FlowAct-R1: Towards Interactive Humanoid Video Generation
Abstract: Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces FlowAct-R1, a system that can generate lifelike videos of human-like characters (avatars) in real time. Think of a virtual person who can see, hear, and respond to you during a live conversation—moving their lips to match speech, using facial expressions, and making natural body gestures—without big delays or glitches.
What questions are the researchers trying to answer?
The authors focus on three simple but tough goals:
- Can we make an avatar that responds instantly (low delay) and keeps streaming video smoothly?
- Can the video stay sharp, stable, and consistent for a long time (not just a short clip)?
- Can the avatar control the whole body (not just the mouth or face) and switch naturally between behaviors like speaking, listening, and thinking?
How does it work?
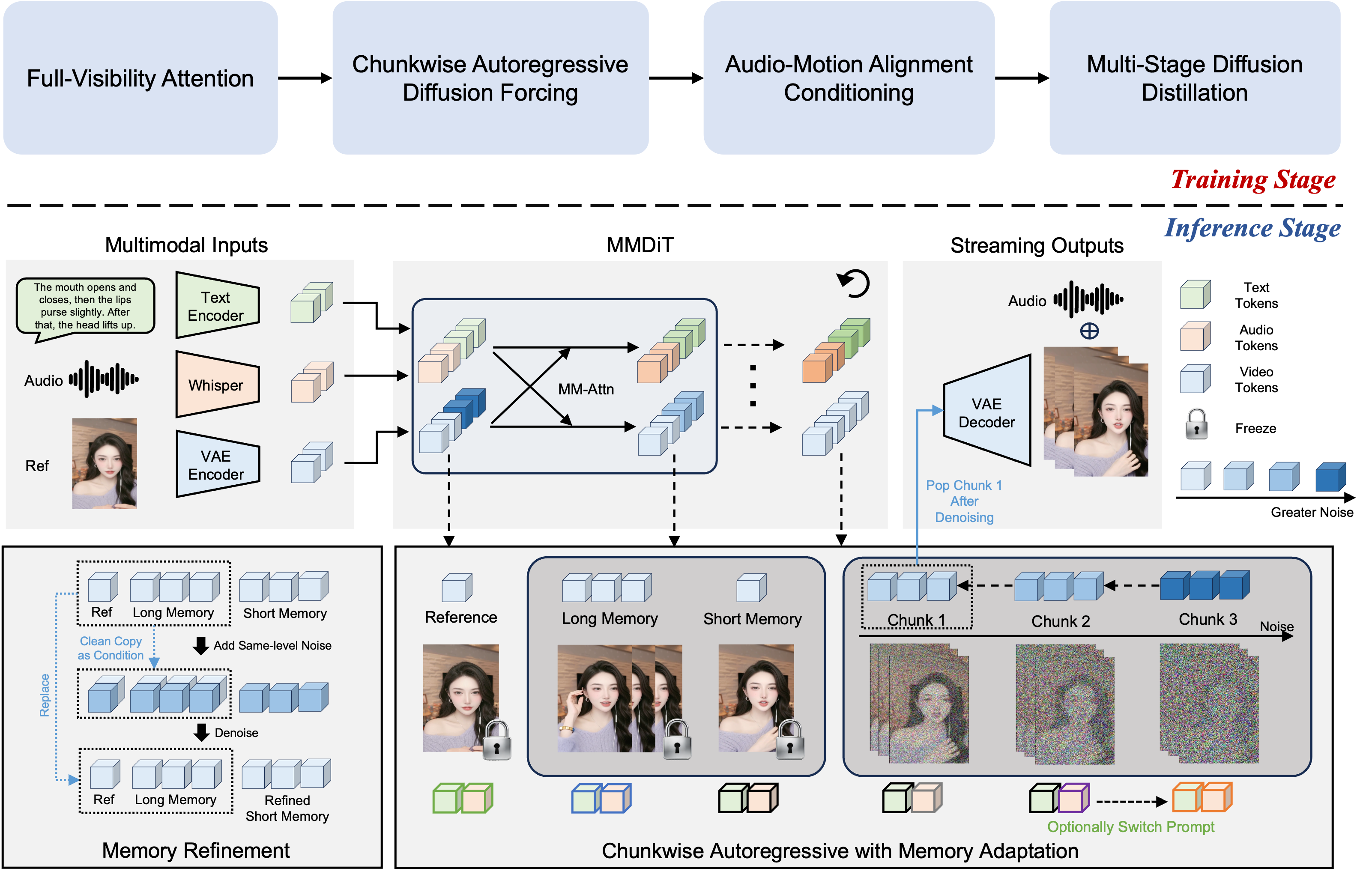
FlowAct-R1 builds on a type of AI model that understands multiple signals at once: text (what to say), audio (how it sounds), and visuals (what it looks like). Here’s the big picture, using everyday ideas:
The core idea: generate video like “cleaning up noise”
The system uses a “diffusion” model. Imagine starting with a snowy TV screen and gradually cleaning away the noise until you reveal a clear picture. The model repeats this process to create each frame of the video, guided by what the character should do and say.
