Q-learning with Adjoint Matching
Abstract: We propose Q-learning with Adjoint Matching (QAM), a novel TD-based reinforcement learning (RL) algorithm that tackles a long-standing challenge in continuous-action RL: efficient optimization of an expressive diffusion or flow-matching policy with respect to a parameterized Q-function. Effective optimization requires exploiting the first-order information of the critic, but it is challenging to do so for flow or diffusion policies because direct gradient-based optimization via backpropagation through their multi-step denoising process is numerically unstable. Existing methods work around this either by only using the value and discarding the gradient information, or by relying on approximations that sacrifice policy expressivity or bias the learned policy. QAM sidesteps both of these challenges by leveraging adjoint matching, a recently proposed technique in generative modeling, which transforms the critic's action gradient to form a step-wise objective function that is free from unstable backpropagation, while providing an unbiased, expressive policy at the optimum. Combined with temporal-difference backup for critic learning, QAM consistently outperforms prior approaches on hard, sparse reward tasks in both offline and offline-to-online RL.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Q-Learning with Adjoint Matching (QAM): A simple explanation
What is this paper about?
This paper introduces a new way to train robots and AI agents to make good decisions when their choices are continuous (like turning a steering wheel a little or a lot). It focuses on a long-standing problem: how to use very powerful “generative” policies (called flow or diffusion policies) without the training becoming unstable and falling apart. The authors’ solution is a method called QAM, which borrows a smart idea from image generation known as adjoint matching to train these policies safely and effectively.
What questions does the paper try to answer?
In easy terms, the paper asks:
- How can we train very expressive policies that make complex, high-quality decisions, while still using helpful guidance from a “critic” (a value function that scores actions) without the training blowing up?
- Can we keep the benefits of powerful generative policies and also directly use the critic’s gradient (its “direction of improvement”) to learn faster and better?
- Will this approach work well when we only have offline data (records of past behavior) and also when we later fine-tune the agent by letting it interact with the world?
How does the method work? (Explained with everyday ideas)
First, some simple roles:
- Policy: the “player” that chooses actions.
