- The paper establishes exponential bounds on the probability of trivial centralizers in random matrix ensembles arising from discretized Schrödinger operators.
- It presents rigorous theoretical guarantees linking matrix diversity to enhanced in-context learning generalization in transformer models.
- Numerical experiments validate that increased system dimensionality boosts diversity, ensuring robust performance across in- and out-of-domain tasks.
Diversity in Random Matrix Ensembles and Implications for In-Context Learning of Schrödinger Operators
Problem Definition and Motivations
This work rigorously investigates the diversity properties of sets of random matrices arising from spatial discretizations of linear Schrödinger operators. The central algebraic object of interest is the centralizer of a set A={A(1),…,A(N)}: the set of all matrices commuting with every element of A. The diversity problem seeks to quantify, for a given distribution P and sample size N, the probability that the centralizer reduces to scalars—i.e., is trivial.
Motivation arises from recent theoretical analyses of transformer-based in-context learning for structured scientific tasks. In particular, when transformers are trained to solve families of linear systems (e.g., those stemming from PDEs), their generalization ability crucially depends on the algebraic diversity of the training set: if the training matrices have nontrivial centralizer, learned representations may encode only the shared structure, hindering out-of-distribution generalization to new operators (Cole et al., 2024).
Main Theoretical Contributions
The authors provide strong exponential bounds for the probability that the centralizer of a random sample of matrices is trivial, under explicit conditions on the matrix ensemble. The main results are as follows:
- Augmented Diversity (Theorem 1): For ensembles of the form A=K+V, where K is symmetric with simple spectrum and V is a random matrix, the centralizer of {A(1),…,A(N),K} is trivial with probability at least 1−(d−1)cN, for c<1 depending on the distribution of off-diagonal entries.
- Vanilla Diversity (Theorem 2): For ensembles where the random part V is diagonal with i.i.d. entries and K has a dense off-diagonal pattern (relative to a permutation), the centralizer of N i.i.d. samples is trivial with probability at least 1−d(d−1)cVN/2, with cV<1 determined by the atom probabilities in the distribution.
- Applications to Discretized Schrödinger Operators: The authors instantiate these distributions with realistic examples arising from numerical PDEs—specifically, finite difference and finite element discretizations of the Schrödinger operator with random, spatially uncorrelated potentials. They show that the theoretical guarantees apply in these cases, demonstrating that ensembles from physical models satisfy strong diversity under very weak assumptions.
Transferability in Transformer-Based In-Context Learning
Recent theoretical breakthroughs tie the generalization of transformer-based meta-learners to matrix diversity. Specifically, if the set of training task matrices A has trivial centralizer, then with high probability, the learned transformer adapts to arbitrary new linear systems, not just those sharing spectral or algebraic features with the training distribution (Cole et al., 2024). The presented results thus provide rigorous sample complexity and distributional conditions ensuring strong in-context generalization for learned solvers of parametric PDEs.
Empirical Validation and Numerical Behavior
The authors corroborate their analytical bounds with comprehensive experiments on discrete Schrödinger ensembles in one and two dimensions:
- Centralizer Triviality Probability:
Probabilistic checks on centralizer triviality (via rank computations) confirm rapid concentration to one as N increases, consistent with exponential convergence in the theoretical bounds.
