OmniTransfer: All-in-one Framework for Spatio-temporal Video Transfer
Abstract: Videos convey richer information than images or text, capturing both spatial and temporal dynamics. However, most existing video customization methods rely on reference images or task-specific temporal priors, failing to fully exploit the rich spatio-temporal information inherent in videos, thereby limiting flexibility and generalization in video generation. To address these limitations, we propose OmniTransfer, a unified framework for spatio-temporal video transfer. It leverages multi-view information across frames to enhance appearance consistency and exploits temporal cues to enable fine-grained temporal control. To unify various video transfer tasks, OmniTransfer incorporates three key designs: Task-aware Positional Bias that adaptively leverages reference video information to improve temporal alignment or appearance consistency; Reference-decoupled Causal Learning separating reference and target branches to enable precise reference transfer while improving efficiency; and Task-adaptive Multimodal Alignment using multimodal semantic guidance to dynamically distinguish and tackle different tasks. Extensive experiments show that OmniTransfer outperforms existing methods in appearance (ID and style) and temporal transfer (camera movement and video effects), while matching pose-guided methods in motion transfer without using pose, establishing a new paradigm for flexible, high-fidelity video generation.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
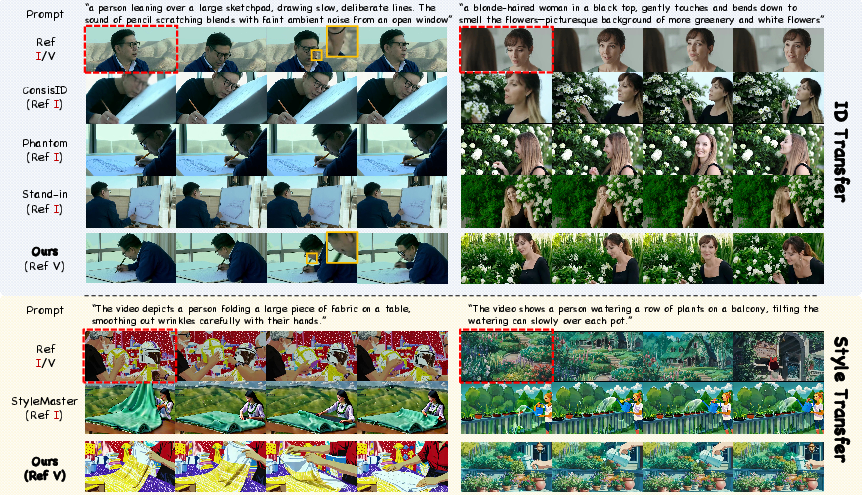
This paper introduces OmniTransfer, a tool that helps AI create new videos by learning from an example video. It doesn’t just copy how things look (like a person’s face or an art style), but also how things move over time (like camera panning, dancing, or special effects). The big idea is to use one system to handle many video “transfer” tasks in a flexible, high-quality way.
What questions does the paper try to answer?
To make the problem easy to understand, think of these goals:
- How can we make a new video that keeps the same identity or style as a reference video?
- How can we make a new video move like the reference—same dance, same camera motion, or similar visual effects?
- Can we do all these different tasks using one unified method instead of many separate tools?
- Can we make the process fast, reliable, and work well on real-world videos?
How does OmniTransfer work?
OmniTransfer is built on a “diffusion” video model. Diffusion is like starting with TV static and gradually “painting” a clear video by learning patterns from data. The model uses attention (like a spotlight that focuses on the most important parts of the video and text) and positional information (clues about where something is in the frame and when it appears in time).
OmniTransfer adds three key ideas:
- Task-aware Positional Bias (TPB)
- Analogy: Imagine you’re organizing comic panels. For motion tasks, you line panels side-by-side to compare movement. For style/identity tasks, you stack panels over time to keep the look consistent.
- What it does: It slightly “shifts” the model’s sense of position differently depending on the task. This helps the AI use the right kind of context:
- For temporal tasks (motion, camera, effects): it uses spatial context to keep movements aligned.
- For appearance tasks (identity, style): it uses time context to spread consistent looks across frames.
- Reference-decoupled Causal Learning (RCL)
- Analogy: Think of a teacher and a student. The teacher shares knowledge with the student, but the student doesn’t change the teacher. This prevents simple copy-paste.
