- The paper demonstrates that precomputed, hardware-aware embeddings eliminate the NP-hard per-iteration mapping cost while maintaining solution quality.
- It introduces a robust BDQA framework with conservative cut rounding and dynamic slack minimization to substantially reduce wall-time.
- Empirical results in transmission network expansion planning show scalable performance improvements, bridging quantum and classical optimization.
Introduction
Mixed-integer linear programming (MILP) remains a fundamental paradigm in operational research and energy systems planning, yet computational scalability poses perennial challenges. Quantum annealing (QA) offers the potential to accelerate discrete combinatorial optimization, but hardware constraints of Noisy Intermediate-Scale Quantum (NISQ) devices—especially qubit count, connectivity, and analog imprecisions—severely limit straightforward application. Quantum-classical hybrid strategies, particularly those leveraging Benders’ Decomposition (BD) to partition the MILP and relegate the “hard” discrete master problem (MP) to the quantum domain, have emerged as a promising direction. This paper presents a rigorous, hardware-agnostic enhancement to Quantum-Classical Benders Decomposition (BDQA) for MILP, with a focus on scalable embedding, cut treatment, and robust stopping criteria (2601.14024).
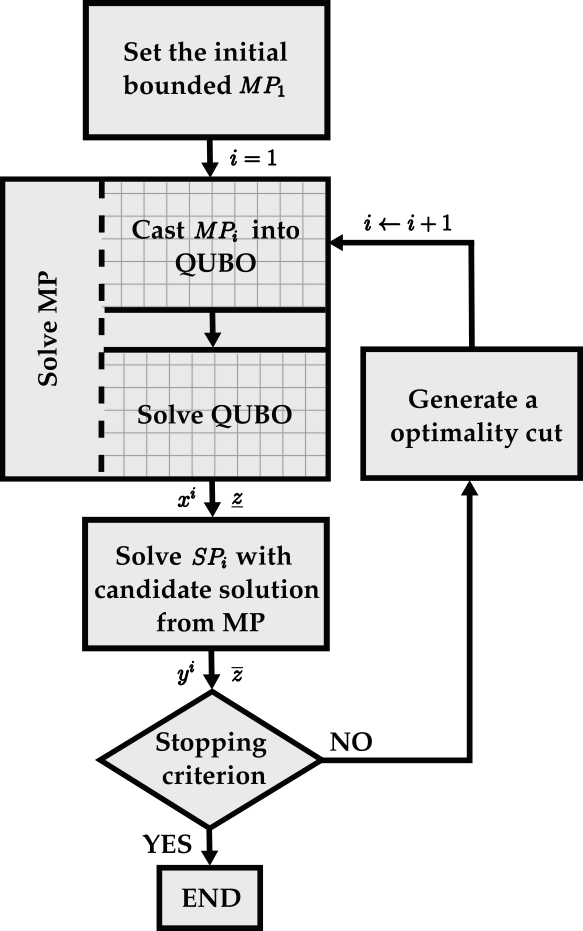
Figure 1: Schematic of the hybrid quantum-classical Benders Decomposition, highlighting the quantum annealing subroutine for the master problem.
The study targets a greenfield Transmission Network Expansion Planning (TNEP) problem, a prototypical application where MILP formulations encode investment and operational decisions under realistic energy system constraints. The BDQA framework decomposes the original MILP into:
- A master problem (MP) comprising discrete decisions (e.g., binary investment variables), reformulated as a QUBO for quantum annealer solution.
- A classical subproblem (SP), typically a high-dimensional linear program (LP), optimized using state-of-the-art classical solvers.
The QUBO reformulation employs penalty encodings for all necessary slack, constraint, and cut variables, with dynamic precision control to minimize binary expansion overhead. The critical step involves translating each growing MP (accumulating BD cuts) into hardware-efficient QUBOs that respect qubit count and precision limitations.
Advances in Embedding Strategies
A major bottleneck in quantum approaches is the logical-to-physical minor embedding required for mapping the QUBO onto the D-Wave Pegasus topology. The default heuristic (Minorminer, MM) incurs substantial preprocessing latency since every QUBO instance requires an NP-hard embedding computation. This work implements two precomputed strategies:
- Fixed (FX): Precompute the largest complete clique embedding and reuse for all QUBOs up to that size.
- Tightest (TT): Dynamically select the smallest sufficient precomputed embedding for each QUBO.
Compared to MM, both approaches eliminate per-iteration embedding cost, without degrading solution feasibility or QUBO sample quality.
Algorithmic Enhancements
Several enhancements over prior hybrid BDQA implementations are introduced:
- Automated, hardware-agnostic implementation in Python (“quacla”): Compatible with any QUBO solver, permitting transparent benchmarking between QA, simulated annealing (SA), and classical solvers.
- Conservative cut rounding: All cut right-hand sides are downward-rounded to ensure no valid solutions are inadvertently excluded, addressing precision mismatches between duals and encoded variables.
- Slack variable minimization: Dynamic bounding and precision control ensure the minimal binary expansion for slack variables, limiting qubit utilization growth per added BD cut.
- Robust stopping criterion: Halts the algorithm when the primal-dual gap (as observed via BD upper and lower bounds) falls below 5%, or when the maximal feasible QUBO size (160 logical variables) is exceeded.
