- The paper introduces a paradigm that activates LLMs to perform chain-of-thought reasoning for enhanced prompt refinement.
- It employs supervised fine-tuning and Dual-GRPO co-optimization to achieve up to 30% improvement over conventional methods.
- Experiments demonstrate superior semantic alignment and robust performance in both text-to-image generation and conceptual image editing.
Reasoning-Aware Text-to-Image Diffusion with LLM Encoders: The Think-Then-Generate Paradigm
Introduction
Conventional text-to-image (T2I) diffusion models have achieved impressive visual synthesis quality and instruction following, especially with the integration of LLMs as text encoders. However, nearly all prior T2I diffusion pipelines restrict LLMs to purely encoding prompts, therefore treating them as passive text-to-latent mappers. This passive role suppresses LLMs' capacity for explicit reasoning, world knowledge, and chain-of-thought-based inference, which limits the ability of current DMs to interpret semantically nuanced or conceptually complex prompts.
This work introduces "Think-Then-Generate: Reasoning-Aware Text-to-Image Diffusion with LLM Encoders" (2601.10332), which establishes the new T2G paradigm. Unlike standard routines, T2G explicitly activates the reasoning ability of the LLM encoder, transitioning it into an active agent that rewrites and augments the user prompt via context-driven chain-of-thought (CoT) reasoning before diffusion-based generation.
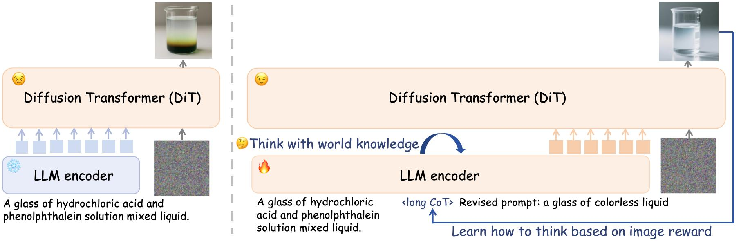
Figure 1: An overview of the think-then-generate pipeline, where LLMs are actively trained to refine and reason over raw prompts guided by the reward of output images.
Methodology
The architecture begins with a raw prompt, which is processed through an LLM encoder (initialized from Qwen2.5-VL). The LLM is post-trained via lightweight supervised fine-tuning (SFT) to simulate a "think-then-rewrite" protocol, i.e., decomposing a raw user instruction into an explicit reasoning trace (CoT) and a refined final prompt, leveraging Gemini-2.5 as a generator for high-quality CoT training targets.
The core pipeline proceeds as follows:
- Supervised Fine-Tuning for Reasoning Activation:
SFT is performed on curated data mapping raw prompts to ([long CoT], refined prompt) pairs, directly instilling explicit reasoning and prompt rewriting capacity into the LLM. t-SNE analysis demonstrates that this SFT step does not materially distort the structural properties of the LLM embedding space, thereby ensuring robust backward compatibility with the diffusion transformer backbone (DiT).
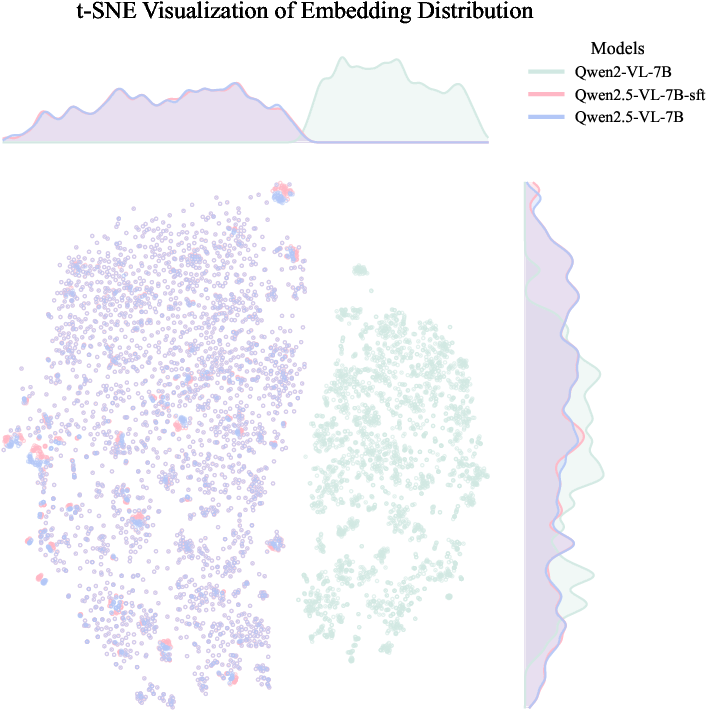
Figure 2: Embedding distributions before and after SFT are nearly identical, indicating SFT preserves structure and does not harm compatibility with DiT.
