- The paper introduces CURVE, a benchmark that employs culturally-authored questions and multi-step reasoning traces to expose and quantify biases in video-language models.
- It demonstrates that multimodal cues, including audio and temporal dynamics, boost model accuracy, yet significant gaps remain compared to human performance.
- The work underscores the need for culturally-aware training and robust diagnostic protocols, paving the way for fairer, more globally relevant VLMs.
CURVE: A Multicultural Benchmark for Long Video Reasoning
Motivation and Benchmark Design
Current video-language evaluation paradigms exhibit a marked Western and English-language bias, with most datasets depicting globally ubiquitous phenomena in predominantly Western contexts, and questions/answers crafted or translated into English or other high-resource languages. This narrow scope induces selection bias in model pretraining and evaluation, which is increasingly problematic as vision-LLMs (VLMs) are deployed worldwide. "CURVE: A Benchmark for Cultural and Multilingual Long Video Reasoning" (2601.10649) directly addresses this deficit by presenting a large-scale, meticulously human-curated benchmark that demands both deep cultural grounding and complex, multi-step reasoning over long-form video data.

Figure 1: CURVE benchmarks multicultural long video reasoning with native-language questions and detailed reasoning traces from culturally diverse locales, exposing failure modes in SOTA VLM responses.
CURVE comprises 540 videos annotated with 2400 open-ended questions. These span 18 locales, covering native content and language for each region. The formulation prohibits automatic translation—instead, all questions, answers, and multi-step reasoning traces are authored by locally-situated experts, maximizing authenticity and language fidelity. Each question is further decomposed into detailed reasoning steps, supporting process-level model diagnostics.
Dataset Properties and Human Annotation Workflow
CURVE targets complexity along multiple axes: (i) cultural (local events, traditional attire, language-specific cues), (ii) temporal (video durations range 1–60+ minutes), (iii) multimodal (requiring integration of audio and visual cues in the native language).
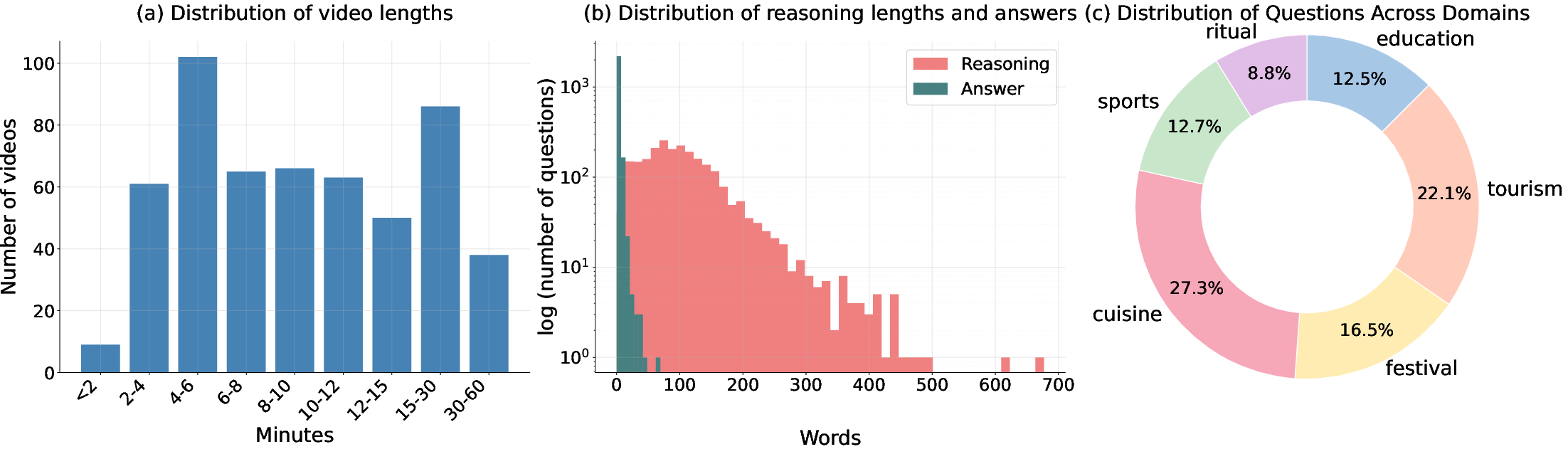
Figure 2: CURVE videos span diverse durations, detailed multi-step reasoning traces (hundreds of words), and six balanced cultural domains.
