Do explanations generalize across large reasoning models?
Abstract: Large reasoning models (LRMs) produce a textual chain of thought (CoT) in the process of solving a problem, which serves as a potentially powerful tool to understand the problem by surfacing a human-readable, natural-language explanation. However, it is unclear whether these explanations generalize, i.e. whether they capture general patterns about the underlying problem rather than patterns which are esoteric to the LRM. This is a crucial question in understanding or discovering new concepts, e.g. in AI for science. We study this generalization question by evaluating a specific notion of generalizability: whether explanations produced by one LRM induce the same behavior when given to other LRMs. We find that CoT explanations often exhibit this form of generalization (i.e. they increase consistency between LRMs) and that this increased generalization is correlated with human preference rankings and post-training with reinforcement learning. We further analyze the conditions under which explanations yield consistent answers and propose a straightforward, sentence-level ensembling strategy that improves consistency. Taken together, these results prescribe caution when using LRM explanations to yield new insights and outline a framework for characterizing LRM explanation generalization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of “Do explanations generalize across large reasoning models?”
Overview
This paper looks at how well the step-by-step explanations that AI models write (called “chain-of-thought,” or CoT) work for other AI models. The big idea: if one model explains how it solved a problem, will that explanation help a different model reach the same answer? If yes, the explanation might capture general ideas that aren’t tied to just one model’s quirks.
What questions were asked?
The authors focused on three simple questions:
- Do explanations from one model help other models reach the same conclusion?
- Are explanations that generalize across models also preferred by people?
- Does extra training (like reinforcement learning) make a model’s explanations more generalizable?
How did they study it?
To test these questions, the researchers compared different ways of giving models “thinking text” between special tags (like a model’s scratch work) before they answer.
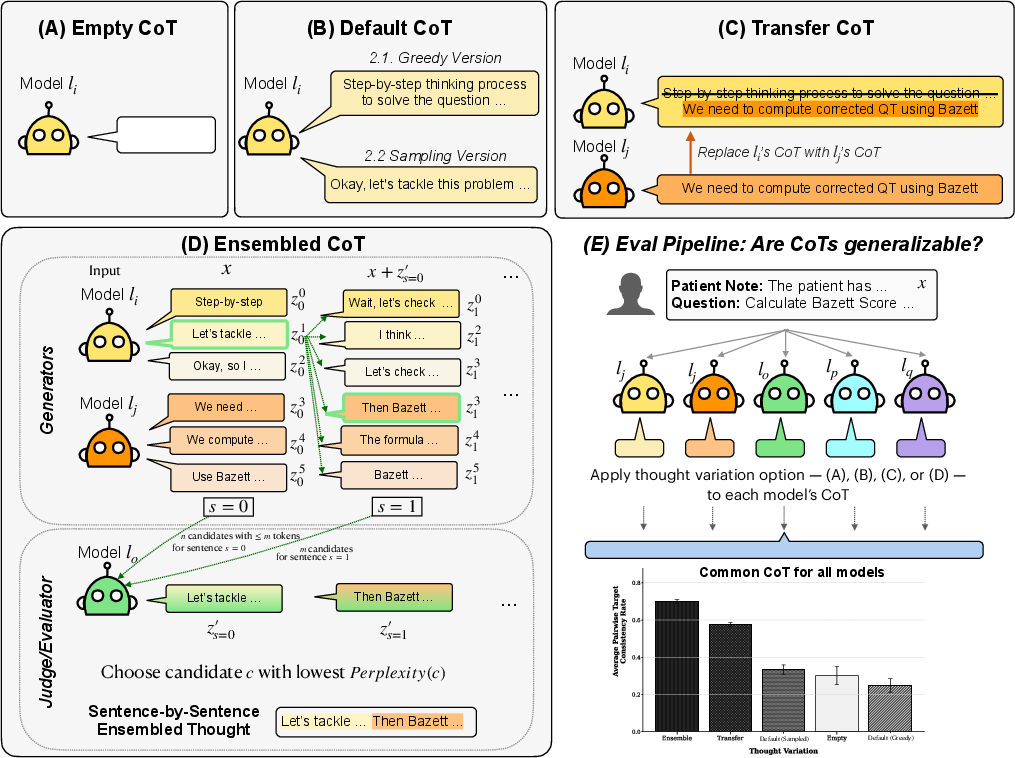
They tried four setups:
- Empty CoT: No reasoning text at all—just the problem.
- Default CoT: The model writes its own reasoning and then answers.
- Transfer CoT: The reasoning from Model A is copied into Model B before Model B answers.
- Ensembled CoT: Multiple models take turns suggesting one short sentence at a time. An “evaluator” model picks the sentence that seems to fit best (the least “surprising” to it). Think of it like a group of students proposing the next sentence in a solution, and a teacher choosing the clearest one. This repeats until the explanation is complete.