- Critic (Q-function): the “coach” that scores each action in each situation.
- Flow/Diffusion policy: a policy that generates an action step-by-step, like sharpening a blurry photo gradually until it’s clear.
- Gradient: an arrow that points toward better actions.
The big challenge:
- These step-by-step (flow/diffusion) policies are very expressive (they can represent complex, multi-modal choices), but to use the critic’s advice (its gradient), you normally need to push feedback through many steps. That “backpropagation through many steps” often becomes numerically unstable—signals can explode or vanish—so training becomes unreliable.
What others tried (and why that’s not enough):
- Some methods ignore the critic’s gradient and only use its score. That’s safer but wastes useful directional information and learns more slowly.
- Others simplify the policy into a single-step version to avoid instability. That’s easier to train but loses expressiveness.
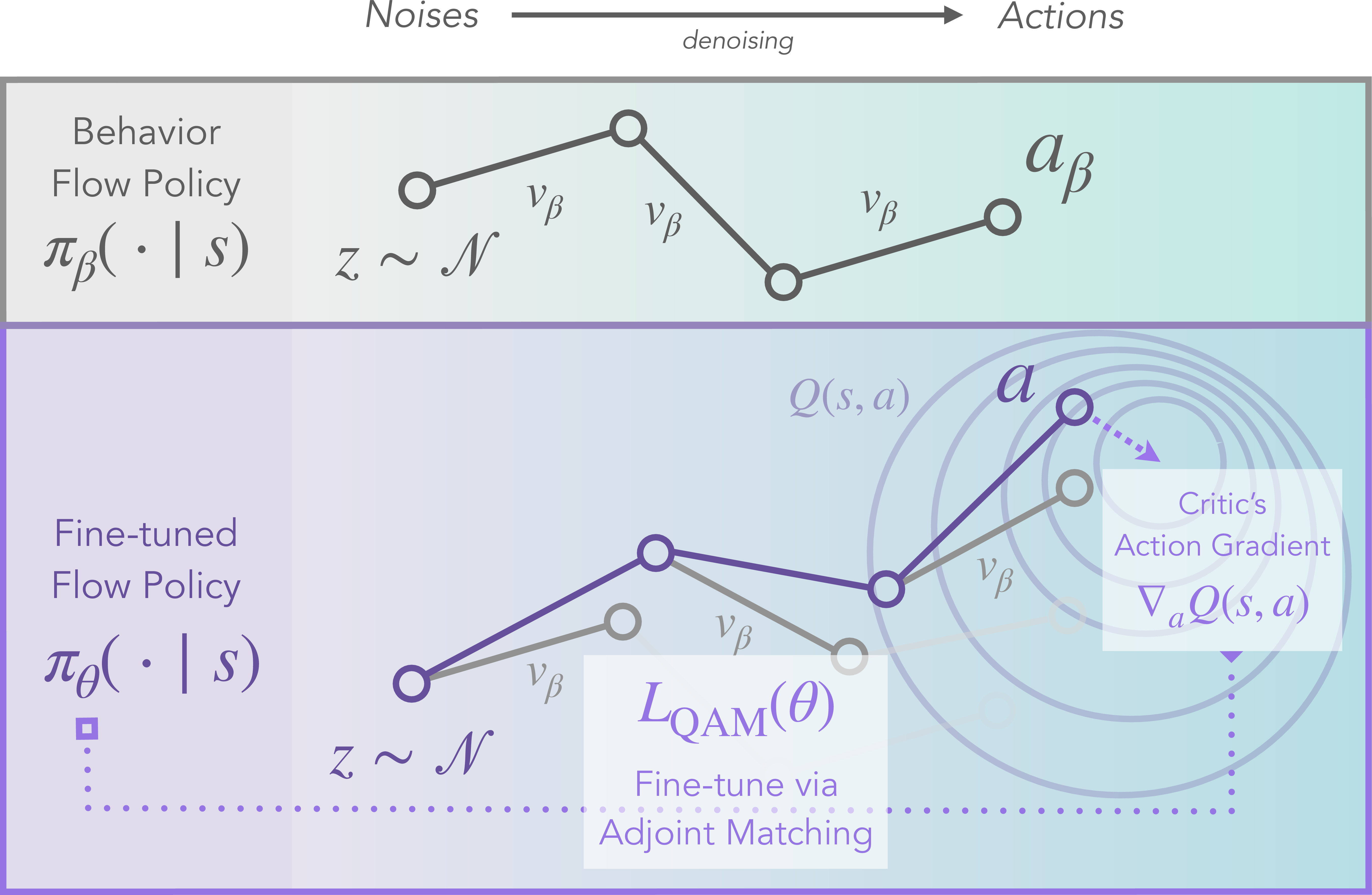
QAM’s key idea: adjoint matching
- Imagine the critic gives the best advice at the final, clean action (the last step of the diffusion process).
- Adjoint matching transports that final advice backward, step-by-step, along a stable path defined by a “behavior model” (a model of how actions in the dataset were made). This creates simple, local training targets for every intermediate step—without backpropagating through the policy’s own complicated chain.
- In other words, instead of pushing fragile gradients through the policy’s entire denoising process, QAM uses a separate, stable “guide rail” (built from the behavior model) to pass instructions backward. This keeps training steady while still using the critic’s direction.
Behavior constraint (staying safe and realistic):
- Offline data comes from a behavior policy (what humans or previous agents did). To avoid weird, unsafe actions, QAM aims for an “optimal but behavior-respecting” policy. The ideal target looks like:
- “New policy ∝ Behavior policy × exp(How good the action is)”
- This means: pick good actions, but still stay close to what the behavior data suggests.
Putting it together:
- Train a behavior flow model on the dataset (learn to imitate).
- Train a policy flow model with adjoint matching, using the critic’s gradient only at the final step, then transporting that signal backward stably via the behavior model.
- Train the critic with a standard TD (temporal-difference) update, with a bit of “pessimism” for safety (an ensemble that favors conservative estimates).
- The result is a stable, efficient way to extract a strong policy from the critic without losing expressiveness.
What did they find?
