- The paper proposes a one-shot multimodal active perception framework that predicts optimal camera viewpoints, enhancing grasp success rates.
- It leverages a cross-attention mechanism and domain randomization to decouple viewpoint quality evaluation from task-specific optimization.
- Experimental validations in simulation and real-world settings demonstrate significant improvements in robotic manipulation performance.
"A General One-Shot Multimodal Active Perception Framework for Robotic Manipulation: Learning to Predict Optimal Viewpoint" (2601.13639)
Introduction
The paper presents a novel framework for improving active perception in vision-based robotic manipulation, a crucial factor affecting task success rates. Existing methodologies often rely on iterative optimization, which incurs high time and motion costs and are typically tailored to specific tasks, limiting their adaptability. The authors propose a one-shot multimodal active perception framework aimed at directly inferring optimal viewpoints, thereby enhancing perceptual inputs for downstream robotic manipulation tasks such as grasping.
Methodology
Active Perception Framework
The proposed framework decouples the task-specific optimization process by establishing a data collection pipeline and developing a Multimodal Optimal Viewpoint Prediction Network (MVPNet). By implementing a two-step process that involves defining optimal viewpoints via systematic sampling and constructing large-scale datasets through domain randomization, the framework supports heterogeneous task requirements and eliminates the need for manual dataset labeling.
Architecture and Design
The framework's architecture involves aligning and fusing features through a cross-attention mechanism, allowing for efficient prediction of camera pose adjustments. This design emphasizes versatility by tailoring viewpoint quality evaluation functions to various tasks, enhancing its generalizability.
The innovations are instantiated in the specific task of robotic grasping within viewpoint-constrained environments. MVPNet employs multimodal inputs to predict optimal camera viewpoints in a single adjustment step, significantly boosting grasp success rates and enabling effective sim-to-real transfer.
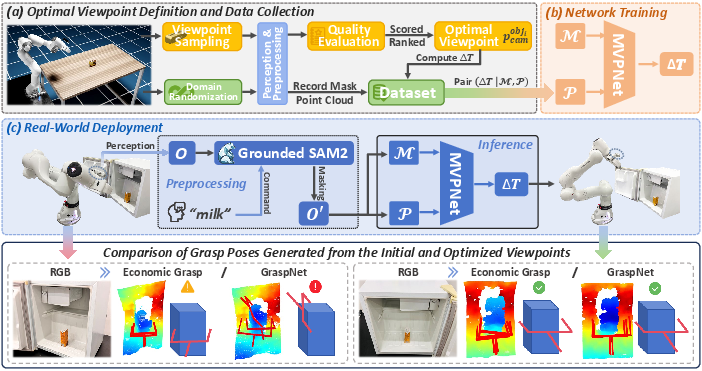
Figure 1: Overall framework of the proposed method, illustrated with robotic grasping in viewpoint-constrained environments: (a) sampling and evaluating candidate viewpoints to obtain the optimal viewpoint for each object, followed by dataset construction via domain randomization; (b) training the MVPNet based on the constructed dataset; and (c) deploying the trained network and conducting comparative evaluations.
Experimental Validation
Simulation and Real-World Testing
Experiments demonstrate that the proposed active perception framework markedly improves grasp success rates. In scenarios using various grasp estimation models, the success rates increased significantly post-optimization. The one-shot prediction capability enables rapid viewpoint adjustment with minimal computational cost.