- Joint Reinforcement Optimization (Dual-GRPO):
The LLM encoder and DiT decoder are co-optimized via a tailored Dual-Group Relative Policy Optimization (Dual-GRPO) algorithm. Here, group-relative normalization enhances credit assignment by aggregating image-grounded rewards within hierarchical rollouts—sampling multiple reasoning traces per prompt and multiple images per trace.
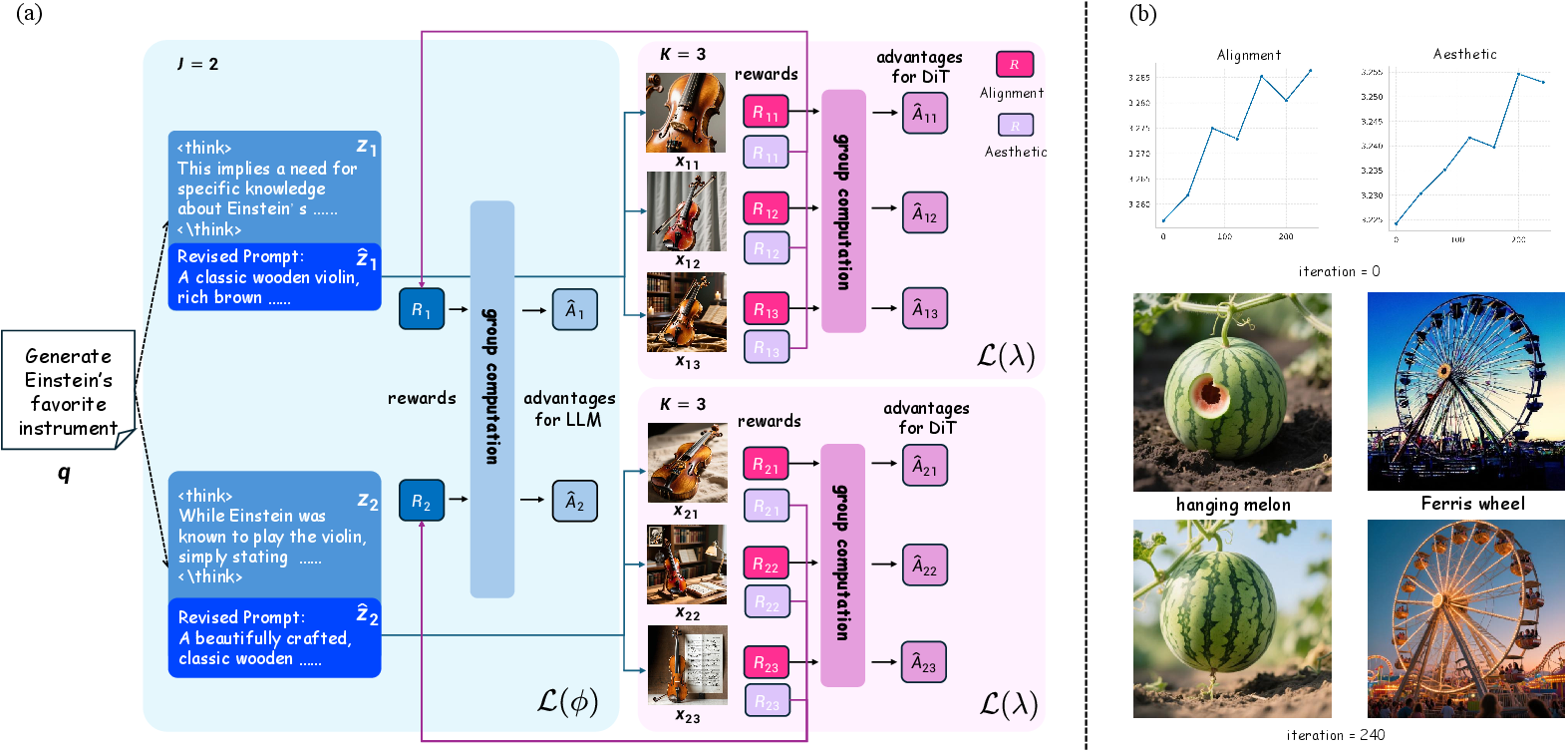
Figure 3: Dual-GRPO: (a) Tree-structured rollout enables diverse reasoning and visual hypotheses per prompt; (b) learning curves show concurrent improvement in semantic alignment and style scores over training.
