Urban Socio-Semantic Segmentation with Vision-Language Reasoning
Abstract: As hubs of human activity, urban surfaces consist of a wealth of semantic entities. Segmenting these various entities from satellite imagery is crucial for a range of downstream applications. Current advanced segmentation models can reliably segment entities defined by physical attributes (e.g., buildings, water bodies) but still struggle with socially defined categories (e.g., schools, parks). In this work, we achieve socio-semantic segmentation by vision-LLM reasoning. To facilitate this, we introduce the Urban Socio-Semantic Segmentation dataset named SocioSeg, a new resource comprising satellite imagery, digital maps, and pixel-level labels of social semantic entities organized in a hierarchical structure. Additionally, we propose a novel vision-language reasoning framework called SocioReasoner that simulates the human process of identifying and annotating social semantic entities via cross-modal recognition and multi-stage reasoning. We employ reinforcement learning to optimize this non-differentiable process and elicit the reasoning capabilities of the vision-LLM. Experiments demonstrate our approach's gains over state-of-the-art models and strong zero-shot generalization. Our dataset and code are available in https://github.com/AMAP-ML/SocioReasoner.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (a quick overview)
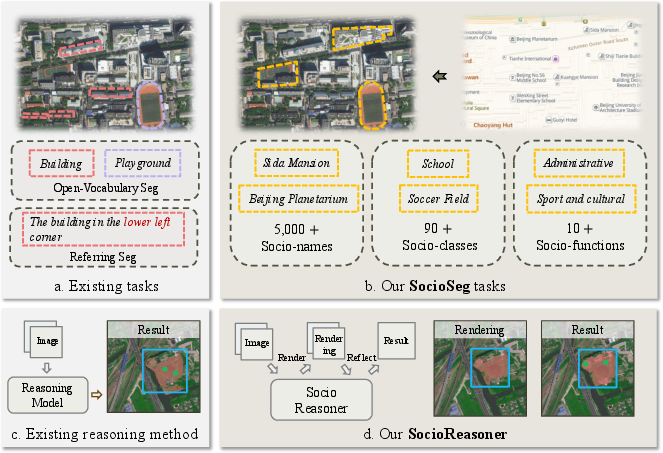
This paper is about teaching computers to “color in” parts of satellite images that represent places people care about, like schools, parks, and universities. These are not just things you can spot by their shape or color (like roads or rivers) — they are defined by their purpose in society. The authors call this “socio-semantic segmentation.” They build:
- A new dataset (SocioSeg) that pairs satellite pictures with simple digital maps and detailed labels for social places.
- A new method (SocioReasoner) that uses a vision-LLM (a model that understands both pictures and words) to reason step by step, like a human would, to find and outline these places.
What questions the paper tries to answer
- Can a computer find and accurately outline socially defined places (like “this is a school campus”) from satellite images, not just physically obvious things (like “this is water”)?
- If we give the computer both a satellite image and a simple digital map (with roads and place names), does that make it better at understanding social places?
- Does a human-like, multi-step reasoning process — first roughly finding a place, then carefully refining the edges — work better than one quick guess?
- Can this approach handle new places or new cities it hasn’t seen before (good “generalization”)?
How they did it (methods explained simply)
The new dataset: SocioSeg
Think of SocioSeg as a set of puzzles for the computer:
- Each puzzle has a satellite photo and a matching simple digital map (with basic roads and Points of Interest).
- The answer key is a clean outline (a mask) showing the exact area of the target place.
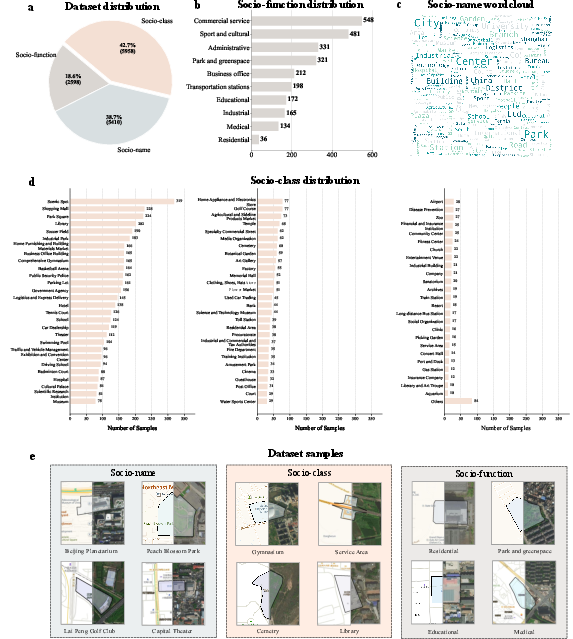
They organize the puzzles in three levels, from specific to general:
- Socio-name: a specific place (like “Wuhan University”).
- Socio-class: a type of place (like “college”).
