FrankenMotion: Part-level Human Motion Generation and Composition
Abstract: Human motion generation from text prompts has made remarkable progress in recent years. However, existing methods primarily rely on either sequence-level or action-level descriptions due to the absence of fine-grained, part-level motion annotations. This limits their controllability over individual body parts. In this work, we construct a high-quality motion dataset with atomic, temporally-aware part-level text annotations, leveraging the reasoning capabilities of LLMs. Unlike prior datasets that either provide synchronized part captions with fixed time segments or rely solely on global sequence labels, our dataset captures asynchronous and semantically distinct part movements at fine temporal resolution. Based on this dataset, we introduce a diffusion-based part-aware motion generation framework, namely FrankenMotion, where each body part is guided by its own temporally-structured textual prompt. This is, to our knowledge, the first work to provide atomic, temporally-aware part-level motion annotations and have a model that allows motion generation with both spatial (body part) and temporal (atomic action) control. Experiments demonstrate that FrankenMotion outperforms all previous baseline models adapted and retrained for our setting, and our model can compose motions unseen during training. Our code and dataset will be publicly available upon publication.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to make 3D human animations from text descriptions, with very precise control over which body parts move and when they move. The authors build a special dataset and a model so you can tell the system things like “raise the left arm while sitting, then turn around,” and it generates a smooth, realistic motion that follows those instructions exactly.
What questions does it ask?
The researchers wanted to solve three simple but important problems:
- How can we control individual body parts (like arms, legs, head, spine) with text, not just the whole body at once?
- How can we control not only what moves, but also when it moves over time?
- Can we mix and match small motion pieces (like “bend knees,” “turn head,” “step forward”) to create new, more complex motions the system hasn’t seen before?
How did the researchers do it?
They tackled the problem in two main steps: building a better dataset and creating a motion generator that understands three levels of instructions.
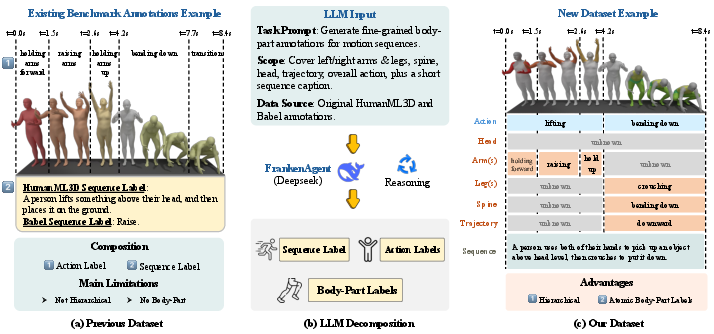
Building a better dataset (FrankenStein)
Most existing motion datasets have only big-picture labels, like “walking” or “sitting,” but not what each body part does at each moment. To fix that, the authors used an AI language assistant (FrankenAgent) to read existing motion descriptions and infer detailed, per-body-part actions with timing. Think of it like turning a rough script (“tie shoes”) into a detailed screenplay that says exactly when the spine bends, when the arms move, and for how long.
They:
- Collected motions and their descriptions from well-known datasets.
- Asked a strong LLM to break each sequence into smaller, timed parts for each body area (arms, legs, head, spine, and trajectory).
- Told the AI to say “unknown” when it wasn’t sure, to avoid making things up.
- Checked the quality with human experts, who agreed the new labels were correct about 93% of the time.
This created FrankenStein: a dataset that links motions to multi-level text labels with precise timing, from full-sequence summaries down to per-body-part actions.
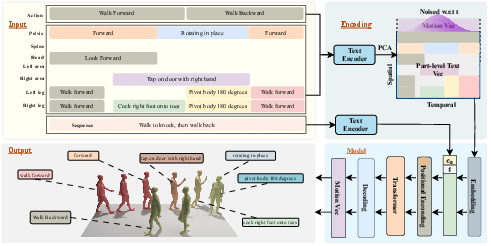
The motion generator (FrankenMotion)
They built a model that composes motions from small building blocks, guided by text at three levels. You can think of it like directing a puppet show:
- Sequence-level: the story of the whole scene.
- Action-level: what happens in chunks of time (like “stand up,” then “turn,” then “walk”).
- Part-level: per-frame instructions for specific body parts (like “left arm rises now,” “head turns now”).
Under the hood:
- They use a transformer, a type of AI that’s good at reading sequences and finding patterns over time.
- They use a diffusion process, which starts from noise and gradually “cleans it up” into a realistic motion—like sharpening a blurry picture step-by-step.
