Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
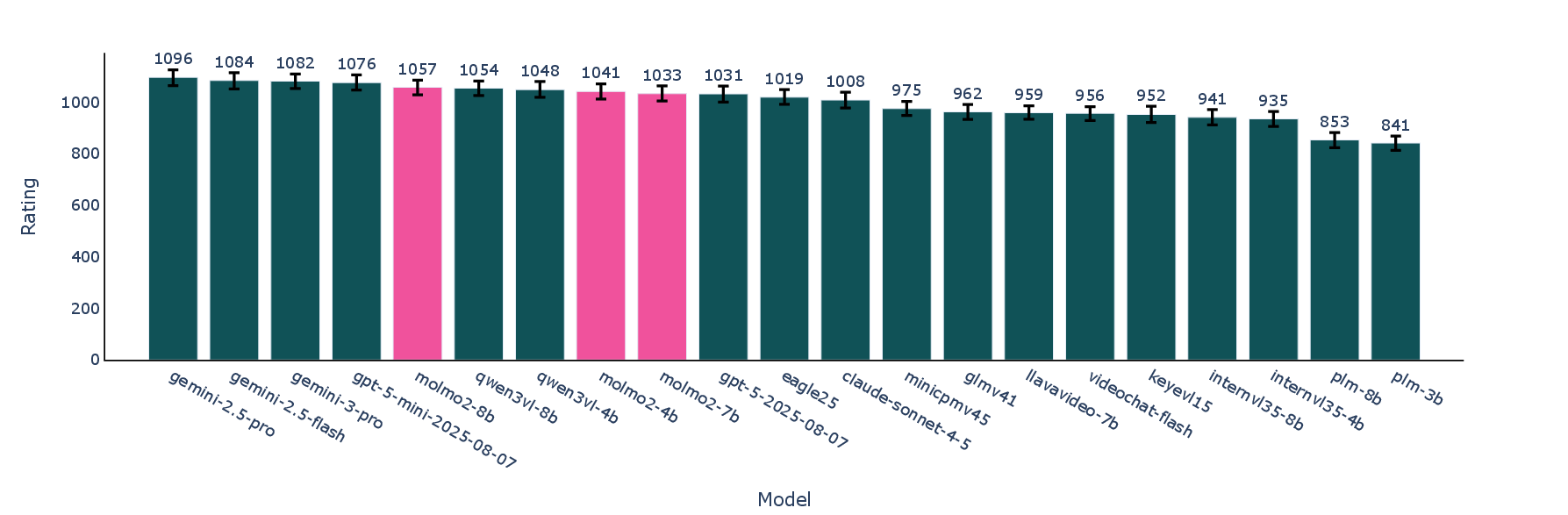
Abstract: Today's strongest video-LLMs (VLMs) remain proprietary. The strongest open-weight models either rely on synthetic data from proprietary VLMs, effectively distilling from them, or do not disclose their training data or recipe. As a result, the open-source community lacks the foundations needed to improve on the state-of-the-art video (and image) LLMs. Crucially, many downstream applications require more than just high-level video understanding; they require grounding -- either by pointing or by tracking in pixels. Even proprietary models lack this capability. We present Molmo2, a new family of VLMs that are state-of-the-art among open-source models and demonstrate exceptional new capabilities in point-driven grounding in single image, multi-image, and video tasks. Our key contribution is a collection of 7 new video datasets and 2 multi-image datasets, including a dataset of highly detailed video captions for pre-training, a free-form video Q&A dataset for fine-tuning, a new object tracking dataset with complex queries, and an innovative new video pointing dataset, all collected without the use of closed VLMs. We also present a training recipe for this data utilizing an efficient packing and message-tree encoding scheme, and show bi-directional attention on vision tokens and a novel token-weight strategy improves performance. Our best-in-class 8B model outperforms others in the class of open weight and data models on short videos, counting, and captioning, and is competitive on long-videos. On video-grounding Molmo2 significantly outperforms existing open-weight models like Qwen3-VL (35.5 vs 29.6 accuracy on video counting) and surpasses proprietary models like Gemini 3 Pro on some tasks (38.4 vs 20.0 F1 on video pointing and 56.2 vs 41.1 J&F on video tracking).


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Molmo2: An open AI that understands videos, can point to things, and explain where it looked
1) What is this paper about?
This paper introduces Molmo2, a new kind of AI that can watch videos (and look at images), answer questions about them, and even show exactly where and when things happen by placing points or following objects over time. Unlike many powerful AIs, Molmo2 is fully open: the model, the training data, and the code are all shared so anyone can learn from and improve it.
2) What were the researchers trying to do?
The team wanted to solve three main problems:
- Build a strong video-and-LLM that’s open, not locked behind company walls.
- Give the model “grounding” skills—so it doesn’t just say “the cat jumps,” it can click on the cat at the exact moment it jumps and track it across frames.
- Create and share high-quality training data (especially for videos) without copying from closed, proprietary systems.
3) How did they do it?