- Socio-function: the broader purpose (like “educational”).
This design checks whether a model can handle precise names, broader categories, and abstract functions.
Why use a digital map layer? Instead of lots of messy, private, or hard-to-align data (like raw Points of Interest files), the map is already aligned with the satellite image and contains the useful hints (like labels and roads) in a simple picture form.
The new method: SocioReasoner
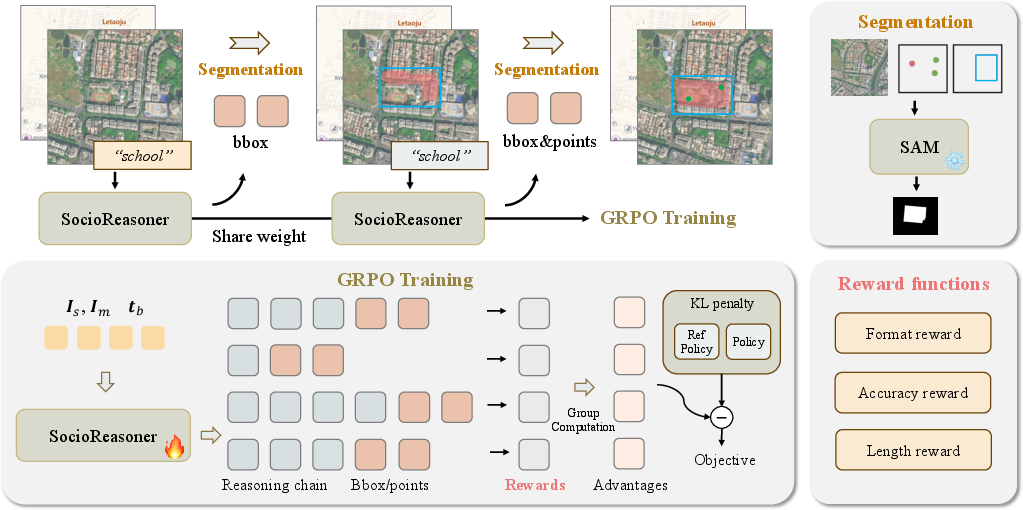
SocioReasoner acts like a careful human annotator who works in two stages:
- Localization (rough find)
- The model looks at the satellite image and the map, plus a text instruction (for example: “segment the college”).
- It draws one or more rectangles (bounding boxes) around the most likely area.
- A tool called SAM (Segment Anything Model) uses those rectangles to “paint” a rough filled-in area (a coarse mask).
- Refinement (clean up the edges)
- The model sees the image again with the rough area drawn on top.
- It adds small points (think of them like taps or pins) to guide SAM to fix the boundaries.
- SAM uses the rectangles and points to produce a sharper, more accurate mask.
Simple analogies:
- Bounding box = drawing a rectangle around the general area where the place is.
- Points = pokes that say “include this” or “adjust here.”
- Mask = the final colored-in shape of the place.
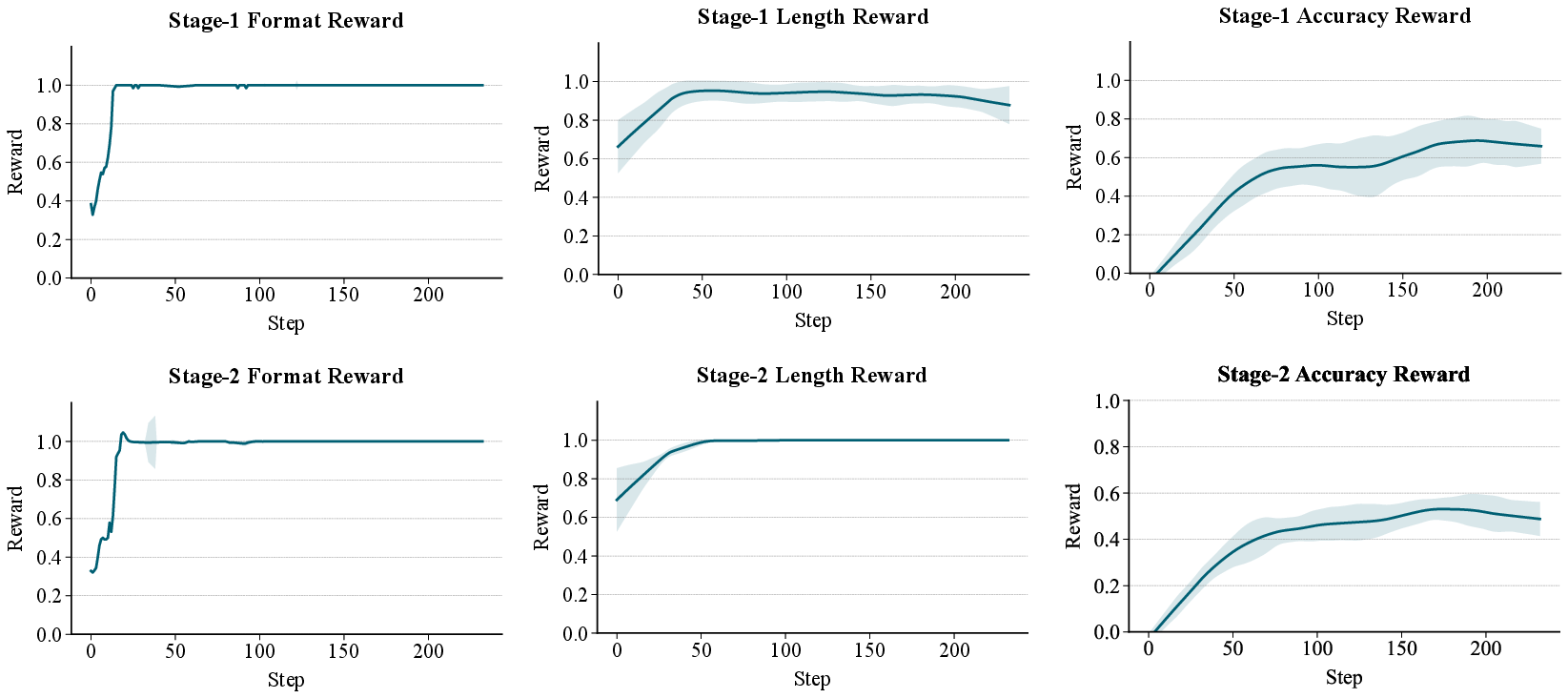
How they train it: reinforcement learning
Some parts of this process are hard to train with standard methods, so they use reinforcement learning (RL), which is like a game with a score:
- The model tries a set of boxes/points.
- It gets a reward based on how well its colored area overlaps with the correct area (overlap is measured using IoU — Intersection over Union — which is basically “how much the computer’s shape and the correct shape overlap, divided by how much space they cover together”).
- Over many tries, the model learns strategies that earn higher scores.
You can think of this as the model practicing: try, get a score, try again, get better.
What they found and why it matters
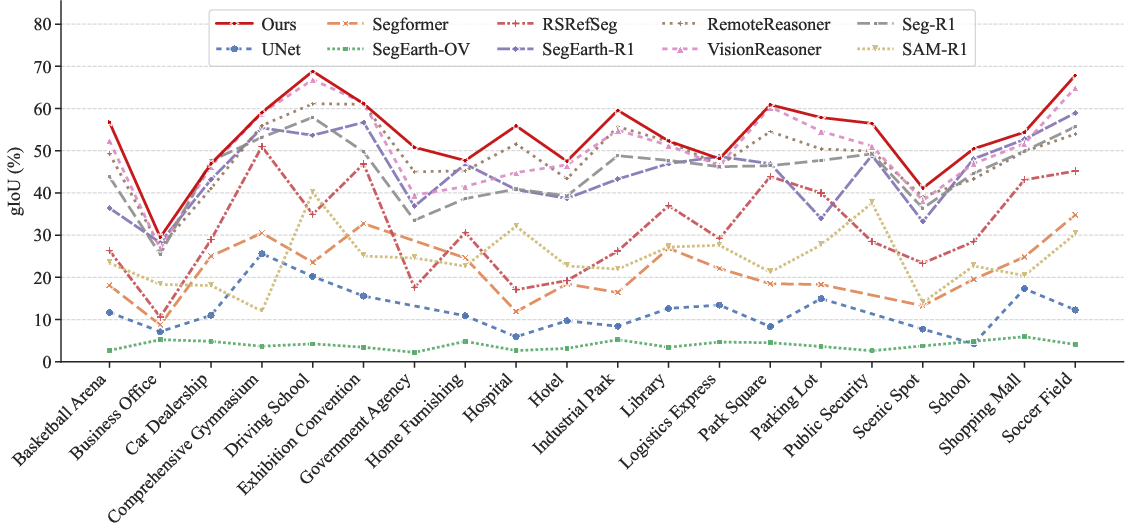
- Better accuracy than other methods: SocioReasoner beats strong baselines, including:
- Standard segmentation models (great for roads/buildings, but they struggle with social categories).
- Vision-language reasoning methods built for normal photos.
- Specialized satellite-image models focused on physical features.
- Two-stage is better than one-stage: Doing a quick rough find, then refining with guidance points, makes the final outlines more precise.
- The right amount of guidance helps: Using about two points in the refinement stage worked best on average (one was often too weak, three could be unstable).
- RL makes it more robust: Training with “trial-and-reward” helps the model handle new map styles (like switching from one map provider to another) and new cities it didn’t see during training. That’s important for real-world use.
Trade-off: Because SocioReasoner thinks and acts in multiple steps, it can be slower than one-shot methods. But the accuracy gain is significant.