Making long videos by stitching “chunks” together
Creating long videos at once is slow and unstable. Instead, FlowAct-R1 makes video in small pieces called chunks (like building a movie scene-by-scene). Each new chunk looks at:
- A reference image (to keep the avatar’s identity the same)
- Long-term memory (older finished parts)
- Short-term memory (the most recent finished part)
- The current noisy frames it’s “cleaning up” right now
This “memory bank” works like your own memory: short-term memory helps keep movements smooth from second to second, and long-term memory keeps the bigger story consistent.
To reduce mistakes that build up over time, they use a strategy called “self-forcing.” It’s like practicing under real test conditions: during training, the model sometimes uses its own previous outputs (not perfect answers) so it learns to recover from small errors, just like it will need to do in real use.
Helping the model “listen and talk” across inputs
- Audio is turned into compact features using Whisper (an audio model), so the avatar can sync lips and express tone.
- Text describes short, action-packed behaviors (“nods,” “smiles,” “raises a hand”) to keep responses lively and timely.
- A Multimodal LLM (a smart planner) suggests the next plausible actions based on recent speech and visuals—like a coach whispering “now look thoughtful” or “gesture to the left” for natural transitions.
Keeping it fast: speed-ups under the hood
Real-time video needs to be fast. The team:
- “Distills” the model: a big “teacher” model trains a faster “student” model to get similar quality with far fewer steps (only 3 cleanup steps per chunk).
- Uses engineering tricks (like lighter math, fused operations, and running parts in parallel) to squeeze out more speed.
- Uses a special attention setup so stable parts (reference and memory) stay locked-in and don’t get disturbed by the newest frames.
Together, these let the system stream at 25 frames per second (smooth video) at 480p resolution, with the first frame appearing in about 1.5 seconds.
What did they find?
Here are the main results the authors report:
- Real-time performance: Stable 25 fps at 480p with time-to-first-frame around 1.5 seconds.
- Endless streaming: It can keep generating video continuously by chaining chunks without falling apart over time.
- Full-body control: It coordinates lip-sync, facial expressions, hands, body posture, and even interactions with objects.
- Natural behavior: The avatar smoothly switches between speaking, listening, reflecting, and idling, reducing awkward repetitions.
- Strong generalization: It can create high-quality avatars from just a single reference image, across many character styles.