Think of Molmo2 as a smart teammate with two main parts: one that “sees” pictures and video frames, and one that “reads and writes” text. The “seeing” part is a vision transformer (a neural network tuned for images), and the “reading/writing” part is a LLM. A small “connector” helps them talk to each other.
To make Molmo2 good at its job, the team built both new data and new training tricks.
- Main ingredients:
- New open datasets for videos and multi-image tasks (no copying from closed models).
- A training recipe in three stages that teaches the model to caption, answer questions, and ground (point/track) things.
- Efficiency tricks so the model learns faster and handles long videos.
Here are the key ideas explained in everyday language:
- Vision-LLM (VLM): An AI that looks at visuals (images or videos) and understands or describes them with words.
- Grounding: Showing proof in the pixels. If you ask “When does the dog start running?”, the model doesn’t just answer—it also clicks on the dog at the exact time it starts running, or draws a path following it.
- Pointing and tracking: Pointing is like placing a sticker on the right spot in a frame; tracking is like keeping that sticker on the moving object across the video.
- Tokens and attention: The model breaks text and images into tiny pieces called “tokens.” Attention is like a spotlight that helps the model focus on the most important pieces at the right time.
- Bi-directional attention on vision tokens: The model lets different video frames “talk” to each other, which helps it understand how things change over time.
- Sequence packing and message trees: Imagine packing a suitcase efficiently so there’s no wasted space; that’s sequence packing—fitting many examples into one training batch. Message trees organize multiple questions or labels about the same video into neat “branches,” so the model can learn from many annotations without mixing them up.
- Token weighting: If you train too much on super-long answers (like very long captions), they can drown out short answers (like A, B, C, or a number). Token weighting keeps things balanced, so the model learns both.
About the data:
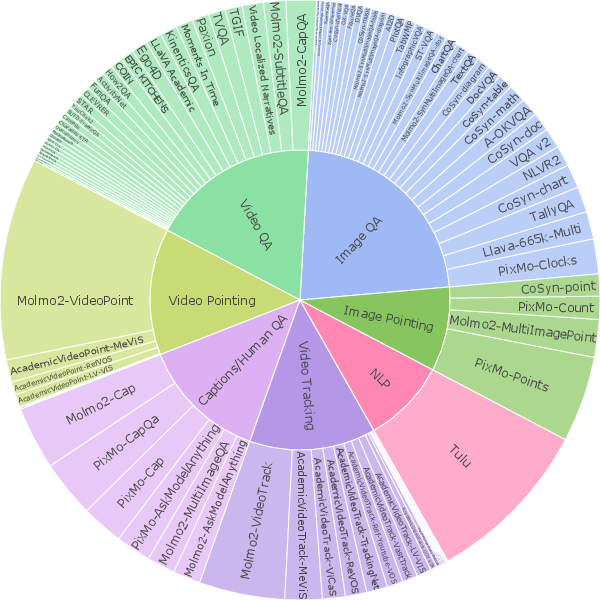
- The team created nine new datasets focused on skills that most open models lack:
- Very detailed video captions (people first spoke descriptions, then they were cleaned up).
- Long-form question answering for videos and sets of images.
- Video pointing (click the right spot at the right time) and video tracking (follow an object continuously).
- Multi-image pointing and multi-image QA (because real questions often refer to multiple pictures, like comparing photos or pages).
- Importantly, they didn’t use closed models to generate the training data. This keeps everything fully open and reproducible.
Training in three steps:
- Pre-train on images (captioning and pointing) to build basic vision-language skills.
- Fine-tune on a big mix of images, videos, and multi-image data to teach QA, counting, pointing, and tracking.
- A short “long-context” stage so it handles longer videos and more frames.
4) What did they find, and why is it important?
- Strong open performance: The largest Molmo2 model (8B) matches or beats other open models on many short-video understanding tasks, and it does especially well at counting, captioning, and grounding (pointing and tracking).
- New grounding superpowers: Molmo2 can:
- Count events by putting points on each occurrence.
- Click the exact moment and place when something happens (like “the cup falls”).
- Track objects across time, even with complex, natural-language queries.
- Even against big commercial systems, Molmo2 holds its own on some grounding tasks. That’s a big deal because showing where an answer comes from makes the model’s responses more trustworthy and useful.
Why this matters:
- Many real-world uses (robotics, sports highlights, video search, assistive tools) need precise “where/when” answers, not just words. Molmo2 brings that precision into an open model.
- By sharing the model, data, and training recipe, the research community can build better systems faster—and test them fairly.
5) What could this change in the future?
- Better, more reliable video tools: Apps could let you ask “How many times does the player touch the ball?” and see each moment highlighted. Teachers, coaches, editors, and safety monitors could all benefit.
- More transparent AI: Grounded answers reduce guesswork. You can see the proof in the video frames.
- Faster open research: Because everything is open, researchers and developers can improve the model, create new benchmarks, and adapt it to new tasks (like home robotics, accessibility tools, or long-video understanding).
In short, Molmo2 shows that open, community-driven video AI can be powerful, trustworthy, and practical—especially when it can point to exactly what it’s talking about.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps and unresolved questions that future work could address.