Why this is important
- Real-world uses: City planning, tracking access to green spaces, school district analysis, emergency response, public health studies (like modeling how people move and gather), and improving navigation and recommendations by better understanding Areas of Interest.
- Less reliance on sensitive data: By turning many different data sources into a single, aligned map image, this approach avoids some of the pain and privacy issues of handling raw, proprietary data.
- A path forward for “social” understanding from space: Most old methods focused on “what it looks like.” This work shows we can capture “what it is for,” which is often what city planners, businesses, and communities care about.
In short (implications)
- The paper introduces a new task and dataset that make computers better at finding socially meaningful places in satellite images.
- A human-like, two-step reasoning process plus reinforcement learning gives clear improvements and works across new map styles and regions.
- This could lead to smarter, more up-to-date maps and stronger tools for understanding how cities work — if used responsibly and ethically.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper that future researchers could address.
- Dataset geographic coverage and representativeness: The main SocioSeg dataset appears to be sourced from Amap (likely China-centric) with limited evidence of broad global coverage; quantify geographic diversity, urban morphology variety, and tail-class representation, and expand to more regions and settlement types (e.g., rural, peri-urban).
- Label definition and boundary criteria: The paper does not specify how socio-semantic boundaries were operationalized (e.g., legal parcels vs. perceived campus extents); publish annotation guidelines, inter-annotator agreement, and strategies for ambiguous cases.
- Multi-label and overlapping functions: Urban entities often have multiple social functions (e.g., mixed-use); clarify whether masks are single-label or multi-label, and develop metrics and protocols for multi-label socio-semantic segmentation.
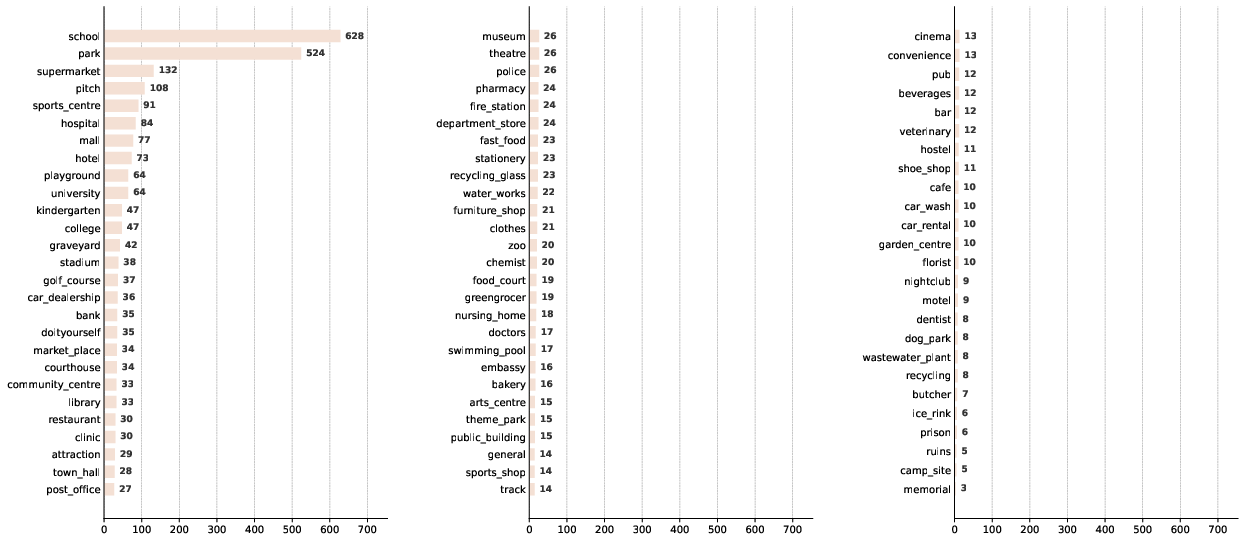
- Class imbalance and tail performance: Only top-20 classes are analyzed; provide full per-class results, tail-class robustness, and techniques to mitigate imbalance (re-weighting, sampling, augmentation).
- Temporal alignment and dynamics: Satellite imagery and digital maps may be captured at different times; quantify performance degradation under temporal misalignment, outdated POIs, or rapid urban change, and explore temporal reasoning.
- Sensitivity to image–map misregistration: Although maps are “co-registered,” small spatial offsets are common; conduct controlled misalignment experiments to quantify robustness and develop alignment-invariant prompting strategies.
- Map provider dependence and bias: The approach relies on Amap tiles and is evaluated OOD only on Google Maps; systematically test across diverse providers (OSM/Mapbox/Apple) and styles, and characterize provider-specific POI coverage and noise impacts.
- Map content limitations: The rendered map uses only roads and POIs; evaluate gains from richer layers (building footprints, parcels, land-use/zoning, transit, amenities) and quantify which layers most improve socio-semantic reasoning.