- Stage-Specific Reward Scheduling:
Distinct reward functions guide each pipeline stage: during reasoning, reward is semantic consistency between diffusion outputs and prompt; during diffusion, reward combines image aesthetics, physical consistency, and semantic alignment. A balanced scheduler (β1(τ)=β2(τ)=0.5) achieves optimal performance compared to staged alternatives.
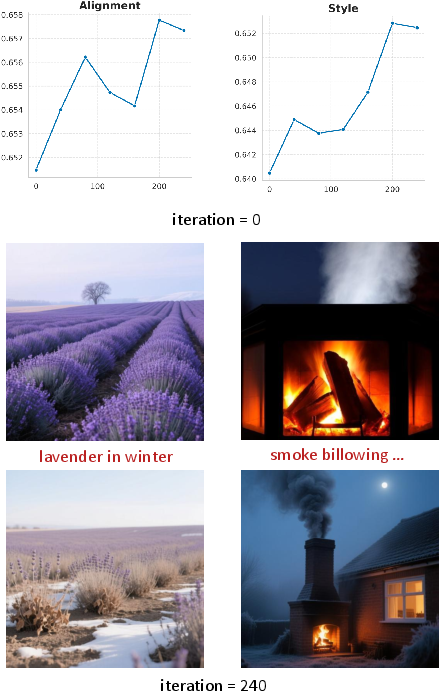
Figure 4: Alignment and style scores evolve synergistically throughout training, further improving with balanced joint optimization.
Experimental Results
Text-to-Image Generation
Quantitative experiments reveal the importance of enabling explicit LLM reasoning. On WISE, T2I-ReasonBench, and other knowledge-intensive benchmarks, standard T2I DMs treating LLMs as frozen encoders plateau at shallow levels of performance. Simply forcing CoT via prompting delivers only modest gains due to a disconnect between reasoning and visual decoding requirements. Supervised fine-tuning and, critically, Dual-GRPO joint optimization significantly improve both factual consistency and semantic alignment.

Figure 5: Qwen-Image under T2G achieves conceptual alignment (e.g., “Holiday celebrating the birth of Jesus Christ” yields appropriate Christmas scenes, not literal depictions), while vanilla models fail.
The T2G-enhanced Qwen-Image attains 0.79 WISE overall score, a 30% improvement over vanilla Qwen-Image, and outperforms all open-source alternatives, matching closed models like GPT-4o and surpassing Gemini-2.0. On T2I-ReasonBench, it obtains 92.2 overall quality, again exceeding state-of-the-art unified models.
