RoboBrain 2.5: Depth in Sight, Time in Mind
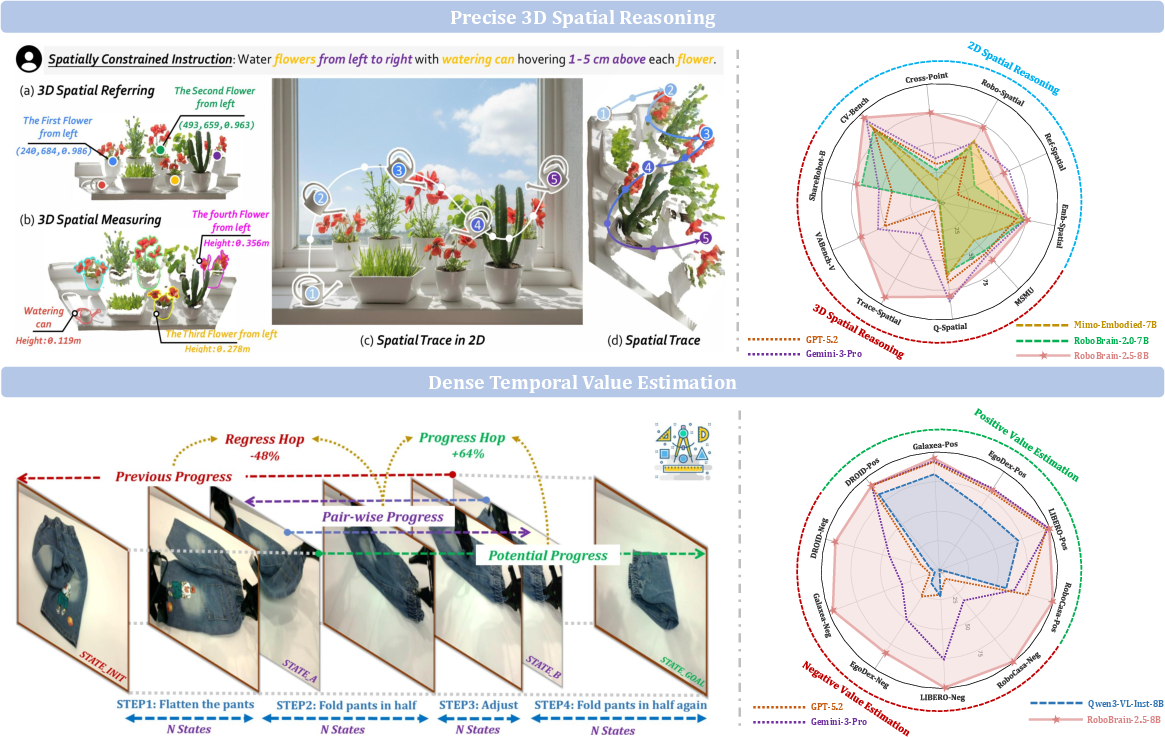
Abstract: We introduce RoboBrain 2.5, a next-generation embodied AI foundation model that advances general perception, spatial reasoning, and temporal modeling through extensive training on high-quality spatiotemporal supervision. Building upon its predecessor, RoboBrain 2.5 introduces two major capability upgrades. Specifically, it unlocks Precise 3D Spatial Reasoning by shifting from 2D pixel-relative grounding to depth-aware coordinate prediction and absolute metric constraint comprehension, generating complete 3D manipulation traces as ordered keypoint sequences under physical constraints. Complementing this spatial precision, the model establishes Dense Temporal Value Estimation that provides dense, step-aware progress prediction and execution state understanding across varying viewpoints, producing stable feedback signals for downstream learning. Together, these upgrades extend the framework toward more physically grounded and execution-aware embodied intelligence for complex, fine-grained manipulation. The code and checkpoints are available at project website: https://superrobobrain.github.io


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces RoboBrain 2.5, a smart model that helps robots understand the real world better. It focuses on two big improvements:
- Seeing depth so robots can plan precise movements in 3D space.
- Understanding time so robots can track how far along a task they are, step by step, and correct themselves if things start going wrong.
The goal is to make robots not just “think” about tasks in words or pictures, but act reliably in the physical world where distances, angles, and timing really matter.
Key Questions
The paper tries to answer simple but important questions:
- How can a robot figure out exactly where things are in 3D, not just on a flat image?
- How can a robot measure real-world distances (like centimeters) and plan movements that avoid collisions?
- How can a robot tell whether it’s making progress, stuck, or going backward, just from what it sees?
