- The paper presents a hybrid framework that combines LLM-generated causal hypotheses with statistical verification, enhancing causal discovery.
- The methodology employs hybrid initialization, collaborative verification, and iterative optimization using BIC to refine causal graphs.
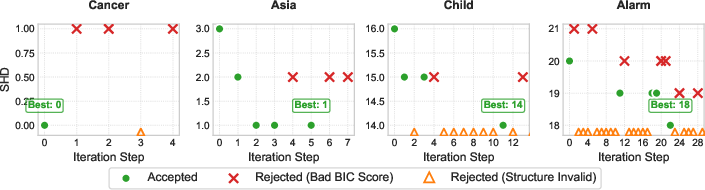
- Experimental results on datasets like Cancer and Alarm demonstrate significant accuracy gains, reduced SHD, and robust error mitigation.
CauScientist: Integrating LLMs with Statistical Methods for Causal Discovery
Introduction
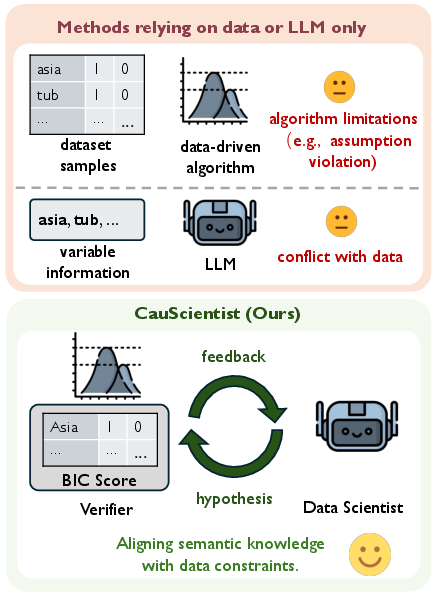
The paper "CauScientist: Teaching LLMs to Respect Data for Causal Discovery" (2601.13614) addresses the challenging task of causal discovery, which is vital for scientific research and reliable decision-making. Traditional data-driven methods and newer techniques utilizing LLMs both have limitations. The former often face issues like statistical indistinguishability and sensitivity to distribution shifts, while LLM-based methods sometimes fail to incorporate empirical data effectively. CauScientist offers an innovative solution by combining LLMs' hypothesis-generating capabilities with strict statistical verification, forming a collaborative framework that promises more robust causal inference.
Methodology
CauScientist's framework is structured into three key stages: hybrid initialization, collaborative verification, and iterative optimization, effectively balancing the semantic richness of LLMs with the empirical rigor of statistical verifiers.
Hybrid Initialization: The initial causal graph is selected from either standard data-driven methods or LLM-generated hypotheses, based on the Bayesian Information Criterion (BIC). This ensures a more balanced starting point that leverages both semantic and statistical data.
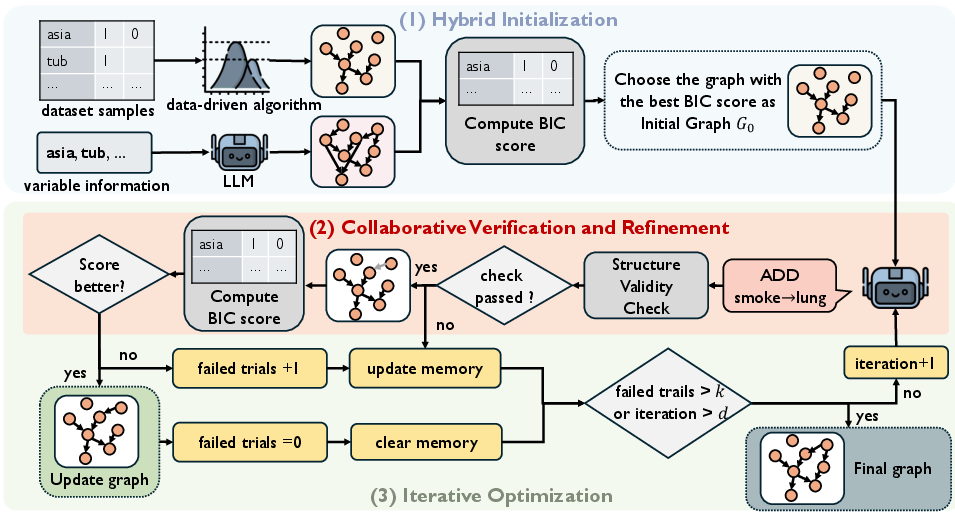
Figure 1: Pipeline of CauScientist. The framework operates in three stages: (1) Hybrid Initialization, (2) Collaborative Verification and Refinement, and (3) Iterative Optimization.
Collaborative Verification: At each iteration, structural modifications proposed by the LLM are validated through a rigorous statistical verifier. Modifications are accepted if they lower the BIC score, ensuring that only empirically supported changes are incorporated.
Iterative Optimization: The system maintains an error memory to avoid redundant errors, iteratively refining the causal graph until convergence.
Experimental Results
The CauScientist framework was evaluated across various datasets with differing complexities. It consistently outperformed purely data-driven approaches, achieving up to a 53.8% increase in F1 score and significantly reducing the Structural Hamming Distance (SHD) on large-scale graphs.
Small-Scale Networks:
Complex Networks:
Implications and Future Directions
CauScientist demonstrates a transformative approach to causal discovery by effectively integrating LLM-generated semantic insights with stringent statistical verification. This methodology not only enhances the accuracy of causal inference but also ensures that the insights remain faithful to the underlying data. It provides a promising direction for future research, particularly in enhancing causal inference techniques and integrating other statistical criteria to accommodate diverse data regimes.
Moreover, the adaptability of CauScientist to incorporate alternative scoring functions suggests potential for further innovation in causal discovery methodologies. Future work could explore the integration of different LLM architectures and more complex datasets, pushing the boundaries of what's possible in automated causal inference.
Conclusion
In summary, CauScientist represents a significant advancement in the field of causal discovery. By leveraging the strengths of both LLMs and statistical methods, it addresses the limitations of each, offering a robust framework capable of extracting reliable causal relationships from complex data. This work not only contributes to the theoretical understanding of causal discovery but also has practical implications for its application across various scientific and industrial domains.