Fundamental Limitations of Favorable Privacy-Utility Guarantees for DP-SGD
Published 15 Jan 2026 in cs.LG and cs.CR | (2601.10237v1)
Abstract: Differentially Private Stochastic Gradient Descent (DP-SGD) is the dominant paradigm for private training, but its fundamental limitations under worst-case adversarial privacy definitions remain poorly understood. We analyze DP-SGD in the $f$-differential privacy framework, which characterizes privacy via hypothesis-testing trade-off curves, and study shuffled sampling over a single epoch with $M$ gradient updates. We derive an explicit suboptimal upper bound on the achievable trade-off curve. This result induces a geometric lower bound on the separation $κ$ which is the maximum distance between the mechanism's trade-off curve and the ideal random-guessing line. Because a large separation implies significant adversarial advantage, meaningful privacy requires small $κ$. However, we prove that enforcing a small separation imposes a strict lower bound on the Gaussian noise multiplier $σ$, which directly limits the achievable utility. In particular, under the standard worst-case adversarial model, shuffled DP-SGD must satisfy $σ\ge \frac{1}{\sqrt{2\ln M}}$ $\quad\text{or}\quad$ $κ\ge\ \frac{1}{\sqrt{8}}!\left(1-\frac{1}{\sqrt{4π\ln M}}\right)$, and thus cannot simultaneously achieve strong privacy and high utility. Although this bound vanishes asymptotically as $M \to \infty$, the convergence is extremely slow: even for practically relevant numbers of updates the required noise magnitude remains substantial. We further show that the same limitation extends to Poisson subsampling up to constant factors. Our experiments confirm that the noise levels implied by this bound leads to significant accuracy degradation at realistic training settings, thus showing a critical bottleneck in DP-SGD under standard worst-case adversarial assumptions.
The paper establishes explicit geometric lower bounds demonstrating that DP-SGD cannot simultaneously achieve low noise and minimal privacy leakage under worst-case adversarial models.
It uses f-DP hypothesis testing and suboptimal threshold methods to quantify the trade-off between Gaussian noise multipliers and separation metrics, revealing a slow noise decay with increased iterations.
Empirical results on standard datasets confirm significant utility loss (over 20 percentage points in accuracy), underscoring the practical impact of inherent privacy-utility limitations.
Fundamental Limits of Privacy-Utility Trade-offs in DP-SGD
Introduction and Context
Differentially Private Stochastic Gradient Descent (DP-SGD) is the principal method for training deep models under formal privacy guarantees. The literature has established both theoretical and practical consequences of invoking DP-SGD, particularly the degraded utility (e.g., accuracy) that results from the injection of calibrated noise. However, the question of whether there exist fundamental, inescapable limits on how close one can approach both strong privacy and high utility under rigorous adversarial privacy models remains unsettled. This paper, "Fundamental Limitations of Favorable Privacy-Utility Guarantees for DP-SGD" (2601.10237), resolves this by establishing explicit geometric lower bounds on the privacy-utility trade-off for standard DP-SGD (both shuffling- and Poisson-based), analyzed in the f-differential privacy (f-DP) hypothesis testing framework.
Problem Formulation and Theoretical Framework
The authors analyze DP-SGD under single-epoch training with M gradient updates, considering both Poisson subsampling and random shuffling batch formation. Explicit attention is given to the strongest (worst-case) adversarial privacy models. Privacy is evaluated using the f-DP formalism, which captures the optimal achievable type I/II error trade-off an adversary faces in distinguishing neighboring datasets.
A key geometric quantity is the separationκ—the L2-distance between the f-DP trade-off curve and the ideal random-guessing line (β=1−α). Small κ indicates strong privacy; large κ indicates substantial privacy leakage. The paper's principal result is that, under standard adversarial models, achieving small separation κ enforces a lower bound on the Gaussian noise multiplier σ, which governs the utility of learned models.