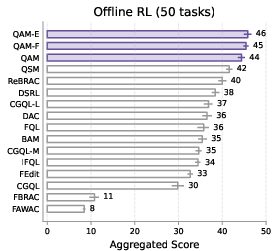
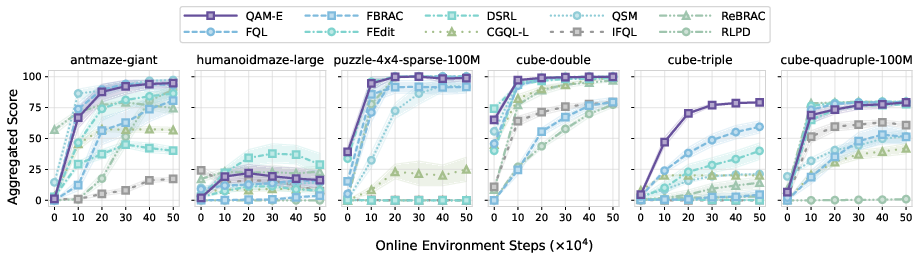
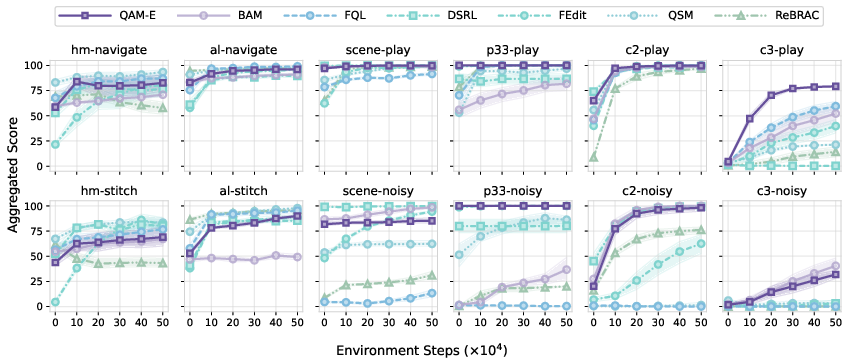
Across 50 challenging tasks (from the OGBench suite), including long-horizon and sparse-reward problems:
- QAM consistently outperforms previous methods in offline RL (learning only from data) and in offline-to-online RL (first learn from data, then fine-tune by interacting with the environment).
- It beats approaches that ignore the critic’s gradient and approaches that backprop through the entire diffusion chain.
- Variants that add a small, safe “edit” or a distilled one-step helper can improve performance even more, especially for online fine-tuning.
Why this matters:
- It shows we can finally use very expressive, multi-step generative policies in RL—without training collapsing—while still making full use of the critic’s guidance.
- This is especially helpful for tasks with complex action spaces and long-term goals, like robotics and navigation.
Why is this important, in plain language?
- Stronger decisions: The method learns smarter, more diverse actions because it keeps the full power of generative policies.
- Stable learning: It avoids the common pitfall of unstable training by not backpropagating through long chains.
- Data-friendly and safe: It respects what’s in the dataset (the behavior constraint), which is important when you can’t try risky actions.
- Practical impact: Better offline learning and faster, safer fine-tuning online could help robots and agents learn real-world tasks more reliably.
A short recap
- Problem: Expressive (flow/diffusion) policies are great but hard to train with a critic due to instability.
- Key idea: Use adjoint matching to send the critic’s final-step advice backward along a stable path defined by the behavior model, avoiding unstable backprop through the policy.
- Result: QAM learns an optimal, behavior-respecting policy efficiently and outperforms strong baselines on tough benchmarks.
- Impact: A practical and robust way to bring powerful generative models into reinforcement learning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper that future researchers could address.
- Convergence under RL-specific nonstationarity: Theoretical guarantees for adjoint matching are borrowed from generative modeling; the paper does not analyze convergence when both the critic and the base flow model are learned concurrently from nonstationary off-policy data with TD bootstrapping, function approximation, and target network lag.
- Sampling-induced bias: The adjoint matching objective is optimized using trajectories sampled from the current fine-tuned policy’s SDE (fθ), while lean adjoint states are computed with the base model (fβ). The paper does not characterize estimator bias, variance, or convergence behavior arising from this mismatch in the trajectory distribution and adjoint dynamics.
- Dependence on behavior model quality: There is no quantitative analysis of how errors in fβ (behavior flow) affect policy optimality or stability, especially because fβ is trained jointly rather than fixed; conditions under which a mis-specified base model degrades adjoint matching remain unknown.
- Discretization error and noise schedules: The method relies on a specific memory-less SDE and fixed discretization h=1/T. The impact of discretization error, choice of T, alternative marginal-preserving schedules, and their effect on optimality and stability are not studied.
- State-dependent temperature τ(s): Although the optimal policy is derived with τ(s), the implementation uses a global τ. There is no method for learning or adapting τ(s) (e.g., via dual variables for KL constraints) nor sensitivity analysis for τ and its interaction with critic scale.
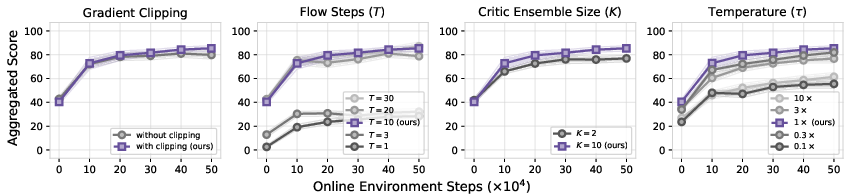
- Critic gradient robustness: The algorithm critically depends on ∇aQ(s,a) at denoised actions but does not quantify robustness to noisy or biased action-gradients, ensemble size K, pessimism level ρ, gradient clipping, or how these choices trade off bias vs. variance.
