- The paper presents a fully automated pipeline that generates a large-scale video action dataset with 147M temporally localized segments.
- It employs hierarchical segmentation and multi-level captioning to provide dense, open-vocabulary annotations for precise action recognition.
- Empirical results show improved zero-shot recognition and robust transfer across video action benchmarks through semantic resampling.
Action100M: The Next-Generation Large-Scale Video Action Dataset
Motivation and Dataset Development
The development of open-domain and open-vocabulary video action recognition models is constrained by limited data scale and diversity in existing datasets. Most standard resources (e.g., COIN, CrossTask, YouCook2, EgoProceL, Ego4D) are hampered either by manual annotation bottlenecks, restrictive domain coverage, or insufficient annotation granularity. Action100M confronts these limitations by leveraging 1.2M curated instructional videos, yielding approximately 147 million temporally localized segments annotated with multi-level, open-vocabulary action labels and captions. The fully automated pipeline integrates three key components: hierarchical temporal segmentation via V-JEPA 2 embeddings, multi-level caption generation with PerceptionLM and Llama-3.2-Vision, and structured evidence aggregation with GPT-OSS-120B under a multi-round Self-Refine protocol.
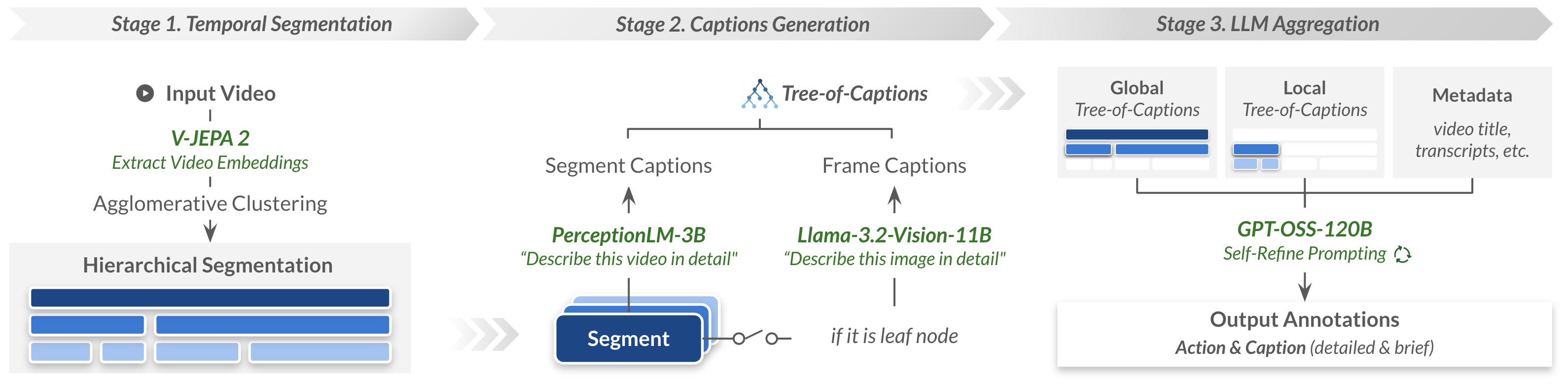
Figure 1: Overview of the Action100M pipeline: hierarchical temporal segmentation, multi-scale captioning, and LLM-based aggregation produce fine-grained annotations.
Each segment in the Tree-of-Captions is independently processed, resulting in annotations at multiple levels of abstraction—brief/detailed action descriptions, actor identification, and brief/detailed captions. This hierarchical annotation schema provides dense supervision for both local procedural steps and global activity context, making Action100M uniquely suited for training advanced world models and enabling robust embodied learning.

Figure 2: Example hierarchical structure of Action100M annotation; granular and contextual captions allow temporal abstraction.
Dataset Composition and Annotation Statistics
Action100M spans 14.6 years of video content with comprehensive metadata coverage. The majority of videos are short instructional clips sourced from HowTo100M, predominantly encompassing domains such as cooking, DIY, and everyday physical tasks. ASR transcripts are available for approximately 72% of the corpus.

Figure 3: Distributions of upload year, view count, video duration, and transcript length in Action100M source metadata.
The annotation process produces four main types: brief action (mean 3.2 words), brief caption (mean 19.2 words), detailed action (mean 27.8 words), and detailed caption (mean 95.3 words), totaling over 21 billion English words. N-gram analysis confirms strong verb dominance in action descriptions and richer object-centric context in captions.

Figure 4: Word cloud of Action100M video titles—keywords reflect dataset’s domination by instructional content and procedural tasks.