- Can these abilities make robots more reliable in long, complex tasks?
How They Did It
Seeing Depth: Precise 3D Spatial Reasoning
Think of a robot looking at a photo. In 2D, it can point to a pixel on the screen. In 3D, it needs to know “where on the screen” plus “how far away” the point is. RoboBrain 2.5 predicts coordinates as (u, v, d):
u, v: the position on the image (like the exact spot on your phone screen),d: depth, meaning how far away that spot is in the real world.
Using known camera settings (like a phone’s lens details), the robot converts (u, v, d) into full 3D positions. This lets it plan precise paths in space, like a dotted line of key points the robot should follow—called a “3D manipulation trace.” It’s like drawing a route in mid-air that avoids bumps and keeps a safe distance.
To make this work, the model is trained to do three related skills, all from regular RGB images (no special sensors):
- Spatial referring: finding the right object and its order (e.g., “water the flowers from left to right”).
- Spatial measuring: estimating real distances (e.g., “hover 1–5 cm above each flower”).
- Spatial tracing: producing a full sequence of 3D keypoints that guide the robot’s motion while respecting physical limits.
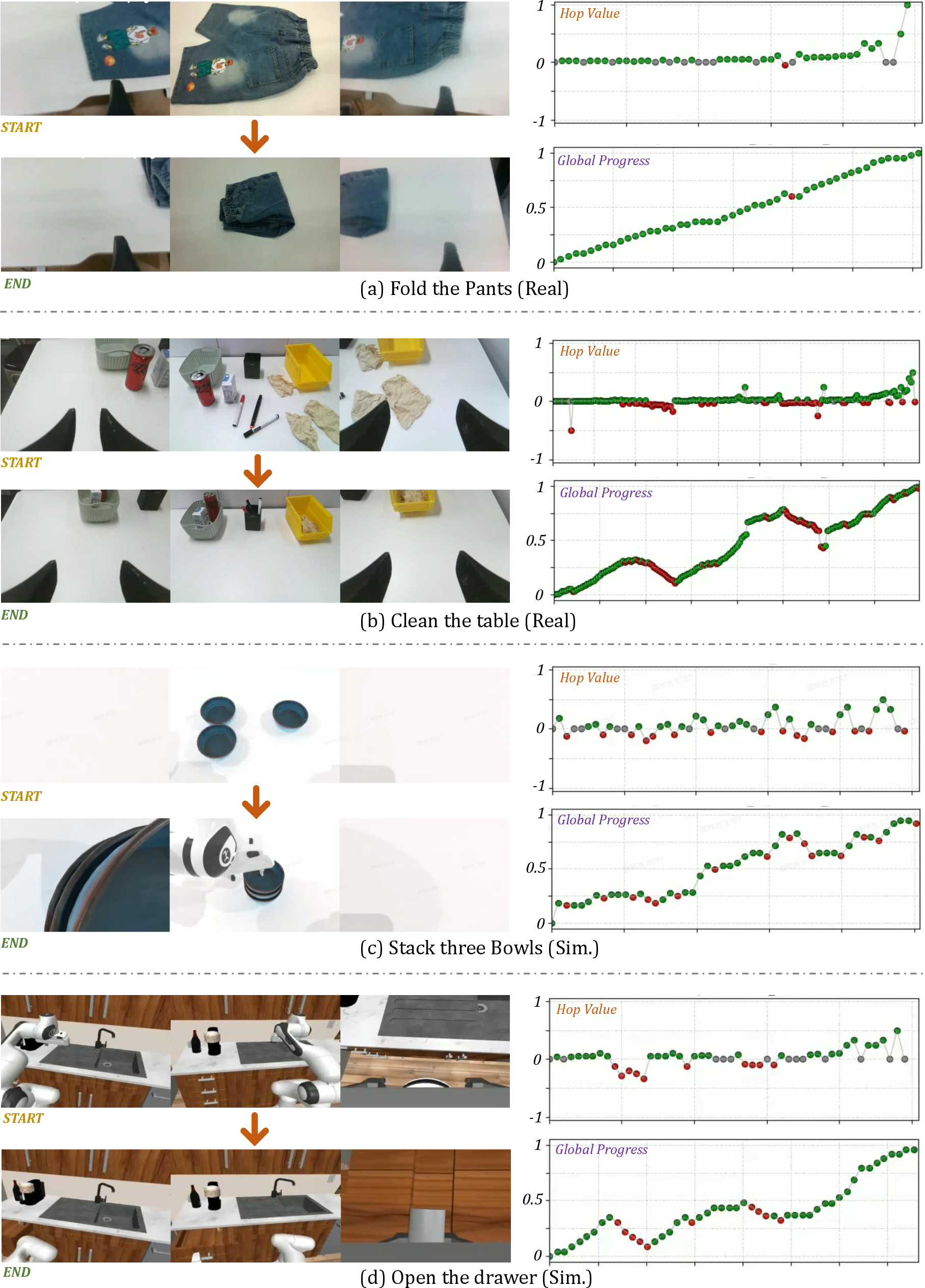
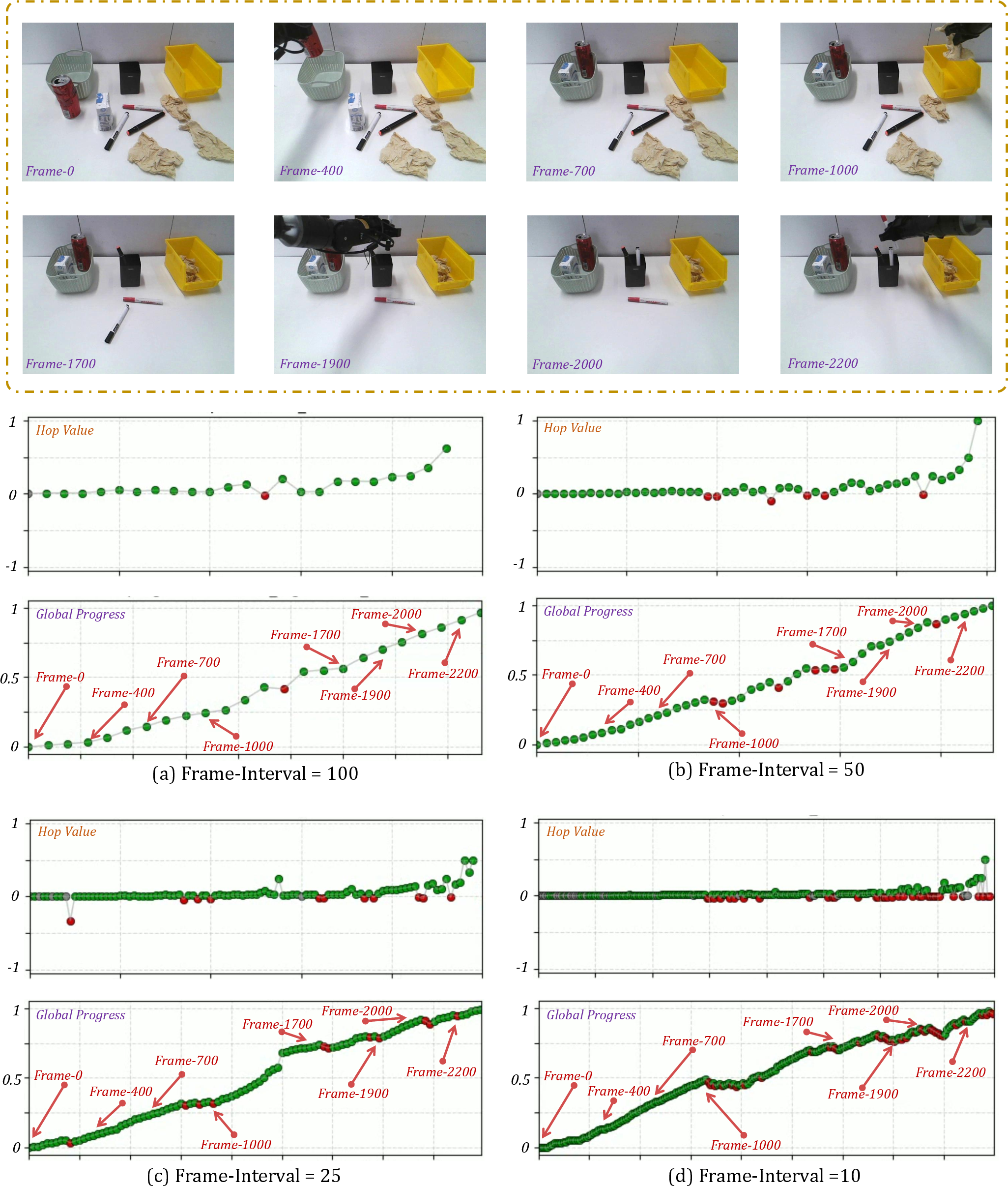
Feeling Time: Dense Temporal Value Estimation
Robots often guess a full plan and then execute it blindly. If something slips or gets stuck, they don’t notice until the end. RoboBrain 2.5 changes that by producing a “progress signal” at every step, based only on what it sees. Think of it like a live progress bar that:
- Goes up when the robot gets closer to the goal,
- Drops if it moves away,
- Stays steady if nothing changes.