- Cross-lingual robustness: Amap offers Chinese/English maps, but cross-language performance is not analyzed; test prompts and map texts across languages (scripts, transliterations, synonyms) and apply multilingual training/evaluation.
- Socio-name segmentation as open-set: Each named entity effectively becomes a unique class; formalize evaluation protocols for open-set/instance-level names, prevent label leakage, and design scalable training for long-tail names.
- Instance separation and multi-part entities: Handling entities composed of disjoint areas (e.g., multi-campus universities) is not discussed; evaluate multi-instance segmentation quality, separation errors, and instance association strategies.
- SAM dependence in remote sensing: SAM is frozen and used via prompts; compare against domain-adapted mask decoders (SAM fine-tuning, remote-sensing-specific models) and quantify trade-offs between prompt-only vs. model adaptation.
- RL reward design sensitivity: The GRPO rewards (syntax, localization, IoU, point length) are hand-crafted; perform ablations on reward terms, scales, clipping, and KL regularization, and report stability, convergence, and sample efficiency.
- Training and compute budgets: The paper omits compute cost (GPU-hours), sampling group size G, and runtime per step; report training/inference efficiency and propose strategies for cost reduction (curriculum, cached SAM, policy distillation).
- Inference latency and scalability: Two-stage render-and-refine increases latency; publish throughput and wall-clock metrics, and investigate speed–accuracy trade-offs (early exit, adaptive number of prompts, batching).
- Failure modes and robustness: Provide systematic error analysis for map noise (incorrect/missing POIs), visual occlusions, seasonal effects, cloud cover, image resolution changes, and adversarial or malformed JSON outputs.
- Generalization across sensors and resolutions: Data are from Amap imagery; evaluate on diverse satellite sensors (Sentinel-2, Planet, Maxar), resolutions, and spectral bands, and explore multi-sensor domain adaptation.
- Downstream application validation: Claims about AOI reconstruction, navigation, and recommendation are not empirically validated; run end-to-end studies quantifying gains in industrial pipelines and urban analytics tasks.
- Hierarchical task transfer: It is unclear whether joint training across name/class/function helps; study multi-task learning, curriculum across hierarchy, and cross-task transfer effects (e.g., pretraining on function improves name).
- Uncertainty quantification: No confidence estimates are provided; add calibrated uncertainty for masks and prompts (e.g., Bayesian heads, ensembles) to support decision-making in planning and safety-critical applications.
- Reasoning faithfulness and interpretability: The method claims an interpretable chain but does not validate step-level correctness; design tests to verify that emitted boxes/points causally improve masks and align with textual reasoning.
- Adaptive refinement strategies: The point number is fixed (two); explore dynamic, iterative refinement (multi-round prompts, termination criteria) and policies that adapt point count/placement based on mask error patterns.
- Style normalization and vectorization: The pipeline uses raster maps; assess benefits of vector maps and style-agnostic representations (symbol normalization, schema mapping) to improve cross-provider generalization.
- Legal/administrative vs. physical extents: Many social entities are defined by legal parcels rather than visual footprints; evaluate alignment with authoritative boundaries and reconcile conflicts between administrative and visual extents.
- Data licensing and reproducibility: Clarify redistribution rights for map tiles and satellite imagery; provide procedures to rebuild SocioSeg with alternative providers to ensure reproducibility under differing licenses.
- Baseline fairness with multi-image inputs: Some baselines are restricted to single-image inputs; include adapted multi-modal baselines or report controlled comparisons to isolate the contribution of adding map context.
- Integration of additional modalities: Explore whether mobility traces (check-ins, traffic), building metadata, and textual corpora (web pages) further improve socio-semantic segmentation and reasoning.
- Security and prompt robustness: Examine resilience to prompt injection, malformed JSON, or adversarial language inputs, and add guardrails to ensure safe, valid outputs in production.
Practical Applications
Practical Applications of “Urban Socio-Semantic Segmentation with Vision-Language Reasoning”
The paper introduces SocioSeg (a new benchmark) and SocioReasoner (a two-stage VLM+SAM, RL-optimized pipeline) to delineate socially defined urban entities (e.g., schools, parks, districts) from satellite imagery and rendered digital maps. Below are actionable applications, grouped by deployment horizon. Each item indicates target sectors, potential tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
These can be piloted or integrated now using the released dataset and code, widely available satellite tiles, and public map layers.
- AOI polygonization from POIs for mapping/navigation
- Sectors: software (mapping SDKs), mobility, logistics, advertising-tech
- What: Convert point POIs (e.g., “X High School”) into precise AOI polygons via the render-and-refine pipeline; improves search ranking, map labeling, snap-to-region, and geofencing.
- Tools/Workflows: “POI→AOI Polygon Service” API; nightly batch jobs to maintain AOIs; conflation with existing map layers.