- Open-data provenance and influence: Several data pipelines rely on Whisper-1 (ASR) and closed LLMs (e.g., Claude Sonnet 4.5) for drafting, refining, and filtering QA/captions. How much do these proprietary systems bias the dataset content and model behavior, and can equivalent fully open-source replacements be validated without quality loss?
- Long-video training scarcity: The paper explicitly cites a lack of open training data for videos longer than 10 minutes as a performance bottleneck. How can the community construct and release large-scale, diverse, fully open long-duration datasets with robust licensing?
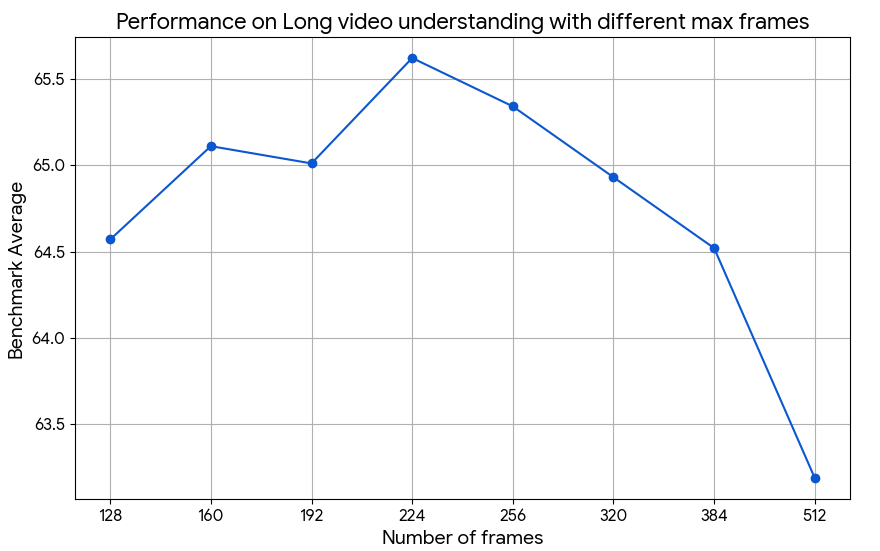
- Ultra-long context training recipe: Long-context SFT is limited to 2k steps due to compute overhead. What training schedules, curriculum strategies, memory-efficient attention variants, or model compressions best improve performance on hour-long videos without prohibitive compute?
- Temporal sampling assumptions: The model samples video frames at 2 fps (F=128 or 384) and always includes the last frame. How sensitive are grounding and QA performance to fps choices, adaptive sampling, and scene-change detection, especially for fast actions or brief events?
- Grounding granularity: Molmo2 emits spatio-temporal points and tracking IDs, not pixel-level masks or boxes. Can the model natively produce segmentation or bounding boxes with consistent IDs across frames, and what training signals are required to bridge from point outputs to dense, instance-level tracking?
- Grounded chain-of-thought evaluation: The paper claims “grounded chain-of-thoughts,” but provides no formal methodology or metric to validate spatial-temporal fidelity of reasoning. How should grounded CoT be represented, constrained, and evaluated to prevent hallucinations and ensure traceable, verifiable steps?
- LLM-as-a-judge metrics: Caption evaluation uses an LLM judge for precision/recall/F1 of statements. What is the robustness of these scores to the choice of judge, prompting, and adversarial captions? Can human audits or reference-based factuality checks calibrate or replace LLM-judged scores?
- Counting via pointing vs textual outputs: The dataset design removes counting questions from QA to push the model toward pointing. How well does Molmo2 handle scenarios where users need both grounded evidence and a numeric answer (e.g., text + points), and how should mixed-output formats be evaluated?
- Synthetic QA difficulty and bias: Large-scale QA is generated from captions and transcripts produced by an in-house captioner. Does this pipeline overfit to caption-derived facts and miss visual reasoning not present in captions (e.g., implicit causality, occlusions), and how can adversarial or counterfactual QA be added?
- Multi-image set construction validity: Image sets are formed by clustering caption similarities and canonicalizing labels. How often does clustering join semantically mismatched images, and does label canonicalization suppress useful lexical diversity or introduce semantic drift?
- Robustness to occlusion, blur, camera motion: Tracking benchmarks are reported, but systematic stress-tests (heavy occlusion, abrupt motion, lighting changes, clutter) are not analyzed. What failure modes dominate in grounding/tracking, and which data or architectural changes are most effective?
- Audio integration: Subtitles are included when available, but raw audio features are not modeled. Can audio-event grounding (e.g., linking sounds to visual events) and audio-driven temporal cues improve temporal localization and QA, especially when transcripts are noisy or unavailable?
- Multilingual capability: Training filters removed non-English content; performance on multilingual videos, cross-lingual QA, and non-Latin scripts is unexplored. What data and tokenization strategies would enable robust multilingual video-language grounding?