They checked two things to judge success:
- Accuracy: Does the answer match the correct solution?
- Consistency: Do different models give the same answer when given the same explanation?
To keep things fair, they removed any “the answer is …” lines from explanations so the reasoning couldn’t just reveal the final answer.
They tested on:
- A medical math benchmark (MedCalc-Bench), which asks models to compute clinical values from patient notes.
- An instruction-writing benchmark (Instruction Induction), where models must figure out the rule behind several examples and then write a clear instruction.
What did they find?
The key results are:
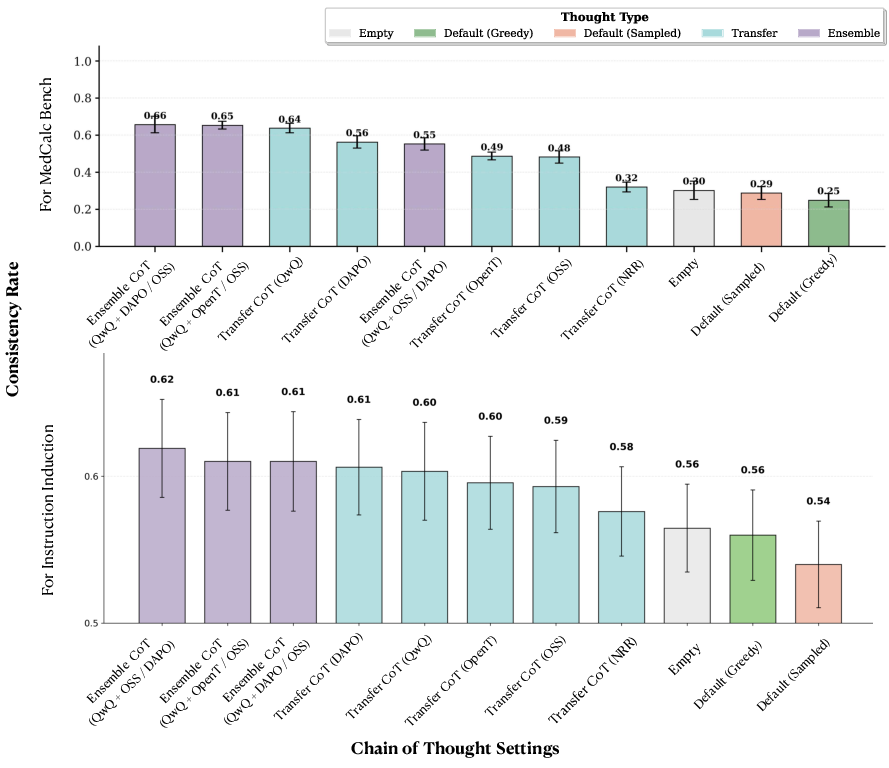
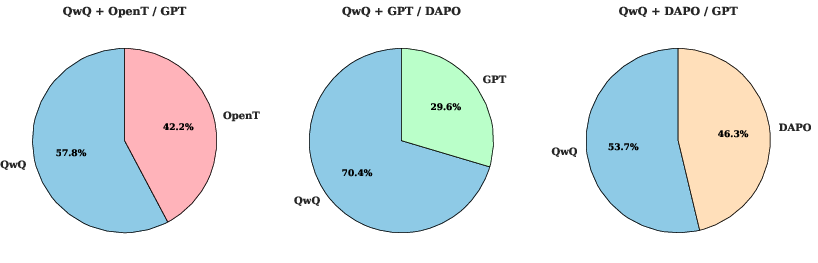
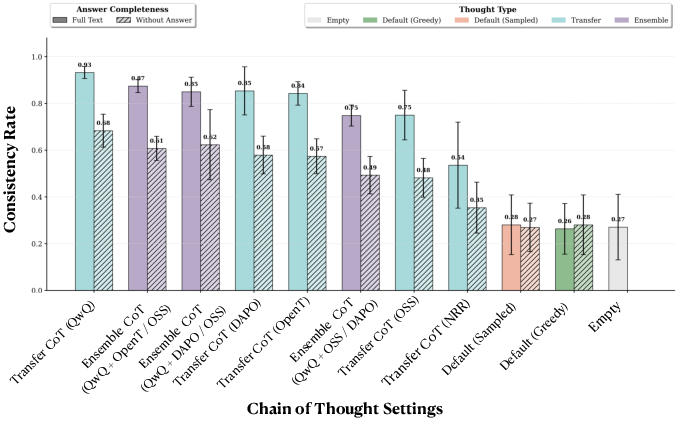
- Explanations make models agree more. Sharing CoTs across models made their answers line up much more often. For example, on the medical benchmark, consistency jumped from about 25% with no reasoning to about 66% with shared or ensembled reasoning. On the instruction benchmark, it also rose, from about 54% to 62%.