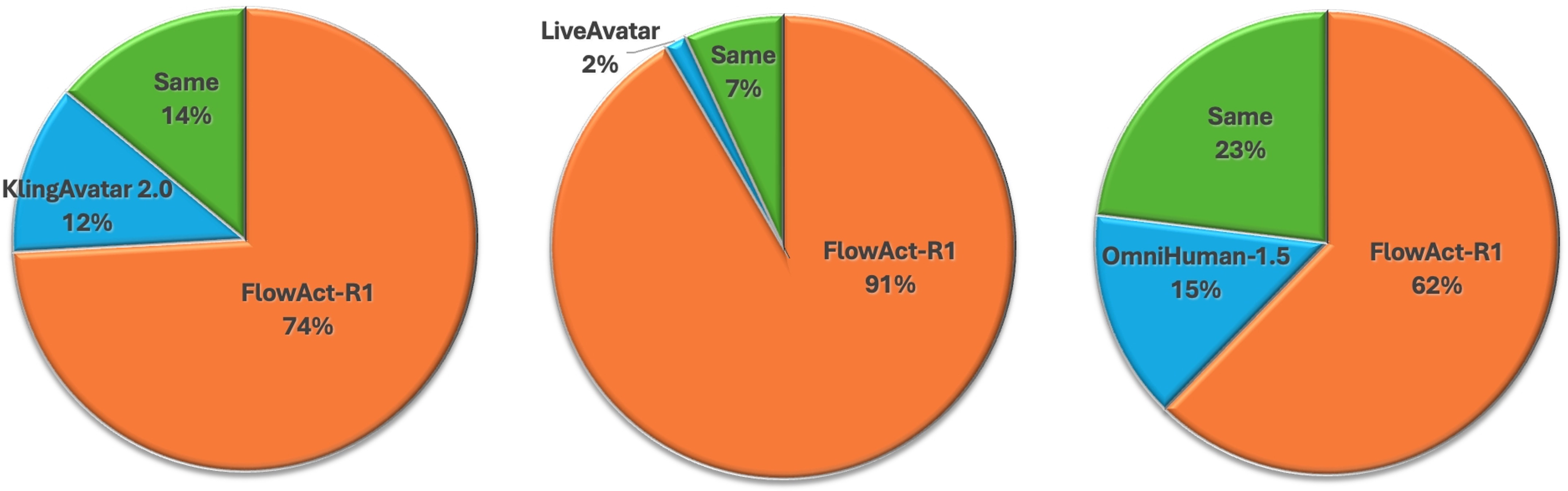
- Better user feedback: In a user study comparing with other top systems, people preferred FlowAct-R1 for motion naturalness, lip-sync accuracy, stability, and motion variety, especially for long, interactive sessions.
Why does this matter, and what could happen next?
FlowAct-R1 brings us closer to believable, responsive virtual people who can join live video calls, host streams, serve as companions or tutors, and interact in games or meetings. Because it’s fast, stable, and expressive, it could power:
- Live streaming hosts or assistants that react to chat and audio instantly
- Virtual teachers or coaches who gesture and respond naturally
- Video conferencing avatars that look and move like real humans
At the same time, there are risks—like using this tech to create fake or harmful content. The authors say they plan to restrict access and verify users, and they used AI-generated faces in demos to protect privacy. Responsible use, clear labeling, and safety checks will be crucial as this technology spreads.
Knowledge Gaps
Below is a single, focused list of knowledge gaps, limitations, and open questions left unresolved by the paper. Each item is concrete and intended to be actionable for future research.
- Objective evaluation is missing: provide standardized quantitative metrics (e.g., FVD/KVD for video quality, LPIPS/PSNR for reconstruction, ID similarity via ArcFace, LSE-C/LSE-D and audio–visual offset for lip-sync, motion diversity and repetition indices, temporal consistency drift metrics) alongside the user study.
- The GSB user study (n=20) is small and purely subjective; report statistical significance, inter-rater reliability, and balanced counterbalancing, and include task-specific ground truth benchmarks to validate claims on naturalness, lip-sync, and motion richness.
- Claims of “full-body control” and “object interactions” are not experimentally validated; design controlled tasks (e.g., hand–object contact success rate, trajectory adherence, semantic action execution accuracy) to quantify full-body and manipulation abilities.
- Generalization claims from a single reference image lack stress tests; evaluate identity retention and motion plausibility under large pose changes, occlusions, extreme expressions, clothing changes, lighting variations, and non-frontal viewpoints.
- Scalability to higher resolutions and frame rates is untested; characterize throughput–quality trade-offs at 720p/1080p and 30–60 fps, and report the impact on TTFF and stability when scaling spatiotemporal token counts.