The human annotation pipeline is multi-phased: initial collection of culture-specific video content, calibration to optimize for LLM-hardness and clarity, iterative curation with independent verification, and multi-layered audits to ensure objective and unambiguous question-answer pairs.

Figure 3: The annotation pipeline emphasizes cultural taxonomy expansion, difficulty calibration, and rigorous multistage audits for high-quality curation.
Evaluation Protocol and Baseline Model Analysis
Performance is assessed using a custom LLM judge (Gemini-2.5-Flash) employing a 0–2 scoring protocol for semantic equivalence, robust to linguistic variation. Human baselines use annotators naïve to ground-truth, using only open-web search for unfamiliar references and strictly forbidden to use LLMs.
Results highlight an unequivocal performance chasm: the best model, Gemini-2.5-Pro, achieves only 45.07% accuracy (weighted average), which is drastically lower than human performance at 95.22%.
Locale-wise breakdowns reveal severe cultural and linguistic disparities. Models underperform in low-resource settings, achieving as low as 28%–31% on ta-IN and te-IN, compared to much higher scores in mainstream locales (e.g., en-GB, ko-KR).
Ablations: Multimodality, Test-Time Compute, and Temporal Complexity
CURVE is designed to stress-test the need for true multimodal reasoning. Ablations indicate that access to audio modalities increases model accuracy by an average of 4.32%, with more substantial improvements in specific locales (up to +8.15%).
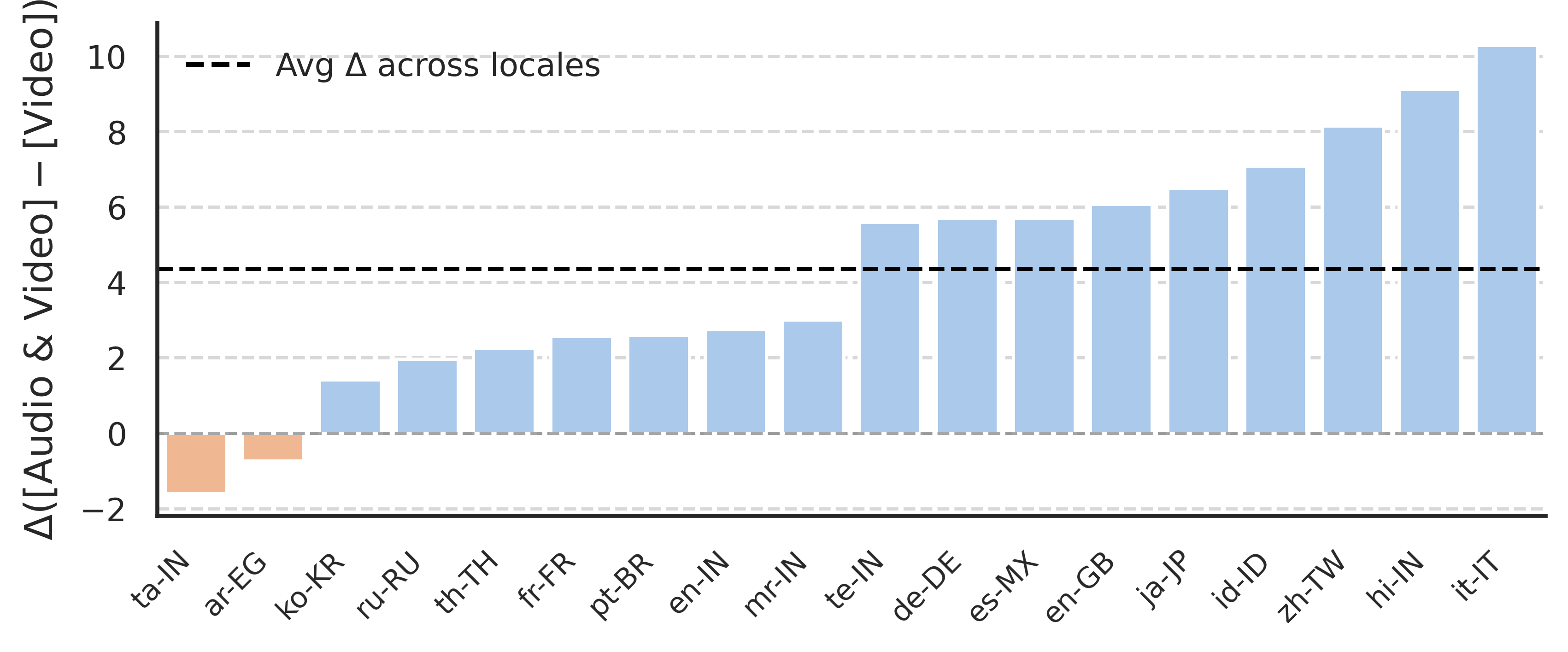
Figure 4: Audio cues provide significant, locale-dependent accuracy gains, confirming the necessity of joint reasoning over linguistic and non-linguistic audio.
Test-time compute budget (output token length) is positively correlated with accuracy, plateauing around 2k output tokens. This suggests that further token budget scaling yields diminishing returns; thus, compute alone does not close the gap to human reasoning.
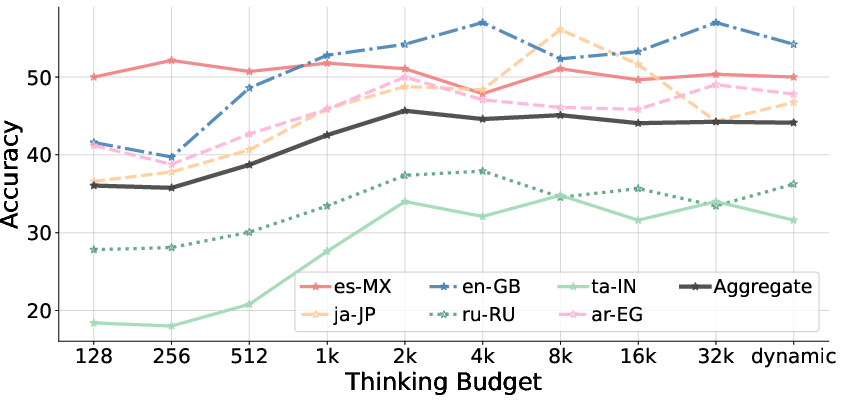
Figure 5: Increasing model output length improves accuracy until saturation, with residual error persistent beyond 2k tokens.
Temporal complexity is validated through systematic frame sampling analysis. Accuracy increases monotonically with additional frames, emphasizing that tasks in CURVE cannot be trivially solved from static images.