- They turn text into numbers the model can understand using a text encoder (so the model can match “raise left arm” to motion patterns).
- During training, they sometimes hide some text inputs on purpose (a “masking” trick) so the model learns to handle missing or partial instructions.
What did they find?
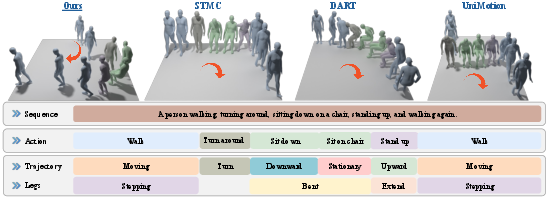
The new dataset and model make motion generation more accurate and more controllable than previous methods.
- Better control: The model followed part-level and timing instructions more precisely than other systems they adapted for comparison.
- More realism: The resulting motions looked smoother and more natural.
- New combinations: The model could combine small motion pieces to make motions it never saw during training (for example, “sit down while raising the left arm”).
- High-quality labels: Human reviewers found the dataset’s fine-grained, per-part, timed labels were correct about 93% of the time, with strong agreement among reviewers.
In simple terms: it both listened better to the instructions and moved more naturally.
Why does it matter?
This work makes it easier to create detailed, believable human animations from plain text. That helps:
- Game developers and film/animation creators quickly craft complex character movements.
- AR/VR experiences feel more responsive and lifelike.
- Robotics and embodied AI learn precise, step-by-step human-like actions.
- Researchers explore motion as a mix-and-match “language” of body-part actions, enabling more flexible and creative motion design.
Big picture: the paper turns motion generation into a kind of “motion Lego,” where small, timed, body-part actions can be composed into rich, realistic sequences guided by simple language.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following gaps and open questions for future research:
- Long-horizon generation: The model cannot produce minute-long sequences in a single pass; strategies for modeling and evaluating long-term temporal dependencies (e.g., hierarchical sampling, memory mechanisms, chunked diffusion with smooth stitching) are not explored.
- Compositional generalization: Claims of composing unseen motions are not systematically validated; a benchmark that holds out specific cross-part/action combinations and measures performance on truly novel compositions is missing.
- LLM annotation reliability at scale: Human auditing covers only 50 sequences; larger-scale, fine-grained validation of per-part temporal alignment and label correctness (including timing offset/error distributions) is needed, especially on edge cases (fast motions, simultaneous multi-part actions, complex transitions).
- Cross-LLM robustness and calibration: FrankenAgent is instantiated with DeepSeek-R1 only; comparative studies across different LLMs (e.g., GPT-4, Claude, Llama-3) and calibration methods (uncertainty-aware outputs, ensemble agreement) are absent.
- Definition and granularity of body parts: The paper does not specify the exact set of body parts; inclusion and impact of finer-grained parts (e.g., hands/fingers, facial features) and their labels on controllability and realism are not evaluated.
- Physical plausibility and contact modeling: No explicit constraints or metrics for physical realism (e.g., contact consistency, foot sliding, joint limit violations, ground penetration) are reported; incorporating physics priors or post-hoc correction and evaluating with contact-based metrics remains open.
- Multi-person and human–object interactions: The dataset/model focuses on single-person motion without objects; extending annotations and generation to interactions (contact events, affordances, relative motion constraints) and evaluating in such settings is unexplored.
- Scene and trajectory constraints: Although “trajectory” is mentioned as a control signal, consistent global path following, obstacle avoidance, and scene-aware constraints (e.g., surfaces, stairs) are not modeled or evaluated.
- Language coverage and robustness: The approach relies on English CLIP embeddings; generalization to non-English, code-switching, domain-specific jargon, and compositional linguistic structures (e.g., nested constraints, conditional instructions) is untested.
- Conflict resolution for contradictory inputs: How the model handles conflicting or infeasible part/action/sequence prompts (e.g., “run while sitting”) and prioritizes constraints is unspecified.
- Impact of sparse/missing labels: The masking strategy (Beta-dropout on known labels) is introduced but not ablated; sensitivity to varying rates/patterns of missingness and strategies for imputing/denoising unknown labels require study.
- Text encoder and embedding choices: CLIP is frozen and part/action embeddings are PCA-reduced to 50D; ablations on encoder choice, dimensionality, and fine-tuning for motion semantics are missing.
- Architectural alternatives for conditioning: The current design concatenates embeddings; exploring cross-attention, conditioning adapters, or gating mechanisms for part/action/sequence fusion and their effects is not investigated.