- Safety and privacy: The paper does not discuss content safety, privacy risks, or personally identifiable information in video. What procedures and datasets are needed to evaluate and mitigate misuse, sensitive content identification, and privacy-preserving grounded outputs?
- Real-time and streaming use: The system processes pre-batched frames; low-latency streaming inference for robotics/assistive scenarios is untested. What architectural and scheduling changes enable incremental, online grounding and temporal pointing under tight latency constraints?
- Confidence calibration and interactive correction: There is no mechanism for uncertainty estimates on points/tracks or interactive corrections. How can the model expose confidence, support user-in-the-loop adjustments, and adapt its grounding based on feedback?
- 3D and geometric grounding: The approach extends 2D pointing to time but does not address 3D (depth/pose). Can the model incorporate geometric priors or multi-view cues to ground in 3D, and how should 3D-aware datasets and metrics be constructed?
- Training mixture and token-weighting heuristics: Token weighting uses fixed or heuristic formulas (e.g., 0.1 for video captions; 4/√n). Are there principled, learnable weighting schemes or multi-task optimizers that outperform these heuristics and reduce interference across tasks?
- Bi-directional visual-token attention: The paper reports gains from allowing visual tokens to forward-attend to one another but does not detail ablations or conditions (e.g., cross-frame vs intra-frame). What attention mask designs maximize temporal reasoning while minimizing leakage and compute?
- Packing and message-tree generality: The custom packing and message-tree encoding show large throughput improvements but are tailored to this setup. How portable are these techniques to other VLM connectors, different ViTs, or sparse attention LLMs, and what are their impacts on gradient mixing and stability?
- Grounding coverage and vocabulary: Video pointing emphasizes everyday objects and complex referring expressions, but tail categories and domain-specific entities may be underrepresented. What sampling/reweighting strategies best improve coverage without harming core performance?
- Licensing and reproducibility: Training aggregates multiple sources (e.g., YouTube-derived datasets, academic tracks). Are all training data licenses compatible with redistribution and commercial use, and is there a precise, reproducible data preprocessing manifest (including filters and frame sampling) for third parties?
- Benchmark standardization: The paper notes that eval details (prompting, frames) vary and are sometimes unavailable across models. Can an open, standardized evaluation protocol (frame budgets, prompts, decoding settings) be established to ensure fair, replicable comparisons for video grounding and QA?
- Conversion from tracking to pointing: Academic video pointing is generated by sampling points from object masks; this may not match human click behavior (e.g., salient parts vs mask centers). How should point sampling strategies be designed to better reflect human grounding preferences?
- Upper bound on dense grounding: Training includes examples with up to 60 points, but tasks can require far denser annotations (e.g., crowded scenes). What are the practical limits for point density and ID association, and how do memory/latency constraints scale?
- Cross-task generalization: The mix includes captioning, QA, pointing, tracking, and NLP SFT. Which tasks transfer best to which others, and how can the curriculum be optimized to maximize generalization (e.g., does tracking pretraining improve temporal QA more than captioning does)?
- Downstream retrieval/search: The paper targets QA, captioning, counting, and grounding; video retrieval and temporal moment localization for search are not addressed. Can Molmo2 be adapted or jointly trained for retrieval tasks and evaluated on standardized retrieval benchmarks?
- Domain adaptation: Performance in specialized domains (medical, industrial inspection, surveillance) is unexplored. What data and fine-tuning protocols enable safe, high-precision grounding in domain-specific contexts with strict operational requirements?
- Decoding effects: Most inference uses greedy decoding (except preference/captioning). How do decoding parameters (temperature, nucleus sampling, repetition penalties) affect factuality, hallucinations, and grounding precision, and can constrained decoding improve grounded outputs?