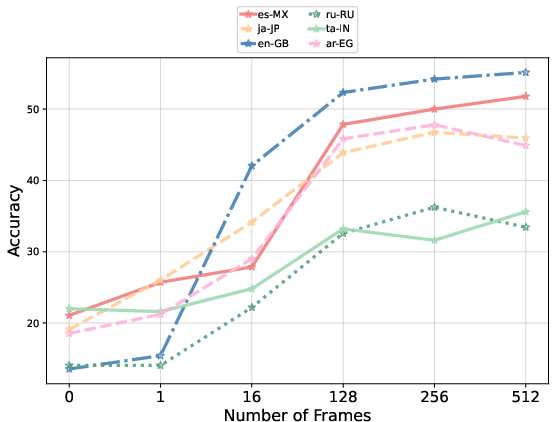
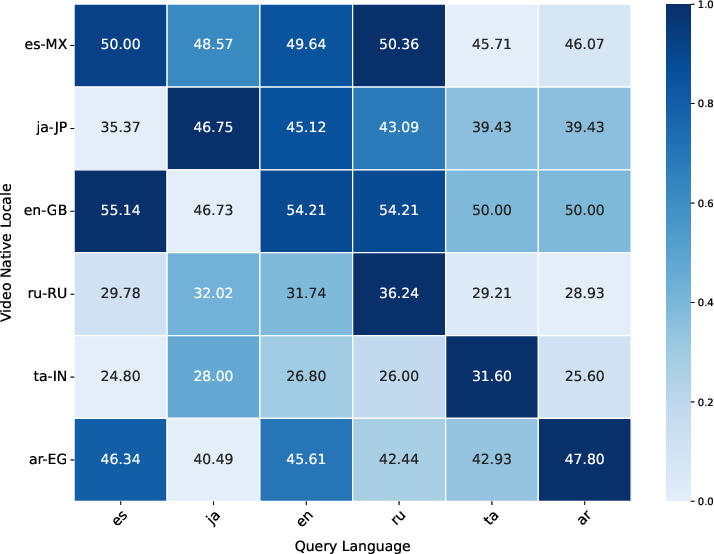
Figure 6: Model accuracy increases with denser temporal sampling, confirming that questions necessitate access to temporal structure within videos.
Process-Level Diagnostics: Evidence Graphs and Error Taxonomy
CURVE introduces a sophisticated evidence graph methodology for fine-grained error analysis. Human reasoning traces are transformed into DAGs where nodes represent atomic evidences (spatio-temporal observations, inferences, or external facts), and edges capture prerequisite dependencies. Model responses are traversed and compared against these graphs through an iterative error isolation protocol.
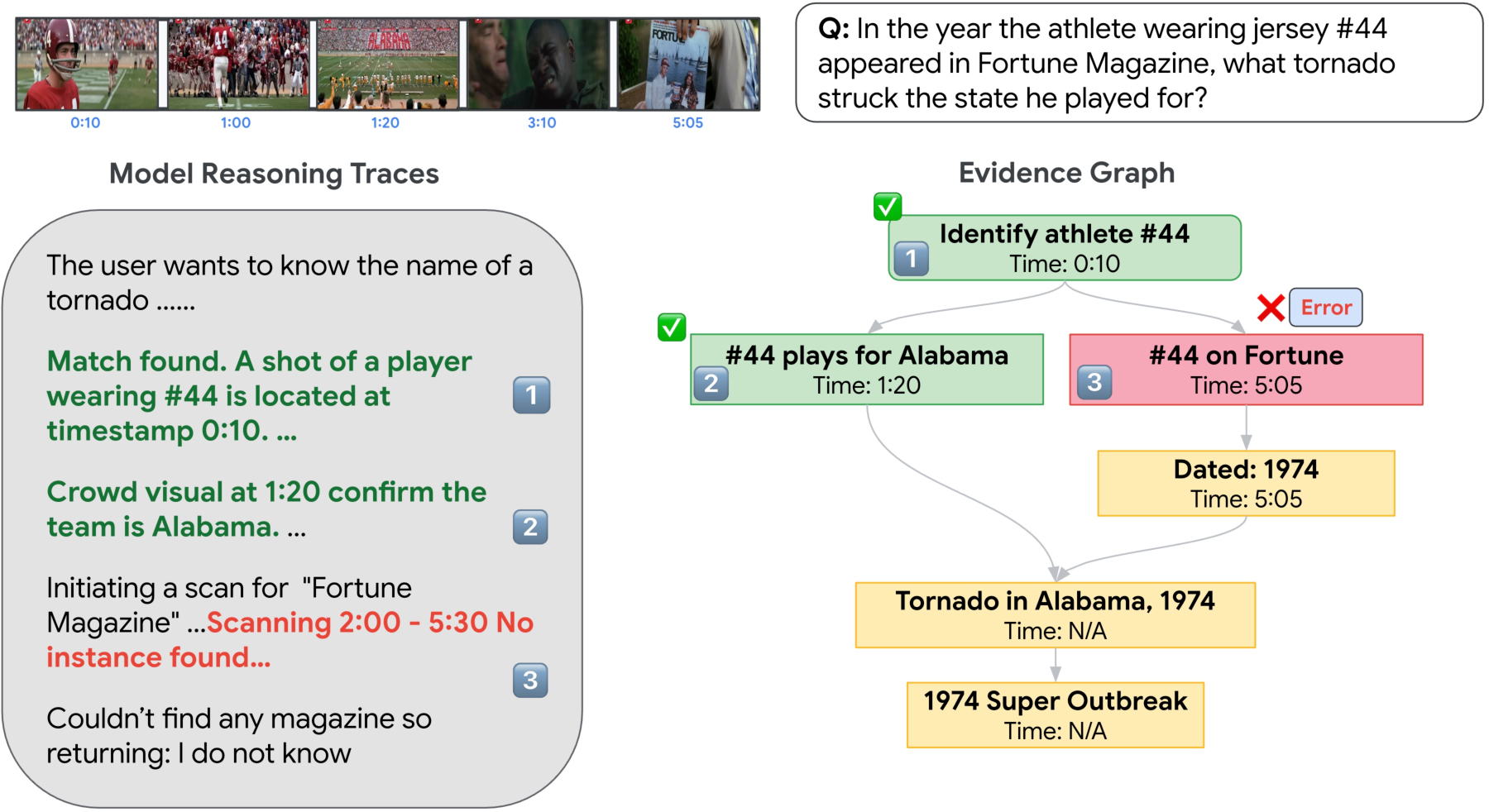
Figure 7: Evidence graphs enable multi-iteration, node-wise error tagging and counterfactual hinting along the reasoning chain.
The analysis reveals perception failures (Temporal Localization, Spatial Grounding, Spurious Object/Event, Attribute Misidentification) constitute ~75% of failures, vastly outnumbering pure logical reasoning or factual knowledge errors. These errors are predominantly cultural in nature, as perception is tightly coupled to locale-specific artifacts, gestures, and events.

Figure 8: Most model failures stem from perceptual errors, especially those intertwined with cultural context.
The error taxonomy is further validated by cross-model comparison and iteration-wise tracking. Multi-pass iterative isolation uncovers additional latent reasoning errors masked by initial perception failures.
Implications and Future Directions
