- The paper introduces DevBench, a benchmark that reflects real developer telemetry and overcomes static benchmark limitations.
- It evaluates nine state-of-the-art models across six programming languages using metrics such as Pass@1, cosine similarity, and LLM-judge assessments.
- The findings reveal trade-offs between functional correctness and output quality, offering actionable insights for advancing code generation models.
Introduction
The emergence of LLMs has revolutionized software development through advanced code generation capabilities. "DevBench: A Realistic, Developer-Informed Benchmark for Code Generation Models" (2601.11895) proposes a novel benchmarking framework specifically designed to evaluate LLMs in code generation tasks with a high degree of realism. This paper introduces DevBench, which focuses on realistic tasks derived from real developer telemetry to address limitations of existing benchmarks that often rely on static rule-based generation.
Benchmark Design
DevBench comprises 1,800 evaluation instances spanning six programming languages (Python, JavaScript, TypeScript, Java, C++, and C#) and six task categories grounded in over one billion developer code completion interactions. These categories include API usage, code purpose understanding, Code-to-Natural Language (NL) transformations, low context completions, pattern matching, and syntax completion. By basing tasks on observed developer behavior and expert review, DevBench ensures ecological validity and contamination resistance.
Evaluation Metrics
The benchmark employs a multi-pronged evaluation strategy combining functional correctness, similarity-based metrics, and LLM-judge assessments. Functional correctness is measured using Pass@1 with multiple samples, while Average Cosine Similarity and Line 0 Exact Match Rate provide semantic and syntactic similarity insights, respectively. An LLM-based judge evaluates output quality in terms of relevance and helpfulness.
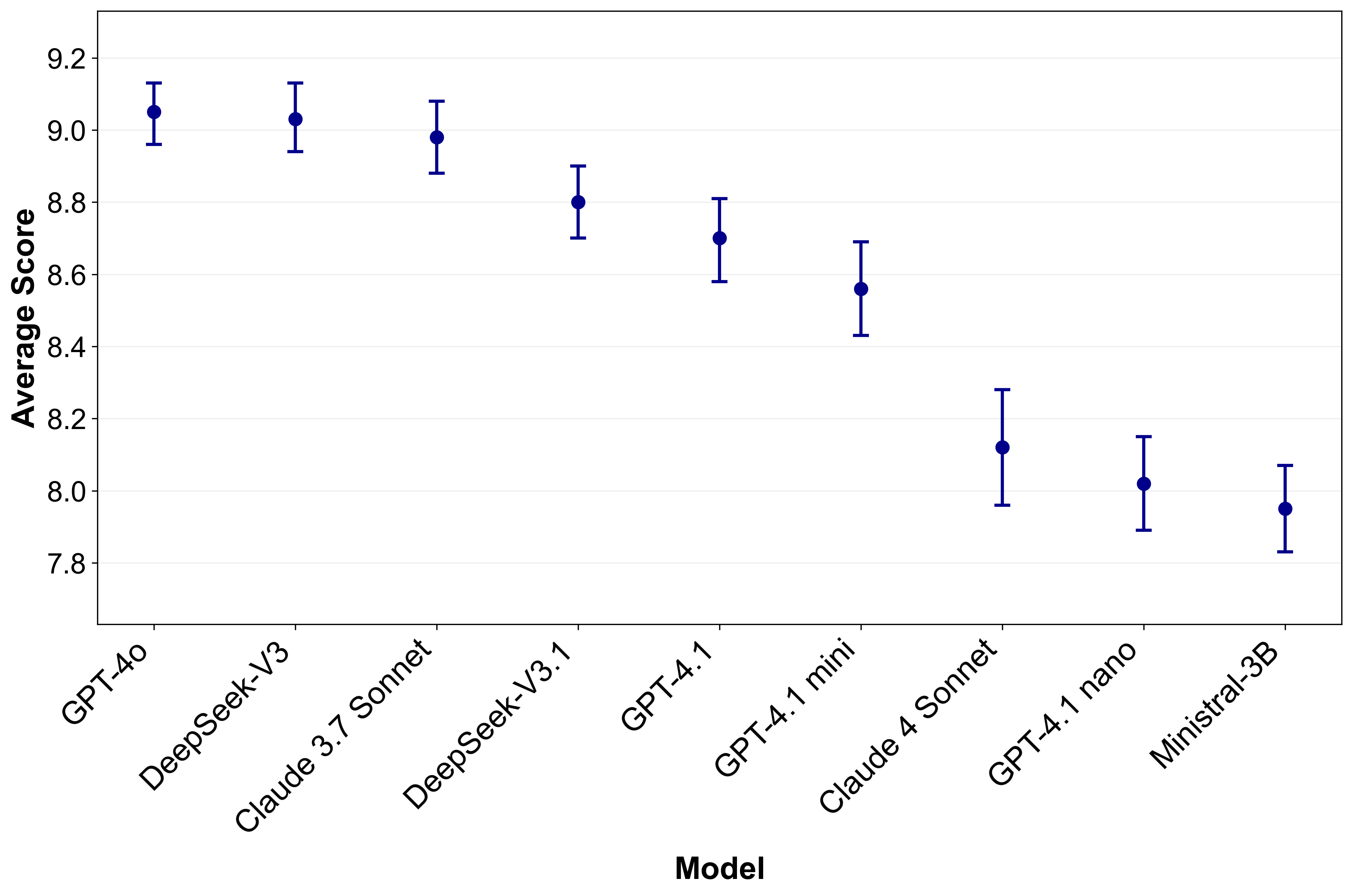
Figure 1: Overall LLM-judge evaluation scores with 95\% confidence intervals.