- Assumptions/Dependencies: Access to high-resolution satellite tiles; map tile licenses; SAM/VLM inference compute; periodic QA to correct local quirks.
- Map conflation, QA, and gap-filling
- Sectors: software (GIS, mapping), public sector GIS
- What: Cross-validate digital map labels/boundaries with VLM-derived socio-semantic masks; auto-flag missing parks, misnamed campuses, or outdated facility extents.
- Tools/Workflows: “SocioBoundary QA” dashboard; false-positive triage queues; change detection triggers for human review.
- Assumptions/Dependencies: Versioned basemaps; alignment of tile projections; human-in-the-loop sign-off for edits.
- 15-minute city and accessibility diagnostics
- Sectors: policy, urban planning, real estate analytics
- What: Compute proximity coverage to socio-functions (education, health, recreation) at block or tract level using the model’s socio-function masks.
- Tools/Workflows: “15-Min Scoring” notebook/templates; KPI dashboards for coverage gaps; export to policy briefs.
- Assumptions/Dependencies: Up-to-date map tiles; basic census or grid population data for normalization.
- Green space and amenity equity audits
- Sectors: policy, ESG, environmental planning
- What: Quantify park/green AOI ratios by neighborhood; identify underserved areas; feed into ESG reports or city resilience plans.
- Tools/Workflows: Automated AOI area summaries; equity scorecards; reproducible pipelines built on SocioSeg code.
- Assumptions/Dependencies: Satellite resolution sufficient to delineate park edges; stable class definitions for “green.”
- Site selection and retail/telecom catchment analysis
- Sectors: retail analytics, telecom (RAN planning), real estate
- What: Use socio-class/function masks to refine demand proxies (e.g., “schools within 1 km”); inform store placement or small-cell siting.
- Tools/Workflows: “Contextual Catchment” API; model-driven heatmaps; export to BI tools.
- Assumptions/Dependencies: Local category taxonomies mapped to SocioSeg hierarchy; privacy-safe aggregation.
- Mobility and delivery geofencing
- Sectors: micro-mobility, last-mile logistics, event management
- What: Define operational polygons for slow/stop zones (e.g., schools/parks), or delivery drop-off exclusion areas.
- Tools/Workflows: “Dynamic Geo-Policy” rules engine integrating AOIs; fleet SDKs consuming updated masks.
- Assumptions/Dependencies: Policy compliance; timely updates when facilities change.
- Emergency planning and drills
- Sectors: public safety, emergency management, NGOs
- What: Maintain authoritative polygons for schools/hospitals/community centers to design evacuation routes and staging areas.
- Tools/Workflows: “Critical Facilities AOI Layer”; scenario planning overlays; export to WebGIS.
- Assumptions/Dependencies: Accuracy of socio-name segmentation; governance for sensitive sites.
- Real estate and consumer discovery features
- Sectors: proptech, consumer apps
- What: Enrich listings and neighborhood pages with verified distances/coverage to parks, schools, clinics; context-aware search (“near education cluster”).
- Tools/Workflows: “Amenity Context” microservice; map overlays in apps; periodic refresh jobs.
- Assumptions/Dependencies: Legal use of map tiles; control for bias and fair presentation of amenities.
- Academic benchmarking and coursework
- Sectors: academia (remote sensing, GIS, CV/NLP)
- What: Use SocioSeg to teach/open-benchmark VLM-based geospatial reasoning; compare supervised vs RL training regimes; study OOD generalization.
- Tools/Workflows: Colab notebooks; reproducible RL training scripts; assignment rubrics.
- Assumptions/Dependencies: GPU availability; adherence to dataset license.
- Annotation acceleration in GIS teams
- Sectors: GIS, mapping production, research labs
- What: Human-in-the-loop “render-and-refine” assistant to pre-fill polygons that editors adjust, speeding up labeling of campuses/parks/districts.
- Tools/Workflows: QGIS/ArcGIS plugin backed by SocioReasoner; audit trails; active learning loops.
- Assumptions/Dependencies: Editor training; integration with enterprise GIS; maintain prompt schemas/JSON validity.
Long-Term Applications
These are promising but require further research, scaling, policy agreements, or productization (e.g., broader OOD robustness, temporal reasoning, governance).
- City-scale digital twins with socio-semantic layers
- Sectors: smart cities, planning tech
- What: Continuously updated, machine-derived socio-name/class/function layers embedded in municipal digital twins for simulation and permitting workflows.
- Tools/Workflows: Streaming update pipelines; versioned AOI histories; APIs for modeling tools.
- Assumptions/Dependencies: City data partnerships; SLAs on accuracy and refresh rates; change detection over time-series imagery.
- Temporal change detection and zoning enforcement
- Sectors: policy, compliance, land-use regulation
- What: Identify unauthorized land-use transitions (e.g., public space encroachment) through time-aware socio-semantic segmentation.