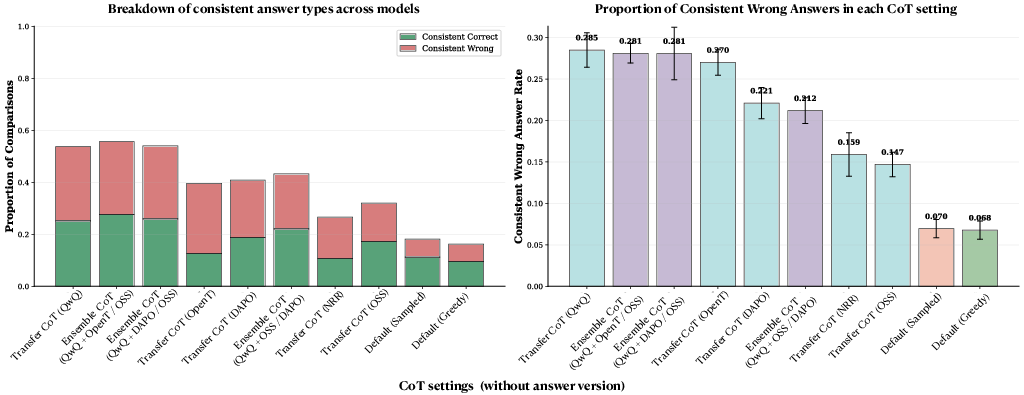
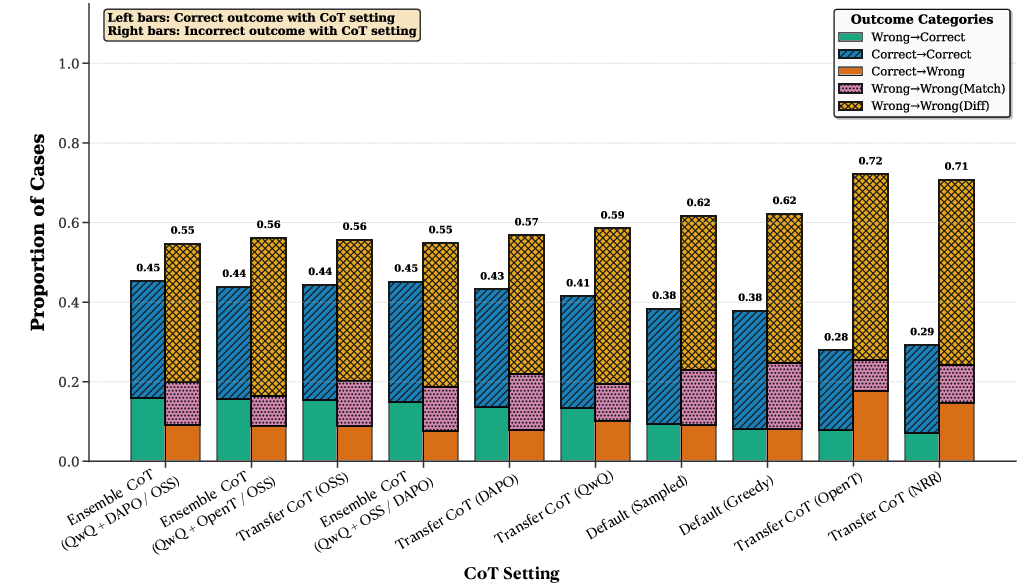
- Agreement isn’t always good—models can agree on the wrong answer. CoTs can steer different models to the same answer even if it’s incorrect. So explanations can spread both good and bad reasoning.
- The ensemble method helps. The sentence-by-sentence “group and judge” process usually produced explanations that boosted cross-model consistency more than other methods.
