Balanced allocation: considerations from large scale service environments
Published 15 Jan 2026 in cs.PF and eess.SY | (2601.10874v1)
Abstract: We study d-way balanced allocation, which assigns each incoming job to the lightest loaded among d randomly chosen servers. While prior work has extensively studied the performance of the basic scheme, there has been less published work on adapting this technique to many aspects of large-scale systems. Based on our experience in building and running planet-scale cloud applications, we extend the understanding of d-way balanced allocation along the following dimensions: (i) Bursts: Events such as breaking news can produce bursts of requests that may temporarily exceed the servicing capacity of the system. Thus, we explore what happens during a burst and how long it takes for the system to recover from such bursts. (ii) Priorities: Production systems need to handle jobs with a mix of priorities (e.g., user facing requests may be high priority while other requests may be low priority). We extend d-way balanced allocation to handle multiple priorities. (iii) Noise: Production systems are often typically distributed and thus d-way balanced allocation must work with stale or incorrect information. Thus we explore the impact of noisy information and their interactions with bursts and priorities. We explore the above using both extensive simulations and analytical arguments. Specifically we show, (i) using simulations, that d-way balanced allocation quickly recovers from bursts and can gracefully handle priorities and noise; and (ii) that analysis of the underlying generative models complements our simulations and provides insight into our simulation results.
The paper demonstrates that using d-way choices significantly reduces queue depths in cloud systems by leveraging double-exponential decay properties.
It employs rigorous simulations and analytical techniques to quantify load balancing under burst conditions and multi-priority scheduling.
The study reveals that even with stale or noisy information, d-choice methods maintain robust performance when d>1.
Balanced Allocation in Large-Scale Service Environments: Analysis and Extensions
Introduction