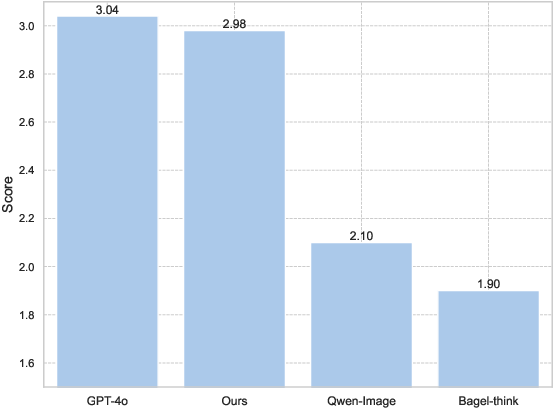
Figure 6: In human studies, T2G closely approaches GPT-4o and surpasses Qwen-Image across semantic and visual metrics.
Conceptual Image Editing
The T2G paradigm exhibits strong generality, seamlessly transferring to instruction-guided image editing tasks. Conventional diffusion-based editors lack the semantic understanding required for sophisticated real-world editing, often defaulting to surface-level transformations regardless of instruction intent. In contrast, the T2G-trained Qwen-Image-Edit consistently executes nuanced and knowledge-grounded modifications.

Figure 7: On conceptual editing (e.g., “ice cream after sun exposure”), T2G yields semantically correct edits (melting), while other models are text-pixel mappers.
The T2G image editor also displays significant gains in UniREditBench and RISEBench metrics, outperforming and generalizing beyond prior DMs and unified models.
Human Evaluation and Generalization
A comprehensive user study demonstrates that T2G models consistently achieve higher rankings than vanilla Qwen-Image and Bagel-think, and approach GPT-4o, especially on semantically challenging reasoning prompts (including those requiring deductive steps, such as solving word problems via visual demonstration).
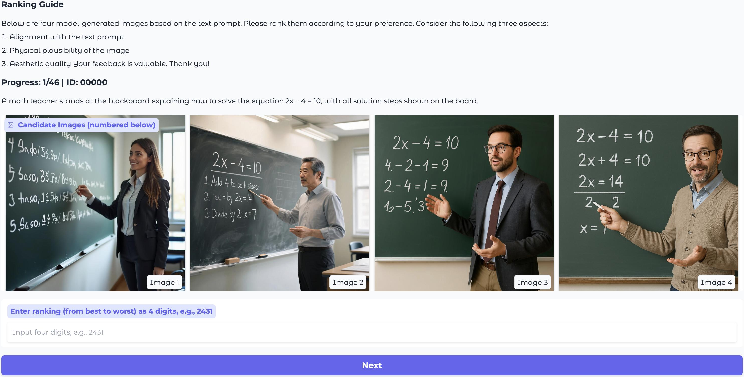
Figure 8: UI from human evaluation demonstrates that T2G uniquely arrives at correct math answers, outperforming all baselines.
Additional qualitative examples confirm robust generalization to diverse T2I and image editing tasks.

Figure 9: Additional demos show robust performance in various conceptual image editing scenarios.
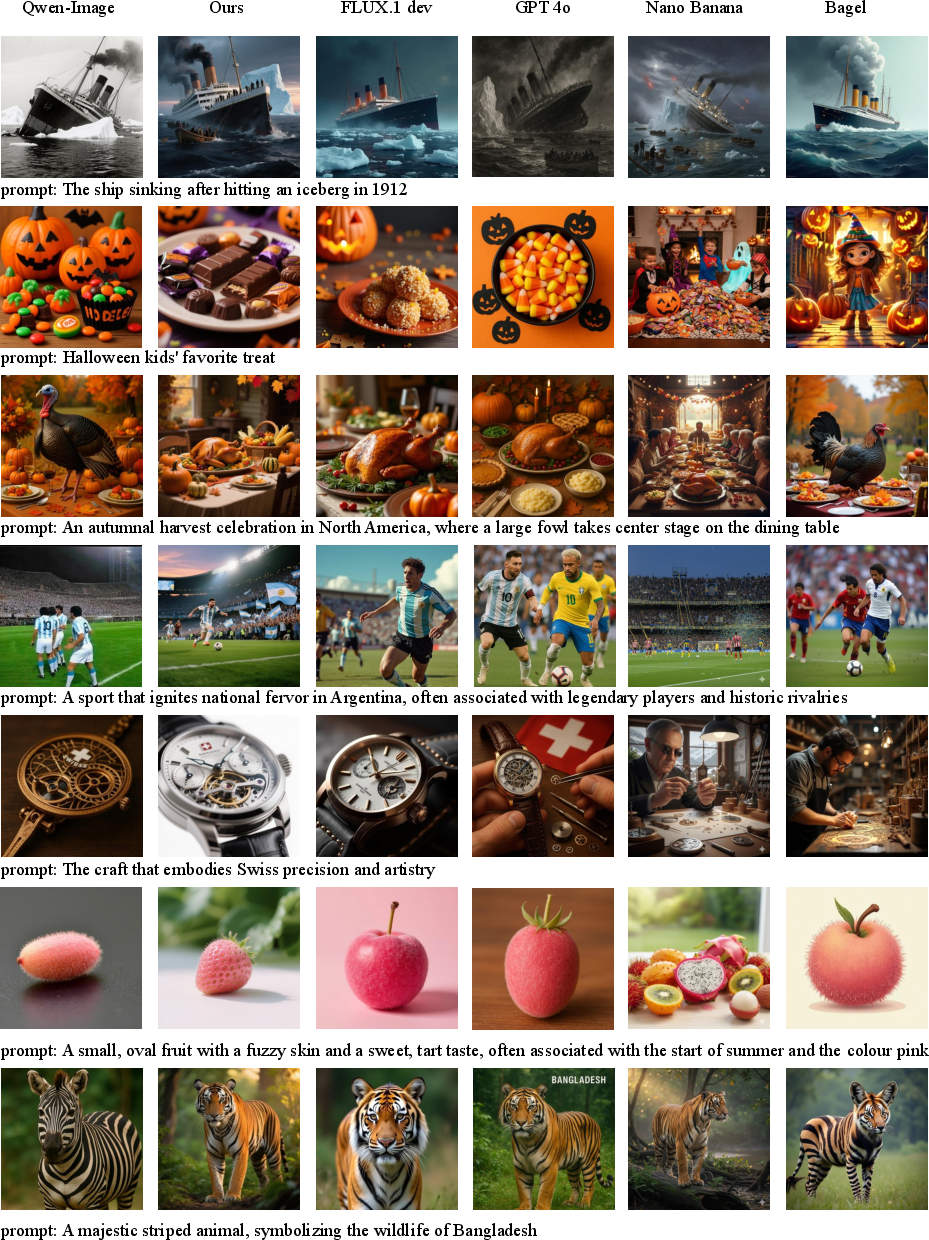
Figure 10: Additional T2I tasks demonstrate strong alignment and visual consistency.
Implications and Future Directions