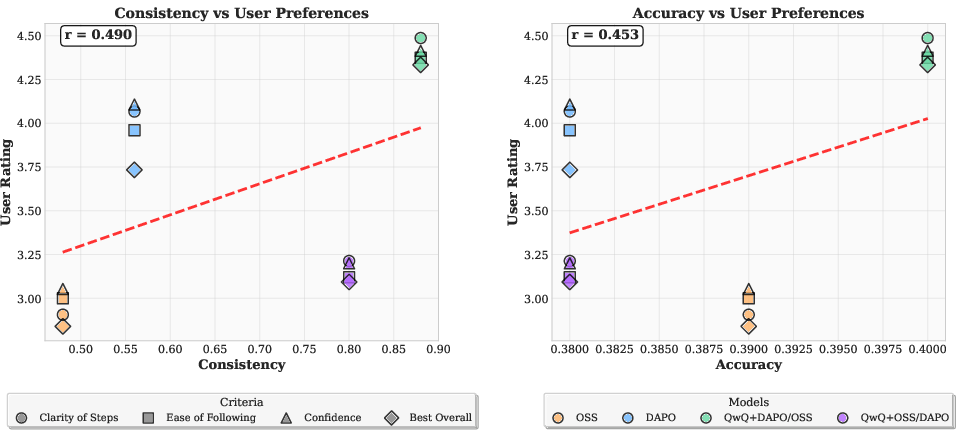
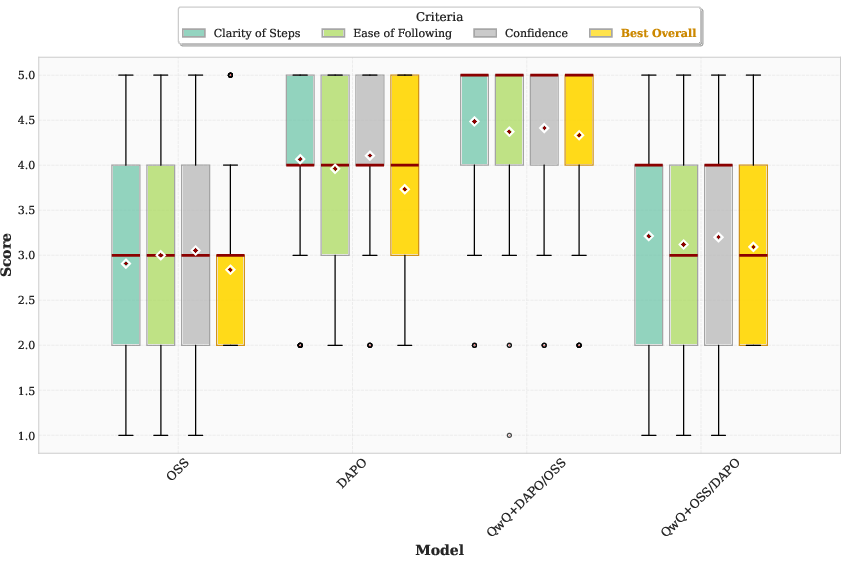
- People preferred more generalizable explanations. In a small user study, explanations that made models agree more were also rated clearer and easier to follow by human readers.
- Extra training changed explanations in helpful ways—but not always for accuracy. Models fine-tuned with reinforcement learning produced explanations that other models followed more consistently. However, this did not always raise how often those transferred explanations led to correct answers. In short: consistency and accuracy are related but not the same.
Why does this matter?
If we want AI to teach us or help in areas like science and medicine, we need explanations that capture real, reusable ideas—not just one model’s habits. This paper shows a way to measure that: see if other models can follow the explanation to reach the same conclusion. It also offers a practical trick (the sentence-level ensemble) to make explanations more broadly useful.
What does this mean for the future?
- Be careful: explanations can make multiple models confidently wrong. In sensitive areas like healthcare or law, that’s risky.
- Good signs for teaching and collaboration: explanations that generalize across models also seem clearer to people, which is promising for education and scientific discovery.
- Better training goals: since consistency and accuracy can split, future training should aim to improve both—so explanations are not just widely followed, but also correct.
- A reusable framework: testing explanations by how well they transfer across models gives researchers a scalable way to judge explanation quality, alongside human studies and checks for correctness.
In short, the paper argues that a “good explanation” should work like a solid set of class notes: it should guide different readers (or different models) to reason in the same way—and preferably to the right answer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that remain unresolved and could guide follow-up research:
- External validity across models
- The study uses a small set of mostly Qwen-derived/open models (1.5B–32B) and excludes frontier proprietary LRMs; it is unknown whether findings hold for larger, diverse architectures, training corpora, or inference-time “hidden thinking” implementations.
- Cross-family effects are not disentangled (e.g., Qwen-to-Qwen vs cross-architecture transfers); do shared pretraining/decoding conventions drive the observed consistency gains?
- Narrow task coverage and small evaluation sets
- Only two benchmarks are used (MedCalc-Bench: 100 sampled items; Instruction Induction: 100 items across 20 tasks, 12 authored by the paper’s team), limiting domain and distributional coverage.
- Missing settings: multi-step math proofs, code/algorithmic tasks with verifiable executors, long-context reasoning, tool-use, multi-turn dialogues, multimodal reasoning, and cross-lingual explanations.
- Definition and measurement of “generalization”
- Generalization is operationalized as cross-model answer consistency, not transfer accuracy or human task performance; it remains unclear when increased consistency reflects genuinely problem-level reasoning vs shared biases or anchoring effects.
- No formal link is established between the proposed behavioral generalization and standard generalization notions (e.g., invariances, distribution shift robustness, or information-theoretic criteria).
- Evaluation metrics and scoring fidelity
- Consistency is measured by pairwise answer matching; it is insensitive to calibration/uncertainty and can reward consistently wrong outcomes.