CURVE exposes a substantial deficit in current Video-LLM capabilities, clearly demonstrating model brittleness on data outside canonical, Western-centric distributions. The error analysis framework substantiates that simply increasing model or compute scale is insufficient for global generalization. Instead, models require improved architectural priors and data augmentation pipelines sensitive to long-range temporal context and local cultural phenomena.
Practically, this benchmark will pressure the development of (i) culturally-localized video-language pretraining, (ii) improved temporal modeling primitives, (iii) advanced multimodal fusion to integrate speech, music, and environmental sounds, and (iv) robust evaluation pipelines for process traceability and interpretability.
Theoretically, CURVE advocates for evaluation schemes where model capability is not judged solely on end-point accuracy but on fine-grained, process-based diagnostics. This aligns with recent trends in reasoning trace evaluation and supports deeper inspection of black-box model inner workings.
Conclusion
CURVE establishes a rigorous, scalable, and extensible benchmark for long video reasoning in multicultural settings, with comprehensive human-centric curation and process-level evaluation. The findings expose the magnitude of cultural bias and perceptual brittleness in state-of-the-art Video-LLMs, setting a new bar for both data and evaluation rigor in the field. Future research must focus on reducing the gap between human and machine understanding in culturally and linguistically diverse scenarios, leveraging CURVE's structure as a foundation for both diagnostic model development and fair global evaluation.