Main Technical Contributions
Explicit Geometric Lower Bound
The central technical result is that for shuffled DP-SGD in single-epoch training with M gradient updates, no mechanism can simultaneously achieve both small σ and small κ. Specifically,
σ≥2lnM1orκ≥8(1−4πlnM1)1
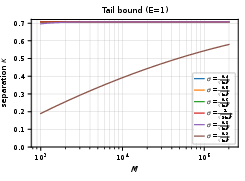
Thus, even as M→∞, the required noise decays only as 1/lnM, which is extremely slow. This lower bound holds for realistic values of M (e.g., ImageNet-scale datasets), enforcing nontrivial noise and hence utility degradation.
Figure 2: Explicit lower bound on the separation sep as a function of the number of rounds per epoch M under various noise schedules.
Suboptimal Test and Tradeoff Analysis
The proof proceeds via analysis of a suboptimal hypothesis test—thresholding the maximum coordinate of noise-injected gradients—and uses Neyman-Pearson lemma machinery to establish analytical expressions for the false-positive/negative tradeoff. The resulting explicit trade-off function (for shuffling) universally upper bounds the true f-DP curve, enabling geometric reasoning about separation.
Poisson Subsampling and Extension
The limitation is shown to extend, up to a multiplicative constant, to Poisson subsampling—thus covering both theoretical and practical DP-SGD sampling regimes. This is achieved by reducing Poisson analyses to mixture models, revealing that no fundamental escape from the lower bound is possible via sampling choice.
Asymptotic and Gaussian DP Analysis
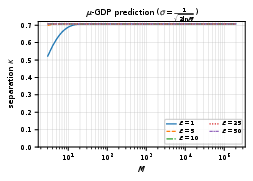
The work contrasts these explicit finite-sample bounds with asymptotic predictions derived from μ-GDP analyses, showing that the separation predicted by GDP aligns in trend but not in explicit finite-M quantification.
Figure 4: GDP-predicted separation κμ-GDP as a function of M under the noise schedule σ=1/2lnM, illustrating slow decay and nontrivial privacy leakage for practical M.
Empirical Validation and Practical Ramifications
The paper provides rigorous empirical experiments supporting the theoretical results. Models (ResNets, ViTs, Transformers) are trained on standard datasets (CIFAR-10/100, SVHN, AG News) using JAX Privacy with both shuffling and Poisson sampling. For noise multipliers at or near the theoretical lower bound, test accuracies exhibit persistent, significant degradation—often more than 20 points compared to non-private or clipping-only baselines. Empirical behavior is nearly identical between shuffling and Poisson, confirming that the bottleneck is intrinsic to the DP mechanism under worst-case adversarial models, not an artifact of sampling.
Implications and Future Directions
The results demonstrate that under the standard adversarial formalizations of privacy, DP-SGD cannot circumvent a strict trade-off: even infinitely large datasets do not eliminate the cost of noise—utility loss is inescapable if worst-case privacy is required. This raises foundational questions about the value and applicability of worst-case adversarial models for practical privacy. Concretely, the findings suggest:
Relaxed Adversarial Models: Future research may explore “average-case” or distributional privacy definitions (e.g., PAC-privacy), seeking improved utility without sacrificing meaningful privacy for most, but not all, records.
Algorithmic Innovations: Solely increasing σ is insufficient; instead new algorithmic techniques—structured clipping, privatization of lower-dimensional summary statistics, or alternative optimization dynamics—may yield distinct privacy-utility behaviors.
Beyond Worst-Case: There is a strong argument for re-examining the DP definitions themselves, or at least for augmenting them with models that better match practical adversary capabilities in deployed distributed or federated learning contexts.
Conclusion
This paper establishes a non-asymptotic, explicit geometric limitation on privacy-utility trade-offs for DP-SGD, showing that for both shuffling and Poisson batch formation, no standard DP-SGD implementation can achieve both strong privacy (κ→0) and high utility (small σ) within single-epoch training under the worst-case adversarial model. The theoretical separation lower bounds are validated empirically across models and datasets, suggesting that the tension is not merely theoretical but fully manifests in practice. Future work must either innovate on the modeling of privacy (relaxing adversarial assumptions), on algorithm design, or both, if improved trade-offs are to be achieved in practical systems.