- Instruction Induction uses BERTScore, which may conflate surface similarity with semantic equivalence; no semantic-equivalence checks (e.g., equivalence testing, canonicalization, or human task-based validation).
- Removal of answer leakage from CoTs
- Explicit answer removal relies on an LLM (o4-mini) with no quantitative audit of leakage rates, paraphrasing side-effects, or residual cues (e.g., numeric templates) that might still steer models; no intercoder agreement or automated detection is reported.
- Prompting and think-tag confounds
- The approach assumes models honor think tags and specific formatting; no ablation across tag schemes, models without “think” training, or “no-think” baselines (i.e., truly absent hidden reasoning) to isolate formatting effects from semantic transfer.
- Ensemble method design and ablations
- The sentence-level ensemble uses an evaluator’s perplexity as the selection objective; there is no comparison to alternative selectors (e.g., truthfulness/verifiability scores, self-consistency, mutual information, diversity-constrained selection).
- Hyperparameters (number of generators, sentences, token cap, stopping criteria) and tokenizer effects on perplexity are fixed; no ablation quantifies sensitivity, compute–performance trade-offs, or robustness across evaluators.
- The method assumes access to evaluator logits (for perplexity), limiting applicability to closed APIs; practicality under real-world constraints is untested.
- Causal mechanisms and faithfulness
- It remains unknown whether models “use” the CoT steps causally vs being anchored by surface cues; no mechanistic or intervention-based tests (e.g., step shuffling, controlled ablations, counterfactual edits, numeric masking) are reported.
- CoT properties (length, structure, explicit assumptions, equation density, lexical markers) that predict transfer success/failure are not systematically analyzed.
- Safety and error propagation
- CoTs often increase consistency in wrong answers; there is no proposed diagnostic to detect misleading transferred CoTs or a mitigation strategy (e.g., disagreement-aware routing, verifier checks, uncertainty thresholds).
- No analysis quantifies when transfer improves accuracy vs induces harmful convergence, especially in high-stakes domains like medicine.
- RL post-training findings are under-specified
- Only two small base models and a single RL objective (RLVR/GRPO) on a single domain are tested; results may reflect overfitting and do not compare against SFT/DPO/best-of-n sampling or reward shaping for generalizable CoTs.
- No analysis of out-of-domain generalization after RL, stability across seeds, or whether optimizing for consistency conflicts with accuracy.
- Human study limitations
- Small N (15 participants), limited conditions (4 CoT types), and ratings of perceived clarity rather than task performance; external validity, power, and inter-rater reliability are unclear.
- No blinded evaluation of whether more “consistent” CoTs actually help humans solve the tasks or transfer skills (e.g., measured improvements in accuracy or time-on-task).
- Transfer granularity and scope
- The work transfers per-example CoTs; it is unknown whether higher-level, example-agnostic “concept CoTs” generalize across instances/tasks or across datasets.
- No tests of cross-domain transfer (e.g., CoTs from math applied to physics word problems) or temporal robustness across model/version updates.
- Answer-space and anchoring effects
- Consistency may be inflated by constrained answer spaces (e.g., numeric outputs) or by anchoring on numeric tokens/hints; no controlled masking or normalization to discount anchoring is attempted.
- Pairwise vs population dynamics
- Average pairwise consistency across five models may hide strong heterogeneity by pair; a full pairwise matrix analysis and clustering by compatibility are not presented.
- Practical costs and deployment
- Compute overhead and latency of the ensemble pipeline are not reported; there is no assessment of cost-effectiveness vs simpler methods (e.g., self-consistency, few-shot rationales, verification pipelines).
- Reproducibility and data risks
- The 12 new Instruction Induction tasks are author-created and unvalidated for difficulty, leakage, or ambiguity; third-party validation and release notes for provenance are not provided.
- MedCalc re-evaluation on the Verified subset is mentioned but not quantified; impact of label corrections on headline conclusions is not rigorously summarized.
- Robustness and adversarial settings
- The system is not tested against adversarial or misleading CoTs, prompt-injection within think tags, or targeted attacks intended to force consensus on incorrect conclusions.
- Format and language variation
- No exploration of cross-lingual CoT transfer, code-based or formal proof rationales, or how paraphrasing/format transformations affect transferability and correctness.
- Theoretical grounding
- There is no formal framework connecting CoT transferability to properties like sufficiency, minimality, or invariance; a theory for when/why CoTs should generalize across models is missing.
Glossary
- BERTScore: A semantic similarity metric that compares text using pretrained LLM embeddings rather than exact string match. Example: "We specify the scoring function I from \cref{eq:consistency} to be exact-matching for MedCalc-Bench and BERTScore~\citep{zhang2019bertscore} for Instruction Induction."