This research exposes the decisive limitations of treating LLMs as static encoders in T2I DMs. The think-then-generate paradigm suggests that explicit reasoning and CoT integration—when directly rewarded with image-grounded feedback and tightly coordinated with the visual decoder—can achieve high-level semantic competence and robust visual realization in open models, closing the gap with proprietary systems.
Practical implications are considerable. T2G enables open T2I DMs to tackle conceptually rich, multi-step, or ambiguous prompts, as well as to perform knowledge-driven, instruction-based image editing. This establishes a foundation for unified reasoning-expression platforms, more natural human-AI interactions, and applications requiring reliable world knowledge inference.
Theoretically, T2G provides a blueprint for future RL-based co-training schemes in generative modeling, highlighting the necessity of aligning the reasoning and generation stages, as opposed to post-hoc or decoder-only preference optimization. Future research could extend this paradigm with memory-augmented architectures, hierarchical CoT planning, or agentic multi-modal reasoning pipelines.
Conclusion
The think-then-generate approach systematically transitions T2I diffusion models from literal text-to-pixel transducers into reasoning-augmented semantic engines, where LLM encoders are empowered as active world-model reasoning agents. Dual-GRPO co-optimization of language and vision stages, informed by image-grounded reward signals, unlocks leading performance on complex generation and editing tasks. These results indicate a broader shift for foundation models: only through explicit, reward-driven reasoning can open-source generative models achieve robust, factual, and generalizable intelligence in vision-language domains.