Glossary
- All-gather: A collective communication operation that shares tensors across devices; used within parallel attention to synchronize context. "We employ Ulysses attention for the LLM context parallelism as its all-gather offers flexibility with the custom attention masks used by our packing and message tree system"
- Attentional pooling: Using attention to pool patch features into fewer tokens, reducing memory/computation. "and the attentional pooling after that across each context parallel group"
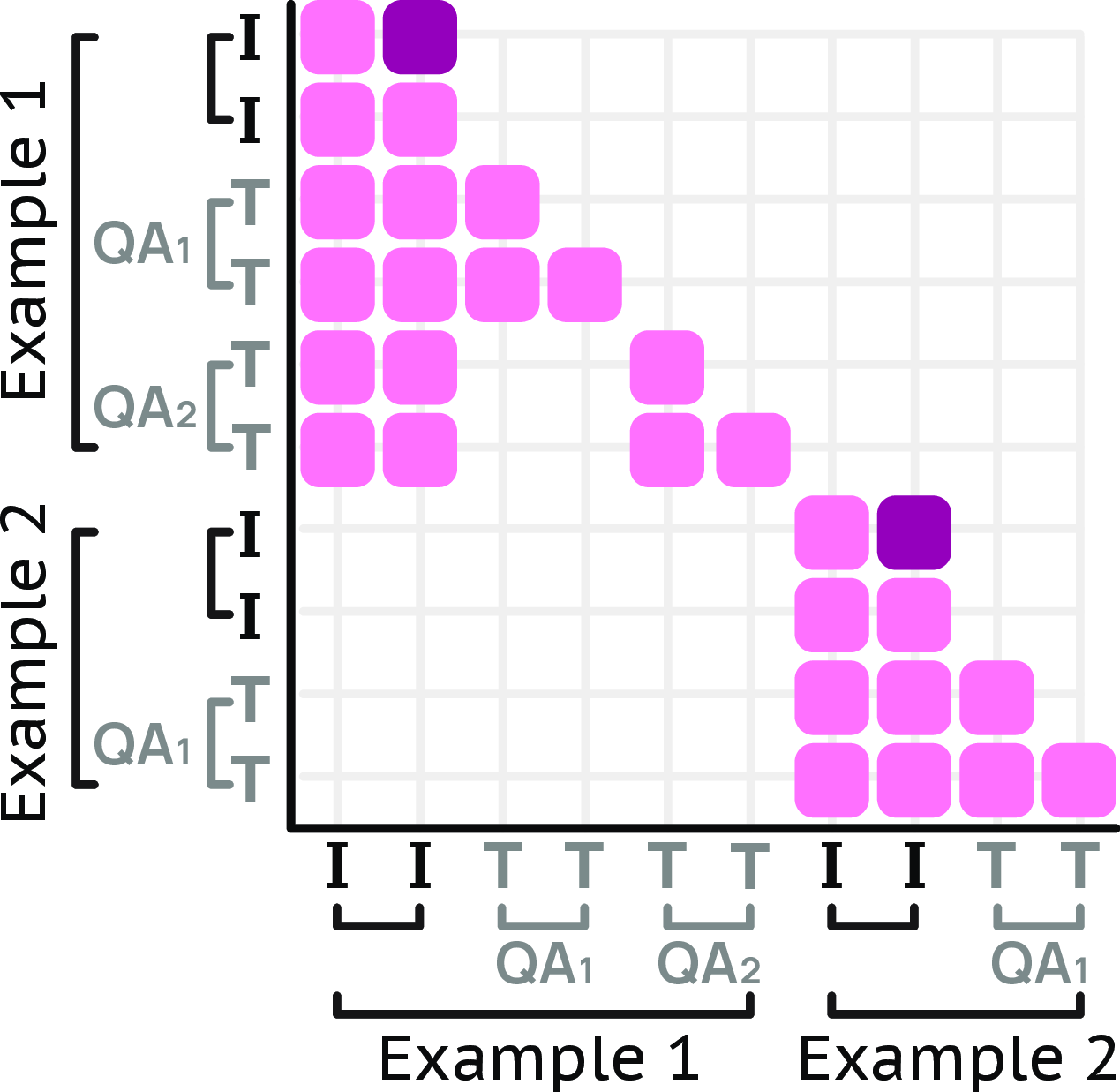
- Attention mask: A mask controlling which tokens can attend to which others in a transformer. "Attention mask for a packed sequence with two examples."
- Bi-directional attention: Allowing tokens to attend both forward and backward within a set (e.g., visual tokens). "We also show that enabling bi-directional attention between visual tokens yields notable gains."
- Bounding box: A rectangle that approximates an object’s extent in an image/video. "segmentation or bounding box object tracks"
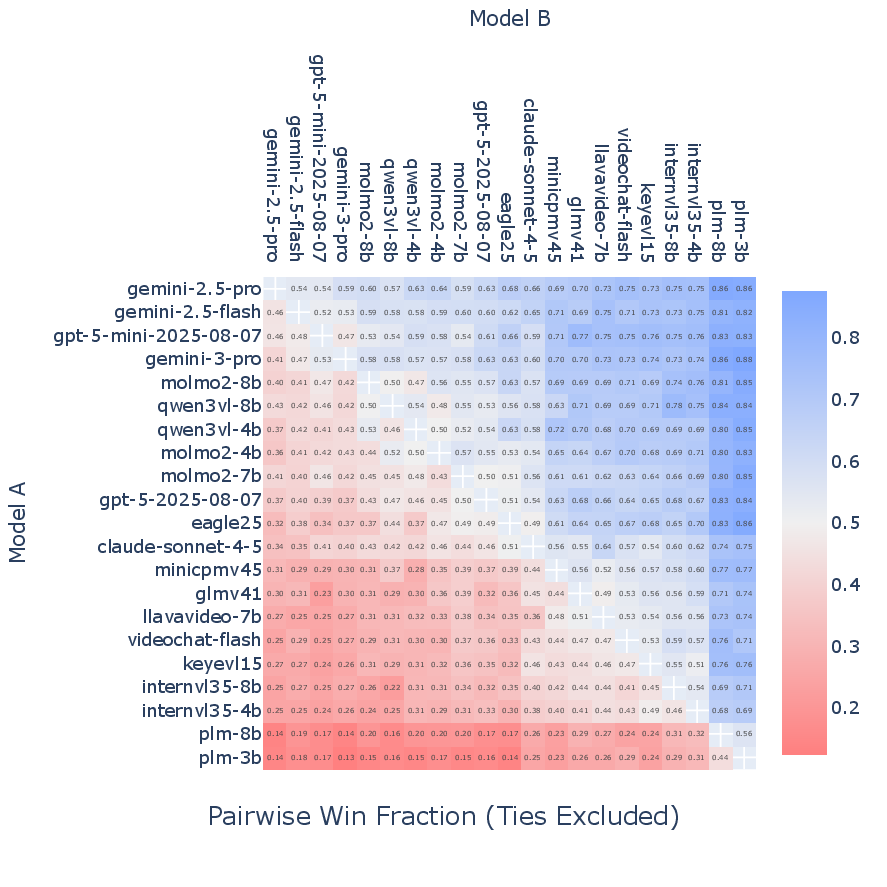
- Bradley-Terry model: A probabilistic model for pairwise comparisons used to convert preferences into rankings. "we calculate an Elo ranking using the Bradley-Terry model"
- Column tokens: Special tokens encoding image aspect ratio/layout for multi-crop processing. "For multi-crop images, we include column tokens to indicate the image's aspect ratio."