This paper systematically dissects d-way balanced allocation—the policy of assigning each arrival to the least-loaded of d randomly selected servers—within the context of planet-scale, latency-sensitive, and highly dynamic cloud applications. While classical results have established the baseline efficiency of this method, this work addresses its robustness and optimality in operational regimes characterized by bursts, multiple priorities, and imperfect information. Both extensive simulation and rigorous analytical techniques are deployed to establish not only efficacy but also to elucidate the limits and interactions of d-choice scheduling in non-ideal, real-world settings.
Baseline Behavior: Steady-State Analysis
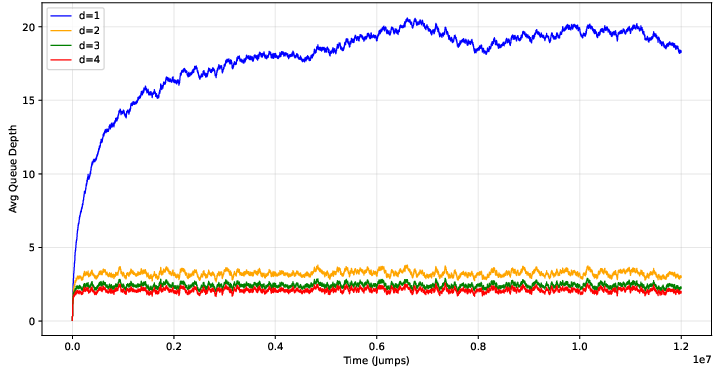
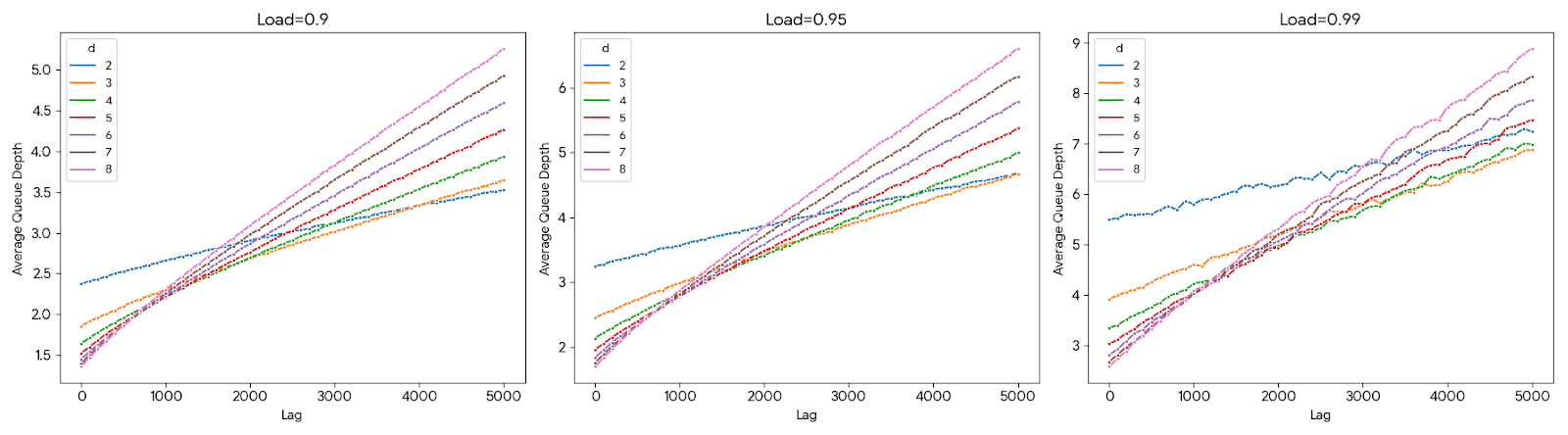
The baseline model considered is an n-queue M/M/1 system with Poisson job arrivals and exponential service, where each incoming job is scheduled to the queue of minimal depth among d randomly sampled queues. For d=1, this degenerates to random assignment; for d>1, the load balancing improves dramatically.
Simulations confirm the well-known double-exponential decay of queue sizes (as analytically established by Vvedenskaya et al. and Mitzenmacher), where the probability πi that a queue has at least i jobs scales as λ(di−1)/(d−1). Empirically, increasing d from $1$ to $2$ reduces mean queue depth and maximum tail depth by an order of magnitude, and gains remain for larger d.
Figure 1: Time series for the baseline configuration, showing rapid stabilization and low queue depths for d>1.
Bursty Arrivals and Recovery Dynamics
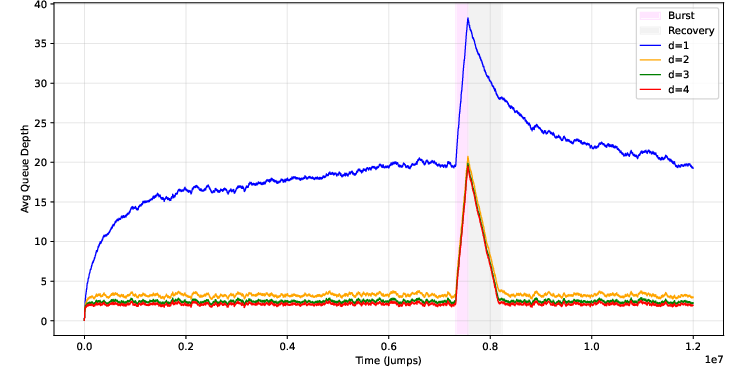
Under burst arrivals—where the input rate temporarily exceeds system capacity—the recovery behavior of allocation strategies diverges sharply.
For d=1, post-burst queue tail lengths grow without bound, and recovery is bottlenecked by queues with significant accumulated backlog, requiring Ω(nm) time to drain, where m is the burst excess. In contrast, for d>1, theoretical results leveraging coupling techniques and extending the heavy-load balls-into-bins analysis show that maximum queue depth grows only as O(loglogn) beyond mean, and system recovery to steady-state occurs in O(nlogn) time—effectively tracking the optimal drain rate with only a negligible tail effect.