- What it does: It separates the reference video branch from the target video branch and makes information flow in one direction—from reference to target. This:
- Avoids lazy copying.
- Cuts computation, making the system about 20% faster.
- Task-adaptive Multimodal Alignment (TMA)
- Analogy: A smart assistant that understands both pictures and words and knows which details matter for each job.
- What it does: It uses a multimodal AI (Qwen-2.5-VL) that reads the reference video, the target’s first frame, and the text prompt. It then picks out the most useful signals for the specific task (e.g., motion vs. style) and guides the video generation with that understanding, using a lightweight tuning method called LoRA.
Putting it together:
- The system takes a reference video and either a starting image or a text prompt.
- It builds special “latents” (compressed representations) for both reference and target.
- It applies TPB to position information, uses RCL for one-way guidance, and adds TMA for smarter task-specific control.
- It then generates a new video that matches the desired look or movement.
What did they find?
The team tested OmniTransfer on five tasks and compared it with leading methods:
- Identity transfer: It kept faces and details more consistently across different angles and frames than other methods. It also scored well on face-similarity and text alignment metrics.
- Style transfer: It captured the visual style from the reference better while keeping good quality and matching the prompt.
- Effect transfer: In user studies, people judged OmniTransfer’s results as most faithful to the reference video’s effects and visually better than strong baselines.
- Camera movement transfer: It reproduced complex camera motions (like cinematic pans and tracking shots) more accurately and at variable resolutions, outperforming existing tools.
- Motion transfer: Even without pose inputs, it matched or came close to top pose-guided methods on movement quality, while preserving appearance more naturally.
Extra wins:
- Works on “in-the-wild” videos (not just clean, controlled data).
- Handles combinations of tasks (like style + camera motion).
- About 20% faster thanks to the decoupled design.
Why is this important?
- A single, flexible tool: Instead of needing different systems for identity, style, camera movement, and effects, creators can use one framework.
- More realistic videos: It keeps appearance consistent across multiple views and frames, and captures motion smoothly.
- Easier creative control: Filmmakers, animators, and content creators can guide videos using both text and video references—and combine them.
- Better generalization: It works across different scenes and tasks, making it practical for real-world use.
Final thoughts and impact
OmniTransfer shows that reference videos carry rich clues—not just how things look, but how they move—and that AI can use all of this at once. By unifying appearance and temporal transfer, it points toward a future where making high-quality, custom videos is faster, easier, and more controllable.
Potential uses include:
- Film and advertising: matching a camera style or visual look across shots.
- Social media and entertainment: consistent identity or style in creative edits.
- Education and training: demonstrating motions or effects using clear examples.
As with any powerful media tool, responsible use matters—especially around identity, copyright, and consent. The paper focuses on academic, non-commercial exploration, but its ideas could shape the next generation of video creation tools.
Knowledge Gaps
Below is a single, actionable list of the paper’s knowledge gaps, limitations, and open questions that remain unresolved.
- Core assumption unvalidated: the claim that “video diffusion models inherently handle temporal consistency through spatial context” is only supported by a small qualitative probe; a systematic validation across architectures, datasets, and shot types is missing.
- Heuristic RoPE offset design: fixed offsets
Δ=(0, w_tgt, 0)for temporal tasks andΔ=(f, 0, 0)for appearance tasks lack sensitivity analysis, principled derivation, or adaptive scheduling; it is unclear when these offsets help or harm. - Height dimension left unexplored: the effect of
Δ_Hor combinedΔ_WandΔ_Hoffsets on temporal alignment and spatial consistency is not studied. - Generality to other base models: OmniTransfer is only evaluated on Wan 2.1 I2V 14B; portability to UNet-based T2V models, other DiT variants (e.g., 28B), and open-source baselines is unknown.
- Computational and memory profiling: the reported ~20% runtime reduction with Reference-decoupled Causal Learning (RCL) is not accompanied by detailed FLOPs/memory breakdowns across resolutions, frame counts, and hardware; scalability trade-offs are unclear.
- Copy-paste/leakage measurement: while RCL is claimed to mitigate direct copying, there is no quantitative metric for identity/content leakage across tasks (e.g., ID leaking into style/effect transfer).