- Bonferroni correction: A multiple-comparisons adjustment that controls the familywise error rate by tightening significance thresholds. Example: "Independent t-tests with Bonferroni correction confirmed that OSS was rated significantly worse than both DAPO () and QwQ+DAPO/OSS () in terms of Clarity of Steps."
- Chain-of-Thought (CoT): A natural-language reasoning trace produced by a model that shows intermediate steps toward an answer. Example: "Large reasoning models (LRMs) produce a textual chain of thought (CoT) in the process of solving a problem,"
- Consistency: A metric capturing how often different models produce the same answer when given the same explanation. Example: "Consistency, which measures the match between answers from different models in a population of models when given the same explanation."
- Default CoT: The model’s own unmodified reasoning trace used to arrive at an answer. Example: "Default CoT (\cref{fig:overview}B): The standard setting used in prior benchmarks, where the think text is generated by the model without modification."
- End-of-thought token: A special token indicating that the model has completed its reasoning/explanation. Example: "This process repeats until one of the generator models outputs an end-of-thought token or the maximum chain length () is reached."
- Ensembled CoT: A reasoning trace constructed by aggregating and selecting among candidate sentences from multiple models. Example: "Ensembled Thoughts (\cref{fig:overview}D): The think text is replaced by explanations generated via Ensemble explanations."
- Exact-Match: An accuracy metric that requires the generated answer to match the ground-truth string exactly. Example: "MedCalc-Bench (Exact-Match)"
- Faithfulness: The extent to which an explanation reflects the model’s true internal decision process. Example: "Hence, in this paper, we examine a different property that is related to faithfulness: we investigate the generalization of reasoning traces across different LRMs."
- Generator–evaluator loop: An iterative procedure where generator models propose candidate reasoning sentences and an evaluator selects among them. Example: "A generatorâevaluator loop."
- Greedy decoding: A deterministic decoding method that selects the highest-probability token at each step. Example: "(2.1) uses greedy decoding, while (2.2) uses nucleus sampling."
- GRPO: A reinforcement learning fine-tuning method (preference-based policy optimization) applied to improve model behavior. Example: "Effect of GRPO training on consistency and accuracy."
- HuggingFace Transformers: A widely used library for training and running transformer-based LLMs. Example: "using the HuggingFace Transformers library \citep{wolf-etal-2020-transformers}"
- Instruction Induction: A benchmark where models infer a natural-language instruction from example input–output pairs. Example: "Second, we study Instruction Induction~\citep{honovich2022instruction}, which evaluates general reasoning capabilities."
- MedCalc-Bench: A benchmark for medical calculation and clinical reasoning tasks. Example: "First, we use MedCalc-Bench~\citep{khandekar2024medcalc}, which targets medical domain-specific reasoning."
- Nucleus sampling: A stochastic decoding method that samples from the smallest set of tokens whose cumulative probability exceeds a threshold (top-p). Example: "(2.1) uses greedy decoding, while (2.2) uses nucleus sampling."
- Perplexity: A measure of how “surprised” a model is by text; lower perplexity indicates text the model finds more probable. Example: "These are scored by the evaluator, and the least surprising candidate (lowest perplexity) is appended to the growing ensembled thought."
- Reinforcement learning (RL): A training paradigm where models are optimized using reward signals to improve behavior or reasoning quality. Example: "Second, we evaluate the relationship between cross-model consistency and post-training with reinforcement learning (RL), and find that RL post-training yields CoTs that are more consistent with other LRMs."
- RLVR: A reinforcement learning setup that relies on verifiable reward signals specific to the task. Example: "We follow the RLVR-only setup and hyperparameters described for this dataset in~\citep{lin2025trainingllmsehrbasedreasoning}."
- Self-consistency: Agreement of a single model’s answers across multiple runs or decoding strategies. Example: "Model self-consistency rates for CoT generation on MedCalc-Bench."
- Sentence-level ensembling: Combining candidate reasoning sentences step-by-step to build a more generalizable explanation. Example: "propose a straightforward, sentence-level ensembling strategy that improves consistency."
- Transfer CoT: Providing the reasoning trace produced by one model to another model to guide its answer. Example: "(C) Transfer CoT. Reasoning from one model is directly transferred to another, replacing its own."
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s findings on cross-model chain-of-thought (CoT) generalization, sentence-level ensembling, and the link between consistency and human preference.
- Reliability middleware for LLM products via CoT transfer/ensembling
- Sectors: healthcare, finance, customer support, education, software.
- What: Insert a “consensus rationale” layer that (a) injects Transfer CoT from a stronger model into target models, or (b) runs the proposed sentence-level Ensembled CoT (generator–evaluator loop) to stabilize answers across model variants.
- Tools/Workflows: microservice that accepts a prompt, queries multiple LRMs for candidate thought sentences, uses a designated evaluator to pick least-surprising sentences, and returns a consolidated CoT + final answer; configurable to strip explicit answers from the CoT before reuse.