- Connector module: The interface projecting vision features into the LLM token space. "Our model architecture follows the common design of combining a pre-trained LLM and a vision transformer (ViT) via a connector module."
- Context parallelism (CP): Splitting long contexts across multiple GPUs for memory-efficient training/inference. "use context parallelism (CP) on the LLM so each example is processed by a group of 8 GPUs."
- Dense video captioning: Generating long, detailed descriptions covering many events and visual details in a video. "including nine new datasets for dense video captioning"
- Distillation: Training a model using outputs of a stronger teacher model to transfer knowledge. "either rely on synthetic data from proprietary VLMs, effectively distilling from them"
- Elo ranking: A rating system converting pairwise wins/losses into scores. "we calculate an Elo ranking using the Bradley-Terry model"
- Forward attention: Attention restricted to later tokens/frames to respect temporal order. "Frame tokens (\textcolor{darkpink}{dark pink}) have forward attention,"
- Grounded chain-of-thoughts: Step-by-step reasoning linked to specific locations/times (e.g., points/tracks). "grounded chain-of-thoughts that localize objects and events over time."
- Grounding: Linking language outputs to precise pixels/locations or timestamps in visual data. "A key missing capability in current video–LLMs is grounding."
- HOTA: Higher Order Tracking Accuracy metric that evaluates detection and association quality in tracking. "HOTA is the tracking accuracy that accounts for association accuracy for models that provide tracking IDs."
- J&F: A combined region/boundary segmentation metric (Jaccard + F-measure) used in video object segmentation. "56.2 vs 41.1 on video tracking"
- LLM: LLM used to process text and interleaved visual tokens. "The LLM takes as input the visual tokens interleaved with text timestamps (for videos) or image indices (for multi-image input)."
- Long-context training: Training with extended sequence lengths to handle long videos/inputs. "We only do long-context training as a short final training stage since its adds significant overhead to the training."
- Message trees: Encoding a visual input with multiple annotation branches, linearized with custom attention. "We encode videos and images with multiple annotations as message-trees."
- Multi-headed attention: Attention mechanism with multiple heads to capture diverse relations. "using a multi-headed attention layer, where the mean of the patches serves as the query."
- Multimodal: Involving multiple data modalities (e.g., vision and language). "video-centric multimodal corpus to date"
- Open-vocabulary: Handling arbitrary, user-provided labels/phrases beyond fixed class sets. "two open-vocabulary video pointing and tracking datasets"
- Patch-level features: Features computed on fixed-size image patches for transformer encoding. "which are encoded into patch-level features by the ViT."
- Ref-VOS: Referring Video Object Segmentation, where natural-language queries specify which objects to segment/track. "Our dataset collection follows Ref-VOS by asking users to re-label existing tracking annotations."
- Segmentation masks: Pixel-wise regions delineating objects. "by using SAM-2 to generate segmentation masks and corresponding point tasks."
- Sequence packing: Combining multiple short examples into one long sequence to reduce padding waste. "sequence packing and a message-tree encoding scheme"
- Spatio-temporal points: Points that specify both spatial coordinates and time within a video. "spatio-temporal points, object tracks, and grounded chain-of-thoughts"
- Supervised fine-tuning (SFT): Further training on labeled data to adapt/prefer specific tasks. "a joint video/image supervised fine-tuning (SFT) stage"
- Token weighting: Adjusting per-example loss weight based on output length to balance training. "a novel token-weighting scheme during fine-tuning to balance learning from diverse tasks"
- Ulysses attention: An attention implementation enabling efficient context parallelism via all-gather. "We employ Ulysses attention for the LLM context parallelism as its all-gather offers flexibility"
- Vision Transformer (ViT): A transformer-based visual encoder operating on image patches. "vision transformer (ViT)"
- Vision-LLM (VLM): A model that jointly processes visual inputs and language. "video-LLMs (VLMs) remain proprietary."