- Role of concurrent training: Training fβ, fθ, and Q together may induce co-adaptation and instability; the paper does not compare against using a frozen/pretrained behavior flow nor analyze how base-model drift affects the adjoint objective and convergence.
- Formal guarantees for constraint relaxations: The QAM-FQL (W2) and QAM-EDIT (W1, L∞-bounded edits) variants are heuristic approximations. There is no formal analysis of their optimality, constraint satisfaction, or conditions under which they provably reduce support-mismatch while preserving value.
- Metric and q selection in Wasserstein constraints: The paper does not examine how the choice of metric d(·,·), q, and σa impacts policy expressivity, off-support generalization, or stability, nor provide guidance for setting these hyperparameters.
- Exploration in offline-to-online RL: Beyond entropy in QAM-EDIT, there is no systematic study of exploration behavior (e.g., visitation diversity, novelty metrics) or comparison with explicit exploration strategies; the data-mixing ratio (offline/online) is fixed and unexplored.
- Sample efficiency quantification: The paper reports aggregate scores but does not provide learning curves, interaction budgets, or per-task sample efficiency improvements; sensitivity to online steps, replay buffer composition, and evaluation protocols remains unquantified.
- Compute, memory, and scalability: Adjoint matching requires per-step VJPs through fβ and solving SDE/ODE chains. Runtime/memory costs, scaling with action dimensionality, T, and model size, as well as inference-time overhead, are not measured or compared to baselines.
- Stability diagnostics vs. BPTT: While claiming improved stability, the paper does not include diagnostics (e.g., gradient norms/conditioning over time, loss curvature, training variance across seeds) to explain why QAM is more stable than BAM/FBRAC or when BPTT can be competitive.
- Extension to diffusion policies: The method is presented for flow-matching; it remains unclear how to adapt adjoint matching to DDPM-like diffusion policies, whether similar lean adjoint constructions exist, and what practical differences arise.
- Sensitivity to best-of-N and target-action sampling: The critic backup uses one sampled action; the impact of best-of-N action sampling, or using value-aware target selection, on stability and performance is not studied.
- Alternative value targets (advantage vs. Q): The policy tilt uses Q(s,a). It is unclear whether using advantages A(s,a) or normalized Q improves optimization, mitigates scaling issues, or reduces sensitivity to τ.
- Out-of-distribution states and sparse rewards: Although the method targets sparse, long-horizon tasks, the paper does not analyze robustness when state distributions during online fine-tuning drift far from offline data, nor how adjoint matching behaves when rewards are extremely sparse or delayed.
- Discrete-action and hybrid-action settings: The applicability of adjoint matching for discrete or mixed action spaces, or for policies that combine continuous controls with discrete modes, remains an open question.
- Real-world deployment: There is no evaluation on real robotic systems or safety-critical domains; how to choose σa (edits) and τ to respect safety constraints while retaining performance is unexplored.
- Impact of action chunking: While action chunking is used, the paper does not isolate its influence on performance or study how chunk length affects adjoint matching, stability, and expressivity.
- Changing base distribution during training: Theoretical results typically assume a fixed base distribution pβ. With fβ being updated throughout training, the paper does not analyze whether the optimality guarantees still hold or require modifications (e.g., slower updates, two-timescale learning).
- Lean adjoint numerical accuracy: Computing lean adjoint states via VJPs through fβ may accumulate numerical errors; the method does not evaluate the accuracy of these adjoints, their sensitivity to Jacobian conditioning, or whether preconditioning helps.
- Benchmarks and breadth: Results focus on OGBench. Comparative evaluations on additional continuous-control suites (e.g., D4RL), complex manipulation, and locomotion with different dynamics and reward structures are missing.
- Hyperparameter selection and tuning protocols: The paper does not provide principled procedures for choosing τ, σa, T, ρ, K, clipping magnitudes, or learning rates, nor analyze their interactions and the risk of overfitting hyperparameters to particular domains.
- Connections to SMC/test-time guidance: Given the relation to classifier guidance, a direct comparison with SMC-based composition or Langevin-based approaches (including hybrid training+sampling strategies) is absent, leaving open whether adjoint matching is preferable under tight compute limits or specific data regimes.
