- The paper introduces FutureOmni as the first benchmark for omni-modal future event prediction, using an LLM-assisted human-in-loop pipeline to generate high-quality samples.
- It employs a rigorous methodology that filters ~18,000 YouTube videos with dual-stage QA verification and adversarial distractor construction to capture causal audio-visual cues.
- Key results show state-of-the-art models, like Gemini 3 Flash at 64.8% accuracy, struggle with future forecasting, but instruction tuning via the OFF regime yields notable performance gains.
FutureOmni: Benchmarking Omni-Modal Future Forecasting in Multimodal LLMs
Motivation and Overview
Despite rapid advances in Multimodal LLMs (MLLMs) for perception and retrospective reasoning, future event forecasting from joint audio–visual cues remains largely underexplored. Prevailing benchmarks principally evaluate models' capacity for post hoc analysis, leaving a critical gap in assessing their predictive reasoning under naturalistic, multimodal input. "FutureOmni: Evaluating Future Forecasting from Omni-Modal Context for Multimodal LLMs" (2601.13836) addresses this gap by introducing the first rigorously constructed benchmark dedicated to omni-modal future event forecasting, emphasizing cross-modal causal and temporal reasoning, and challenging models to leverage internal world knowledge.
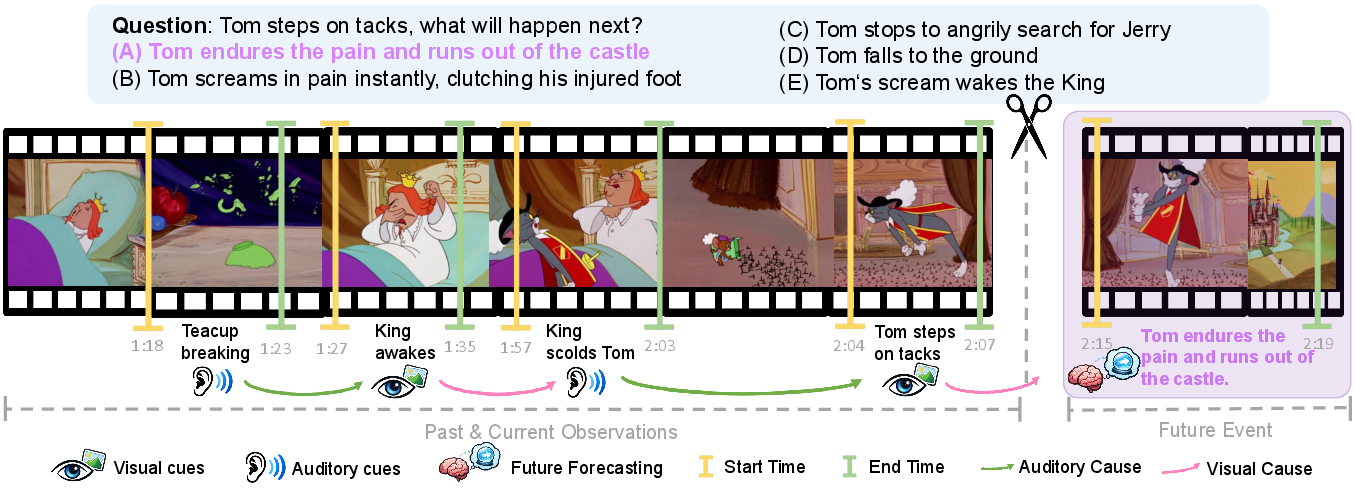
Figure 1: An example depicting FutureOmni’s omni-modal future prediction task, where models must forecast an outcome from complex visual and auditory cues.
Benchmark Construction and Dataset Properties
A central contribution of FutureOmni is its scalable, LLM-assisted, human-in-the-loop pipeline for high-quality, challenging sample creation. The pipeline initiates with the collection and filtering of approximately 18,000 YouTube videos (30s–20min). Videos with sustained static content or decorative audio are eliminated via frame and semantic similarity metrics. Only those with significant audio-visual entwinement, as quantified by changes in UGCVideoCaptioner-generated captions with/without audio, advance to annotation.