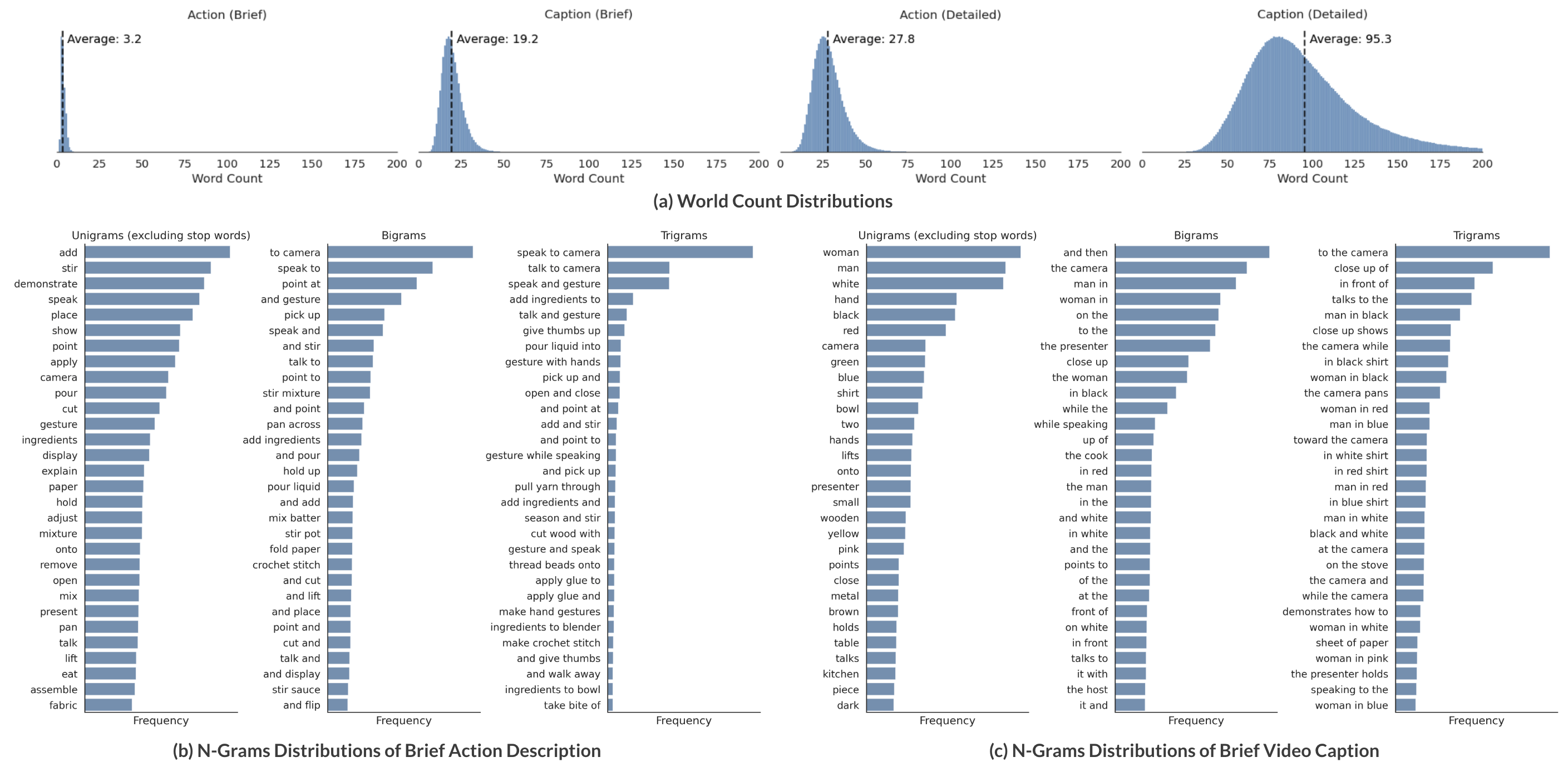
Figure 5: Quantitative annotation statistics: length distributions and top n-grams for action descriptions and video captions.
Action frequency exhibits a pronounced long-tail effect, with significant redundancy (over 141 million duplicate brief actions) that is explicitly addressed by deduplication and semantic resampling strategies.