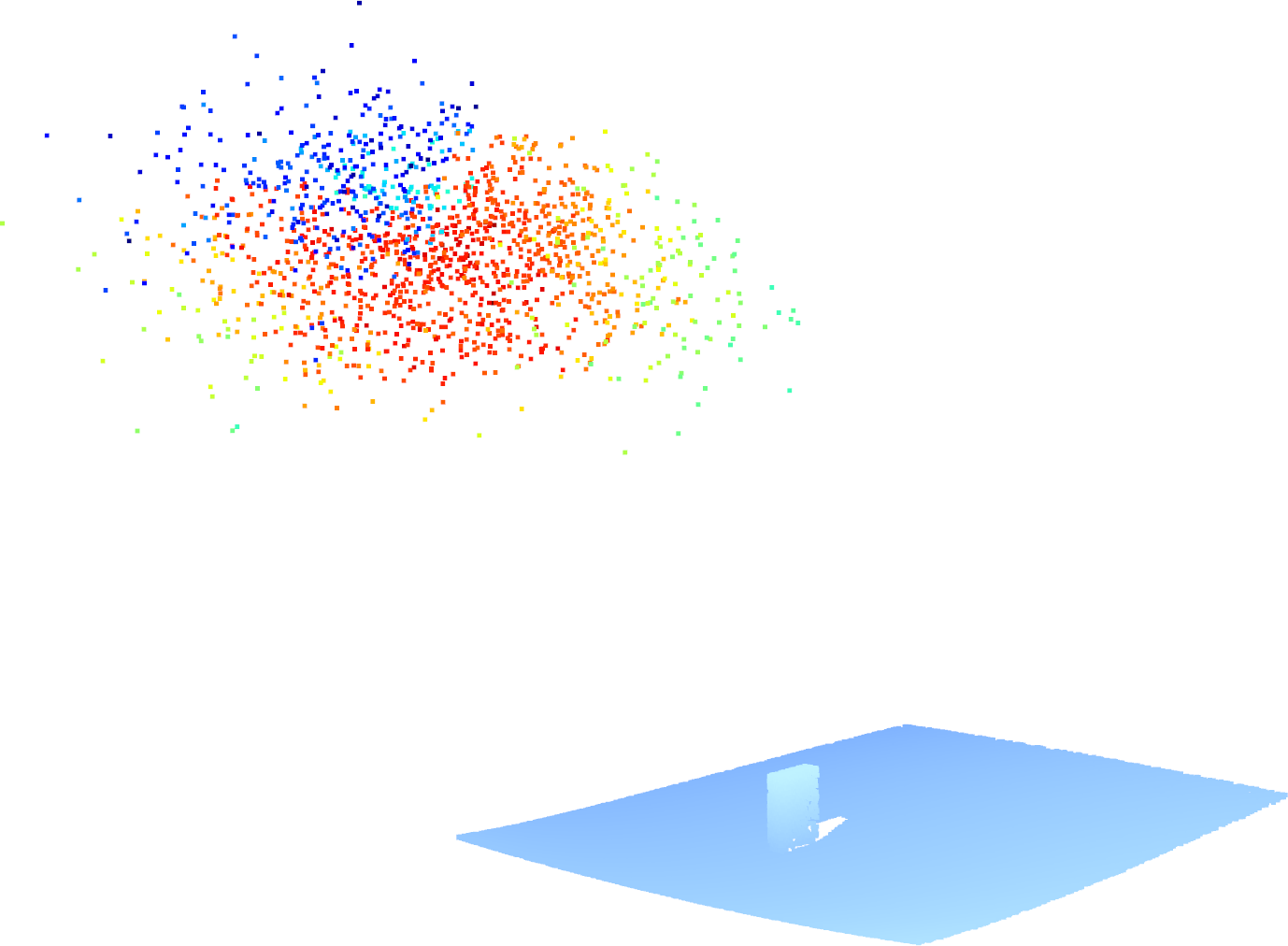
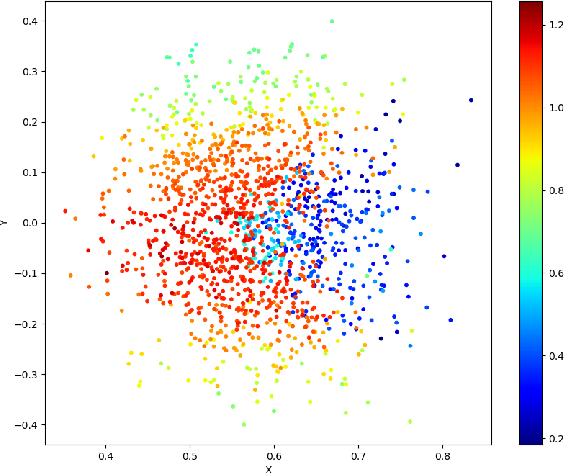
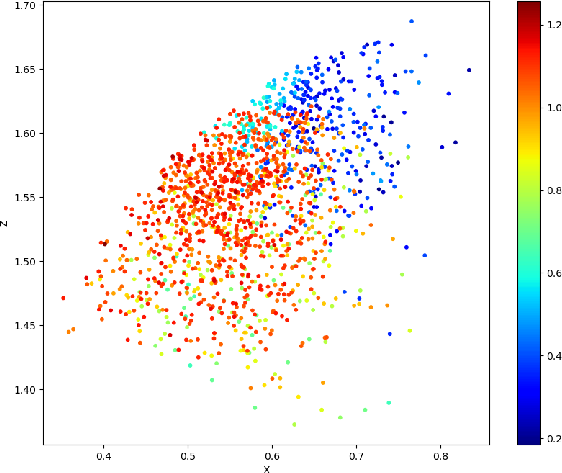
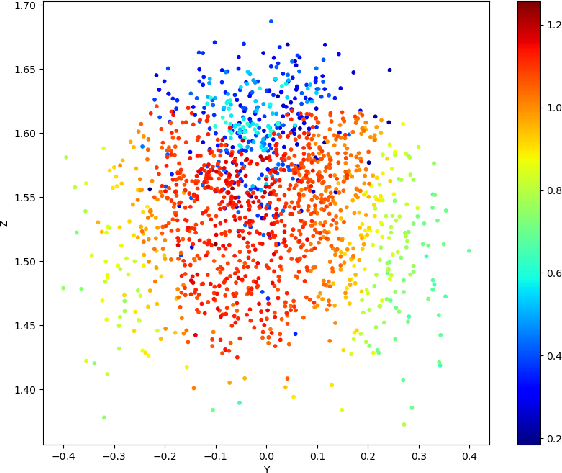
Figure 2: An example of the viewpoint score distribution of the object: (a) 3D distribution; (b) X-Y plane projection; (c) X-Z plane projection; (d) Y-Z plane projection. Each point represents an observation viewpoint, with color indicating its score: red (highest), green (medium), and blue (lowest).
Furthermore, real-world evaluations without additional fine-tuning corroborate the framework's robustness and applicability, achieving substantial improvements in grasp success rates and declutter rates.
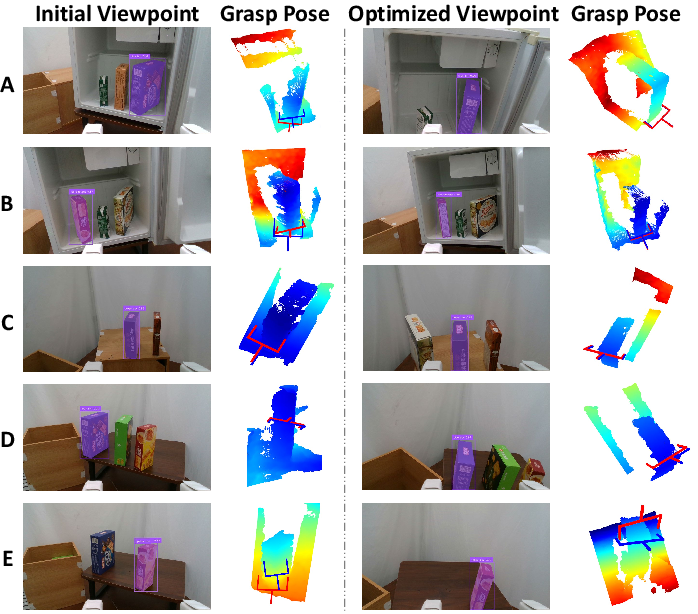
Figure 3: Active perception in real-world scenarios. The second and fourth columns present the grasp poses generated by Economic Grasp under the initial and optimized viewpoints, respectively.
Implications and Future Work
The implications of this research span both practical and theoretical domains. Practically, the framework enhances robotic manipulation efficiency and adaptability across diverse environments and tasks. Theoretically, it contributes to the discourse on active perception by proposing a unified, task-agnostic methodology for viewpoint optimization.
Future work could explore extending the framework to a wider array of tasks beyond grasping and investigating richer viewpoint representations to support more complex manipulation scenarios. The framework's applicability in dynamic environments and its integration with other robotic perception and action strategies offer promising avenues for further research.
Conclusion
This study introduces a sophisticated one-shot multimodal active perception framework that effectively predicts optimal viewpoints in robotic manipulation tasks. By decoupling viewpoint quality evaluation from task specifics, it offers a widely applicable solution that markedly enhances performance in both simulated and real-world environments. The research bridges significant gaps in active perception theory and practice, setting a precedent for future investigations into generalizable robotic perception systems.