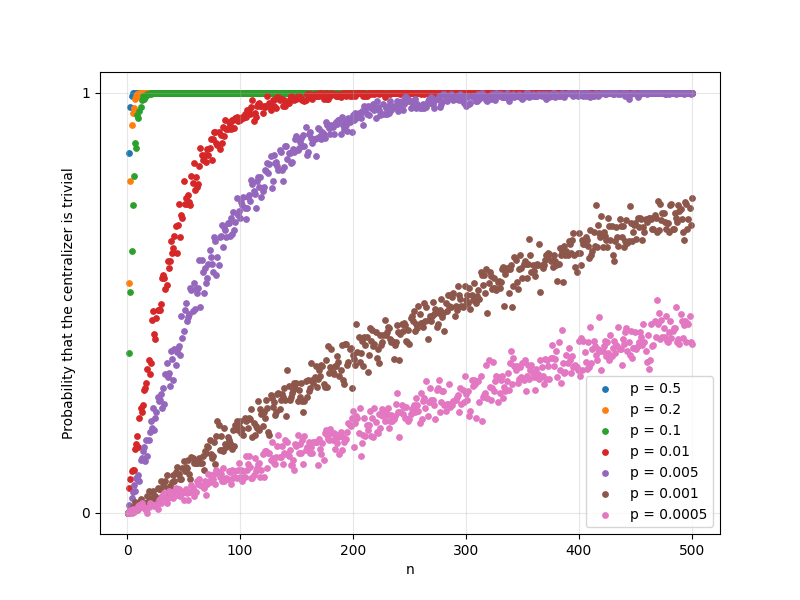
Figure 1: The probability that a 1D discrete Schrödinger operator sample set has trivial centralizer rises sharply with N, with dependence on the Bernoulli parameter p.
- In-Domain Generalization:
For transformer architectures trained and tested on the same operator distribution and discretization, the prediction error decays as O(m−1) in the prompt length m.
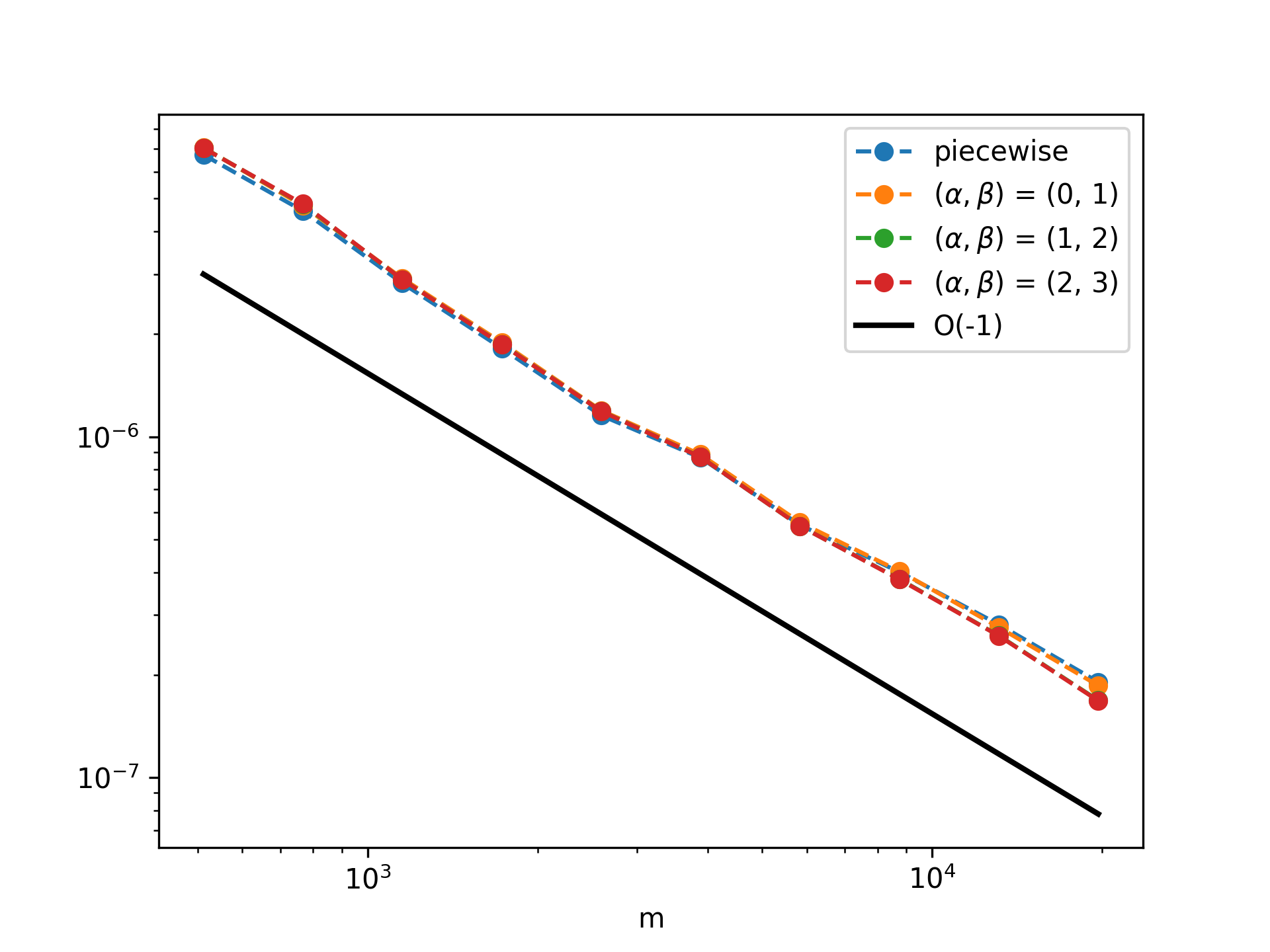
Figure 2: In-domain test MSE (decaying as O(m−1)) for various potential distributions in 1D.
