- The paper introduces ICONIC-444, a contamination-free, high-resolution industrial benchmark with 3.1M images across 444 classes for robust OOD evaluation.
- It employs a rigorous three-stage quality control and hierarchical class structure that mimics realistic, fine-grained industrial scenarios.
- Empirical results show that feature-based methods, like GRAM, achieve high classification accuracy but still struggle with challenging near- and far-OOD detections.
ICONIC-444: A Large-Scale Benchmark for Out-of-Distribution Detection
Motivation and Context
Out-of-distribution (OOD) detection remains a persistent obstacle in the deployment of robust deep learning models, particularly in safety- and reliability-critical real-world environments such as industrial sorting. Existing benchmarks predominantly utilize small-scale, low-resolution, or contaminated datasets, lacking both sufficient granularity and comprehensive coverage of realistic OOD scenarios. The ICONIC-444 dataset addresses these deficiencies by providing a large-scale, methodologically clean benchmark: over 3.1 million high-resolution images spanning 444 fine-grained classes, acquired in an industrial sorting environment mimicking real-world conditions (Figure 1).
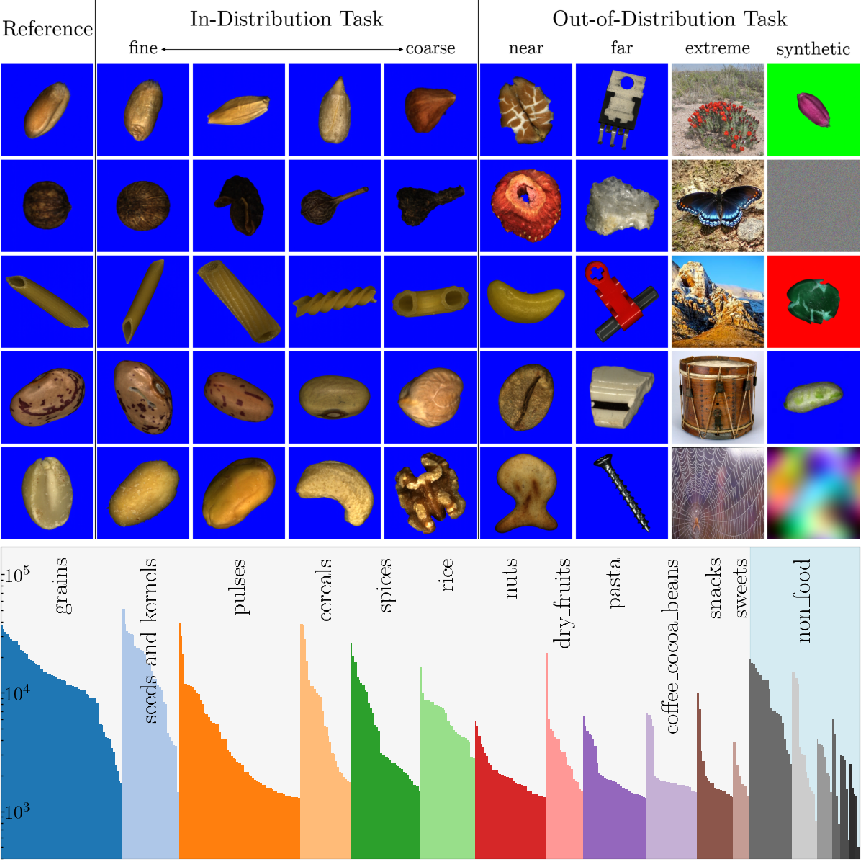
Figure 1: Overview of ICONIC-444, demonstrating progression across granularity of ID classes and the hierarchical composition of OOD categories (near, far, extreme, synthetic) using both internal and external data sources.
Dataset Structure and Acquisition Protocol
ICONIC-444 is structured hierarchically: two main categories (Food and Non-Food), further subdivided into 19 groups and 444 mutually exclusive classes, with a pronounced long-tail distribution reflecting real operational frequencies. Images were acquired using a high-throughput sorting machine prototype equipped with a 4K line-scan camera, yielding images from 256×256 to 1024×1024 pixels at 56μm/pixel, which enables detailed modeling of fine-grained, industry-specific features. Variability is induced both naturally (biological differences, object orientation, domain-specific artifacts) and artificially (manual defects), ensuring high intra-class variance and strong cross-class separation.
A rigorous three-stage quality control protocol was implemented: sourcing uncontaminated material, strictly separated acquisition runs with post-run cleaning, and semi-automatic post-processing based on multi-modal feature analysis and manual inspection. This guarantees both intra-class purity and systematic rejection of contaminated or ambiguous samples (Figure 2).