- Maximum stable streaming duration and drift behavior are not quantified; measure identity drift, temporal jitter, and motion repetition over 10–60 minutes and beyond, and define failure rates and recovery mechanisms.
- Chunk definition is ambiguous: clarify the mapping between “chunk-size=3,” “3 latents per chunk,” VAE temporal stride, and frames-per-chunk at 25 fps; ablate chunk length and latent packing strategies on latency, quality, and drift.
- Memory bank design is heuristic (long-term size=3, short-term=1) without ablation; systematically vary memory sizes, replacement policies, and prioritization to optimize long-range consistency vs. latency.
- Memory Refinement strategy lacks schedule details and cost analysis; ablate refinement frequency, noise levels, guidance sources, and measure its effect on latency, TTFF, and long-term artifact suppression.
- The fake-causal attention mask is proposed without comparative evidence; evaluate quality/speed impacts vs. alternative masks (causal, bidirectional, block-local) and quantify attention leakage/stability effects across DiT layers.
- Self-Forcing variant details (noise schedule, selection probability of generated-GT-latents, alignment with inference errors) are unspecified; provide ablations and theory/diagnostics on error accumulation mitigation and train–test gap closure.
- Distillation pipeline (CFG removal + progressive step distillation + DMD) lacks per-stage ablations; quantify quality loss and speed gains at each step, robustness across content types, and sensitivity to student/fake initialization.
- The “CFG embedding layer” approach for guidance removal needs validation; measure whether distribution shifts occur (e.g., loss of conditional sharpness) across guidance scales and content domains.
- MLLM-driven action planning is underspecified (model choice, input formatting, inference latency, failure modes); ablate its contribution to naturalness, measure latency budget, and test robustness under ASR errors or ambiguous contexts.
- Audio conditioning relies on Whisper features but cross-lingual robustness, noisy environments, overlapped speech, and diarization are not evaluated; benchmark lip-sync and motion alignment across languages, noise SNRs, and multi-speaker scenarios.
- Multi-person interaction, turn-taking, and dyadic coordination are not supported or tested; extend to multi-agent scenes with role-conditioned control and quantify conversational synchrony and gaze/gesture alignment.
- Camera motion and scene dynamics are unaddressed; test with moving cameras, zooms, and background changes, and include mechanisms for viewpoint stabilization and scene-aware action planning.
- Environmental and physics plausibility are not considered; explore contact constraints, collision avoidance, and physically plausible motion priors for object manipulation and locomotion within scenes.
- Dataset composition, scale, annotation schema, and licenses are not disclosed; release details (or a proxy dataset) enabling reproducibility, including behavioral labels, prompt segmentation rules, and temporal alignment strategy.
- Hardware dependence is strong (A100); measure performance on consumer GPUs (e.g., RTX 3060/4060/4090), mobile NPUs, and edge devices, and characterize degradation, energy cost, and achievable TTFF/fps.
- Distributed inference strategy and bandwidth constraints are not analyzed; quantify end-to-end latency breakdown (DiT denoising, VAE decode, MLLM planning, inter-GPU communication), and test stability under network jitter/packet loss.
- FP8 quantization is applied without quality-impact audit; report failure cases (banding, flicker, identity artifacts), per-layer sensitivity, and dynamic quantization schemes to safeguard quality.
- Streaming robustness under variable input rates and prompt updates is untested; evaluate frequent text prompt changes, asynchronous audio arrivals, and partial/missing modality inputs, including recovery behaviors.
- Safety and provenance are not operationalized beyond access control; implement and evaluate watermarking/provenance markers, deepfake detection compatibility, consent management, and identity spoofing safeguards in streaming settings.
- Release status of code/models is unclear; provide reproducible pipelines, inference scripts, and evaluation tooling to validate streaming real-time claims and facilitate adoption.
