- The paper introduces a unified autoregressive transformer that integrates TTS, ASR, and VC into a shared discrete token space.
- It adopts a dual-tokenizer design and joint multitask training to enhance cross-task synergy and streamline deployment.
- Empirical results demonstrate competitive accuracy and low latency, making the framework viable for real-time, scalable speech applications.
Motivation and Background
Conventional speech processing systems maintain disparate model architectures for text-to-speech (TTS), automatic speech recognition (ASR), and voice conversion (VC). This fragmentation results in duplicated modeling efforts, increased system complexity, and limited capacity for cross-task generalization and deployment efficiency. Although recent advances in LLMs and autoregressive models have demonstrated empirical success across individual tasks, few efforts attempt a truly unified pipeline where these diverse tasks are treated as instances of a common generative sequence modeling problem.
GPA introduces a comprehensive, instruction-driven framework that places all core speech tasks—including TTS, ASR, and VC—within a shared discrete token space, processed through a single large-scale autoregressive LLM backbone. The central hypothesis is that unification over a discrete semantic–acoustic tokenization, in concert with fully joint multitask training, provides cross-task synergy, architectural efficiency, and deployment scalability, without compromising practical performance.
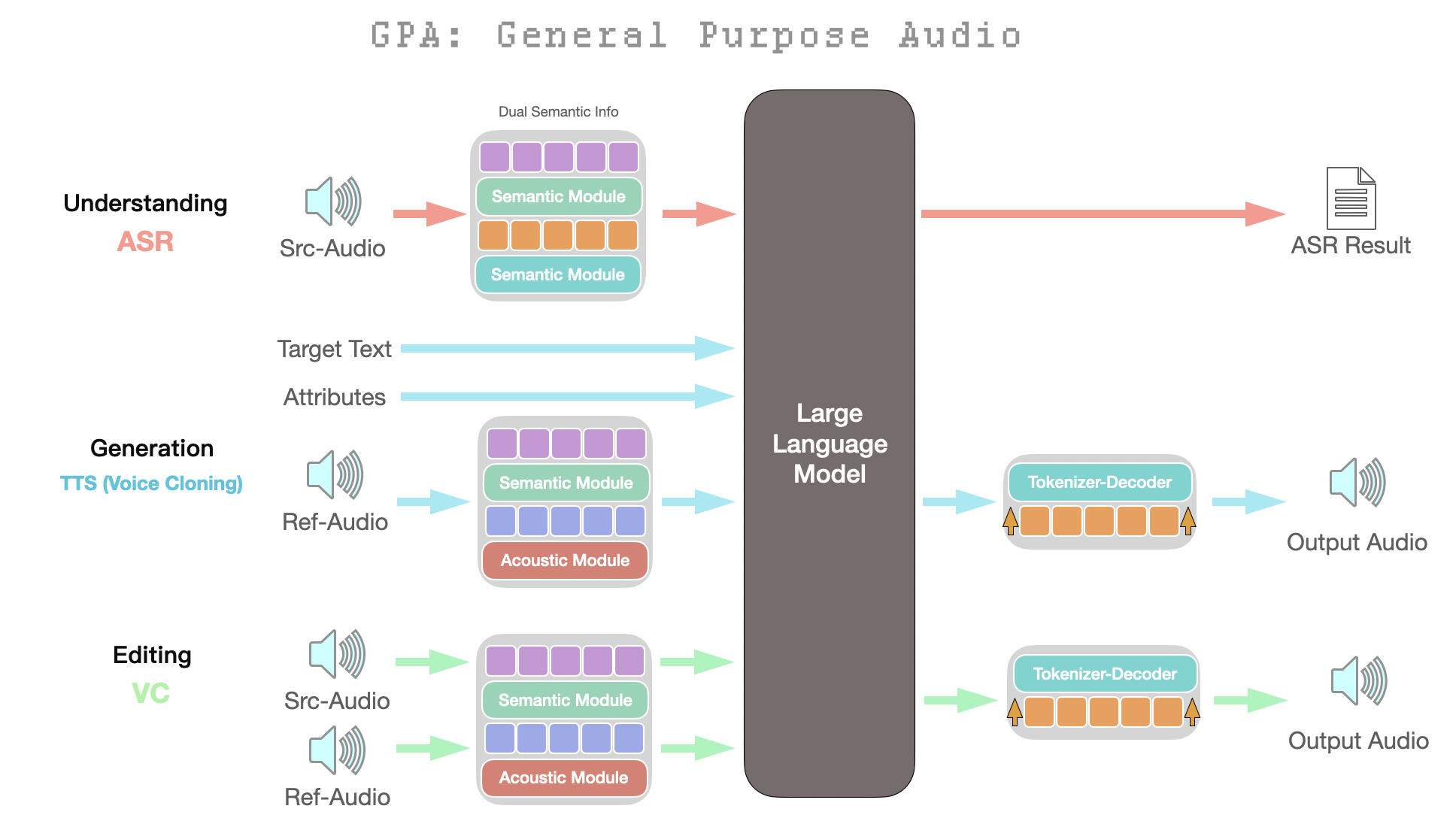
Figure 1: Architecture of the proposed GPA framework, showing a unified LLM backbone and modular token discretization to support all core audio tasks.