- Reference branch noise handling: the reference latent is kept noise-free (
t=0); robustness to noisy, compressed, or artifact-laden reference videos and train–test mismatch remain unexplored. - Resolution/aspect ratio mismatch: the mechanism for aligning reference and target latents under differing resolutions/aspect ratios (e.g., resampling strategy, anti-aliasing) is under-specified; the impact on artifacts and consistency is not evaluated.
- MLLM dependency and failure modes: replacing T5 with Qwen-2.5-VL plus MetaQueries is not ablated against alternative MLLMs; sensitivity to prompt quality, template tokens, and MLLM hallucination is not characterized.
- Dataset availability and reproducibility: the collected training/test datasets are not described in detail (scale, diversity, annotation, licensing) and do not appear public, limiting reproducibility and external benchmarking.
- Metrics for temporal tasks: camera and effect transfer rely on small user studies (n=20) without objective metrics; standardized measures (e.g., camera trajectory similarity, optical-flow/motion-consistency scores, effect segmentation consistency) are absent.
- Compositional control evaluation: although compositional task generalization is claimed, there is no quantitative study of simultaneous task combinations (e.g., style+camera+motion) or conflict-resolution strategies.
- Long-duration/high-resolution scalability: experiments focus on ~81 frames at 480p; behavior at 4K, minute-long videos, and memory/time scaling is not reported.
- Multi-person quantitative validation: the method’s “easy extension to multi-person” is shown only qualitatively; quantitative results for multi-person interactions, occlusions, and identity disentanglement are missing.
- Robustness to challenging conditions: performance under fast motion, motion blur, severe occlusion, sudden illumination changes, and shot transitions is not systematically evaluated.
- Non-human generalization: most benchmarks are human-centric (ID, dance, camera shots); transfer quality for animals, vehicles, highly deformable objects, and complex scenes is unknown.
- Fine-grained controllability: interfaces or parameterizations for controlling camera parameters (e.g., focal length, dolly vs. pan), motion amplitude/speed, and effect intensity are not provided or benchmarked.
- Safety and ethics: risks of identity cloning, deepfake misuse, and stylistic appropriation are not addressed; there are no safeguards (e.g., watermarking, consent mechanisms, misuse detection).
- Failure analysis: the paper lacks a systematic characterization of failure cases (e.g., when TPB misaligns temporally, when MLLM guidance is misleading, when copy-paste persists).
- Reference frame selection: the impact of the number, diversity, and sampling strategy of reference frames on performance is not studied; minimal reference requirements remain unknown.
- Domain and language bias: reliance on internet data and an MLLM may introduce domain/language biases; cross-lingual prompts, non-Western styles, and varied cinematography are not analyzed.
- Theoretical understanding: there is no formal analysis of why RoPE offsets enable temporal or appearance transfer, nor comparison to alternative positional encoding schemes (ALiBi, learned embeddings).
- Hybrid priors: combining OmniTransfer with explicit priors (pose skeletons, camera parameters) to improve controllability or robustness is not explored.
- Real-time/streaming generation: latency on commodity GPUs, incremental/online generation, and feasibility for interactive workflows are not evaluated.
- Release and licensing: code, models, and datasets are not clearly released; licensing constraints and compatibility with open-source ecosystems are not specified.
Practical Applications
Immediate Applications
The following applications can be deployed using the paper’s proposed OmniTransfer framework today, given access to the model or equivalent implementations and suitable compute.
- Brand-consistent ad variants and trailers — Media/Marketing
- Description: Generate multiple localized ad/video variants that preserve brand ID (faces, logos, styling), clone camera movement from exemplar spots, and transfer bespoke visual effects without training LoRAs.
- Tools/Workflows: “Brand Motion Cloner” plug-in for Adobe After Effects/Premiere; cloud API that ingests reference videos plus a first-frame or prompt; batch generation pipeline using RCL for faster iteration.
- Assumptions/Dependencies: Rights to reference assets; GPU resources (inference ~142–180s per 480p/81f on 8×A100 per paper); content-safety filters; model access (Wan2.1 I2V backbone or equivalent).
- Previsualization and post-production look replication — Film/TV
- Description: Clone camera trajectories and temporal effects from reference films to previs sequences; preserve actor ID and style while varying scene/prompt; combine tasks (e.g., style+camera+effect).
- Tools/Workflows: Shot ingestion → reference video selection → first-frame storyboard → OmniTransfer generation → editor review → conform; pipeline integration via NLE plug-in.