Practical Applications
Immediate Applications
These applications can be deployed with today’s infrastructure, leveraging FlowAct-R1’s real-time 25fps (480p), ~1.5s TTFF streaming, full-body control, chunkwise diffusion forcing with self-forcing, structured memory bank, Whisper-based audio tokens, MLLM-guided action planning, 3-NFE distillation, FP8 quantization, and system-level optimizations.
- Bolded digital agent for customer support (video contact centers)
- Sectors: customer service, telecom, finance, insurance
- Tools/products/workflows: WebRTC/gRPC streaming microservice; CRM/CCaaS plugin (e.g., Genesys/NICE/Twilio); MLLM for intent+action planning; scripted text prompts for persona; Whisper audio tokens for lip-sync; chunked streaming for long calls
- Assumptions/dependencies: A100-class GPU per concurrent stream or GPU pooling; content moderation and safety guardrails; consent and disclosure for synthetic media; data encryption in transit
- Live-commerce co-host and stream moderator
- Sectors: retail/e-commerce, media and entertainment
- Tools/products/workflows: OBS/Streamlabs plugin; chat-to-action planning via MLLM; product catalog APIs; gesture presets (pointing, showcasing) via text control; memory refinement to reduce drift in long streams
- Assumptions/dependencies: Chat moderation; latency budget (<1–2s end-to-end); scalability for concurrent sessions; brand voice/likeness licensing
- Video meeting copilot and presenter
- Sectors: enterprise software, productivity
- Tools/products/workflows: Zoom/Teams add-in; script-to-gesture mapping; slide control triggers; diarization to manage turn-taking; “privacy avatar” mode that uses audio-only input and a single reference image
- Assumptions/dependencies: Corporate compliance policies for synthetic video; low-jitter audio capture; on-prem or VPC deployment for sensitive orgs
- Virtual receptionist/concierge kiosk
- Sectors: hospitality, travel, retail, smart buildings
- Tools/products/workflows: Touchscreen kiosk frontend; booking/CRM lookup; multilingual TTS+ASR pipeline; gesture libraries for directing people to locations
- Assumptions/dependencies: Robust far-field audio capture; consent signage; uptime SLAs; physical security of kiosks
- Telemedicine front desk and intake assistant (non-diagnostic)
- Sectors: healthcare
- Tools/products/workflows: HIPAA-compliant deployment; scripted triage Q&A; EHR appointment integration; escalation workflows to clinicians
- Assumptions/dependencies: Regulatory compliance (HIPAA/GDPR); explicit non-clinical disclaimers; real-time content filtering for sensitive scenarios
- Corporate training and LMS presenter
- Sectors: education (K–12, higher ed), enterprise L&D
- Tools/products/workflows: LMS plugin to generate instructor videos from scripts; text prompts for gesture and persona; batch render service with chunkwise streaming for long courses
- Assumptions/dependencies: Voice-rights and likeness licensing; style guides; QA for gesture appropriateness by culture/region
- Media localization: real-time dubbing avatar for live or recorded content
- Sectors: media and entertainment, education
- Tools/products/workflows: Translator+TTS → FlowAct-R1 lip/body sync; phoneme-aligned TTS improves mouth motion; production pipeline export to broadcast formats
- Assumptions/dependencies: High-quality TTS alignment; cultural adaptation; IP rights for performers/characters
- In-game cloud NPCs with live dialog and gestures (overlay streaming)
- Sectors: gaming
- Tools/products/workflows: Cloud-rendered agent video composited in-engine; action planning tied to quest/dialog systems; memory bank stabilizes long sessions
- Assumptions/dependencies: Bandwidth and latency constraints; cost per MAU; art-direction controls for consistent style
- HR recruiting assistant for career sites and job fairs
- Sectors: HR tech
- Tools/products/workflows: ATS integration; pre-screen Q&A; persona and tone control via text prompts; interview scheduling actions
- Assumptions/dependencies: Fairness and bias evaluation; candidate consent; audit logs and transcripts
- Synthetic data generation for research and model training
- Sectors: academia, computer vision/ML, HCI
- Tools/products/workflows: Scripted behavior catalogs; batch generation with diverse identities and contexts; labels for gesture-speech alignment