Unified Tokenization and Model Architecture
The GPA framework capitalizes on a dual-tokenizer design: the BiCodec tokenizer, as in Spark-TTS, provides robust latent speech representations, while an additional GLM tokenizer (derived from large ASR models and optimized for transcription alignment) complements this with linguistically grounded semantic tokens. All tasks are reduced to autoregressive next-token prediction—with inputs and outputs mapped into this shared token space.
GPA adopts an autoregressive Transformer backbone (Qwen3 variant) as the model core. Task instructions—encoded as tokens—select between TTS, ASR, and VC functionalities by varying input–output token compositions, obviating the need for specialized task heads or routing logic. This design supports seamless, instruction-driven task switching and enables a strictly unified decoding pipeline at both training and inference stages.
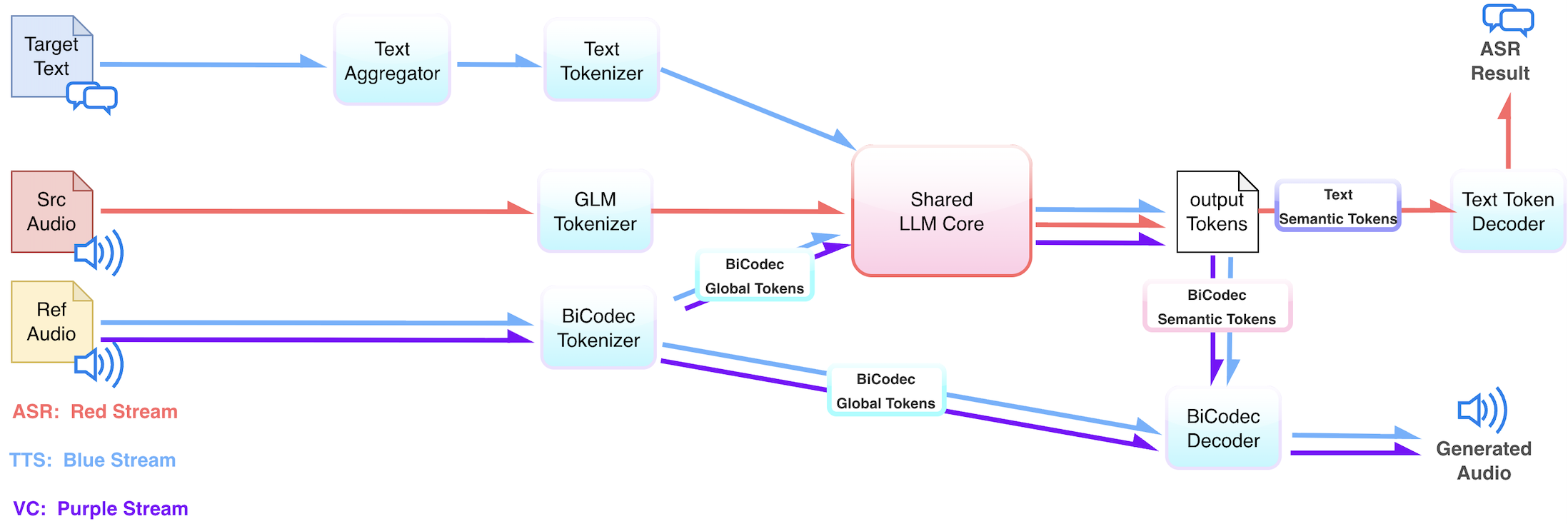
Figure 2: Tokenization and task flow in GPA, illustrating unified processing across TTS, ASR, and VC through different token compositions.