- Visual tokens: Tokenized representations of pooled visual features for the LLM. "passed as visual tokens, along with any text inputs, to the LLM."
Practical Applications
Immediate Applications
Below are specific, deployable use cases enabled by Molmo2’s open models, data, and training recipes. Each item notes target sectors, potential tools/workflows, and key assumptions/dependencies.
- Actionable video search and indexing with dense captions
- Sectors: media/entertainment, education, enterprise knowledge management, accessibility
- How: Batch-caption videos using Molmo2 (4B/8B) to generate long, detailed, searchable metadata; store as text embeddings in a vector DB; enable semantic search and highlight reels
- Dependencies/assumptions: Offline/batch processing acceptable; 2 fps sampling and frame limits (≤384) fit content length; open-weight model runs on workstation or modest cloud GPU; quality suitable for non-safety-critical workflows
- Grounded counting and event localization (point-in-time/space)
- Sectors: retail analytics (footfall), manufacturing QA (defect counts), sports analytics, security/traffic monitoring
- How: Use Molmo2-VideoPoint to answer “how many” by emitting clicks over frames with timestamps; integrate into dashboards that auto-generate clip lists and thumbnails at precise moments
- Dependencies/assumptions: Counting framed as pointing works for open-vocabulary objects/actions at 2 fps; tolerance for occasional misses; privacy/compliance processes in place for surveillance contexts
- Object tracking for review and triage
- Sectors: logistics/warehousing (package flow), insurance (incident review), media post-production (B-roll tracking), animal/wildlife monitoring
- How: Use Molmo2-VideoTrack to generate time-stamped tracks with IDs; export tracks to standard formats; optional handoff to SAM-2/3 for segmentation if needed
- Dependencies/assumptions: Point-based tracks sufficient; pairing with a segmentation model is needed for masks; acceptable to process short-to-medium videos offline
- Semi-automatic video annotation and pre-labeling
- Sectors: data labeling providers, CV teams across industries (autonomy, robotics, retail)
- How: Integrate Molmo2 as a plug-in for CVAT/Label Studio to pre-populate points/tracks; human-in-the-loop correction to cut labeling time
- Dependencies/assumptions: Annotation UIs accept point/track import; QA processes handle occasional drift/occlusion errors
- Multi-image reasoning for cataloging and documentation
- Sectors: e-commerce, document intelligence, MRO/field service
- How: Use multi-image QA and pointing to answer cross-image questions (e.g., compare product variants, find part location across schematics/photos)
- Dependencies/assumptions: Image sets 2–5 work best; may require domain-specific prompt templates for charts/tables/docs
- Accessibility: richer audio descriptions and grounded guidance
- Sectors: accessibility tech, media platforms, public institutions
- How: Generate dense video captions and grounded references (“the player in the red shirt at 01:22”) to power descriptive audio and navigable summaries
- Dependencies/assumptions: Non-medical, non-safety-critical usage; content licensing allows transcription/captioning
- Education: lesson and lab video summarization with grounded references
- Sectors: EdTech, corporate training
- How: Produce long-form summaries, time-stamped concept highlights, and multi-image question sets for practice; align with transcripts if available
- Dependencies/assumptions: Accuracy acceptable for study aids; instructional design reviews; transcript availability improves results
- Video content moderation triage with explainability
- Sectors: trust & safety, platform moderation, policy compliance
- How: Use pointing/tracking outputs to localize suspected violations (e.g., dangerous acts, restricted symbols) for reviewer triage
- Dependencies/assumptions: Not a final decision system; policy taxonomies and human reviewers required; privacy and legal guardrails
- Sports analytics for coaching and highlight extraction
- Sectors: sports tech, media
- How: Count and localize events (goals, shots), track players/ball; auto-generate clips from grounded chains-of-thought
- Dependencies/assumptions: Domain prompts/templates per sport; 2 fps sampling suffices for many tasks, but very fast play may need higher fps or pairing with trackers
- Robotics data curation and evaluation
- Sectors: robotics (household/industrial)
- How: Use video grounding to label grasps, failures, and object state changes for offline analysis and dataset creation
- Dependencies/assumptions: Offline analytics only; not used in-the-loop for real-time control; domain drift addressed via fine-tuning if needed
- Open, reproducible research baselines and training efficiencies
- Sectors: academia, ML tools/software
- How: Reuse open datasets, message-tree packing (15× throughput), token-weighting, and bi-directional vision-token attention to train/evaluate multimodal models
- Dependencies/assumptions: Access to moderate compute; adherence to data licenses; ability to integrate Ulysses attention and context parallelism for long sequences
- Synthetic multimodal dataset generation
- Sectors: ML research, vertical AI teams
- How: Use Molmo2 captioning + LLM prompting pipelines (CapQA/SubtitleQA-style) to create domain-specific QA for medium-length videos
- Dependencies/assumptions: Quality control on synthetic data; minimize compounding label noise; ensure no leakage of proprietary content
Long-Term Applications
These use cases require additional research, scaling, or engineering for robustness, latency, or compliance.
