- The paper's main contribution is the introduction of HuDA, a reward model that uses off-the-shelf human detectors combined with temporal prompt alignment to improve video generation realism.
- The methodology employs a linear combination of human detection (H-score) and prompt alignment (P-score) to effectively penalize anomalies like missing limbs and implausible poses.
- Optimization using RL-based GRPO with HuDA significantly enhances generation fidelity, achieving a 73% win-rate on challenging human actions.
HuDA: Leveraging Human Detection for Reward Modeling in Video Generation
Introduction
The paper "Human detectors are surprisingly powerful reward models" (2601.14037) introduces HuDA, a reward model that directly leverages the outputs of off-the-shelf human detectors, combined with temporal prompt alignment, to substantially improve human appearance and motion in text-to-video (T2V) generation. Rather than large-scale manual annotation or custom contrastive models, HuDA utilizes only existing vision models and LLMs in a zero-shot manner. Empirical benchmarks demonstrate that HuDA correlates more strongly with human judgments of realism than prior trained or zero-shot reward models, and that optimizing T2V models with HuDA as an RL signal via Group Reward Policy Optimization (GRPO) yields significant improvements in generation fidelity—particularly for complex human actions.






Figure 1: HuDA identifies and penalizes missing/extra body parts, implausible pose, and motion-prompt misalignment, leading to improved human appearance and motion in generated video after GRPO training.
Methodology
HuDA is a linear combination of two terms: a human detection score (H-score) and a temporal prompt alignment score (P-score). H-score is obtained by applying an object detector (typically ViTDet) to each frame of the video, taking as the reward the minimum (worst-case) aggregate human detection confidence across temporally sliding windows. This design penalizes typical anomalies in diffusion-generated humans, including missing/extra limbs or implausible poses.
P-score complements H-score by ensuring generated video exhibits the temporally coherent motion described in the prompt. Phase captions are generated using an LLM, breaking down the action into temporally ordered sub-events. For each sub-event, a sampled frame is compared to its phase caption with a visual-text similarity model (BLIP). The P-score is the average of these similarities, weighted appropriately.

Figure 2: Computation of HuDA as the weighted sum of worst-case human detection window confidence and temporal prompt alignment based on phase-level similarity across uniformly sampled frames.
RL-based Video Model Optimization
HuDA is used as the reward function for on-policy RL post-training of a T2V diffusion model via GRPO. This method delivers a rich, continuous reward signal, in contrast to previous approaches using DPO or discrete preference modeling. Crucially, since HuDA is based on robust, zero-shot, general-purpose detectors, it imposes little annotation burden and generalizes to both in- and out-of-distribution motion types.
Experimental Results
Reward Model Evaluation
HuDA's ability to capture human preferences was quantitatively benchmarked against strong baselines, including zero-shot VLM-as-a-judge [Qwen2.5], DanceGRPO VLM quality metrics, and VBench-2.0's trained anomaly detector. In human evaluation over pairwise video comparisons, HuDA achieved 77.4% accuracy, exceeding VBench-2.0 (72.7%) despite requiring no task-specific training. Ablation experiments confirmed the necessity of both H-score and P-score for robust performance—using only appearance or only the overall prompt similarity results in lower human preference correlation.
Video Generation Improvement
Applying HuDA-based GRPO to Wan 2.1 models (1.3B and 14B parameters) yielded large gains in human-evaluated win-rate compared to both the base models and other reward-tuning methods, across easy, medium, and hard prompt sets. The model trained with HuDA achieves a 73% win-rate on the hardest set (complex actions such as flips or spins), compared to 63% for the base model.
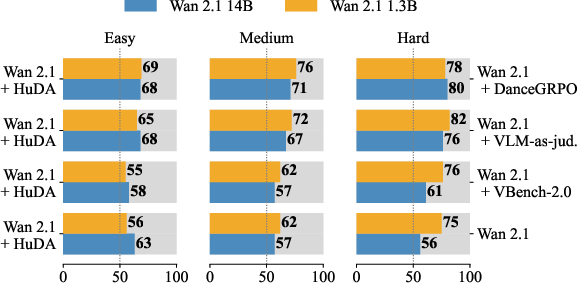
Figure 3: Annotator win-rate preferences for HuDA-trained models show largest improvements in the hard action category.
Qualitative analysis indicated significant reductions in multi-limb artifacts, implausible poses, and body part distortions previously persistent in high-capacity open-domain T2V models.