- Out-of-Domain Generalization:
Strong out-of-distribution generalization is retained: models trained with one discretization or potential distribution perform with minimal degradation when tested on shifted distributions or alternate numerical discretizations, as long as training diversity is sufficient.
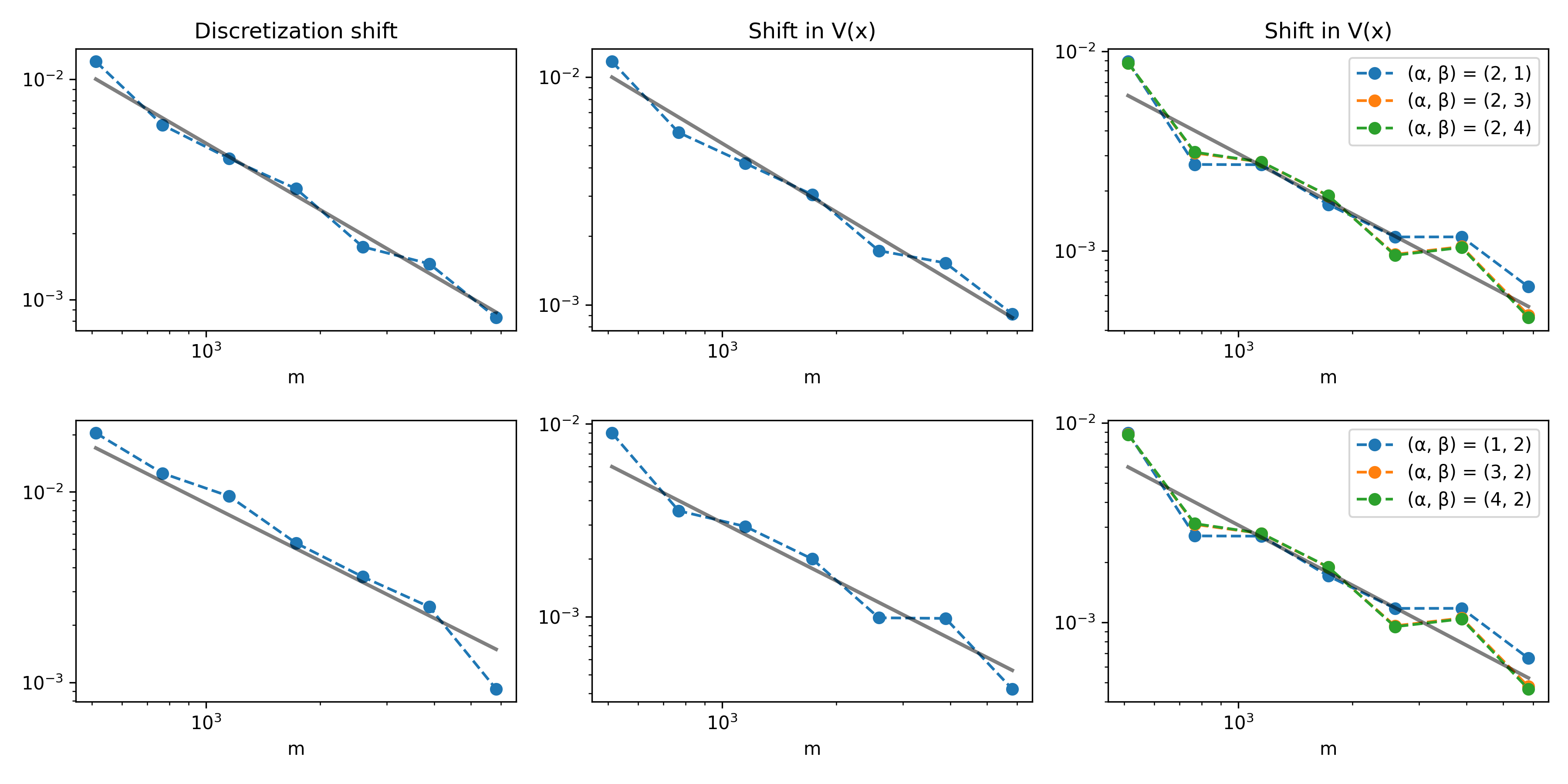
Figure 3: Out-of-domain error curves (also scaling as O(m−1)) for prompt distribution and discretization mismatches in 1D.