- Evaluation metrics validity: Semantic correctness relies on learned evaluators trained on the same dataset and MPNet embeddings; independent human studies, fine-grained spatio-temporal alignment metrics (e.g., DTW per joint, per-part timing IoU), and physics-based metrics are lacking.
- Baseline adaptation fairness: Baselines are modified to fit the task (e.g., merging texts), which may disadvantage them; stronger part-aware baselines or re-implementations designed for part-level control should be compared under matched training budgets.
- Editing and controllability benchmarks: While qualitative editing is shown, quantitative evaluation protocols for per-part editing fidelity, minimality (edit locality), and user-in-the-loop control latency/accuracy are absent.
- Efficiency and real-time usage: Training/inference costs (47.5 hours on H100; 100 diffusion steps) are reported without latency/throughput benchmarks; approaches for low-latency interactive control (e.g., LCMs, distillation) and their quality trade-offs need assessment.
- Retargeting and rig generalization: The method is SMPL-centric; generalization to diverse skeletal rigs, retargeting quality, and cross-skeleton consistency metrics are not addressed.
- Dataset scope and bias: FrankenStein covers ~39 hours; coverage of diverse motion genres (dance, sports, acrobatics), long-tail actions, and demographic/anthropometric variation is unclear; distribution analyses and bias audits are needed.
- Annotation protocol transparency: Detailed prompt templates and alignment procedures are relegated to the supplementary; releasing full protocols, alignment heuristics, and failure case analyses would improve reproducibility and trustworthiness.
- Diffusion schedule and objective choices: The model uses prediction with 100 cosine-scheduled steps; ablations on step counts, prediction parameterization (e.g., , ), guidance strategies, and their effects on controllability/realism are missing.
- Safety and ethics: Potential biases introduced by LLM-generated labels, misuse risks (e.g., synthesizing harmful or deceptive motions), and guidelines for responsible dataset/model use are not discussed.
Practical Applications
Overview
FrankenMotion introduces a diffusion-based, transformer motion generator with hierarchical control at sequence, action, and body-part levels, and FrankenStein, the first large-scale dataset with atomic, temporally aligned part-level text annotations produced via an LLM agent (FrankenAgent). The key innovations—fine-grained spatiotemporal control, compositional motion synthesis, and scalable LLM-assisted annotation—unlock practical applications across content creation, simulation, robotics, human factors, and research workflows.
Below are actionable use cases, grouped by deployment horizon, with sector links, potential tools/products/workflows, and feasibility assumptions or dependencies.
Immediate Applications
- Text-to-motion authoring and editing for animation/VFX
- Sector: Media/Entertainment, Software
- Tool/product/workflow: Blender/Maya/Unreal plugins to generate or edit skeletal animation from sequence/action/part-level prompts; timeline UI to author part-specific constraints (e.g., “left arm waves from 1.0–2.2 s”).
- Assumptions/dependencies: Rig retargeting from SMPL to studio rigs; offline/near-real-time is acceptable; post-processing for foot-skate and contacts; GPU availability.
- Rapid previsualization and storyboarding
- Sector: Film/TV, Advertising
- Tool/product/workflow: Previz storyboard tool where directors sketch global actions and refine with part-level prompts for key beats; export to DCC packages.
- Assumptions/dependencies: Non-real-time acceptable; human-in-the-loop refinement; proper licensing for trained models and datasets.
- Game development prototyping for NPC behaviors and cutscenes
- Sector: Gaming
- Tool/product/workflow: Editor toolkit to produce cutscene clips and NPC idle/ambient animations by composing limb-specific instructions; integrate into motion matching systems.
- Assumptions/dependencies: Offline generation pipelines; engine integration (UE/Unity); careful quality control for transitions.
- VTuber/virtual presenter gesture design
- Sector: Creator Economy, Live Streaming, Education
- Tool/product/workflow: Library of reusable gesture “macros” (part-level prompts) that can be triggered via text commands during streams or recording.
- Assumptions/dependencies: Latency may limit live real-time use; requires avatar retargeting and basic calibration.
- Motion editing and mocap data augmentation
- Sector: Media/Entertainment, Sports Tech
- Tool/product/workflow: Patch/extend mocap by inserting atomic actions or editing specific limbs without re-shooting; generate long-tail variants for motion libraries.
- Assumptions/dependencies: Consistency checks for continuity and contacts; compatibility with existing mocap formats.