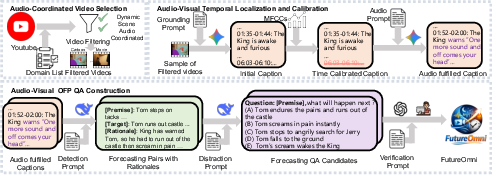
Figure 3: FutureOmni’s data pipeline, combining AI-assisted event extraction and dual-stage QA verification.
Subsequent event segmentation leverages the Gemini 2.5 Flash model for temporal localization and boundary calibration, incorporating automatic acoustic change detection (via MFCC features) and prompting for synchronous marking of critical audio (speech, music, sound effects). Causal relationships are mined using adjacent event analyses in DeepSeek-V3.2, with strict constraints on temporal proximity and a scoring rubric to quantify audio’s causal contribution.
Distractor construction is a key strength, employing four adversarial techniques: (1) visual-only distractors contradicted by audio, (2) audio-only distractors misaligned with visuals, (3) temporally delayed options, and (4) reverse-causal distractors. Each candidate QA undergoes GPT-4o verification and subsequent human review.
The final benchmark spans 919 videos and 1,034 multi-choice QA samples across eight domains (e.g., Education, Surveillance, Emergency, Movies, Games) and 21 fine-grained subcategories. Video durations (avg. 163s) are significantly longer than those in comparable benchmarks, increasing reasoning complexity and context length. A structured taxonomy ensures coverage over various reasoning patterns: Thematic Montage, Routine Sequences, and Causal Events.
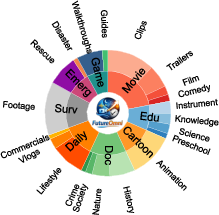
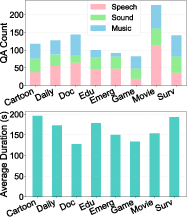
Figure 2: Hierarchical distribution of video domains and their audio/duration composition.
Experimental Protocol and Key Results
Comprehensive evaluation is performed on 20 MLLMs (13 omni-modal, 7 video-only), covering both open-source systems (e.g., Qwen3-Omni, video-SALMONN 2, MiniCPM-o 2.6) and proprietary models (Gemini 3 Flash, Claude Haiku 4.5, GPT-4o). Accuracy is the principal metric, based on exact matching to ground truth.
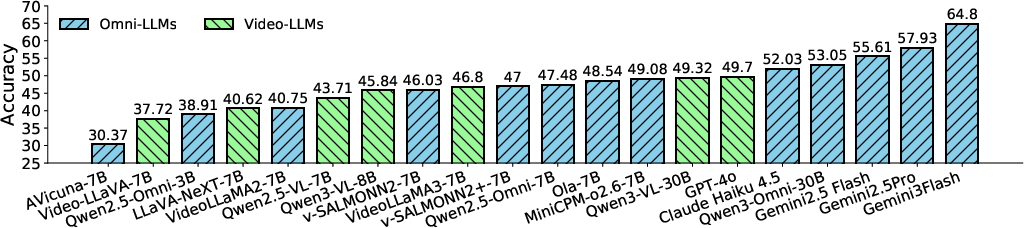
Figure 4: Aggregate performance of evaluated models on FutureOmni, highlighting notable gaps across model families.
Despite strong retrospective abilities, all models demonstrate poor generalization to future event prediction. Gemini 3 Flash, the strongest model, reaches only 64.8% accuracy, and open-source SOTA models trail by up to 10–12 percentage points. This substantial headroom underscores that MLLMs are not yet competent at tasked future reasoning in complex, naturalistic contexts.
Domain-wise analysis reveals higher scores in Game and Dailylife, with the Documentary and Emergency domains posing the greatest challenge due to nuanced, context-rich narration and chaotic sensory cues. The dataset exhibits a "cold start" effect: prediction accuracy collapses for short-duration videos lacking sufficient narrative buildup and peaks with medium-length context.
Modality ablation confirms that audio-visual synergy is essential: performance consistently drops (by 2–5% absolute) when models are provided only audio or video. Supplementing video with subtitles or captions partially mitigates this loss, but never matches access to raw audio signals, which provide rich paralinguistic and environmental information.