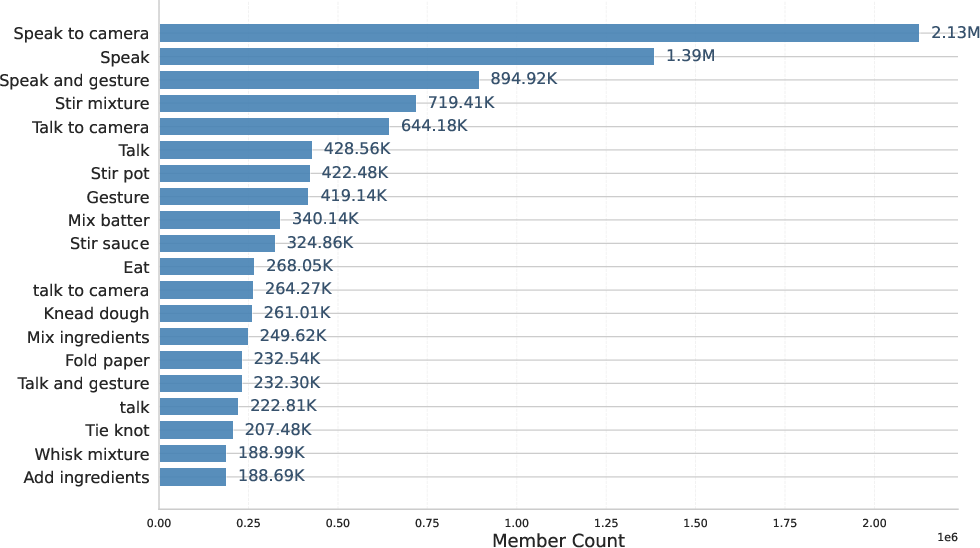
Figure 6: Distribution of duplicated brief action descriptions, highlighting redundancy and long-tailed occurrence.
Hierarchical and Semantic Diversity
Action100M annotations encode complex hierarchical action compositions as demonstrated by sunburst visualizations, revealing frequent co-occurrences and semantic structure within the action vocabulary.

Figure 7: Sunburst visualizations expose hierarchical semantic relationships in five most frequent brief action verbs.
Semantic clustering further organizes the deduplicated action space, supporting controlled granularity from broad compositional clusters (k=103) to highly specific ones (k=105), facilitating uniform sampling of rare actions and reducing bias.






Figure 8: Cluster visualizations show semantic grouping efficacy and granularity trade-off with different k values in k-means clustering.
Coverage assessment via UMAP demonstrates strong alignment between semantic clusters and standard downstream benchmarks, confirming the dataset’s breadth.