- Assumptions/dependencies: Domain gap vs. real footage; dataset documentation; reproducible seeds; compute quotas
- Creative previz and storyboard blocking
- Sectors: film/TV, advertising, game cinematics
- Tools/products/workflows: Shot scripts to video with gesture/emotion directives; quick iteration loops; export to image sequences or EDLs
- Assumptions/dependencies: 480p proxies acceptable for early-stage work; style consistency controls; asset/likeness licenses
- Accessibility and bandwidth optimization for calls
- Sectors: communications, accessibility
- Tools/products/workflows: Audio-only uplink from user; server-side avatar generation at 25fps; privacy mode that masks real faces; automatic caption overlays
- Assumptions/dependencies: Explicit user opt-in; detection/watermarking; does not substitute for sign language (see long-term)
- Personalized marketing spokesperson at scale
- Sectors: advertising/marketing
- Tools/products/workflows: CRM token insertion into text prompts; automated batch renders; A/B testing of gestures/emotions for conversion uplift
- Assumptions/dependencies: Consent for personalization; output provenance (C2PA); platform policies on synthetic endorsements
- Telepresence avatar on displays/robots (screen-based)
- Sectors: enterprise, events, robotics (display-only)
- Tools/products/workflows: Replace live video feed with FlowAct-R1 avatar driven by speech+text; “on-hold” idling states between turns
- Assumptions/dependencies: Stable network; disclosure of synthetic presence; safety for public deployments
Long-Term Applications
These require further research, scaling, domain adaptation, or regulatory progress (e.g., higher resolution, on-device inference, multi-agent scenes, specialized datasets, or formal validation).
- On-device or edge deployment (laptops, mobiles, kiosks without datacenter GPUs)
- Sectors: device OEMs, telecom, SaaS
- Tools/products/workflows: Additional distillation/pruning, INT4/FP4 quantization, operator fusion; adaptive chunk sizing
- Assumptions/dependencies: Significant model compression; hardware acceleration (NPU/NPUs on smartphones); quality retention
- High-resolution real-time (1080p–4K) streaming avatars
- Sectors: broadcast, film/TV, premium conferencing
- Tools/products/workflows: Multi-scale VAEs; tiled decoding; memory bank scaling; improved diffusion forcing for stability
- Assumptions/dependencies: More powerful GPUs or multi-GPU pipelines; bandwidth expansion; artifact-free upscaling
- Volumetric 3D/VR avatars with view-dependent rendering
- Sectors: XR, metaverse, gaming
- Tools/products/workflows: Integration with neural rendering (NeRF/GS) or 3D Gaussians; stereo/6DoF outputs; head-tracked view synthesis
- Assumptions/dependencies: 3D-consistent training data; real-time 3D rendering budgets; human factors testing for comfort
- Multi-agent interactive scenes (turn-taking, spatial grounding)
- Sectors: social platforms, virtual events, education
- Tools/products/workflows: Multi-speaker diarization; group action planning; memory retrieval across agents; collision/occlusion handling
- Assumptions/dependencies: Training on multi-person interaction datasets; scene graph integration; latency-aware coordination
- Real-time sign language interpreting avatars with linguistic fidelity
- Sectors: accessibility, public services, education
- Tools/products/workflows: Specialized corpora (phonology, grammar, non-manual signals); evaluation with Deaf communities; domain-specific gesture controls
- Assumptions/dependencies: High-quality datasets and benchmarks; community co-design; regulatory and accessibility standards compliance
- Clinically validated therapeutic companions and patient education
- Sectors: healthcare
- Tools/products/workflows: Empathy modeling; safety layers; scripted care pathways; RCTs for efficacy; EHR integration for personalization
- Assumptions/dependencies: Regulatory approvals; clinical oversight; data governance; strict disclaimers and escalation to clinicians
- Financial services virtual teller with KYC and transaction flows
- Sectors: finance/banking
- Tools/products/workflows: ID verification; fraud detection; secure function-calling to core banking; audit trails