Joint Multi-Task Training
GPA is trained from scratch using a mixture of large-scale public (notably Emilia) and proprietary datasets, covering approximately 1M hours for pretraining and 200K hours for supervised fine-tuning. All tasks are trained under a single autoregressive next-token loss, with each task realized by varying input–output token type and ordering.
Joint multi-task optimization yields mutual benefits. ASR regularizes linguistic alignment in latent representations; TTS and VC induce high-fidelity acoustic rendering and speaker attribute preservation. Gradient flow across tasks regularizes the model and mitigates overfitting to task-specific artifacts, enhancing transferability and generalization. Empirical results demonstrate consistent outperformance over task-specific baselines at equivalent model scale, particularly in low-data or speaker-diverse conditions.
Inference, Latency, and Systems Implications
The architectural unification of GPA directly supports streaming, concurrent inference. All tasks—regardless of modality—are handled via a single, immediately-decodable autoregressive sequence. This homogeneity simplifies concurrency management, reduces overhead for batching and scheduling, and is compatible with standard LLM inference infrastructure.
For edge deployment, a compact 0.3B-parameter GPA variant provides strong TTS and VC results with minimal hardware requirements. The inference paradigm offers low time-to-first-chunk (TTS) and time-to-first-token (ASR) latencies under varying concurrency, demonstrating practical viability across both cloud and on-device scenarios.
Empirical Results and Analysis
- The 0.3B GPA model achieves CER of 0.95% (Chinese) and WER of 1.51% (English) for TTS tasks, with speaker similarity of 65.9% (zh) and 56.5% (en).
- The larger 3B variant closes the gap toward state-of-the-art, recording 0.84% CER and 1.31% WER, and speaker similarity of 73.0% (zh) and 71.7% (en).
- When compared to contemporaneous autoregressive TTS systems of similar size, GPA models are competitive in intelligibility metrics, though speaker similarity is slightly lower for the edge-scale variant.
- The 0.3B model reports 8.88% WER (Librispeech) and 4.50% CER (AISHELL-1); scaling to 3B parameters brings these to 2.52% and 1.93% respectively.
- Larger ASR-specific models (e.g., Whisper-L, FireRed-ASR) outperform GPA on ASR metrics alone. However, GPA’s unified configuration provides competitive accuracy without task-specific tuning.
Latency and Throughput
- Under streaming conditions, the GPA-0.3B model delivers TTS time-to-first-chunk (TTFC) as low as 258.8 ms and ASR time-to-first-token (TTFT) at 157.5 ms for single requests, increasing sublinearly under heavy concurrency (up to 160 streams).
- Throughput and latency are maintained at acceptable levels even as request volume grows, emphasizing the viability for real-time applications.
Implications, Limitations, and Future Directions
GPA shifts the paradigm in speech technology by treating all major tasks as conditional sequence modeling over a unified, discrete token space. This not only streamlines model design and deployment but also positions such systems for future research into joint speech–LLMs, instruction following, and reinforcement learning over discrete audio outputs—a challenge for prior, modular pipelines due to ambiguous credit assignment.
Notable limitations include model bottlenecking on long-form sequence inference and a gap to the highest-performing, task-specialized ASR models at smaller scales. Tuning, scaling, and model-pruning methods—plus advances in efficient sequence processing—are promising avenues for overcoming these constraints.
Direct RL fine-tuning on unified objectives (e.g., perceptual quality, instruction accuracy) is a compelling direction uniquely enabled by GPA’s architecture, with the potential to improve both controllability and generalization.
Conclusion
GPA presents a robust, autoregressive transformer solution that unifies TTS, ASR, and VC in a shared model, delivering competitive empirical performance while significantly simplifying architecture and deployment. This approach underscores the viability and scalability of unified audio foundation models and provides a strong foundation for further developments in multi-modal, multi-task, and instruction-driven speech AI systems.