Analogous patterns are observed in two dimensions.
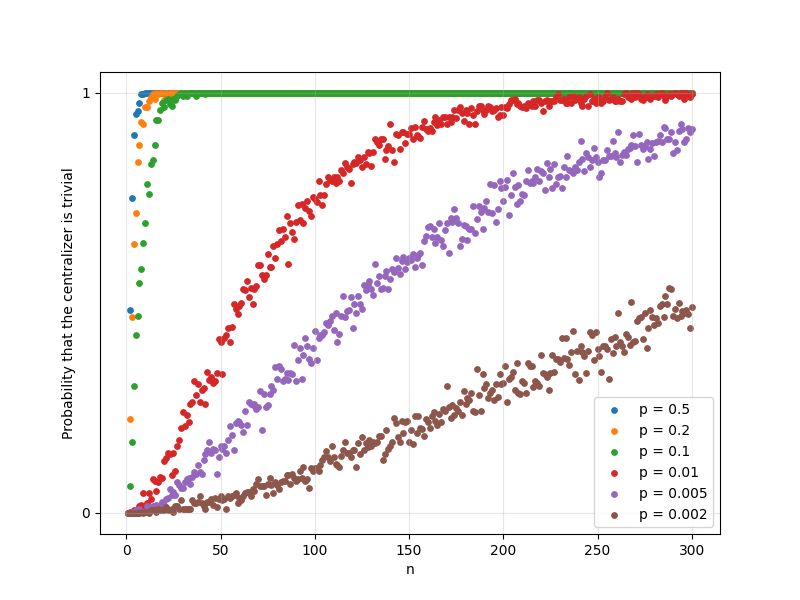
Figure 4: Probability of trivial centralizer for 2D discrete Schrödinger samples as function of N and p.