- Tools/Workflows: “Use-Change Watch” service; alerts to inspectors; adjudication dashboards.
- Assumptions/Dependencies: Access to time-series imagery; legal frameworks for automated evidence; low false positive rates.
- Epidemiology and public health modeling
- Sectors: health policy, NGOs, academia
- What: Couple socio-function masks (schools, markets, worship places) with mobility/population layers to parameterize contact networks and targeted interventions.
- Tools/Workflows: Risk modeling kits; intervention planning maps; evaluation pipelines.
- Assumptions/Dependencies: Ethical data governance; co-variates (mobility, demographics); uncertainty quantification.
- AV/robotics context-aware mapping
- Sectors: autonomous driving, outdoor robotics, AR
- What: Enrich HD maps with human-centered semantics (e.g., school zones, playgrounds) for behavior planning and context-aware AR overlays.
- Tools/Workflows: “Socio-Context Enrichment” SDK for HD maps; on-vehicle edge inference variants.
- Assumptions/Dependencies: Real-time constraints; rigorous safety validation; licensing of basemap layers.
- Insurance and finance risk underwriting
- Sectors: insurance, finance
- What: Use AOI delineations to assess exposure (e.g., schools/elderly homes near flood zones) and inform pricing or portfolio risk.
- Tools/Workflows: “Contextual Exposure” scoring; integration with catastrophe models.
- Assumptions/Dependencies: Regulatory approval; explainability; audited performance across regions.
- Global SDG and inequality dashboards
- Sectors: international development, policy research
- What: Harmonized, global measurement of access to education/health/green spaces; progress tracking for SDG 3/4/11.
- Tools/Workflows: Open dashboards; reproducible country reports; data donation pipelines.
- Assumptions/Dependencies: Broad OOD robustness (different cartographic styles/languages); periodic updates; fair comparisons across cities.
- Drone/UAM geofencing and urban airspace rules
- Sectors: aviation tech, public safety
- What: Generate and maintain sensitive site polygons (schools, hospitals, government complexes) to inform flight planning and automated geo-fencing.
- Tools/Workflows: “Sensitive AOI Feed” to UTM providers; compliance validators.
- Assumptions/Dependencies: Regulatory endorsement; strict precision/recall thresholds; integration with NOTAM/airspace data.
- Energy and infrastructure planning
- Sectors: energy utilities, public works
- What: Prioritize microgrids or cooling centers by overlaying socio-functional clusters with heat-risk and grid topology.
- Tools/Workflows: Planning copilots; multi-criteria decision analysis with AOIs.
- Assumptions/Dependencies: Access to grid and risk layers; stakeholder alignment; credible model governance.
- Foundation models for geospatial socio-semantics
- Sectors: AI research, platform providers
- What: Pre-train/align VLMs on large-scale, multi-region socio-semantic data; unify text, map, and imagery for open-vocabulary urban reasoning.
- Tools/Workflows: Multimodal pretraining pipelines; RL with non-differentiable rewards (IoU) at scale; evaluation suites.
- Assumptions/Dependencies: Diverse global datasets and licenses; compute budgets; robust data curation and bias checks.
- Privacy-preserving, on-device mapping assistants
- Sectors: consumer apps, field NGOs
- What: Lightweight, on-device socio-semantic segmentation for offline contexts (disaster response, rural mapping) with federated updates.
- Tools/Workflows: Distilled SocioReasoner variants; tiled inference; secure model updates.
- Assumptions/Dependencies: Efficient SAM/VLM distillation; device constraints; privacy guarantees.
Cross-Cutting Assumptions and Dependencies
- Data access and licensing: Legal use of satellite tiles and digital map layers (Amap or alternatives); adherence to regional data restrictions.
- Resolution and coverage: Sufficient spatial resolution to delineate boundaries; rural or informal settings may need tailored models.
- Generalization: While RL improved OOD robustness, further validation is needed across styles, languages, and continents.
- Human-in-the-loop: Quality control and ethical oversight (especially for sensitive sites) remain essential.
- Infrastructure: GPU/accelerator availability for training/inference; MLOps for versioned models and audit trails.
- Governance and ethics: Avoid surveillance or discriminatory applications; ensure fairness and transparency in public-facing products.
These applications leverage the paper’s key innovations: (1) a unified digital-map rendering that simplifies heterogeneous geospatial fusion; (2) a human-like, two-stage render-and-refine reasoning workflow; and (3) RL optimization (GRPO) directly aligned with non-differentiable segmentation quality. Together, they enable deployable improvements to today’s maps and analytics, and open credible paths toward richer, policy-relevant urban intelligence at scale.