- Assumptions/Dependencies: Resolution matching workflows; professional QC; licensing/consent for identities; adequate compute.
- Social media personalization: identity-preserving avatars and stylized reels — Consumer Software/Daily Life
- Description: Maintain user face identity across different scenes and styles; apply camera/effect transfer from favorite creators to personal videos without pose rigs.
- Tools/Workflows: Mobile app with cloud inference; preset “camera clone” and “style from video” filters; template library.
- Assumptions/Dependencies: Privacy/consent; scalable cloud backends; simplified UI; moderation to prevent misuse.
- Sports and dance coaching from reference videos — Education/Sports
- Description: Motion transfer from pro dance/sport videos onto a learner’s first-frame to visualize target motion while preserving learner’s appearance; camera movement replication for instructional clarity.
- Tools/Workflows: “Coach Cam” app: upload reference clip → record first frame → generate guided motion sequence; annotate key phases.
- Assumptions/Dependencies: No explicit pose inputs needed (per paper), but requires accurate temporal transfer; liability disclaimers; user consent.
- Game cutscene generation with consistent character identity and cinematography — Gaming/Software
- Description: Rapidly produce cutscenes that keep character ID/style consistent across shots; clone cinematic camera moves; transfer VFX look from franchise references.
- Tools/Workflows: Unreal/Unity plug-ins; asset pipeline adapters; batch automation with task combinations (ID+camera+effects).
- Assumptions/Dependencies: Integration APIs; latency tolerances; IP rights; performance at required resolutions.
- Virtual production previs on LED volumes — Entertainment/AR
- Description: Near-real-time previs sequences with camera movement cloned from references and style/effects applied for director review on set.
- Tools/Workflows: On-set workstation; shot planning tool that generates variants; director selects best camera and effect combination.
- Assumptions/Dependencies: Not real-time at high resolutions; requires high-end GPUs; used for previs, not final pixels.
- E-commerce product video stylization and consistency — Retail/Fashion
- Description: Maintain model identity across multiple product videos; transfer house style and camera moves from exemplar campaigns; apply subtle effect transfer for seasonal looks.
- Tools/Workflows: CMS integration; batch processing jobs; QA loop; asset reuse with ID/style templates.
- Assumptions/Dependencies: Brand rights; data governance; compute budgeting.
- Corporate communications and localization — Enterprise/Media
- Description: CEO/host identity-preserving videos with region-specific styles and camera language; effect transfer for compliance (e.g., lower-third styles).
- Tools/Workflows: Template-driven generation; review/approval workflows; archiving with references.
- Assumptions/Dependencies: Consent/logging; audit trails; watermarking.
- Newsroom production: camera/effect style consistency across multilingual segments — Media/Journalism
- Description: Clone camera moves and graphics effects from main segment to localized variants while maintaining anchor ID.
- Tools/Workflows: Newsroom automation pipeline; ingest segment → reference selection → OmniTransfer pass → editorial QC.
- Assumptions/Dependencies: Strict compliance; content provenance; fair-use analysis.
- Academic research on spatio-temporal in-context learning — Academia/ML
- Description: Use OmniTransfer’s TPB, RCL, and TMA modules to study how spatial offsets drive temporal consistency; reproduce ablations; test task compositions.
- Tools/Workflows: Integrate TPB/RCL/TMA into DiT backbones; benchmark suites for ID/style/motion/camera/effect transfer; user studies.
- Assumptions/Dependencies: Access to model weights or re-implementation; curated datasets (paper’s were collected in-house); ethics approvals for user studies.
- Compliance and content governance dashboards — Policy/Enterprise
- Description: Operationalize RCL to reduce “copy-paste” risk; monitor reference influence; enforce watermarking and consent for ID transfer use.
- Tools/Workflows: Audit logs recording reference-target attention routing; watermark embedding; policy checklists tied to workflows.
- Assumptions/Dependencies: Standardization of audit formats; legal review; integration with enterprise DAM.
Long-Term Applications
These applications are feasible but require further research, scaling, productization, or regulatory work.
- Real-time or on-device OmniTransfer for mobile and wearables — Consumer/Edge AI
- Description: Compress and distill the model to run camera/effect/style transfer on smartphones or smart glasses in near-real-time.
- Tools/Workflows: Model quantization, LoRA adapters, hardware acceleration (NPU/GPU), streaming pipelines.