- Human factors and ergonomics what-if testing
- Sector: Manufacturing, Workplace Safety
- Tool/product/workflow: Compose task variants (reach, bend, twist) to stress-test digital human models; evaluate posture risks.
- Assumptions/dependencies: Motions are not guaranteed physically accurate; may require physics or biomechanical validation layers.
- Simulation assets for robotics imitation in sim
- Sector: Robotics
- Tool/product/workflow: Generate families of semantically labeled reference motions (with part constraints) to train imitation policies and curriculum learning.
- Assumptions/dependencies: Sim-to-real transfer gap; needs physics consistency and contact modeling if used directly for policy learning.
- Kinesiology/biomechanics pedagogy
- Sector: Education, Academia
- Tool/product/workflow: Interactive web app demonstrating part-specific motion decomposition and timing; students edit body-part prompts and observe outcomes.
- Assumptions/dependencies: Educational use only; not a clinical tool.
- Semantic motion retrieval and library organization
- Sector: Media/Entertainment, Software
- Tool/product/workflow: Index existing motion libraries using generated part/action/sequence annotations; query by fine-grained semantics (e.g., “right leg stutter step while turning left”).
- Assumptions/dependencies: FrankenAgent QA to minimize annotation hallucination; human spot checks.
- LLM-assisted annotation to bootstrap new datasets
- Sector: Academia, R&D Labs, Data Operations
- Tool/product/workflow: FrankenAgent-style pipelines to create part-level, temporally aligned labels from legacy motion datasets; integrated uncertainty flags and human-in-the-loop QA.
- Assumptions/dependencies: Access to an LLM with comparable reasoning (e.g., DeepSeek-R1 or equivalent), robust prompt templates, and annotation governance.
- Synthetic 3D motion for text-to-video training data
- Sector: Foundation Models, GenAI
- Tool/product/workflow: Render 3D characters driven by FrankenMotion under controlled part/action prompts to create high-quality text-aligned video for multimodal pretraining.
- Assumptions/dependencies: High-fidelity rendering pipeline; ethics review and watermarking; domain match to downstream tasks.
Long-Term Applications
- Real-time, low-latency avatar control from language
- Sector: AR/VR, Social Telepresence
- Tool/product/workflow: On-device or cloud-in-the-loop controller that maps voice/text to continuous motions with part-level constraints, using distilled/accelerated diffusion (e.g., LCM variants) for sub-50 ms latency.
- Assumptions/dependencies: Model compression and inference optimization; robust safety filters; bandwidth constraints.
- Whole-body humanoid robot control via compositional part commands
- Sector: Robotics, Industrial Automation
- Tool/product/workflow: Translate part-level natural language constraints into whole-body motion plans with contact/dynamics feasibility; integrate with MPC and safety monitors.
- Assumptions/dependencies: Physics-grounded controllers, contact planning, compliance control, and rigorous safety certification.
- Multi-human and human–object interaction synthesis with scene constraints
- Sector: Gaming, Film, Robotics Simulation
- Tool/product/workflow: Extend control to interactions (grasp, handover) and multi-agent coordination, conditioned on object affordances and scene geometry.
- Assumptions/dependencies: New datasets with HOI/scene labels; contact and collision handling; improved physical plausibility.
- Clinical-grade rehab and physical therapy guidance
- Sector: Healthcare
- Tool/product/workflow: Personalized exercise generation and progress tracking with part-level targets and timing (e.g., “increase shoulder abduction to 70° over 2 s”); tele-rehab supervision.
- Assumptions/dependencies: Clinical validation, biomechanics fidelity, regulatory clearance (e.g., MDR/FDA), patient safety and privacy compliance.
- Workplace safety training simulators at scale
- Sector: EHS (Environment, Health & Safety), Insurance
- Tool/product/workflow: Generate parameterized task catalogs exploring hazardous motion variants (awkward lifts, slips) with annotated part-level risk factors for immersive training.
- Assumptions/dependencies: Physics-based risk estimation; expert-reviewed hazard models; content governance.
- Autonomous driving and robotics perception simulation
- Sector: Mobility, AV/ADAS, Robotics
- Tool/product/workflow: Populate simulation with semantically diverse pedestrian/cyclist motions, composed at part-level for rare behaviors and edge cases.
- Assumptions/dependencies: Validation against real-world distributions; transferability of behavior statistics; simulation fidelity.
- Inclusive and accurate sign language and gesture production
- Sector: Accessibility, Education, Media
- Tool/product/workflow: Controlled handshape, facial expression, and upper-body motions for sign language avatars; curriculum for gesture-rich presenters.