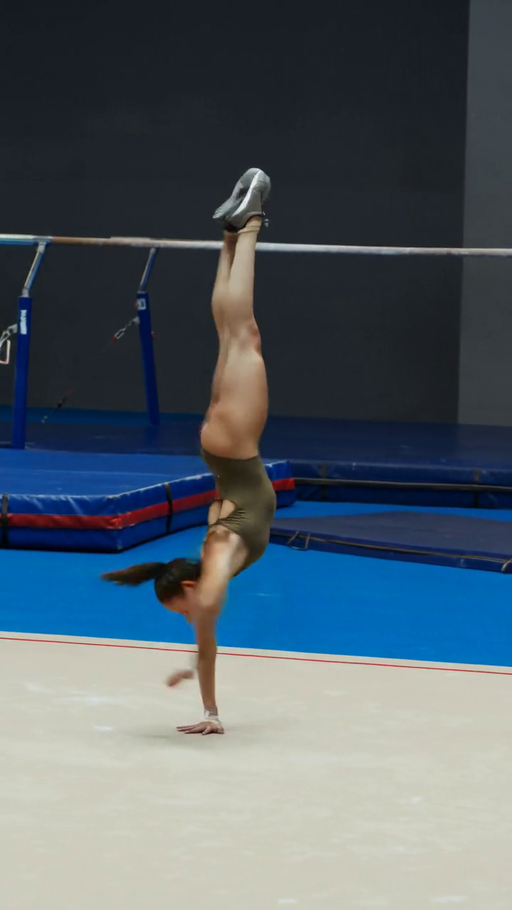
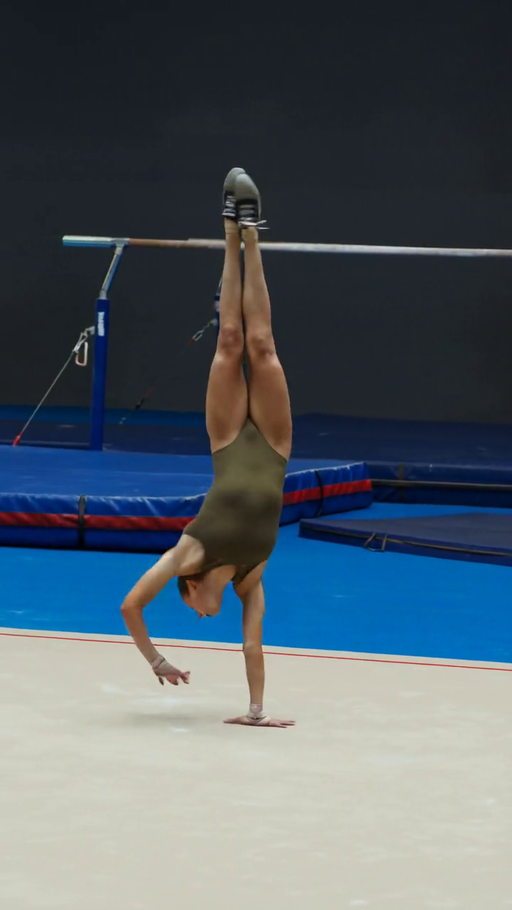
Figure 4: Qualitative comparison demonstrates HuDA-trained model eliminates severe pose/appearance artifacts, ensuring anatomically plausible and prompt-aligned rendering of challenging human actions.
Ablations also showed that HuDA-driven improvements are robust to inference-time resolution, sample count, and training frame selection.
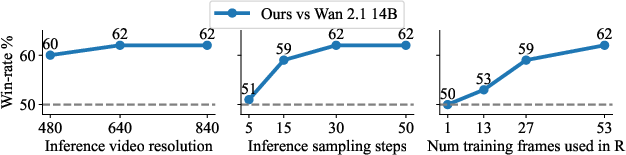
Figure 5: Ablation of inference resolution, step count, and training frame subsampling demonstrates that consistent gains are observed across these choices, with best performance when more frames are included in the reward.
Generalization Beyond Human Generation
While designed for human-centric actions, models trained with HuDA generalized to non-human subjects (e.g., animal motion), even in zero-shot scenarios. This suggests that the human detection term supports learning about general body deformation realism, which carries over to other articulated agents.






Figure 6: HuDA-trained models generate anatomically consistent animal videos without missing/extra parts even for actions atypical to those species.
Further, HuDA optimization led to improved human-object interactions. Correct hand-object and tool manipulation sequences—which indirectly require faithful body generation—were preferentially generated after training.






Figure 7: Reward surface and generated videos indicate that correct human-object and contact interactions are also improved by HuDA-based training.
Implications and Future Directions
The results demonstrate that off-the-shelf human detectors can substitute for labor-intensive annotation and specialized discriminator training in high-dimensional, temporally structured reward modeling. HuDA reveals that large-scale, closed-vocabulary vision models possess sufficient zero-shot robustness to function as practical reward providers in T2V RL frameworks. This minimalistic approach underscores the importance of leveraging generally trained vision priors rather than domain-specific models for reward shaping.
Practically, these results suggest immediate applicability to any backbone video diffusion model, facilitating improved human realism without costly data curation. The strong generalization to out-of-distribution categories (e.g., animals) suggests future research into compositionally extending reward modeling to arbitrary articulated agents.
Theoretically, this work raises questions about the limits of reward modeling by proxy detection; softmax-based detectors may miss subtle inter-frame artifacts, and temporally local rewards may overlook global physical implausibility. Addressing transient artifacts—for example, physically impossible temporal discontinuities—may require hybrid approaches combining framewise detection and explicit motion/physics modeling.
Conclusion
HuDA demonstrates that a zero-shot reward model composed of human detection confidences and phase-level prompt alignment, both derived from general-purpose vision-LLMs, robustly quantifies and improves human appearance and motion in video generation. Optimizing video diffusion models using HuDA and GRPO delivers strong improvements in both subjective realism and objective artifact reduction, outpacing prior annotation- and training-heavy baselines. The approach's generality and annotation efficiency invite broader adoption for generation tasks where precise human (or agent) realism is critical, and suggest new frontiers in reward design for generative video modeling.