- Assumptions/Dependencies: Significant model optimization beyond current 14B backbone; battery and thermal constraints; UX safety.
- Autonomous cinematography: robots/drones reproducing learned camera moves — Robotics/Media
- Description: Convert cloned camera movements into physically executable trajectories for camera robots or drones to match cinematic reference shots.
- Tools/Workflows: Trajectory extraction from generated sequences; motion planning and control; safety systems.
- Assumptions/Dependencies: Robust mapping between visual camera paths and robot kinematics; environment awareness; liability and safety regulations.
- Personalized tutoring avatars with consistent ID/style and expressive motion — Education
- Description: Synthetic instructors that preserve identity and style across courses while exhibiting natural motion patterns and camera language tailored to pedagogy.
- Tools/Workflows: LMS integration; content generation pipeline tied to lesson scripts via MLLM semantics; assessment hooks.
- Assumptions/Dependencies: Improved semantic alignment for pedagogy; trust, transparency, and privacy frameworks; institutional approvals.
- Physical therapy and rehabilitation guidance — Healthcare
- Description: Personalized motion transfer from therapist videos onto patient avatars to demonstrate exercises; adjustable camera views for clarity.
- Tools/Workflows: Clinical app; therapist library of reference motions; patient-specific generation; clinician review loop.
- Assumptions/Dependencies: Clinical validation of efficacy and safety; HIPAA/GDPR compliance; clear disclaimers and oversight.
- Live broadcasting augmentation: real-time effect and camera style transfer — Media/Streaming
- Description: Apply effect/camera transfer in live productions (sports/concerts), maintaining presenter ID consistency.
- Tools/Workflows: Stream-processing pipelines; GPU clusters; failover controls; latency-optimized inference.
- Assumptions/Dependencies: Sub-100ms latency goals; robust moderation; fault tolerance; cost control.
- Synthetic dataset generation for multi-view/temporal computer vision — AI/Data
- Description: Produce consistent multi-view identity/style data and camera trajectories to train recognition, tracking, or re-ID models.
- Tools/Workflows: Data engine with controllable task compositions; metadata-rich synthetic sets; domain adaptation procedures.
- Assumptions/Dependencies: Bias and domain-gap assessments; licensing for any reference content; acceptance by CV community.
- Creative suite integration with script-aware multimodal guidance — Software/MediaTech
- Description: End-to-end authoring tools where scripts/storyboards guide task selection (ID/style/motion/camera/effects) via TMA with MLLMs.
- Tools/Workflows: Script ingestion → MLLM scene parsing → task-specific MetaQueries → shot generation → editorial feedback.
- Assumptions/Dependencies: More robust multimodal alignment; enterprise-grade toolchains; user training.
- Regulatory tooling for provenance and accountability — Policy/Governance
- Description: Standards-based reporting of reference influence; mandatory watermarking; consent enforcement and revocation workflows.
- Tools/Workflows: Provenance manifests; cryptographic watermarks; policy APIs integrated with platforms.
- Assumptions/Dependencies: Industry and governmental standards; platform cooperation; legal frameworks.
- AR cultural heritage experiences — Museums/Arts
- Description: Transfer style and camera language from archival films to modern recreations and guided tours, preserving identity of historical figures in educational contexts.
- Tools/Workflows: Curatorial pipelines; visitor devices; on-site edge inference or cloud streaming.
- Assumptions/Dependencies: Ethical approvals; rights to archival material; performance on constrained hardware.
- Smart home content assistants — Daily Life/IoT
- Description: Household devices that generate personalized, identity-consistent family videos with stylized camera moves and effects.
- Tools/Workflows: Voice/script-driven generation; family consent management; local processing.
- Assumptions/Dependencies: Privacy and child-safety protections; efficient edge models; user trust and controls.
Cross-cutting assumptions and dependencies
To ensure feasibility across applications, the following conditions should be considered:
- Compute and performance: Current inference times suggest cloud or workstation deployment; real-time use requires compression/distillation and hardware acceleration.
- Rights and consent: ID transfer and style/effect cloning demand clear rights to reference content and explicit consent for identities; watermarking and audit trails recommended.
- Data availability: The paper uses in-house datasets due to the lack of public paired reference sets; broader deployment benefits from curated, rights-cleared corpora.