- Assumptions/dependencies: Specialized linguistic datasets and constraints (phonology, prosody); community co-design; high-fidelity finger/face rigs.
- Industry standards for motion annotation and provenance
- Sector: Policy, Standards Bodies, Data Governance
- Tool/product/workflow: Define schema and best practices for atomic part-level annotations, LLM-assisted labeling protocols, audit trails, and uncertainty tagging.
- Assumptions/dependencies: Multi-stakeholder coordination (academia, studios, robotics firms); alignment with existing data standards.
- Watermarking and content provenance for synthetic human motion
- Sector: Policy, Platforms, Media
- Tool/product/workflow: Motion-level watermarking to mark synthetic or edited sequences; platform-side provenance checks for uploads.
- Assumptions/dependencies: Technically robust watermarking for motion data; platform adoption; legal/policy frameworks.
- Cross-modal agentic NPCs and training-by-description
- Sector: Gaming, Simulation, AI Agents
- Tool/product/workflow: LLM-driven agents that plan and execute actions by emitting part-level motion constraints in real time, coupled with environment feedback.
- Assumptions/dependencies: Fast inference, safety filters, and tight engine integration; sandboxing to prevent exploitative behaviors.
- Long-horizon, multi-stage tasks with robust temporal planning
- Sector: Robotics, Training Simulators, Film/Games
- Tool/product/workflow: Author minute-long sequences with staged constraints (e.g., “approach, kneel, pick, stand, turn, place”) and smooth inter-stage transitions.
- Assumptions/dependencies: Advances in long-context modeling and memory; hierarchical controllers; temporal consistency across minutes.
Cross-cutting dependencies and assumptions
- Retargeting and rig compatibility: Most workflows require mapping SMPL-style output to production rigs/avatars with consistent skeleton topology and scale.
- Physical plausibility: Raw outputs may need physics correction for contact forces, balance, and constraints; crucial in robotics/ergonomics/clinical uses.
- Dataset licenses and domain shift: Training on AMASS/BABEL/KIT-ML/HumanML3D-derived assets may have licensing constraints; performance may degrade on out-of-domain actions.
- LLM-based annotation quality: FrankenAgent accuracy is high but not perfect; pipelines should include uncertainty reporting and human QA.
- Compute and latency: The baseline diffusion pipeline (100 steps) is not real-time; deployment-grade systems need distillation, caching, or LCM-like acceleration.
- Safety, ethics, and governance: Synthetic human motion entails risks (misuse, deepfakes, biased portrayals); adopt watermarking, provenance, and ethical review.
Glossary
- 6D representation: A rotation encoding scheme that avoids discontinuities by representing 3D rotations with six parameters. "encoded using the 6D representation~\cite{zhou2019continuity},"
- AdamW optimizer: A variant of Adam that decouples weight decay from the gradient update to improve generalization. "We use the AdamW optimizer~\cite{loshchilov2017decoupled} with a learning rate of and a batch size of 32."
- Affordance reasoning: Inferring possible actions enabled by objects in an environment, used to guide interaction modeling. "Human–object interaction modeling~\cite{zhang2022couch,Zeng_2025_CVPR,xu2024interdreamer,wu2025human,zhang2024hoi,xu2025intermimic,xu2025interact,zeng2025chainhoi,li2023object} further introduces affordance reasoning and contact-based control,"
- AMASS: A large unified motion capture dataset that standardizes human motion parameterization across sources. "AMASS later unified motion capture data from 15 publicly available mocap datasets into a consistent parameterization of human motion,"
- Autoregressive: A modeling approach that predicts future outputs based on previously generated outputs. "DART~\cite{Zhao:DartControl:2025} employs a latent diffusion model for real-time, autoregressive motion generation,"
- Beta distribution: A probabilistic distribution over [0,1] often used to sample masking probabilities in regularization. "We adopt Beta distribution to randomly decide the zero out probability of a body part text label : ,"
- CLIP: A multimodal model that encodes text and images into a shared embedding space for alignment. "we use CLIP~\cite{radford2021learning} to extract text features for all input prompts."
- Cosine noise schedule: A diffusion training schedule that varies noise levels following a cosine curve to improve sampling quality. "we employ a cosine noise schedule with 100 diffusion steps, as introduced by~\cite{chen2023importance}."