Figure 2: Quality control illustration, showing accepted and rejected samples, ensuring inter-class purity and removing contaminants.
Benchmark Tasks and ID/OOD Category Construction
ICONIC-444 facilitates creation of benchmark tasks targeting a spectrum of classification and OOD challenges. Four canonical tasks are defined:
- Almond: Seven almond-centric classes, representing moderate fine-grained complexity.
- Wheat: Twelve wheat varieties, a fine-grained classification scenario with subtle inter-class features.
- Kernels: 29 seed and kernel classes, providing medium-grained complexity.
- Food-grade: 324 non-defective food classes, testing large-scale classification.
For each task, OOD splits are constructed by excluding select internal classes (near-OOD from same domain), introducing structurally distinct internal categories (far-OOD from Non-Food), and supplementing with semantically unrelated external datasets (extreme-OOD: ImageNet, iNaturalist, Places365, Textures) and synthetic signal corruptions (synthetic OOD, covering system failure and transmission error scenarios).
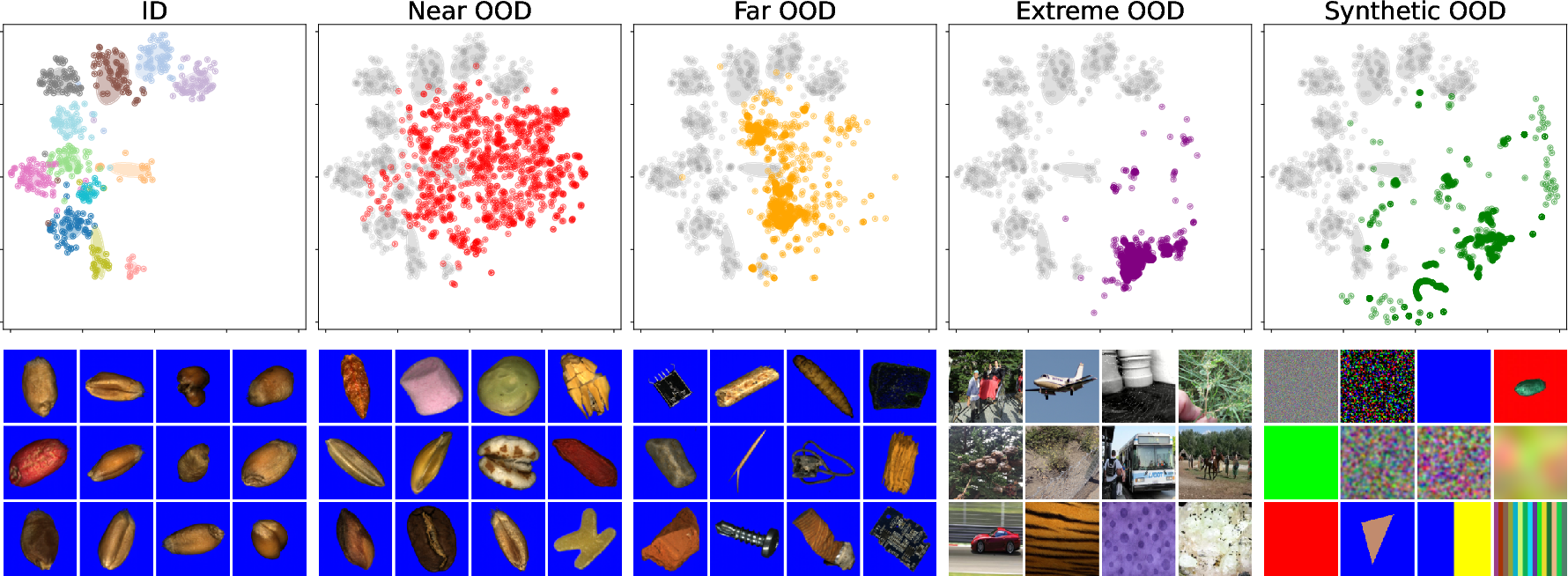
Figure 3: t-SNE of Wheat task embeddings revealing substantial overlap between ID and near-OOD clusters and progressive separation for far, extreme, and synthetic OOD, reflecting hierarchical semantic complexity.
Experimental Protocol and Metrics
Models are trained on defined ID splits using standard modern architectures—ResNet18 (CNN) and Compact Transformer (CCT)—with validation and test splits supporting robust statistical assessment (minimum 1303 samples per class, balanced OOD sample selection). Evaluation leverages 22 state-of-the-art, post-hoc OOD detection methods, spanning score-based (e.g., MSP, MLS, Mahalanobis, KNN) and inference-enhancement algorithms (e.g., ReAct, DICE, ASH, SCALE).