Figure 2: Queue sizes with one burst, showing substantially faster recovery for d>1 compared to d=1.
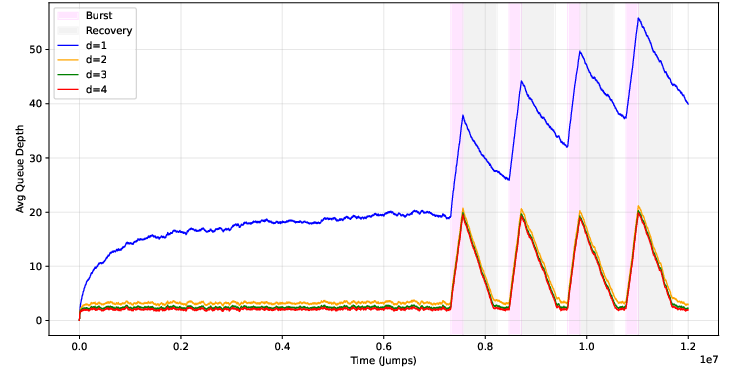
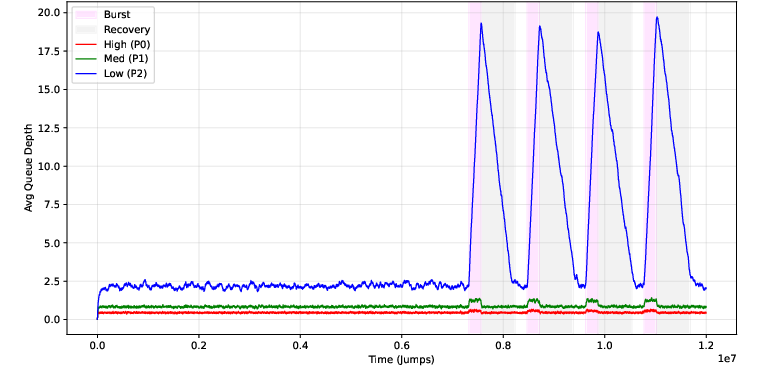
Figure 3: Multiple bursts accentuate the gap in recovery rates; d=4 maintains rapid recovery and avoids queue accumulation.
Empirical results reinforce these theoretical bounds: for d≥2, increasing burst count has marginal impact on steady-state or maximum queue depths, while for d=1, both metrics degrade rapidly as bursts cluster.
Incorporating Job Priorities: Analytical and Simulation Results
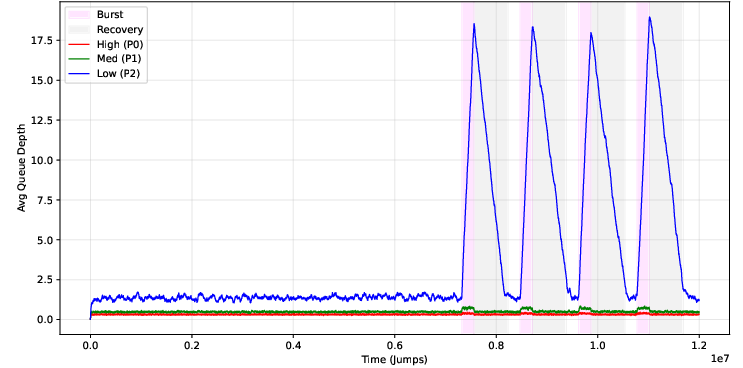
Cloud schedulers must handle heterogenous job priorities. The paper evaluates four scheduler variants for multi-priority traffic, all generalizing d-way allocation. Among these, the "Independent" and "MineThenTotal" strategies yield nearly identical and optimal queue depths for top priorities, with no substantial additional complexity required for priority-awareness.
Simulations (see Tables~\ref{tab:priority-avg} and \ref{tab:priority-max} in the original manuscript) and matching theoretical analysis extend the double-exponential queue depth decay to each priority class. Lower priorities see their traffic conditioned on the residual capacity left by the higher-priority classes. Specifically, the ith priority class is distributed as a balanced allocation system with effective load λi/(1−∑j<iλj).