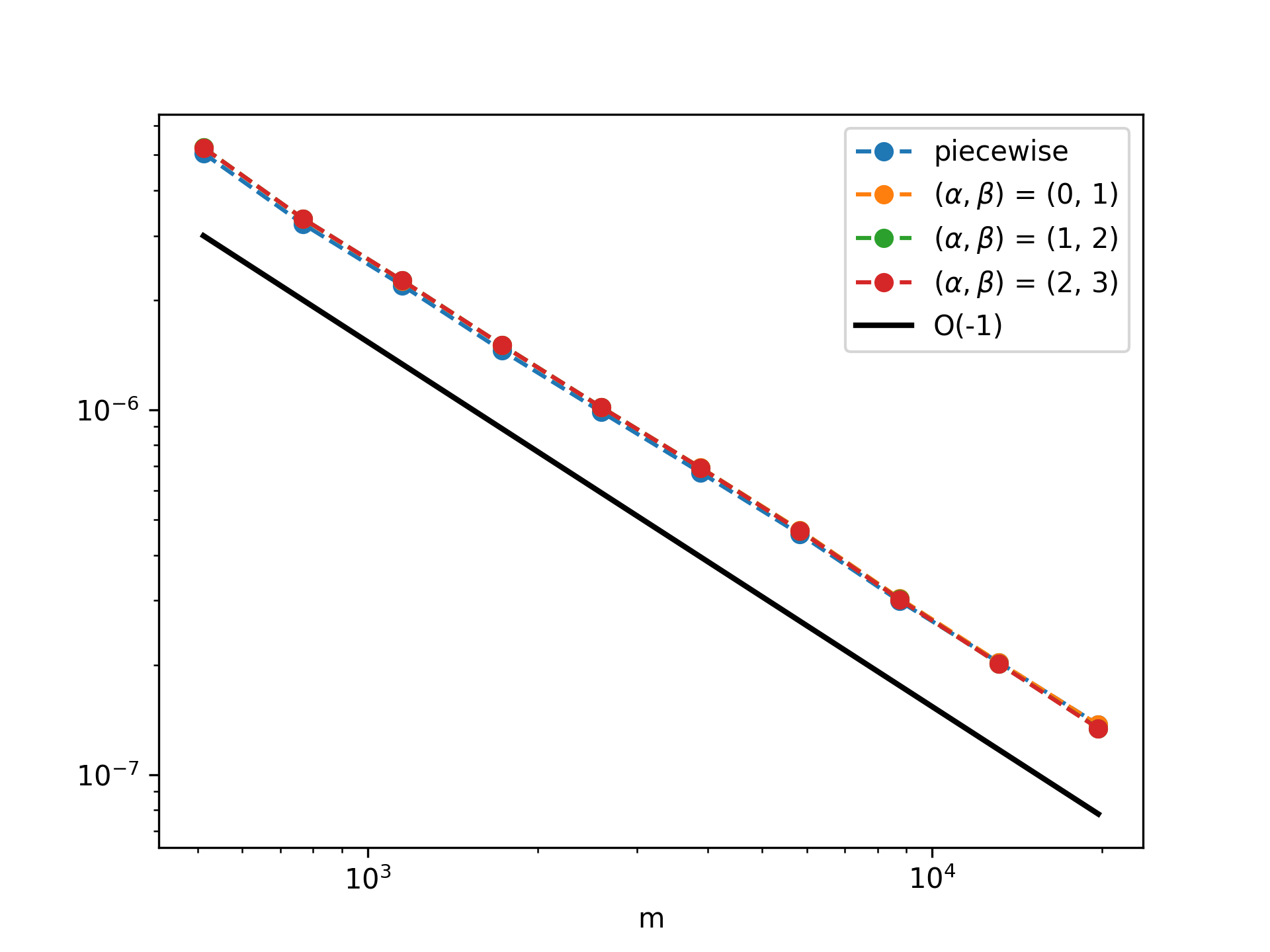
Figure 5: In-domain MSE decay in 2D for diverse potential distributions and prompt lengths.
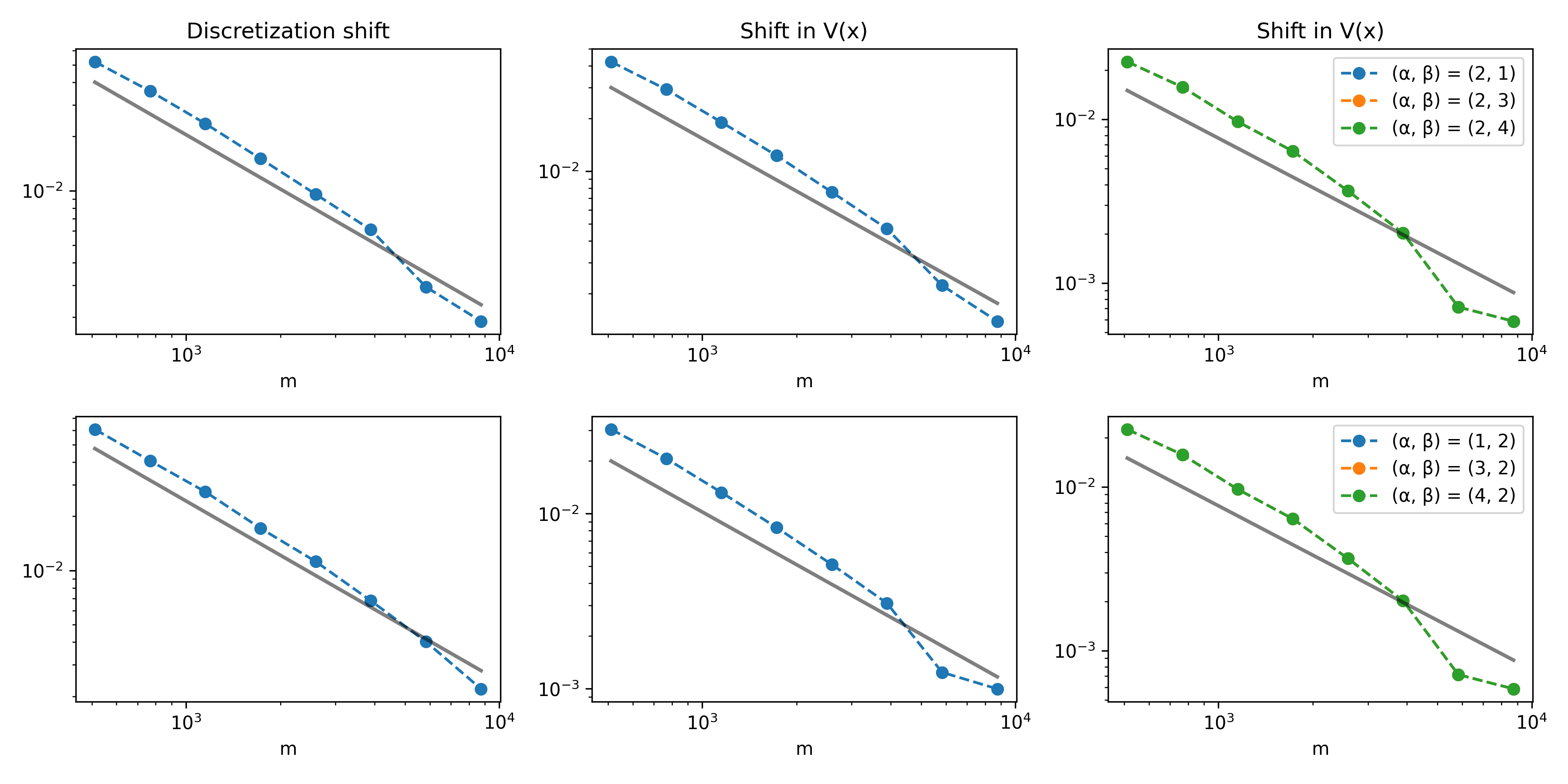
Figure 6: Out-of-domain error decay in 2D for various train/test distribution/configuration pairs.
Quantitative Bounds and Blessing of Dimensionality
A notable quantitative observation is the “blessing of dimensionality”: the probability that the sample centralizer is trivial increases as the system size (spatial discretization granularity) grows. This is due to increased disorder and non-commensurability in higher-dimensional random Schrödinger ensembles, which is reflected in tighter theoretical exponential bounds for large M.
Implications and Future Directions
The results provide robust algebraic guarantees for the transferability of transformer-based architectures across families of parametric PDEs in operator learning settings. The established exponential sample complexity bounds give theoretical underpinning to the empirical success of large meta-learning models in scientific machine learning, offering practical guidelines for data curation and model pretraining—especially in high-dimensional operator estimation.
These findings suggest several impactful future directions:
- Extension to broader operator families (e.g., variable diffusion, time-dependence, non-symmetric forms).
- Tighter dimension dependence in finite-sample diversity rates.
- Applications in representation theory of operator algebras and the design of new randomized ensembles for meta-learning.
Conclusion
This paper establishes a rigorous algebraic and probabilistic foundation for diversity in random matrix ensembles and demonstrates its crucial role in the generalization behavior of in-context learning models for PDEs. The combination of sharp probabilistic bounds, direct application to discretized Schrödinger operators, and validation via numerical experiments offers a substantial step towards principled meta-learning for scientific computing and operator regression.