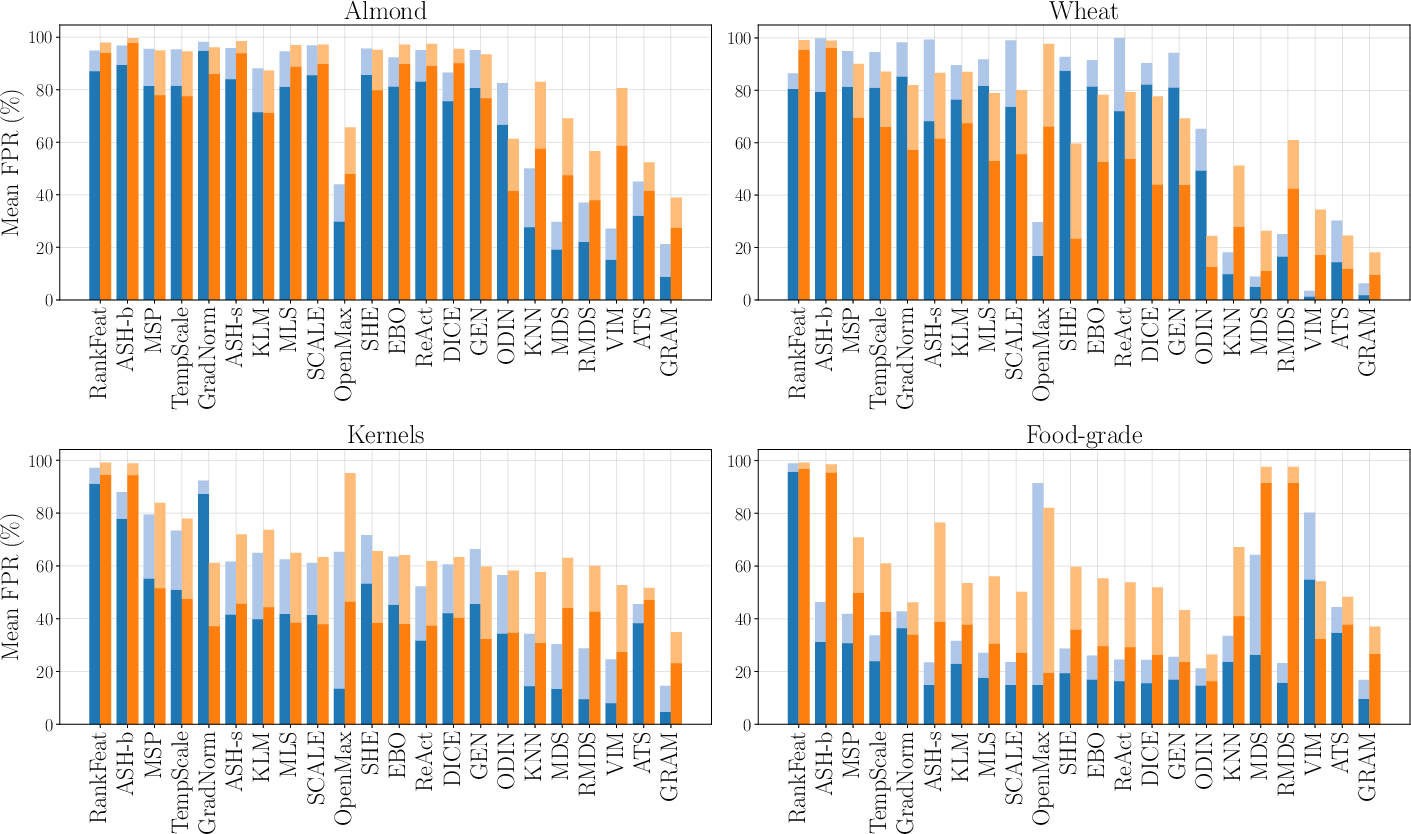
Performance is measured not just via AUROC, but also through false positive rates at stringent operating points—FPR95 and the newly emphasized FPR99, which is critical for industrial settings since even 5% rejection of bona-fide data may be operationally infeasible.
Empirical Results and Methodological Analysis
Across all benchmark tasks, models achieve high classification accuracies (93.18%–96.38%) with low ECE, confirming both discriminative capacity and calibration suitability. OOD detection, however, remains challenging:
- Intermediate Feature-Based Methods Outperform: GRAM, ATS, ViM, and KNN, which operate on penultimate-layer feature statistics, consistently dominate both FPR and AUROC metrics, particularly in the controlled, object-centric context of ICONIC-444.