- Real-time, on-device AR video assistants with grounded interaction
- Sectors: AR/VR, assistive tech, field service
- How: Live pointing/tracking overlays (“tap the loose connector”; “follow the third bolt pattern”)
- Dependencies/assumptions: Efficient ViTs, higher-fps pipelines, hardware acceleration; energy/thermal constraints; robust occlusion handling
- Interactive robotics with grounded dialogs (“point-ask-act” loops)
- Sectors: robotics (home, warehouse, manufacturing)
- How: Natural language commands tied to on-frame points/tracks; grounded chain-of-thought for safe manipulation
- Dependencies/assumptions: Closed-loop latency, safety assurance, failure recovery; domain adaptation; integration with perception and control stacks
- Clinical/OR video assistance and compliance logging
- Sectors: healthcare
- How: Tool usage counting, step verification, time-stamped procedure highlights for audit/training
- Dependencies/assumptions: Rigorous clinical validation, privacy/security (HIPAA, GDPR), data governance; not for diagnostic use without regulatory clearance
- City-scale traffic analytics with explainability
- Sectors: smart cities, transportation
- How: Counting/locating events (near misses, lane violations) across distributed cameras with auditable groundings
- Dependencies/assumptions: Long-video robustness, higher fps and low-light handling, privacy-preserving analytics, policy frameworks for surveillance data
- End-to-end video editing via grounded instructions
- Sectors: media creation, marketing
- How: “Remove the red bottle wherever it appears”; “highlight every dunk”; transform point/track outputs into edit lists
- Dependencies/assumptions: Stable tracking over long sequences; integration with NLEs; coupling with segmentation/rotoscoping models
- Autonomous driving event mining and post hoc forensics
- Sectors: automotive
- How: Localize and count edge-case scenarios, generate grounded narratives for incident analysis
- Dependencies/assumptions: Ultra-long-context handling (10+ minutes), multi-camera streams, synchronized sensors; high reliability
- Industrial inspection at scale (energy, utilities, infrastructure)
- Sectors: energy, utilities, construction
- How: Track defects/anomalies over time (corrosion, leaks) in drone/robot video; produce time-stamped evidence for maintenance systems
- Dependencies/assumptions: Domain fine-tuning; challenging conditions (glare, weather); integration with EAM/CMMS; safety certifications
- Personalized coaching and rehabilitation with temporal grounding
- Sectors: sports/fitness, digital health
- How: Track body parts/tools, count reps/events, provide grounded feedback loops
- Dependencies/assumptions: Pose/biomechanics integration, privacy; consumer-grade cameras with varied lighting; not medical advice without validation
- Compliance and policy auditing with grounded evidence
- Sectors: public sector, enterprise compliance
- How: Open, explainable video analytics with point/track outputs to support audits and procurement standards for AI
- Dependencies/assumptions: Standardized schemas for grounded outputs; governance for bias/privacy; legal frameworks for explainable AI
- Long-form multimodal tutoring and assessments
- Sectors: education
- How: Generate lesson-aligned, grounded Q&A spanning full lectures/labs with multi-image artifacts
- Dependencies/assumptions: Stronger performance on 10–60+ minute content; curriculum alignment; plagiarism safeguards
- Household assistants for home cameras and DIY robotics
- Sectors: consumer IoT
- How: “Find when the dog went outside,” “count package deliveries,” “track the red cube during my robot’s pick-and-place”
- Dependencies/assumptions: Efficient on-edge inference, privacy-preserving home deployments; robust to diverse camera qualities
- General-purpose, open grounded evaluation standards
- Sectors: standards bodies, research consortia
- How: Use Molmo2’s open data/formats to define benchmarks where models must “show where and when” to earn credit
- Dependencies/assumptions: Community consensus on metrics; curated long-video datasets; ongoing maintenance and governance
Cross-cutting Assumptions and Dependencies
- Performance envelope: Current strengths on short-to-medium videos; long-video robustness improving but constrained by open long-video data and compute for ultra-long context training.
- Sampling and latency: Training/inference recipes use ~2 fps and ≤384 frames; real-time or high-speed activities may need higher fps, specialized trackers, or future model variants.
- Grounded outputs: Native outputs are points/tracks; applications needing masks should pair with segmentation models (e.g., SAM-2/3) or downstream post-processing.
- Domain adaptation: For specialized domains (medical, industrial), expect fine-tuning and QA; not for safety-critical decision-making without validation and regulatory approvals.
- Privacy/ethics: Ensure consent, redaction, and policy compliance when processing people-centric or sensitive video; establish data governance early.
- Compute and deployment: 4B/7B/8B models can run on a single modern GPU for batch jobs; real-time, on-device, or multi-camera deployments will require optimization, quantization, and accelerator support.
- Openness: Leveraging Molmo2’s open data/weights enables reproducibility and auditability; adhere to licenses and content-use restrictions when creating derived datasets.
Collections
Sign up for free to add this paper to one or more collections.