- Assumptions/dependencies: KYC/AML compliance; deepfake-resistant liveness detection; robust provenance/watermarking
- Government service kiosks (multilingual, 24/7)
- Sectors: public sector, transportation
- Tools/products/workflows: Localization; policy-scripted responses; accessibility features; secure data handling
- Assumptions/dependencies: Procurement and standards; bias/fairness audits; citizen consent mechanisms
- Embodied robotics telepresence and assistance
- Sectors: robotics, manufacturing, eldercare
- Tools/products/workflows: Map FlowAct-R1’s action plans to robot controllers; sensor fusion for world awareness; safety envelopes
- Assumptions/dependencies: Reliable perception-control stack; alignment between generated motions and physical feasibility; certification
- Classroom-scale orchestration (Socratic, multi-student engagement)
- Sectors: education
- Tools/products/workflows: Attention and engagement modeling; whiteboard/screen pointing; per-student adaptations
- Assumptions/dependencies: Datasets for classroom interactions; privacy in minors’ data; pedagogical validation
- Real-time digital doubles on-set (actor replacements/stand-ins)
- Sectors: film/TV
- Tools/products/workflows: High-res, latency-bounded pipelines; union-compliant consent/tracking; rights management/residuals reporting
- Assumptions/dependencies: Legal frameworks and contracts; artistic direction tooling; robust facial/body identity preservation
- E-commerce try-on assistant with physically plausible garment motion
- Sectors: retail/fashion
- Tools/products/workflows: Cloth simulation or learned physics; body measurement estimation; product catalog linking
- Assumptions/dependencies: Physics-grounded datasets; size/fit accuracy; returns/liability considerations
- Behavioral science at scale (A/B testing of gesture and affect)
- Sectors: academia, marketing science, HCI
- Tools/products/workflows: Experimental pipelines to vary nonverbal cues; automatic outcome measurement (conversion, trust scores)
- Assumptions/dependencies: IRB/ethics approvals; avoidance of manipulative practices; pre-registration and transparency
- Emergency response training with high-stress role players
- Sectors: public safety, defense, healthcare
- Tools/products/workflows: Scenario scripting; multi-agent coordination; after-action review tooling
- Assumptions/dependencies: Psychological safety protocols; specialized content filters; domain SME oversight
- Knowledge-grounded enterprise avatars (API/action execution)
- Sectors: enterprise software, ITSM
- Tools/products/workflows: Function calling; knowledge graph grounding; retrieval-augmented action planning
- Assumptions/dependencies: Strict permissioning; hallucination mitigation; observability and rollback
- Standardized provenance and safety frameworks for synthetic video
- Sectors: policy, platforms, cybersecurity
- Tools/products/workflows: C2PA signing; robust watermarking; detector services; platform-wide disclosure labels
- Assumptions/dependencies: Cross-industry standards; low false positive/negative rates; regulatory adoption
Notes on Cross-Cutting Assumptions and Dependencies
- Compute and latency: Reported benchmarks rely on datacenter GPUs (e.g., NVIDIA A100). Edge/on-device use requires further distillation/quantization and may trade off quality or resolution.
- Audio pipeline: Whisper-derived tokens and stable ASR/TTS are assumed; phoneme alignment improves lip-sync quality.
- Safety and ethics: Clear disclosure that content is synthetic; consent and rights for likeness/voice; content moderation and misuse prevention are mandatory.
- Provenance and detection: Watermarking/signing and compatible platform policies are critical to mitigate impersonation and fraud.
- Data and domain adaptation: Specialized applications (e.g., sign language, clinical, finance) require dedicated datasets, domain evaluation, and often regulatory approvals.
- Integration: Real-world deployments need connectors to CRMs, EHRs, ATS, conferencing platforms, payment or identity systems, plus observability and incident response.
Glossary
- Acoustic tokens: Fixed-length audio representations aligned with video frames for conditioning generation. "we utilize Whisper to compress audio input into aligned acoustic tokens."