Practical Applications
Overview
This paper introduces QAM (Q-learning with Adjoint Matching), a TD-based reinforcement learning algorithm that optimizes expressive flow/diffusion policies directly with a critic’s action gradient, without unstable backpropagation through multi-step denoising. It preserves policy expressivity, provides a principled objective that recovers the optimal behavior-regularized policy at convergence, and demonstrates strong results on hard, sparse-reward offline and offline-to-online benchmarks. Two practical variants extend usability: QAM-FQL (1-step distilled policy with a Wasserstein proximity constraint) and QAM-EDIT (bounded action “edit” policy for safe, controlled deviations). Below are concrete applications, organized by time horizon.
Immediate Applications
- Sector: Robotics and Automation (warehousing, field robotics, drones); Use case: Fine-tune robot manipulation and navigation policies from large teleoperation or logged autonomy datasets, then safely improve online with minimal exploration. Tools/workflows: Train a flow behavior policy fβ from logs, apply QAM to extract the exp(Q)-regularized policy, wrap with QAM-EDIT to bound actuation changes during real-world trials; integrate into ROS2 and a safety monitor using pessimistic critic ensembles. Assumptions/Dependencies: Rich offline coverage near desired behaviors; continuous-action control; reward shaping aligned with task; compute for flow training and adjoint VJPs; safety layer for trials.
- Sector: Industrial Process Control (manufacturing lines, chemical plants); Use case: Offline RL from historian data to improve PID/MPPC controllers’ set-point tracking or energy efficiency, followed by cautious online adaptation. Tools/workflows: QAM policy head atop existing control stack; QAM-EDIT to cap deviations; monitoring for policy drift and constraint violations; nightly retraining from logs. Assumptions/Dependencies: Stable data-generating processes; accurate reward proxies (e.g., yield, cost); hard safety constraints and interlocks; continuous-action interfaces.
- Sector: Built Environment and Energy (HVAC, microgrids); Use case: Reduce energy and peak demand using logged building/microgrid data, fine-tuned online when conditions change (weather/occupancy). Tools/workflows: Behavior flow policy learned from BMS logs; QAM-FQL for fast 1-step inference on embedded controllers; conservative critic ensemble for risk-aware updates. Assumptions/Dependencies: Sufficient action-state coverage across seasons; latency-constrained inference; interpretable safety and comfort bounds.
- Sector: Recommender Systems and Ads (software); Use case: Offline bandit-log policy improvement with expressive, multi-modal action selection (e.g., content mixtures, pricing), then small-step online adaptation. Tools/workflows: Train flow policy on logged context–action data; QAM-FQL for efficient serving (1-step policy); guardrails via QAM-EDIT (bounds over catalog embeddings); offline evaluation/OPE and guardrails for fairness. Assumptions/Dependencies: Reliable reward/utility proxies; large logged coverage near candidate actions; constraint handling (slates, quotas); continuous or embedding-based action parameterization.
- Sector: Finance (execution, market making, portfolio sizing); Use case: Improve trading action policies from historical tapes and simulators with conservative online deployment. Tools/workflows: QAM-EDIT to hard-cap delta in position sizing (L∞ bounds); pessimistic value backups to handle non-stationarity; staged deployment in paper/live shadow modes. Assumptions/Dependencies: Strong backtesting/simulation; stringent risk controls; regime shift monitoring; explainability/approval processes.
- Sector: Gaming and Simulation; Use case: NPC policies that model multi-modal tactics trained from play logs, then tuned to new levels/metas. Tools/workflows: Flow policy for action diversity; QAM for value-aligned guidance; instant distillation with QAM-FQL for low-latency inference in engines (Unreal/Unity plug-ins). Assumptions/Dependencies: Well-defined reward signals; latency budgets; content-specific constraints.
- Sector: Autonomy Features (ADAS, mobile platforms) — constrained pilots; Use case: Offline-trained assistive control (e.g., lane keeping, docking) augmented with QAM-EDIT to bound interventions within certifiable limits. Tools/workflows: QAM offline; QAM-EDIT as a wrapper to keep outputs within validated envelopes; rigorous sim-in-the-loop and gating; telemetry-driven retraining. Assumptions/Dependencies: Regulatory compliance; extensive simulation; strong behavior coverage; rigorous hazard analysis.
- Sector: Academic Research and Education; Use case: Studying stable actor–critic training with expressive policies; benchmarking offline-to-online RL; bridging generative modeling (adjoint matching) and control. Tools/workflows: Public QAM codebase; OGBench pipelines; ablations on lean versus basic adjoint; curriculum labs and coursework modules. Assumptions/Dependencies: Access to compute and datasets; reproducible configs.