- DDPM objective: The training loss used in Denoising Diffusion Probabilistic Models to recover clean data from noisy inputs. "We train our diffusion model parametrized by using the standard DDPM objective~\cite{Ho2020DDPM}:"
- Diffusion model: A generative model that iteratively denoises samples from a noise distribution to produce data. "We adopt a transformer-based diffusion model as the framework for our text conditioned motion generation."
- Diffusion timestep embedding: A learned representation of the current diffusion step injected into the model for conditioning. "The diffusion timestep embedding, after an MLP projection, is also added as a separate token."
- Diversity (metric): A measure of variability across generated samples indicating non-redundant outputs. "realism, consisting of Fréchet Inception Distance (FID) and Diversity~\cite{Guo2022CVPR_humanml3d}."
- Fréchet Inception Distance (FID): A metric comparing distributions of real and generated data via feature statistics to assess realism. "realism, consisting of Fréchet Inception Distance (FID) and Diversity~\cite{Guo2022CVPR_humanml3d}."
- Gwet’s AC1 coefficient: A reliability statistic assessing inter-rater agreement less biased by prevalence than Cohen’s kappa. "We also report inter-annotator agreement using Gwet’s AC1 coefficient ()~\cite{gwet2001handbook} to assess the reliability of human evaluation,"
- Hierarchical annotation: A structured labeling paradigm that spans sequence-, action-, and part-level descriptions over time. "This hierarchical annotation design enables a richer and more structured representation of human motion."
- Hierarchical conditioning: Conditioning a generative model on multiple levels of semantic inputs (sequence, action, part) simultaneously. "learning to compose complex motions through hierarchical conditioning on part-, action-, and sequence-level text,"
- Joint embedding: A unified representation space that fuses multiple modalities (e.g., text and motion) for learning alignment. "we use a joint embedding for sequence, action, part-level text and motion,"
- Latent diffusion model: A diffusion process applied in a compressed latent space to improve efficiency and quality. "DART~\cite{Zhao:DartControl:2025} employs a latent diffusion model for real-time, autoregressive motion generation,"
- Latent space: A learned, lower-dimensional representation where cross-modal alignment and generation are performed. "fine tune the pre-trained LLMs to align text and motion in the latent space."
- LLMs: Scalable neural LLMs with strong reasoning and long-context capabilities used for annotation. "leveraging the reasoning capabilities of LLMs."
- M2T: A motion-to-text alignment metric used to quantify semantic correctness of generated motions. "semantic correctness, consisting of R-Precision~\cite{Guo2022CVPR_humanml3d} and M2T~\cite{petrovich2024stmc},"
- MPNet embeddings: Text representations from the MPNet model used to mitigate paraphrase-induced false negatives. "we follow~\cite{petrovich23tmr} and use MPNet~\cite{song2020mpnet} embeddings to remove false negative pairs due to paraphrased text labels"
- Motion capture (mocap): The process and datasets capturing human movement for modeling and generation. "largely driven by the growing availability of motion capture (mocap) datasets and their corresponding textual annotations."
- PCA (Principal Component Analysis): A dimensionality reduction technique applied to text features to control model complexity. "For action and part labels, we apply PCA to reduce the embedding dimension to ,"
- Rotation-invariant representation: A representation that remains consistent regardless of global rotation, aiding robust pose modeling. "forming a rotation-invariant representation by defining in a local coordinate frame aligned with the body."
- R-Precision: A retrieval-based metric (R@K) that evaluates how well generated motions match their corresponding texts. "semantic correctness, consisting of R-Precision~\cite{Guo2022CVPR_humanml3d} and M2T~\cite{petrovich2024stmc},"
- SMPL: A parametric 3D human body model that provides pose and shape parameters for motion representation. "using SMPL~\cite{smpl} pose parameters, joint positions, velocities and angular velocities:"
- Stochastic masking: Randomly dropping conditioning inputs during training to improve robustness to sparse or missing labels. "This stochastic masking enhances robustness to incomplete conditioning and improves generalization under sparse supervision~\cite{Liu2019BetaDropout}."
- Transformer-based diffusion model: A diffusion architecture that uses transformer layers to model spatiotemporal dependencies. "Our model is a transformer-based diffusion model that can be input conditioned on a) sequence level prompt, b) action-level prompt and c) part-level prompt."
- ViT-B/32: A specific Vision Transformer variant used within CLIP as the text encoder backbone. "we adopt the frozen text encoder from CLIP (ViT-B/32)~\cite{radford2021learning}."
Collections
Sign up for free to add this paper to one or more collections.