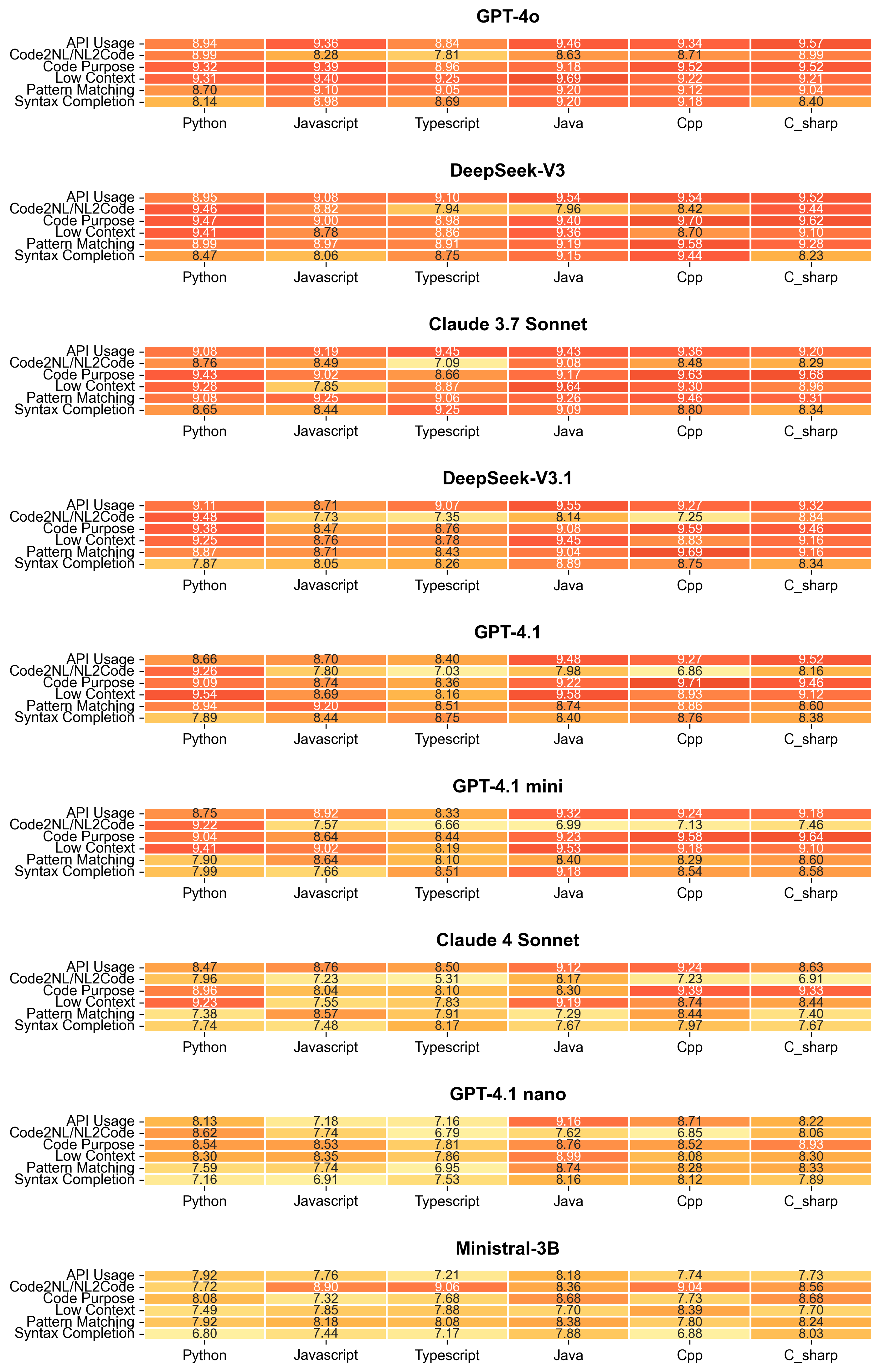
Figure 2: Breakdown of LLM-judge scores across models.
Experimental Results
The evaluation of nine state-of-the-art models highlights significant performance variations across task categories and languages. Top-performing models demonstrate strengths in handling low context completions, while bidirectional NL-Code transformations remain challenging. Notably, the results reveal different rankings when considering functional correctness versus quality judgments, highlighting the importance of multi-faceted evaluation.
Implications and Future Developments
DevBench provides a robust foundation for guiding model selection and improvement, offering insights often missing in other benchmarks. It supports practical deployment considerations and targeted model development. Future research directions include extending benchmark coverage to additional languages and development tasks, optimizing resource efficiency, and advancing fairness and inclusivity in model evaluation.
Conclusion
DevBench represents a significant advancement in realistic code generation evaluation, enabling nuanced understanding and accountable assessment of LLMs. By aligning closely with real-world developer interactions and providing detailed diagnostic capabilities, DevBench sets the stage for future innovations in code generation models and their applications in software development.
This work underscores the need for continuous research to enhance evaluation frameworks, address broader impacts, and encourage community engagement for collaborative model development and assessment.