- Sector: ML Engineering and MLOps; Use case: Production pipeline for behavior-constrained RL with expressive policies. Tools/workflows: “FlowRL Toolkit” packaging: (1) BC flow fitting (fβ), (2) QAM extraction, (3) QAM-FQL distillation for serving, (4) QAM-EDIT safety layer, (5) critic ensemble services, (6) drift monitoring and rollback. Assumptions/Dependencies: CI/CD for RL; metrics for safety/performance; hardware for VJP-heavy training.
- Sector: Generative Control for Robotics Content; Use case: Action chunking policies for long-horizon tasks (e.g., multi-step manipulation sequences). Tools/workflows: The paper’s action-chunked flow policies; QAM for extraction; chunk-length sweeps; replay buffer mixing for fine-tuning. Assumptions/Dependencies: High-quality play data; chunk sizes tuned to task; stable critic learning under sparse rewards.
Long-Term Applications
- Sector: Autonomous Vehicles (full-stack decision-making); Use case: Policy learning from vast offline logs (fleet operations) with safe, certifiable online adaptation. Tools/products: QAM-EDIT as a certifiable safety envelope; hierarchical QAM for interaction layers; standards-aligned audit logging. Assumptions/Dependencies: Certification pathways; extreme robustness requirements; multi-agent coordination; strong simulation-to-real fidelity.
- Sector: Healthcare (treatment planning, dosing, operations); Use case: Offline RL from EHRs and simulators to propose continuous dosages/schedules, with bounded, clinician-in-the-loop edits. Tools/products: Clinical decision support with QAM-EDIT constraints; uncertainty-aware critic ensembles; prospective trials. Assumptions/Dependencies: Regulatory approval; causal validity and bias control; rigorous OPE; privacy/security.
- Sector: Grid-Scale Energy Dispatch and Markets; Use case: Multi-objective continuous control (cost, reliability, emissions) from historical operations and digital twins. Tools/products: Multi-task QAM with behavior priors per region; safety wrappers for N-1 grid security; policy governance dashboards. Assumptions/Dependencies: High-fidelity simulators; operator-in-the-loop validation; non-stationary demand/renewables.
- Sector: Generalist Robotics and Foundation Control Models; Use case: Unifying multi-task robot control with multi-modal flow policies; scalable offline-to-online adaptation. Tools/products: Pretrained fβ from large play datasets; QAM for task-specific extraction; fast serving via QAM-FQL; cross-embodiment adapters. Assumptions/Dependencies: Massive datasets; consistent action/state abstractions; robust cross-domain critics.
- Sector: Multi-Agent Systems (warehouses, traffic, logistics); Use case: Coordinated continuous control with behavior-constrained updates to avoid cascading failures. Tools/products: Decentralized QAM with shared priors; bounded edits for safety; game-theoretic critics. Assumptions/Dependencies: Reliable multi-agent simulators; communication constraints; equilibrium and stability analysis.
- Sector: Recommender/Search with Huge Discrete Catalogs; Use case: Flow-based parameterization over item embeddings for continuous action control in dense spaces, coupled with QAM extraction. Tools/products: Embedding-space flow policies; edit-layer constraints for compliance/brand safety; hybrid slate optimization. Assumptions/Dependencies: Smooth embedding geometries; robust mapping from continuous actions to discrete items; compliant logging.
- Sector: Safety-Critical RL Certification and Governance; Use case: Formalizing behavior-constrained policies with verifiable proximity to validated priors and provable deviation bounds. Tools/products: Auditable QAM-EDIT envelopes; conformance tests; standard benchmarks for offline-to-online transitions. Assumptions/Dependencies: Accepted standards; formal verification for learned controllers; interpretable critic diagnostics.
- Sector: World-Model–Integrated Control; Use case: Combine QAM policies with learned dynamics/world models for planning under uncertainty. Tools/products: Joint training loops (model + QAM + ensembles); uncertainty-aware adjoint guidance; planning-time editing. Assumptions/Dependencies: Reliable long-horizon modeling; compounding error mitigation; compute budgets.
- Sector: Methodological Extensions in RL and Generative Modeling; Use case: Broader constraint sets (beyond KL), discrete/structured actions, and preference-based critics. Tools/products: Generalized adjoint-matching objectives; Wasserstein/proximal constraints; preference or human-feedback–driven Q critics. Assumptions/Dependencies: Theoretical advances; efficient VJP computation under alternative samplers; robust preference learning.
- Sector: Public Policy and Standards for Data-Driven Control; Use case: Best practices for offline-to-online deployment minimizing exploration risk in public infrastructure. Tools/products: Deployment playbooks (behavior priors, pessimistic critics, bounded edits); audit trails; incident response protocols. Assumptions/Dependencies: Cross-agency coordination; transparency mandates; privacy-preserving data sharing.