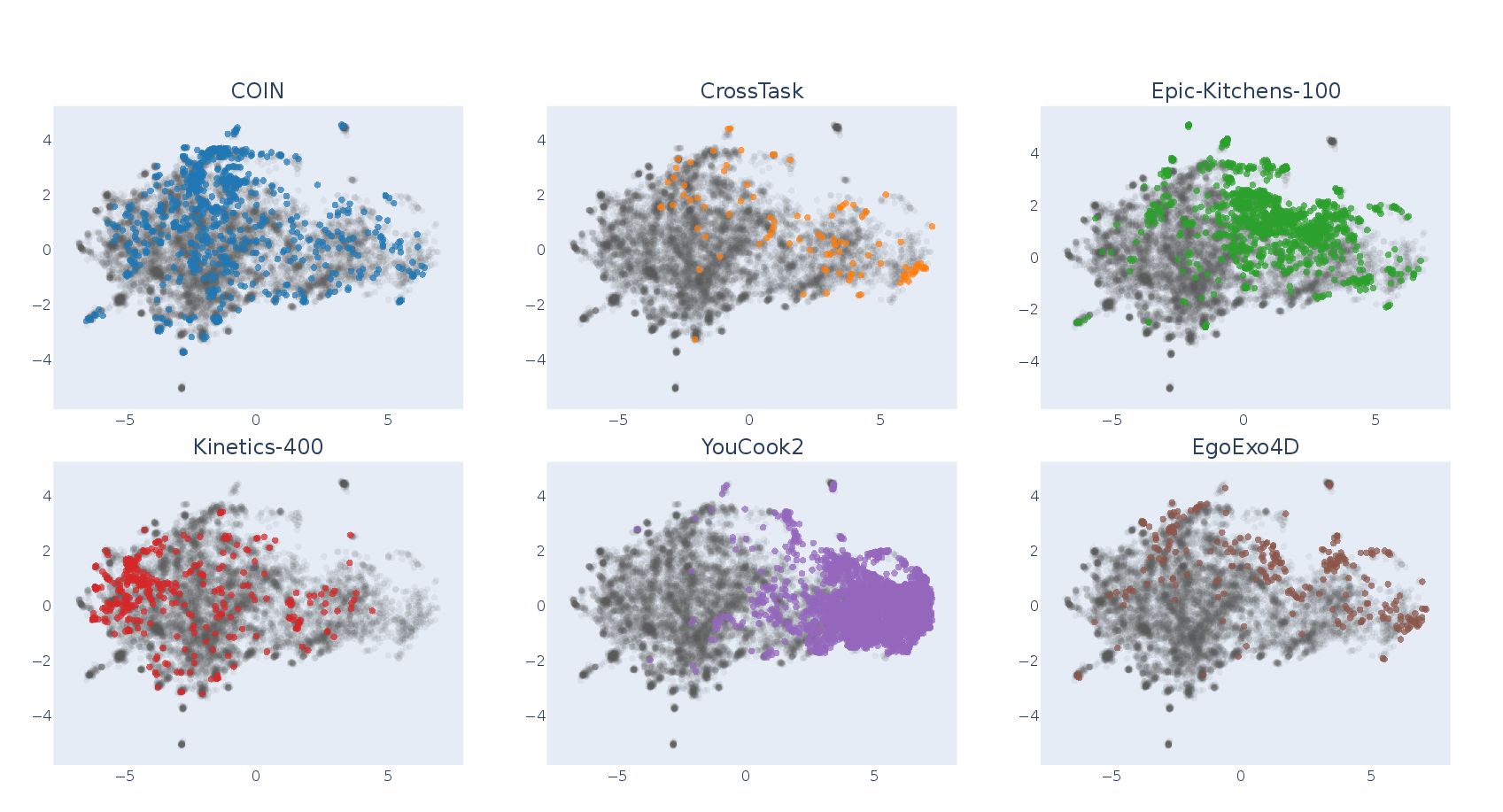
Figure 9: UMAP visualization illustrates overlap of Action100M clusters with canonical downstream datasets, ensuring broad representational coverage.
Experimental Evaluation: Scaling Laws and Transfer
VL-JEPA, a vision-LLM employing V-JEPA 2 encoders and InfoNCE-based contrastive alignment, was pretrained on Action100M in a three-stage protocol (image-only, short video, long video). Empirical scaling reveals that zero-shot action recognition accuracy increases consistently with training sample size, outperforming CLIP, SigLIP2, and Perception Encoder models on a range of benchmarks despite using fewer samples and lower backbone resolution.
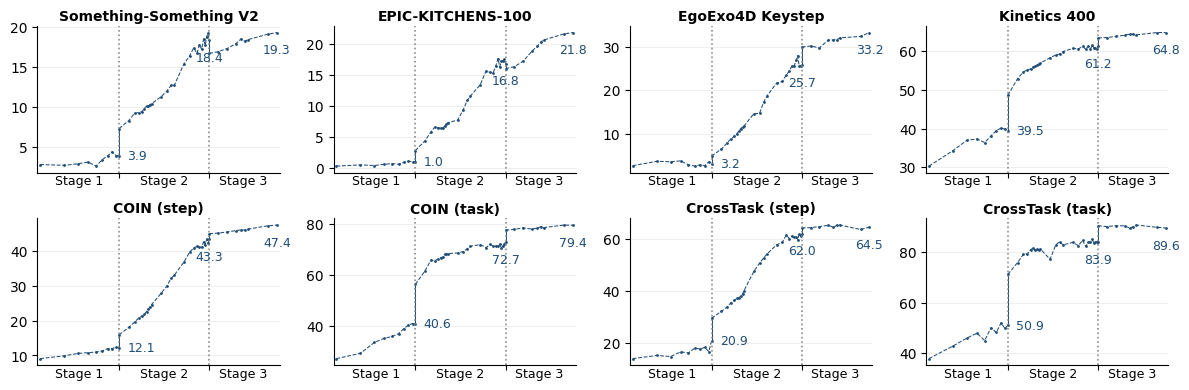
Figure 10: Staged scaling results: zero-shot action recognition improves monotonically with scale across pretraining stages.
In ablation studies, Action100M brief action annotations delivered superior gains compared to direct PLM-3B pseudo-labeling, validating the pipeline’s hierarchical captioning and LLM aggregation steps.