Empirical Benchmarking
Experiments span TNEP test cases from 3 up to 15 buses (limited by available qubits) and compare:
- Classical (Gurobi) MILP (gold standard)
- BD with classical MP (Gurobi), SP (Gurobi)
- BD with MP solved by simulated annealing (SA-GRB)
- BDQA with MP solved by D-Wave (MM, FX, TT), SP (Gurobi)
Key benchmarking metrics include objective optimality gap, success rate (fraction of runs within 5% of classical optimum), QUBO size evolution, iteration counts, solve and total wall-time (including all preprocessing and postprocessing), and scaling behavior.
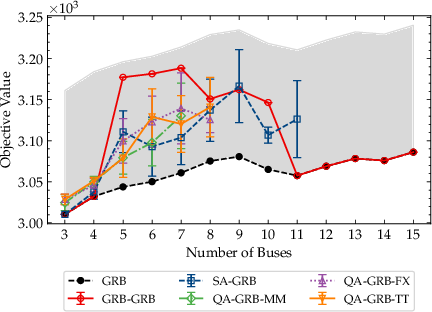
Figure 2: Mean objective values versus the number of buses, with a 5% gap threshold relative to MILP optimum.
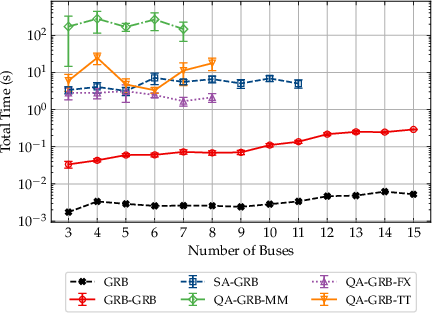
BDQA approaches leveraging FX and TT embeddings not only outperform MM in total runtime but also support larger instances before qubit resources are exhausted.
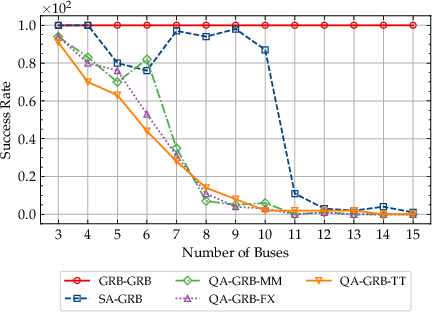
Figure 3: Success rate of various solver configurations as the number of buses (problem size) grows.
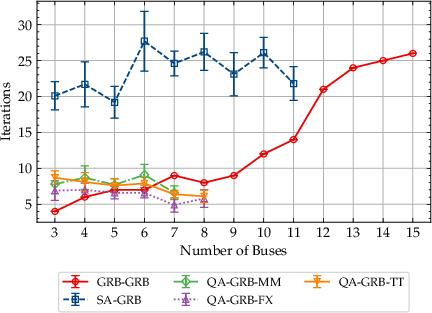
Figure 4: Iteration counts required for convergence as a function of problem size; quantum and SA heuristics show stabilization with increasing size.
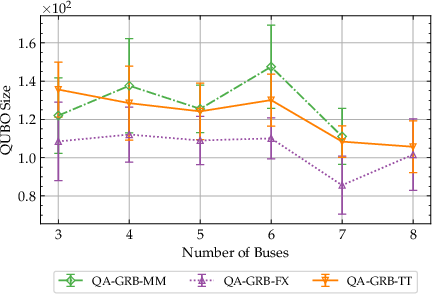
Figure 5: Final QUBO size (number of logical qubits) versus problem size, dominated by slack growth from accumulating BD cuts.
Crucially, using precomputed embeddings enables an order-of-magnitude reduction in wall-time compared to MM (Figure 6 below), and maintains solution quality parity up to hardware bounds.
Scaling and Complexity
Empirical results indicate:
Implications and Future Directions
This work establishes that precomputed, hardware-aware embeddings are essential for leveraging quantum annealing within hybrid quantum-classical optimization frameworks. While QA does not yet surpass classical solvers in absolute speed or optimality for small-to-moderate MILPs, the demonstrated strategies materially reduce quantum overhead and harden solution quality. As D-Wave QPU size and connectivity improve, and as gate-model quantum optimizers mature, the practical threshold for quantum utility in MILP-like combinatorial planning is expected to shift.
Further, the modular, hardware-agnostic architecture permits immediate benchmarking across both present and future quantum optimization paradigms (e.g., QAOA, VQE). The rigorous treatment of rounding, cut addition, and binary encoding highlights both the numerical subtleties and hardware limitations that must be addressed as QUBO-based quantum optimization frameworks are scaled to industrial problem sizes.
Notably, theoretical convergence of Benders' decomposition under heuristic quantum solvers is not guaranteed, and further work is needed to quantify and mitigate gap pathologies introduced by sampling errors, rounding, and chain breaks. Use of multi-cut strategies, dynamic cut selection, and adaptive annealing schedules constitutes important next steps for scalability. Finally, extending the empirical analysis to non-convex, non-linear, and time-constrained energy models offers a clear avenue for leveraging quantum hardware where classical solvers tend to fail.
Conclusion
This study delivers a comprehensive, technically sophisticated enhancement to hybrid quantum-classical Benders Decomposition for MILP, addressing both theoretical and practical constraints of current quantum annealers. Precomputed embeddings, conservative cut handling, and judicious binary expansions yield order-of-magnitude gains in runtime, enabling robust benchmarking and setting an actionable baseline for future quantum optimization research in energy systems and beyond.