Notes on feasibility dependencies that recur across applications:
- Data and coverage: QAM assumes offline logs capturing relevant behavior; limited support mismatch reduces efficacy (partially mitigated by QAM-FQL and QAM-EDIT).
- Action space: Currently best-suited to continuous control or continuous parameterizations of discrete choices.
- Critic quality: Reliable Q-function gradients near denoised actions are crucial; ensembles and pessimistic backups help but require careful tuning.
- Compute and latency: Training needs VJP-heavy adjoint computations; serving can be optimized via QAM-FQL (1-step) or efficient ODE solvers.
- Safety and governance: For safety-critical domains, bounded-edit layers (QAM-EDIT), conservative targets, and rigorous OPE/simulation are essential.
- Hyperparameters: τ (temperature), discretization steps T, and constraint radii (Wasserstein or L∞) materially affect stability and performance.
Glossary
- Action chunking: Executing or predicting sequences of multiple low-level actions as a single high-level action unit to handle long horizons or complex control. "we follow \citet{li2025reinforcement} to learn action chunking policies with an action chunking size of ."
- Adjoint matching: A technique to fine-tune flow/diffusion models by transforming a target gradient signal into step-wise supervision without unstable backpropagation through the generative process. "Adjoint matching is a technique developed by \citet{domingo-enrich2025adjoint} with the goal of modifying a base flow-matching generative model such that the resulting flow model generates the following tilt distribution:"
- Adjoint state: The backward-propagated gradient-like quantity used in adjoint methods to compute sensitivities along trajectories. "Let the adjoint state be the gradient of the tilt function applied at the denoised :"
- Advantage-weighted actor-critic (AWAC): A policy optimization method that weights behavior cloning updates by estimated advantages. "FAWAC (advantage weighted actor critic, AWAC~\citep{nair2020awac} (with flow policy);"
- Backpropagation through time (BPTT): Differentiating through the entire unrolled multi-step process (e.g., denoising dynamics) to compute gradients. "It is worth noting that FBRAC also leverages backpropagation through time (BPTT) similar to BAM,"
- Behavior cloning: Learning a policy by imitating actions from a dataset, often via supervised learning. "we augment the original QSM loss with the standard DDPM loss on as the behavior cloning loss."
- Behavior constraint: A regularization that keeps the learned policy close to a behavior (data) policy, often via KL divergence. "the best policy under the standard KL behavior constraint:"
- Behavior policy: The policy that generated the dataset or serves as a prior for regularization. "We approximate the behavior policy using a flow-matching behavior policy, "
- Best-of-N sampling: Selecting the best action among N sampled candidates according to a value function or heuristic. "no best-of-N sampling (i.e., ) for both our method and all our baselines"
- Brownian motion: A continuous-time stochastic process used to model noise in SDEs. "with being a Brownian motion and being any noise schedule."
- Classifier guidance: Steering diffusion/flow sampling using gradients from an external classifier (or value function) to bias outputs toward desired conditions. "as in diffusion classifier guidance (with the critic function being the classifier)~\citep{dhariwal2021diffusion}."
- Classifier-free guidance: Conditioning guidance for diffusion/flow models without an explicit classifier, typically interpolating conditional and unconditional scores. "classifier guidance/classifier-free guidance~\citep{dhariwal2021diffusion, ho2022classifier},"
- Continuous adjoint method: An optimal control gradient computation technique that uses adjoint dynamics rather than direct backprop through time. "the continuous adjoint method~\citep{pontryagin1962mathematical}."
- Denoising process: The multi-step procedure by which diffusion/flow models transform noise into data samples. "backpropagation through their multi-step denoising process is numerically unstable."