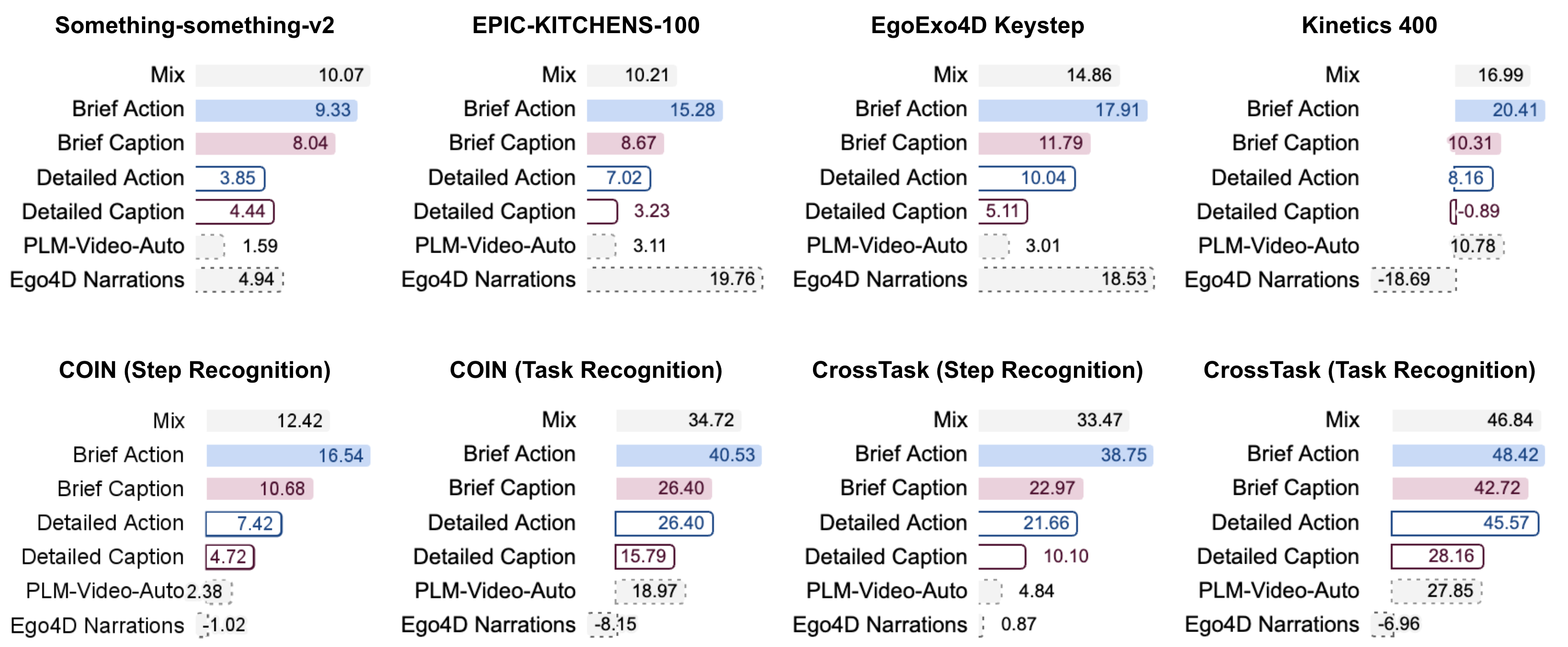
Figure 11: Stage 2 pretraining using Action100M data outperforms baseline data sources, verifying annotation quality and pipeline effectiveness.
Semantic resampling using k-means clustering of action embeddings demonstrably improves overall benchmark performance, particularly when using a smaller number of clusters to compensate for frequency imbalance.
Dataset Implications and Future Directions
Action100M redefines the landscape of action-centric video understanding through scale, diversity, and annotation richness. The hierarchical multi-level labeling schema enhances the training of models capable of both low-level motion recognition and long-horizon procedural reasoning. Its demonstrated transfer to diverse video action and retrieval benchmarks, particularly for fine-grained physical actions, underscores strong compositional generalization and sample efficiency. The dataset's automated construction protocols set a reproducible standard for future multimodal corpus generation.
Action100M enables broad avenues in embodied AI—from real-world assistive agents and robotics (vision-language-action models) to world model pretraining for planning and anticipatory reasoning. The semantic resampling framework facilitates scalable handling of long-tailed distributions, and the Tree-of-Captions structure fosters multi-scale structural understanding in video representations. Prospective directions include integrating Action100M in continual learning, action-conditioned world models, simulation fidelity benchmarks, and cross-modal reasoning tasks demanding fine temporal grounding and procedural compositionality.
Conclusion
Action100M constitutes a large-scale, fully automated video action dataset with open-vocabulary supervision and hierarchical temporal structure, facilitating robust training and evaluation of next-generation video understanding architectures. It establishes new baselines for zero-shot action recognition, dense video retrieval, and compositional generalization. The protocol’s efficacy—in annotation, resampling, and scalable transfer—provides a foundation for action-centric AI with implications for embodied reasoning, physical world modeling, and procedural planning (2601.10592).