- All-to-all communication: A distributed computing pattern where extensive data exchange occurs among devices, often a bottleneck in parallel systems. "This reconfiguration significantly reduces the all-to-all communication overhead and mitigates network bottlenecks."
- Autoregressive Adaptation: Modifying a model to generate outputs sequentially conditioned on previous outputs to enable streaming. "Autoregressive Adaptation, transforming the general-purpose MMDiT into a streaming-compatible variant;"
- Classifier-Free Guidance (CFG): A diffusion sampling technique that balances unconditional and conditional predictions to steer outputs without a classifier. "Prior to step distillation, we first eliminate the overhead of classifier-free guidance (CFG)."
- Chunkwise diffusion forcing: A strategy that generates video in chunks while enforcing consistency with prior chunks to reduce error accumulation. "We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation"
- Cross-attention: An attention mechanism where one set of tokens attends to another modality’s tokens to fuse information. "where information extraction and exchange occur via cross-attention mechanisms."
- DiT (Diffusion Transformer): A transformer architecture tailored for diffusion-based generative modeling. "we decouple DiT denoising and VAE decoding into an asynchronous pipeline"
- Distribution Matching Distillation (DMD): A distillation objective that aligns the student’s score function with the teacher’s to enable fast, few-step sampling. "Following step distillation, we apply few-step score distillation - DMD."
- Fake-causal attention: An attention masking scheme that simulates causal constraints to stabilize streaming generation without full causal computation. "we implement a fake-causal attention mechanism during both training and inference."
- FP8 quantization: Using 8-bit floating-point precision for weights/activations to accelerate inference with minimal quality loss. "we strategically employ FP8 quantization across a selection of attention and linear layers"
- HBM and SRAM: High Bandwidth Memory and Static Random-Access Memory; distinct hardware memory types affecting throughput and latency. "To minimize the data movement overhead between HBM and SRAM \cite{dao2022flashattention}, frequent operators are fused into single kernels within each DiT block."
- Image-to-Video (I2V): Generating a video sequence starting from a single image. "native Image-to-Video (I2V) capabilities are retained via weighted loss during training"
- IP-Adapter: A conditioning adapter mechanism (originally for images) used here to correlate audio with fine-grained motion via attention. "we adopt an IP-Adapter-style approach to correlate audio signals with fine-grained motions"
- Latent tokens: Compact, encoded representations of video frames in latent space for efficient processing. "The input video stream is compressed temporally and spatially into latent tokens via a VAE"
- MMDiT (Multimodal Diffusion Transformer): A diffusion transformer that natively aligns and fuses multiple modalities (text, audio, video). "Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations"
- Multimodal LLM (MLLM): An LLM that processes and reasons over multiple modalities (e.g., text, audio, images) for action planning. "we integrate a Multimodal LLM (MLLM) into the action planning process."
- Number of Function Evaluations (NFEs): The count of denoising steps/evaluations in diffusion sampling affecting speed and quality. "reduce the denoising process to only 3 NFEs."
- Sequence parallelism: Parallelizing transformer computations by partitioning sequences across devices. "we transition from token-level sequence parallelism to a frame-level hybrid-parallel strategy."
- Shot-based temporal slicing: Splitting videos into short temporal segments (“shots”) to reduce compute and enable streaming. "characterized by reduced parameters, shot-based temporal slicing, and window-based spatial attention"
- Step distillation: Collapsing multiple diffusion micro-steps into fewer steps to accelerate sampling. "We then perform naive step distillation"
- Time-to-First-Frame (TTFF): The latency from inference start until the first frame is produced. "restricting the Time-to-First-Frame (TTFF) to approximately 1.5 seconds."
- Variational Autoencoder (VAE): A generative encoder–decoder model that maps inputs to a latent distribution and reconstructs from it. "The input video stream is compressed temporally and spatially into latent tokens via a VAE"
- Window-based spatial attention: Attention limited to local spatial windows to cut complexity and improve efficiency. "characterized by reduced parameters, shot-based temporal slicing, and window-based spatial attention"
Collections
Sign up for free to add this paper to one or more collections.