score and semantic score)"
Collections
Sign up for free to add this paper to one or more collections.