- Assumptions/Dependencies: access to multiple LRMs; cost and latency budget for multi-model calls; standardized think tags; licenses permitting reuse/transfer of CoTs; guardrails to detect/mitigate “consistently wrong” convergence; domain-specific evaluation functions.
- Human-facing explanation selection using consistency as a quality signal
- Sectors: education/tutoring, customer support, developer tools/documentation.
- What: Rank and surface CoTs with higher cross-model consistency as more understandable, aligning with the paper’s user study indicating that consistency correlates with human preference.
- Tools/Workflows: an “explanation ranker” that scores candidate CoTs by cross-model consistency before showing them to users; A/B testing to monitor UX impact.
- Assumptions/Dependencies: the consistency–preference link is correlational (sample size limited); must jointly track accuracy to avoid promoting clear but wrong explanations.
- Model governance and audit: cross-model CoT generalization as a compliance check
- Sectors: policy/risk, finance, healthcare.
- What: Add a test suite that logs CoTs and quantifies cross-model consistency and transfer accuracy as part of model validation, change management, and external audits.
- Tools/Workflows: automated reports summarizing consistency/accuracy across a panel of LRMs; “drift” alerts when CoT generalization degrades after updates.
- Assumptions/Dependencies: storage and privacy controls for CoTs; legal/IP constraints on sharing rationale text; clear thresholds for acceptable consistency.
- Training pipeline add-ons to encourage generalizable CoTs
- Sectors: AI model vendors, research labs.
- What: Incorporate RL post-training or selection criteria that favor CoTs with higher cross-model consistency (as observed improvements after RL) while monitoring transfer accuracy.
- Tools/Workflows: training callbacks that compute consistency across a small evaluator panel; curriculum or rejection-sampling to prefer generalizable CoTs; distillation from ensembled CoTs.
- Assumptions/Dependencies: additional compute; careful reward design to avoid overfitting to “agreement” at the expense of accuracy or diversity.
- Prompting patterns that scaffold weaker/cheaper models
- Sectors: software, edge/embedded deployment, contact centers.
- What: Provide CoT scaffolds generated by stronger models to steer smaller models toward more stable outputs (Transfer CoT).
- Tools/Workflows: prompt templates with think tags containing vetted CoTs; routing that selects the source model by domain/task.
- Assumptions/Dependencies: context-window constraints; licensing for CoT reuse; domain mismatch may mislead.
- Multi-agent coordination via shared CoTs
- Sectors: agent platforms, operations tooling.
- What: Synchronize agent behavior by sharing a consensus CoT plan; use sentence-level ensembling to iteratively build a plan accepted by heterogeneous agents.
- Tools/Workflows: planner agent (ensemble generator) + judge agent (evaluator) loop; plan dissemination to worker agents.
- Assumptions/Dependencies: orchestration layer; latency budgets; monitoring to prevent “herding” to wrong plans.
- Higher-quality synthetic data and instructions with ensemble CoTs
- Sectors: academia, edtech, data vendors.
- What: Use ensemble CoTs to generate clearer task descriptions (e.g., instruction-induction), rationales, and exemplars for data augmentation.
- Tools/Workflows: data generation pipelines that filter/score candidate rationales by cross-model consistency and BERTScore/exact-match metrics.
- Assumptions/Dependencies: verifier metrics must reflect downstream goals; risk of propagating shared model biases.
- Clinical calculators and decision-support “consensus steps”
- Sectors: healthcare.
- What: For EHR-integrated calculators (MedCalc-style), show an ensembled step-by-step rationale and a consensus answer; flag disagreements for clinician review.
- Tools/Workflows: EHR plug-ins that render rationale traces and uncertainty indicators (agreement vs. disagreement).
- Assumptions/Dependencies: clinical validation, HIPAA compliance, human-in-the-loop sign-off; explicit handling of consistent-but-wrong failure modes.
- Operational triage with consistent rationales
- Sectors: IT ops, trust & safety, legal ops.
- What: Use cross-model consistent rationales to speed incident triage and create reproducible case notes.
- Tools/Workflows: ticketing integrations that attach consensus CoTs; searchable rationale logs.
- Assumptions/Dependencies: quality controls to avoid spurious consensus; secure logging.
- Personal assistant “consensus mode”
- Sectors: daily life.
- What: For budgeting, scheduling, and study plans, generate an ensemble rationale to improve clarity and confidence.
- Tools/Workflows: toggle in consumer assistants to use a compact two-model ensemble with an on-device evaluator (when feasible).
- Assumptions/Dependencies: privacy and cost; local model quality and resource limits.
Long-Term Applications
These opportunities become practical as methods and standards mature, accuracy improves, and costs drop.
- Standards and certification for “generalizable explanations”
- Sectors: policy/regulatory, procurement.