- Model access and licensing: The framework is built atop Wan2.1 I2V (14B) and utilizes Qwen-2.5-VL for multimodal alignment; alternative backbones/MLLMs may require adaptation.
- Safety and moderation: Guardrails for deepfake misuse, content filtering, and enterprise compliance must be integrated.
- Integration maturity: Production use requires APIs, plug-ins, and pipelines that encapsulate TPB, RCL, and TMA while exposing simple task controls to end users.
Glossary
- 3D Rotary Positional Embedding (RoPE): A positional encoding technique that applies rotations to attention queries and keys across temporal and spatial axes in video models. "The self-attention adopts 3D Rotary Positional Embedding (RoPE):"
- Attention inversion: A method that manipulates attention maps to transfer or reconstruct patterns without explicit parameterization. "and parameter-free attention inversion~\cite{hu2024motionmaster,motionclone},"
- Binary mask latent: A latent channel indicating which frames/tokens are preserved versus generated in the diffusion process. "binary mask latent with values of 1 for preserved and 0 for generated frames."
- CLIP-T: A metric for evaluating text–video alignment using CLIP-derived features. "we measure text–video alignment using the CLIP-T~\cite{wang2022internvideo} score,"
- Cross-attention: An attention mechanism where queries attend to keys/values from another source modality (e.g., text to video). "Cross-attention integrates textual features as "
- Diffusion inversion: The process of recovering latent trajectories or noise that reconstruct a given sample within a diffusion model. "but most rely on diffusion inversion or test-time finetuning."
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion models, providing self- and cross-attention blocks. "Each Diffusion Transformer (DiT) block in Wan2.1 includes self-attention and cross-attention layers."
- Image-to-Video (I2V): A generation paradigm where a video is synthesized starting from a single input image. "Temporal Transfer (I2V)"
- In-context learning: Conditioning a model on provided reference inputs (images/videos/text) to perform tasks without explicit fine-tuning. "In the first stage, we train the DiT blocks via in-context learning."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects small rank-decomposed updates. "the MLLM is fine-tuned using LoRA~\cite{hu2022lora}."
- MetaQuery: Learnable query tokens designed to collect task-specific information from multimodal inputs. "we draw inspiration from MetaQuery~\cite{pan2025transfer} and introduce a set of learnable tokens dedicated to each task."
- Multimodal LLM (MLLM): A model that jointly processes visual and textual inputs to provide richer semantic guidance. "we introduce a Multimodal LLM (MLLM) via a Task-adaptive Multimodal Alignment module."
- Reference-decoupled Causal Learning: A unidirectional reference-to-target transfer scheme that separates branches to avoid copy-paste behavior and reduce compute. "Second, we introduce Reference-decoupled Causal Learning, which employs unidirectional transfer from reference to target, preventing simple copy-pasting."
- Task-adaptive Multimodal Alignment: A mechanism that aligns multimodal semantic features to the diffusion model based on the specific transfer task. "and Task-adaptive Multimodal Alignment using multimodal semantic guidance to dynamically distinguish and tackle different tasks."
- Task-aware Positional Bias: Task-dependent offsets applied to positional embeddings to enhance either temporal alignment or appearance propagation. "Task-aware Positional Bias that adaptively leverages reference video information to improve temporal alignment or appearance consistency;"
- Temporal context concatenation: Combining reference features along the temporal dimension to share motion/context information. "CamCloneMaster~\cite{camclonemaster} made an initial reference-based attempt on camera motion through temporal context concatenation,"
- Temporal priors: Predefined motion or camera constraints (e.g., pose skeletons) used to guide generation. "task-specific temporal priors,"
- Time embeddings: Embeddings that encode the diffusion timestep (noise level) to condition the model’s denoising process. "We further decouple the time embeddings of the two branches."
- Token-wise concatenation: Concatenating sequences of tokens (e.g., keys/values) along the token dimension to merge contexts. "where denotes token-wise concatenation."
- Variational Autoencoder (VAE): A generative encoder–decoder used to compress video frames into latent codes for diffusion. "adding timestep noise to VAE-compressed video features "
- Video CSD Score (VCSD): A metric assessing style consistency across video frames. "and style consistency with the video CSD Score~\cite{somepalli2024measuring} (VCSD) using four sampled reference frames."
Collections
Sign up for free to add this paper to one or more collections.