Figure 4: Average queue depth for a multi-priority system (MineThenTotal), indicating robust handling of all priority classes and efficient suppression of low-priority queue inflation.
Notably, the results demonstrate no statistically significant advantage for complex heuristics over the simplest Independent rule, and overall system utilization remains optimal, matching single-priority baselines.
Robustness to Imperfect (Stale or Noisy) Information
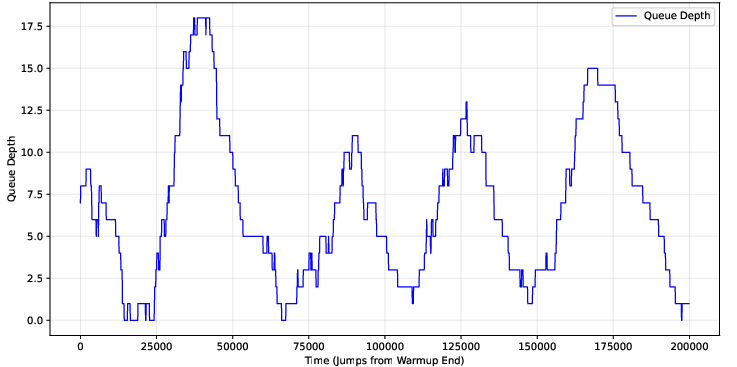
In distributed environments, load balancers operate with delayed (lagged) or fuzzy (noisy) queue state data. The impact of this on d-choice schemes is nontrivial. As lag increases, higher d exacerbates "herd behavior," driving many arrivals to queues that were empty at the time of last observation, causing periodic overload. However, for moderate lag or comparison fuzz, d>1 continues to outperform d=1 on both mean and tail queue depths.
Figure 5: Trace of queue depth for d=4 under lag=10000, revealing sawtooth "herd" overload patterns.
Mathematical analysis shows that, for any constant fuzz b, queues with depth ≤b+1 behave as in standard M/M/1, while beyond this, the distribution decays doubly exponentially with parameters determined by b and d. This structural characterization provides explicit guidelines for parameter selection under practical system constraints.
Figure 6: d versus lag and λ: increasing lag shifts performance optima to lower d as higher d becomes counterproductive under stale information.
Interaction of Bursts, Priorities, and Noise: Aggregate System Behavior
With high load (λ=0.95), 4 bursts, 3 priorities, and lag, d=4 consistently delivers minimal queueing delay for all but the lowest priority class, which absorbs transients. Post-burst recovery remains rapid, and overall efficiency is retained under all compounded adversities.
Implications and Prospects
These results have substantial implications:
Resource Provisioning: d-way balanced allocation substantially reduces the tail latency and necessary over-provisioning due to queue imbalance, provided that the dynamic regime is not dominated by high staleness.
System Stability: The doubly exponential decay in queue depths, extended rigorously to handle priorities and noisy state, ensures excellent probabilistic guarantees for SLO-constrained services.
Parameter Tuning: The explicit demonstration of trade-offs in d selection, especially under lag or fuzz, motivates adaptive or load-aware d in production deployments.
Future research is likely to focus on:
Adaptive d mechanisms that react to measured lag and load,
More precise modeling and control of "herd" effects under lag,
End-to-end latency models incorporating network and service heterogeneity,
Extensions to non-Poissonian arrival and/or service distributions.
Conclusion
The study precisely quantifies and extends the robust efficiency profile of d-way balanced allocation policies in realistic, large-scale cloud settings. By leveraging simulation, combinatorial, and probabilistic methods, it delivers a detailed map of their efficacy in face of bursts, priority mixing, and information imperfection. These findings support the continued adoption and parameterization of d-choice scheduling as a foundational element of cloud-scale resource allocation heuristics.