- High False Positive Rates Persist: Even leading methods (e.g., GRAM) exhibit FPRs in excess of 35% for near- and far-OOD at 99% TPR, highlighting the gulf between OOD separation and acceptable operational reliability.
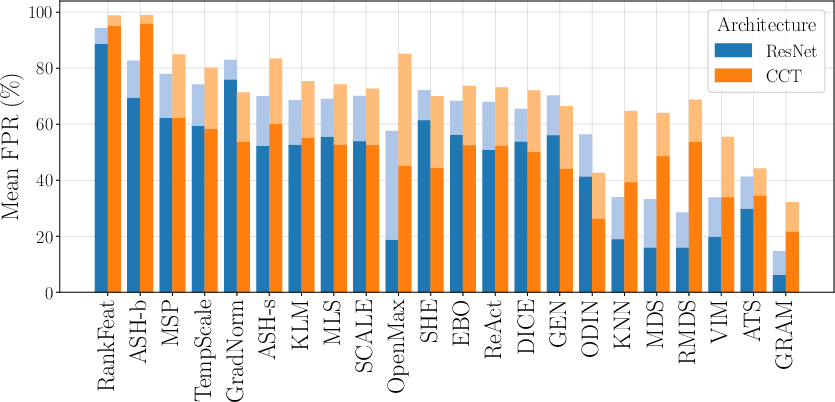
Figure 4: Comparison of mean FPR95 and FPR99 for each OOD detection method, visualizing severe performance degradation at high TPR regimes, especially for near- and far-OOD.
- Architecture-Specific Behavior: CNNs (ResNet18) outperform CCT transformers, likely due to method overfitting during design to classic CNN representation styles. Scaling up to ConvNeXt or ViT architectures does not reliably improve OOD detection performance.
- OOD Category Difficulty: Near-OOD (fine-grained internal exclusions) is substantially harder than far-OOD (structurally distinct internal samples); extreme and synthetic OOD, while easier for most methods, still present prohibitively high FPR for industrial integration.

Figure 5: Samples depicting difficult near- and far-OOD cases for GRAM, along with nearest ID samples, highlighting challenges due to visual and structural similarity.
Cross-Dataset Benchmarking and Statistical Analysis
Feature space analysis via t-SNE and activation profile visualizations demonstrate unique representational advantages of ICONIC-444 over typical scene-centric benchmarks (e.g., ImageNet). Feature sparsity and class separation are substantially higher, favoring statistic-based methods, but not resulting in an overall easier OOD task; OOD samples in the industrial context can be extremely subtle.
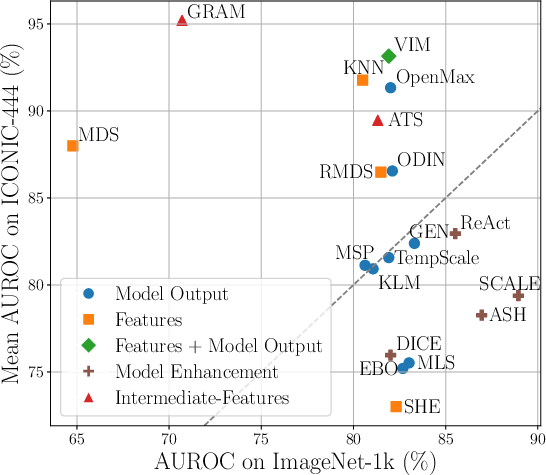
Figure 6: AUROC comparison across ICONIC-444 and ImageNet, demonstrating task-dependent optimality and lack of universal superiority across method classes.
Theoretical and Practical Implications
ICONIC-444 empirically demonstrates that:
Prospective Directions
- ICONIC-444 stands as a foundation for methodologically rigorous, domain-specific OOD research, enabling investigation into new paradigms such as cross-domain generalization, robust feature modeling, and hybrid approaches leveraging both semantic and signal-based cues.
- The dataset's size, structural diversity, and hierarchical OOD composition will facilitate future developments in scalable industrial AI, safety-critical ML deployment, and continual learning under open-world assumptions.
Conclusion
ICONIC-444 addresses critical gaps in OOD detection benchmarking by delivering a contamination-free, large-scale, high-resolution industrial image dataset with finely controlled ID/OOD split construction, supporting realistic and stringent evaluation of state-of-the-art methods. Experimental results demonstrate persistent limitations in current OOD detection models, strong method-task dependence, and the necessity for new research directions leveraging granular, statistically coherent data (2601.10802). As industrial and safety applications of deep learning proliferate, ICONIC-444 will serve as an indispensable asset for research, development, and deployment of reliable OOD detection algorithms.