- Diffusion policy: A policy represented by a diffusion model that generates actions via iterative denoising from noise. "Diffusion and flow policies have been explored in both policy gradient methods"
- Ensemble (of critics): Using multiple Q-functions to improve robustness or enable pessimistic estimates. "we use an ensemble of critic functions "
- Entropy term: A regularization in policy optimization encouraging exploration via higher entropy. "we also include the standard entropy term from \citet{haarnoja2018soft} with the automatic entropy tuning trick"
- Exponential moving average (EMA): A smoothed parameter update maintaining a slowly changing target network. " is the exponential moving average of with a time-constant of "
- Flow matching: A training objective for flow models that learns a velocity field matching the interpolation dynamics between noise and data. "Flow models are typically trained with a flow matching objective~\citep{liu2022flow}:"
- Flow model: A generative model that transports a noise distribution to data via a learned time-dependent velocity field. "A flow model uses a time-variant velocity field "
- Fokker–Planck equations: PDEs describing the time evolution of probability densities for stochastic processes, relating SDEs and their marginals. "one may use the Fokker-Planck equations to construct a family of stochastic differential equations (SDE)"
- Inverse temperature (coefficient): A scalar scaling the influence of the value function in an energy-based or regularized policy form. " is the inverse temperature coefficient"
- Langevin dynamics: A sampling method using gradients of log densities (scores) with injected noise. "One solution is to use Langevin dynamics sampling approaches"
- Lean adjoint state: A reduced adjoint state that omits terms vanishing at optimality, improving stability while preserving optima. "the `lean' adjoint state where all the terms in the adjoint state that are zero at the optimum are removed"
- Markov Decision Process (MDP): A formalism for sequential decision-making with states, actions, transitions, and rewards. "We consider a Markov Decision Process (MDP), ,"
- Marginal-preserving SDE: An SDE whose time marginals match those of a chosen interpolation between noise and data. "uses a marginal-preserving SDE with a `memory-less' noise schedule"
- Memory-less noise schedule: A schedule ensuring independence between start and end states of the interpolation (e.g., independent of ). "with a `memory-less' noise schedule (i.e., and are independent),"
- Memory-less SDE: An SDE discretization or formulation where start and end variables are independent, used to avoid unstable backpropagation. "backpropagating through the memory-less SDE as we discuss above"
- Noise-conditioned policy: A policy taking noise as input to generate stochastic actions in a single step. "we learn a 1-step noise-conditioned policy, "
- Noise schedule: The function controlling noise magnitude over time in diffusion/SDE-based models. " being any noise schedule."
- Offline RL: Learning policies solely from logged data without environment interaction during training. "Our first goal (offline RL) is to learn a policy "
- Offline-to-online RL: Pretraining offline then fine-tuning online with environment interaction for improved sample efficiency. "The second goal (offline-to-online RL) is to fine-tune the offline pre-trained policy"
- Ordinary Differential Equation (ODE): A deterministic differential equation used to define flow model trajectories without stochastic noise. "via an ordinary differential equation (ODE) starting from the noise"
- Pessimistic value backup: A target value computation that subtracts a scaled uncertainty term to encourage conservatism. "we use the pessimistic target value backup with a coefficient of "
- Policy extraction: The process of deriving a policy from a value function or a generative model under constraints. "comparing policy extraction methods for flow/diffusion policies"
- Replay buffer: A memory storing past transitions for off-policy learning and data reuse. "by treating the offline dataset as additional off-policy data that is pre-loaded into the replay buffer"
- Rejection sampling: A sampling scheme that filters proposals based on acceptance probabilities, often guided by a critic/value. "refine the action distribution from a base diffusion/flow policy with rejection sampling based on the critic value"
- Reparameterization trick: A gradient estimation method that expresses stochastic sampling as a deterministic function of noise. "via the reparameterization trick~\citep{haarnoja2018soft}"
- Score function: The gradient of the log-density; in diffusion, used for gradient-based sampling. "only the score function for the noise-free distribution is required"
- Sequential Monte Carlo (SMC): A set of particle-based methods with resampling to approximate target distributions and correct guidance bias. "propose to use Sequential Monte Carlo (SMC) that uses resampling procedures to leverage additional test-time compute to correct such bias."
- Stochastic Differential Equation (SDE): A differential equation driven by stochastic processes (e.g., Brownian motion) to model noisy dynamics. "a family of stochastic differential equations (SDE) that admits the same marginals as well:"
- Stochastic optimal control (SOC): Optimization of controls for stochastic dynamics to extremize expected objectives; here used to formalize policy objectives. "such a constrained optimization problem on a flow model can be formulated as a stochastic optimal control (SOC) objective,"
- Temporal-difference (TD) backup: A value learning update bootstrapping from next-state value estimates. "Combined with temporal-difference backup for critic learning, QAM consistently outperforms prior approaches"
- Tilt distribution: A distribution reweighted by an exponential of a value or energy function relative to a base distribution. "generates the following tilt distribution:"
- Vector-Jacobian product (VJP): An efficient way to compute products of a vector with a Jacobian transpose, used in reverse-mode autodiff. "which can be efficiently computed with the vector-Jacobian product (VJP) in most modern deep learning frameworks"
- Velocity field: The time-dependent vector field that pushes samples along the flow from noise to data. "A flow model uses a time-variant velocity field "
- Wasserstein distance (W_q): An optimal transport distance between probability distributions parameterized by order q and a ground metric. "where is the -Wasserstein distance between under some metric "
Collections
Sign up for free to add this paper to one or more collections.