Glossary
- 15-minute city: An urban planning concept where daily necessities are accessible within a 15-minute walk or bike ride. "the 15-minute city"
- Areas of Interest (AOIs): Spatial regions representing semantically meaningful places or complexes, often larger than single points. "inferring socio-semantic Areas of Interest (AOIs) from Points of Interest (POIs) to enhance navigation and recommendation"
- bounding box prompts: Rectangular region hints used to guide a segmentation model toward target locations. "it first generates bounding box prompts from both satellite and map imagery to localize the target region"
- cartographic style: The visual design and symbology choices used to render maps, which can vary across map providers. "The “OOD (Map Style)” setting tests robustness to cartographic style shifts."
- cIoU: Class-level Intersection over Union; IoU computed per class and averaged, emphasizing balanced performance across categories. "we follow previous work \citep{lai2024lisa} in reporting cIoU and gIoU."
- co-registered: Spatially aligned across layers or sensors so corresponding pixels map to the same geographic location. "the map layer is inherently co-registered with the satellite imagery"
- coarse mask: An initial, approximate segmentation result that may require further refinement. "to produce a preliminary coarse mask "
- cross-modal recognition: Identifying and aligning information across different modalities (e.g., images and text). "via cross-modal recognition and multi-stage reasoning"
- digital map layer: A rasterized, unified rendering of heterogeneous geospatial data used as an image input. "a single digital map layer"
- Earth Observation: The acquisition and analysis of information about Earth’s surface using remote sensing and related data. "a critical subject for Earth Observation"
- gIoU: Global Intersection over Union; IoU computed across all pixels globally, reflecting overall segmentation quality. "we follow previous work \citep{lai2024lisa} in reporting cIoU and gIoU."
- geolocalization: Determining the geographic location depicted in an image or scene. "geolocalization \citep{li2024georeasoner}"
- geospatial: Pertaining to data or analysis that is tied to geographic coordinates and locations. "incorporating auxiliary multi-modal geospatial data (e.g., Points of Interest)"
- Group Relative Policy Optimization (GRPO): A reinforcement learning method that uses group-based baselines to compute advantages for policy updates. "using reinforcement learning with Group Relative Policy Optimization (GRPO)"
- in-domain (ID): Data drawn from the same distribution or setting as the training set. "where ID and OOD refer to in-domain and out-of-domain, respectively."
- Intersection over Union (IoU): A segmentation metric measuring overlap between predicted and ground-truth masks. "non-differentiable IoU"
- KL regularization: A penalty based on Kullback–Leibler divergence to keep the learned policy close to a reference policy. "a clipped PPO-like surrogate with KL regularization against a frozen reference policy"
- non-differentiable: Not permitting gradient-based optimization end-to-end, requiring alternative training strategies. "Since this pipeline is non-differentiable"
- open-vocabulary segmentation: Segmenting objects described by arbitrary text labels beyond a fixed training taxonomy. "open-vocabulary segmentation \citep{ghiasi2022scaling}"
- out-of-domain (OOD): Data from a different distribution, style, or region than the training set. "where ID and OOD refer to in-domain and out-of-domain, respectively."
- Points of Interest (POIs): Discrete, labeled locations (e.g., shops, schools) used as geospatial cues. "Points of Interest (POIs)"
- PPO-like surrogate: The clipped objective function used in Proximal Policy Optimization for stable policy updates. "a clipped PPO-like surrogate with KL regularization"
- referring segmentation: Segmenting an object specified by a natural-language referring expression. "referring segmentation \citep{wang2022cris}"
- render-and-refine mechanism: A two-stage process that first renders a coarse result and then iteratively refines it with additional prompts. "employs a two-stage reasoning strategy with a render-and-refine mechanism"
- reinforcement learning (RL): Training an agent to act via rewards from an environment rather than supervised labels. "We employ reinforcement learning to optimize this non-differentiable process"
- Segment Anything Model (SAM): A promptable segmentation model that outputs masks given points, boxes, or other hints. "Segment Anything Model (SAM)"
- socio-semantic segmentation: Segmenting entities defined by social semantics (names, functions, classes) rather than purely physical appearance. "we achieve socio-semantic segmentation by vision-LLM reasoning."
- Supervised Fine-Tuning (SFT): Further training of a model on labeled pairs using standard supervised learning. "a Supervised Fine-Tuning (SFT) baseline."
- token-level importance ratio: In PPO-style methods, the per-token ratio of current to reference policy probabilities used for clipping. "is the token-level importance ratio."
- visual grounding: Linking textual mentions to their corresponding regions in an image. "visual grounding \citep{bai2025univg}"
- Vision-LLM (VLM): A multimodal model jointly processing images and text for understanding and reasoning. "Recent advances in Vision-LLMs (VLMs)"
- visual prompts: Guidance inputs such as boxes or points provided to a segmentation model to focus on targets. "These methods feed visual prompts (e.g., bounding boxes or points) derived from VLM inference into the SAM"
- zero-shot generalization: Performing well on unseen categories or data without additional task-specific training. "strong zero-shot generalization."
Collections
Sign up for free to add this paper to one or more collections.