Error Analysis
A fine-grained error taxonomy, applied to 318 Gemini 3 Flash failure cases, reveals that the primary bottlenecks are in video perception (51.6%) and joint audio-visual reasoning (30.8%), with knowledge deficits (2.5%) being rare. This points to MLLM limitations not in static world knowledge, but in dynamic scene understanding and temporal synthesis. Audio-only and video-only errors are both prominent. Speech-heavy contexts are particularly difficult: even the top proprietary models exhibit a 7–10% accuracy drop on speech-driven samples versus music or ambient sound.
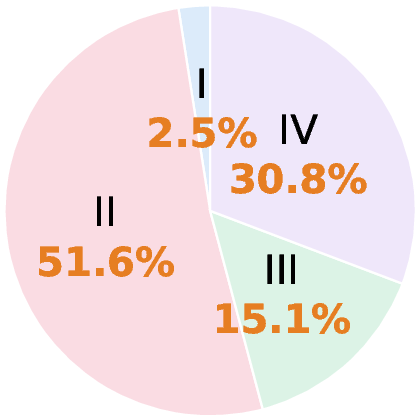
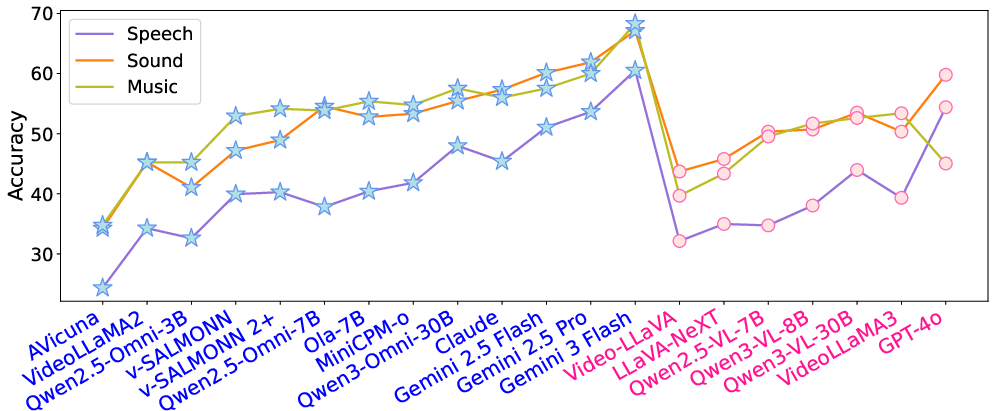
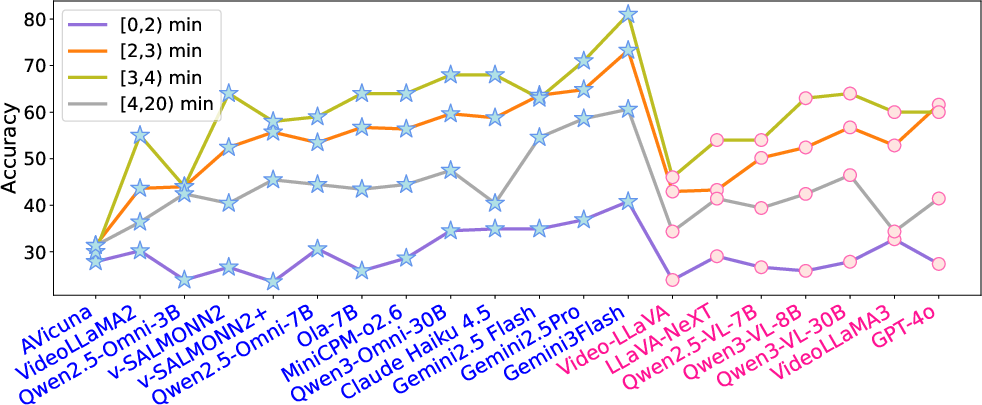
Figure 5: Distribution of failure modes, emphasizing perception and joint reasoning as dominant challenges.
