- The paper introduces LLM-guided split selection and leaf prediction to overcome few-shot challenges in tabular data learning.
- It integrates unlabeled data to boost classification AUC and lower regression NRMSE, outperforming traditional methods.
- ForestLLM produces interpretable decision paths and generalizes well, even on out-of-distribution datasets.
ForestLLM: LLM-Guided Random Forests for Few-Shot Tabular Learning
Motivation and Problem Statement
Few-shot tabular learning is characterized by limited labeled data and ubiquitous availability of unlabeled instances, typical in high-impact domains like healthcare and finance. Traditional decision forests, though robust for full-supervision, degrade under label scarcity due to their reliance on statistical splitting criteria (e.g., Gini impurity, information gain) and high-variance leaf estimates. Direct LLM-based predictors on tabular data, typically through table serialization and prompting, struggle with data structure misalignment and inefficiency, often being unsuitable for test-time deployment due to cost and latency. The question addressed is: Can an LLM, with its strong semantic priors and domain abstraction, be repositioned as an offline model designer, guiding the training-time construction of interpretable, lightweight models that generalize in data-poor settings?
ForestLLM: Methodology
ForestLLM proposes a two-fold mechanism:
- Semantic Tree Induction with LLM-guided Splitting. At each node, a summary prompt is constructed, fusing (i) serialized labeled exemplars, (ii) a structural summary of the local feature distribution—obtained from both labeled and unlabeled samples—and (iii) contextual tree path metadata. The LLM is prompted to select splits based on causal plausibility and evidential support, synthesizing human-like, semantically coherent tree structures that integrate the low-level data manifold with high-level priors.
- In-Context Leaf Prediction. Rather than using empirical aggregates at leaves, the model performs a single-pass LLM-driven inference procedure. The accumulated decision path is converted into a natural language rule and paired with a relevant support set of labeled exemplars. The LLM is then prompted to deterministically synthesize the leaf prediction. This framework abstracts majority voting or averaging, replacing it with context-sensitive, prior-informed reasoning.
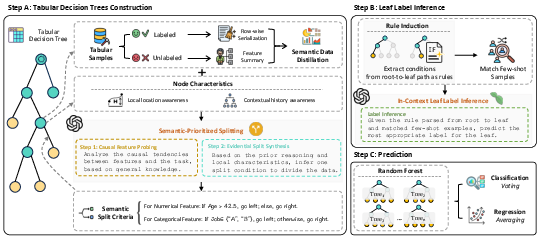
Figure 1: ForestLLM framework overview: training uses an LLM as an offline architect for split selection and semantic leaf prediction; inference is purely via the lightweight forest.
Empirical Evaluation and Comparative Analysis
ForestLLM demonstrates consistent state-of-the-art performance under 4-, 8-, and 16-shot scenarios across a diverse suite of tabular classification and regression datasets. In many cases, it achieves AUC or NRMSE competitive with (or surpassing) existing LLM-augmented baselines (e.g., TableLLM, LIFT, FeatLLM, P2T) and strong classical learners (XGBoost, TabPFN, random forests). ForestLLM excels in cases where the target dataset is out-of-distribution, including benchmarks unpublished prior to LLM pretraining (e.g., Gallstone, Infrared Thermography Temperature), indicating genuine generalization rather than memorization.
Key numerical highlights:
- Classification: Average AUC across 13 datasets (4–16 shots): 0.786–0.797, consistently outperforming all baselines except for isolated cases where TabPFN or FeatLLM match performance.
- Regression: Average NRMSE across 10 datasets (4–16 shots): 0.147–0.133, indicating reliable numerical estimation despite LLMs’ known limitations in arithmetic tasks.
ForestLLM’s superiority is most pronounced in the 4- and 8-shot regime, with robust gains attributed to its use of unlabeled data and semantic split criteria.
Effect of Unlabeled Data
An ablation experiment quantifies the unique impact of unlabeled data integration within the semantic-split framework. Removal of unlabeled data reduces both AUC (classification) and elevates NRMSE (regression), confirming that unlabeled samples regularize the choice of splits and mitigate overfitting. Classical forests remain insensitive to unlabeled data, and thus, are consistently inferior in few-shot contexts.
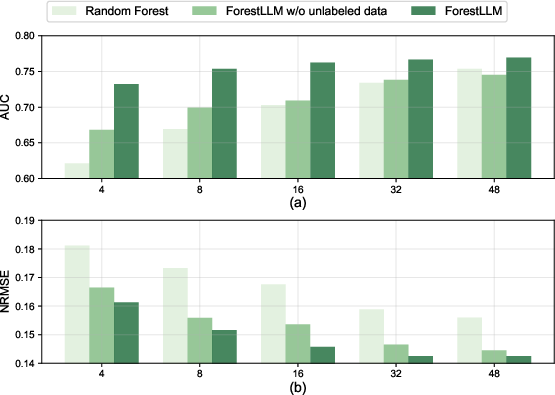
Figure 2: Ablation study: integrating unlabeled data consistently improves classification AUC and reduces regression NRMSE in few-shot conditions.
Hyperparameter Sensitivity
ForestLLM maintains performance stability across a spectrum of tree depths and ensemble sizes. Even shallow trees and ensembles as small as 5–11 estimators yield close-to-optimal results, especially when shot count is low, underscoring ForestLLM's low sensitivity to hyperparameter tuning in practice.