- What: Define and adopt certification protocols requiring minimum cross-model consistency and transfer accuracy for safety-critical deployments.
- Tools/Workflows: accredited test suites; public scorecards covering consistency vs. accuracy trade-offs.
- Assumptions/Dependencies: consensus among standards bodies; robust, adversarial benchmarks; sector-specific thresholds.
- Oversight networks: watcher models monitoring actor models’ CoTs
- Sectors: AI safety, platform integrity.
- What: Independent LRMs continuously evaluate actor models’ CoTs for idiosyncratic or deceptive reasoning patterns (low generalization), triggering review.
- Tools/Workflows: red-teaming by disagreement; “explanation anomaly detection” dashboards.
- Assumptions/Dependencies: reliable access to CoTs; defenses against collusion or shared blind spots; privacy and IP policies.
- AI-for-science hypothesis transfer and knowledge discovery
- Sectors: academia, pharmaceuticals, materials science.
- What: Extract CoTs that generalize across LRMs as candidate mechanistic explanations or hypotheses; use ensembles to distill model-agnostic patterns before human or lab validation.
- Tools/Workflows: “hypothesis notebooks” that track cross-model consistency, provenance, and experimental outcomes.
- Assumptions/Dependencies: high domain accuracy; strong verification loops; expert oversight.
- Interoperability protocols for explanation exchange
- Sectors: software, standards bodies.
- What: Common CoT schema (think tags, sentence boundaries, end-of-thought tokens), plus APIs for perplexity-based evaluation and sentence-level ensembling.
- Tools/Workflows: open-source libraries and registries for CoT exchange; telemetry for cross-vendor ensembles.
- Assumptions/Dependencies: vendor buy-in; security and redaction standards for sensitive rationales.
- Robust ensemble planning for robotics/autonomy
- Sectors: robotics, automotive, drones.
- What: Use cross-model validated CoT plans with fallback strategies; require consistency across onboard/offboard models before execution.
- Tools/Workflows: real-time evaluators optimized for low-latency perplexity scoring; safety cases including CoT logs.
- Assumptions/Dependencies: tight compute/latency budgets; integration with formal verification; extensive simulation.
- Scalable education systems built on vetted CoTs
- Sectors: education, testing.
- What: Curriculum, hints, and grading rubrics derived from CoTs that generalize across models, improving clarity and fairness in feedback.
- Tools/Workflows: pipelines to generate multi-step explanations with cross-model vetting; learner modeling that adapts CoTs to proficiency.
- Assumptions/Dependencies: pedagogical validation; mitigation of bias; accessibility considerations.
- Liability, insurance, and forensics based on CoT reproducibility
- Sectors: insurance, legal, governance.
- What: Mandate logging and cross-model reproducibility of CoTs for incident analysis and underwriting; leverage consistency as evidence of due diligence.
- Tools/Workflows: tamper-evident rationale logs; replay harnesses to reproduce decisions across an approved model set.
- Assumptions/Dependencies: legal frameworks recognizing explanation audits; secure retention practices.
- Hardware/software co-design for ensemble reasoning
- Sectors: semiconductors, cloud.
- What: Accelerators and runtimes optimized for sentence-level ensembling (fast candidate generation + perplexity evaluation).
- Tools/Workflows: batched multi-model inference; specialized kernels for token-level scoring.
- Assumptions/Dependencies: sufficient demand; standardization of evaluator APIs.
- Marketplaces for reusable, vetted CoTs (“reasoning playbooks”)
- Sectors: software, professional services.
- What: Domain-specific, generalizable CoT libraries for tasks like financial analysis, clinical risk scoring, or compliance checks, licensed and versioned.
- Tools/Workflows: retrieval-augmented agents that pull playbooks; provenance and update channels.
- Assumptions/Dependencies: IP ownership and attribution norms; continual revalidation as models evolve.
- New training objectives that optimize transfer-consistency and transfer-accuracy jointly
- Sectors: AI research and development.
- What: RL and contrastive objectives that explicitly reward generalizable reasoning, with penalties for consistent-but-wrong convergence.
- Tools/Workflows: multi-model training harnesses; validation on diverse evaluator panels and domains.
- Assumptions/Dependencies: curated tasks with faithful scoring; compute budgets; careful balance to preserve creativity and diversity.
Notes on feasibility and risk across applications:
- Consistency can increase even when the final answer is wrong; deploy with accuracy checks, uncertainty flags, and human oversight in high-stakes domains.
- Dependencies include access to multiple heterogeneous LRMs, clear licensing for CoT reuse, standardization of think-tag formats, and evaluation metrics appropriate to the domain.
- Latency/cost of multi-model ensembling must be managed via caching, selective routing, or lightweight evaluators.
Collections
Sign up for free to add this paper to one or more collections.