Omni-Modal Future Forecasting (OFF) Instruction Tuning
To ameliorate these deficiencies, the authors curate a 7k-sample instruction-tuning dataset paired with an explicit rationale chain and propose the Omni-modal Future Forecasting (OFF) training regime. LoRA-adapted fine-tuning is performed on three open-source omni-modal LLMs (Qwen2.5-Omni, Ola, video-SALMONN 2), freezing visual/audio encoders and updating only the text backbone.
This instruction tuning boosts open-source accuracy by up to 3.9% absolute and, most notably, raises Speech scenario accuracy by nearly 10% for Qwen2.5-Omni, suggesting substantial gain in the most semantically taxing modality. Domain and duration-based improvements are consistent; the most recalcitrant domains (Emergency, Documentary) see relative improvements, though a significant performance gap still remains.
Generalization is quantitatively probed by evaluating tuned models on diverse out-of-domain benchmarks (WorldSense, DailyOmni, JointAVBench, OmniVideoBench, Video-MME, MLVU). Gains are maintained or even amplified, even when tested on video-only tasks, indicating that training for omni-modal future prediction imparts transferable causal and cross-modal reasoning skills. Attention visualization demonstrates increased model focus on ground-truth video and audio keyframes in relevant transformer layers post-OFF training.
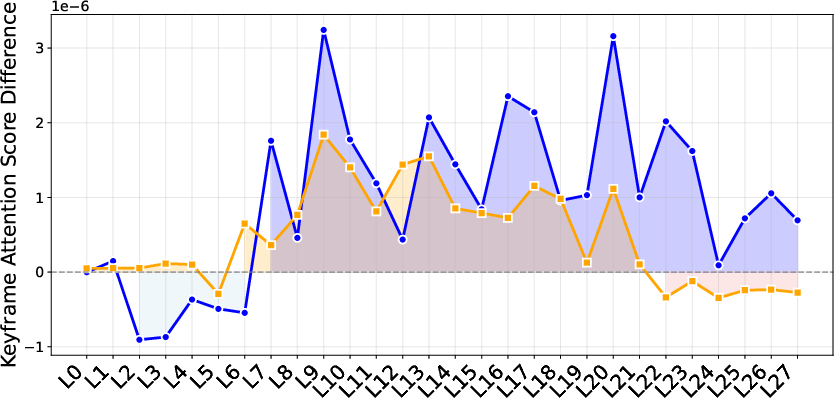
Figure 6: Visualization of post-training attention shifts to modality-critical keyframes across transformer layers.
Theoretical and Practical Implications
The evidence consolidates multiple theoretical implications:
- Current MLLMs are fundamentally limited in prospective, multimodal temporal reasoning—a property required for safety-critical tasks (autonomous driving, human-robot interaction, surveillance, etc.), and not readily improved without cross-modal supervision and explicit rationale-guided tuning.
- Omni-modal instruction tuning, especially with rationale exposure, not only improves direct performance but generalizes to broader audio-visual and even video-only reasoning tasks, hinting at latent synergy in shared representations or improved temporal abstraction.
- Domain transfer is nontrivial: even with rationale-guided tuning, the most complex and context-dependent categories continue to elude existing models, suggesting the need for enhanced event grounding, memory, and long-context modeling architectures.
Practically, the release of FutureOmni establishes a rigorous, adversarial benchmark for the field, systematically preventing shortcut learning and evaluating true causal understanding in multimodal agents.
Conclusion
FutureOmni and its methodologically coherent evaluation suite represent a pivotal step in multimodal LLM benchmarking, shifting focus from perception and static QA to the more challenging domain of future event prediction. The findings robustly demonstrate that neither current open-source nor proprietary MLLMs possess competent omni-modal predictive abilities, particularly under speech-heavy and narration-driven scenarios. However, rationale-enhanced instruction tuning using the OFF strategy closes part of this gap and improves generalization, supporting its use as a core training paradigm for next-generation MLLMs. The authors' approach of hard negative construction, dual-stage verification, and explicit alignment with causal reasoning offers an actionable path forward for future research in predictive multimodal intelligence.
Reference:
FutureOmni: Evaluating Future Forecasting from Omni-Modal Context for Multimodal LLMs (2601.13836)