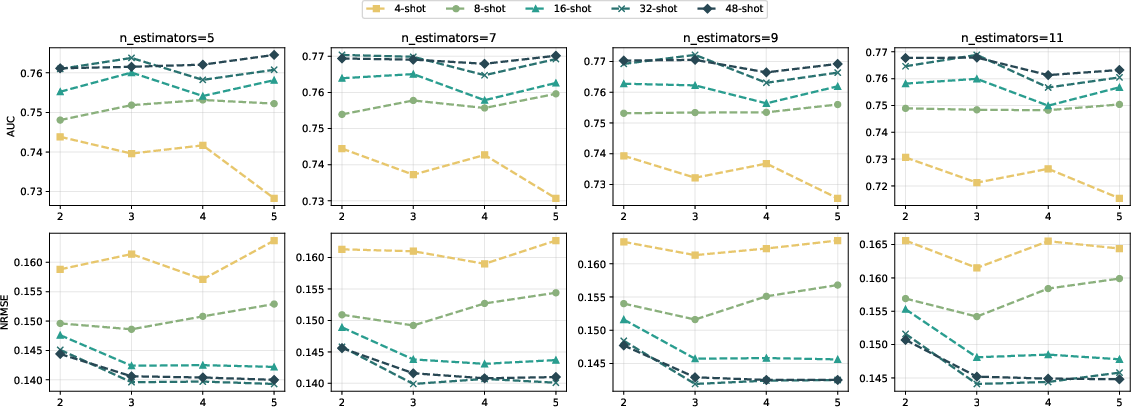
Figure 3: ForestLLM’s classification AUC and regression NRMSE are robust to max depth and ensemble size, especially from 16-shots onward.
Semantic Versus Statistical Splitting: Feature Importance Analysis
On Gallstone Disease prediction, ForestLLM selects splits oriented around upstream causal factors (e.g., hepatic fat, BMI, cholesterol), in contrast to vanilla random forests, which focus on downstream inflammation biomarkers (e.g., CRP, ALP, AST). This split-selection pattern illustrates how LLM-guided construction injects domain priors and causality awareness directly into forest structure—yielding interpretable, clinically meaningful models even in low-shot scenarios.
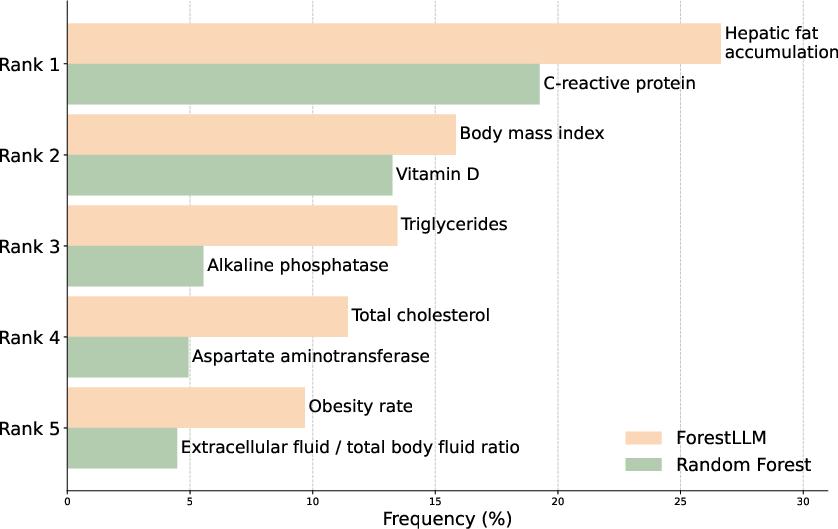
Figure 4: Top-5 split features: ForestLLM surfaces semantically and causally relevant variables, rather than mere correlates as in random forests.
Practical and Theoretical Implications
ForestLLM reframes LLMs not as inference-time oracles, but as knowledge-rich, offline architects. This has several direct implications:
- Efficiency: By offloading LLM usage entirely to training, ForestLLM eliminates the runtime bottleneck and operational cost intrinsic to prompt-based or serialization-based LLM predictors.
- Interpretability: ForestLLM produces human-aligned decision paths and split justifications, enhancing trust and auditability.
- Generalization: Semantic partitioning and rule induction robustly adapt to unseen datasets, unlike memorization-prone, fine-tuned LLMs or overfitting-prone conventional forests.
- Extensibility: The offline-architect paradigm can augment not only forests but potentially any structure-rich parametric model (e.g., rules-based systems, program synthesizers), opening avenues for LLM-driven, human-in-the-loop system design.
Future Directions
Potential directions emanate from this framework:
- Extension to continuous/discrete semi-supervised and domain-adaptive settings, further leveraging richer forms of unlabeled data.
- Exploration of other foundation models (e.g., vision-LLMs for multi-modal tabular data).
- Theoretical formalization of the entropy/variance reduction achievable with semantic splits vs. statistical ones, providing bounds under various label-unlabeled ratios.
Conclusion
ForestLLM provides an empirically validated, theoretically motivated instantiation of LLMs as architectural supervisors for few-shot tabular learning. By embedding prior knowledge during training rather than inference, and by operationalizing symbolic, law-like abstractions for split selection and leaf inference, ForestLLM delivers robust, interpretable, and label-efficient models which are both practical and adaptable to real-world, resource-constrained environments (2601.11311).