To keep this signal stable and meaningful, the paper uses a “hop-based” idea: it measures how much closer a new state is compared to how far is left to go, normalizing it so values stay between -1 and 1. This keeps progress estimates steady even across different viewpoints or tasks.
It then “fuses” the progress estimate from three angles:
- Incremental: step-by-step (good for local changes but may drift over time).
- Forward-anchored: compare the current step to the very beginning (stable early on).
- Backward-anchored: compare the current step to the goal (sensitive near the end).
Averaging these three gives a robust final progress estimate. There’s also a safety check: if the forward and backward views disagree a lot (a sign the scene is strange or outside the training data), the model becomes cautious and reduces the confidence of its update. This helps prevent “reward hacking,” where a robot might misread the scene and think it’s succeeding when it’s not.
Training and Data
RoboBrain 2.5 was trained in two phases using millions of examples:
- Phase 1: Build general skills—recognizing objects, basic 2D spatial grounding, and planning in simple steps.
- Phase 2: Add precision—3D metric reasoning (real measurements) and dense progress estimation.
The data mix is large and varied, combining:
- General visual-language data to keep broad understanding,
- Spatial datasets for pointing, measuring, and tracing in 3D,
- Temporal datasets (videos and robot recordings) to learn step-aware progress.
This variety helps the model handle different robots, scenes, and viewpoints without overfitting to a single setup.
Main Findings
The paper reports that RoboBrain 2.5:
- Improves 3D spatial reasoning: it predicts depth-aware positions and full 3D keypoint traces that follow physical constraints, leading to more precise, collision-free motions.
- Improves temporal tracking: it produces stable, step-wise progress signals from visual input alone, even when the camera view changes or objects are partly hidden, which is useful for reinforcement learning.
- Performs better on spatial and temporal benchmarks compared to prior models.
- Shows stronger “zero-shot” robustness in real, contact-rich tasks (meaning it works well on new tasks without retraining), translating success from demos to actual deployment.
Why It Matters
Robots don’t live in tidy, controlled demos. They work in messy, changing environments where distances and timing are crucial. By giving robots “Depth in Sight” and “Time in Mind,” RoboBrain 2.5 moves foundation models closer to truly embodied intelligence:
- It helps robots understand the exact 3D layout of the world and plan movements that respect real measurements.
- It lets robots monitor their own progress continuously, notice issues early, and adjust on the fly.
This can lead to more reliable household helpers, factory robots, and assistive devices—systems that are safer, more precise, and better at completing long, detailed tasks. The team has shared code and checkpoints, so others can build on these advances and test them in their own robotic setups.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future work could address.
- Quantify depth accuracy: provide absolute error metrics (e.g., mm, cm) across distance ranges, object types, and scenes; validate “millimeter-level clearance” claims under lens distortion and rolling shutter.
- Reliance on known camera intrinsics: assess performance when intrinsics are unknown, imprecise, or drifting; develop self-calibration or online estimation to maintain
(u, v, d)fidelity. - Coordinate frame ambiguity: evaluate world-frame vs camera-frame outputs; study robustness when extrinsics change (moving camera, pan-tilt, robot-mounted cameras).
- Monocular RGB depth limitations: characterize failure modes with low-texture, specular/transparent surfaces, low light, motion blur; report how errors impact 3D trace safety.
- Trace-to-trajectory mapping: specify and evaluate how 3D keypoint traces are converted to executable joint-space paths under kinematic limits, dynamics, and tool constraints.
- Collision avoidance guarantees: clarify whether collision-free traces rely on learned priors or explicit geometry checks; integrate and benchmark physics-based collision checking in clutter.
- Deformable and fluid interactions: extend measuring/tracing to deformables, soft objects, and liquids; quantify accuracy and stability in contact-rich, compliant tasks.
- Dynamic scenes and moving targets: evaluate closed-loop replanning when targets move or the scene changes; measure time-to-recovery and success under disturbances.
- Uncertainty quantification: add confidence estimates for 3D spatial referring/measuring/tracing; assess how uncertainty propagates to downstream control and safety.
- Multi-view vs single-view inference: training uses multi-view for temporal labels; analyze single-view inference robustness, occlusion handling, and view invariance.
- Unit handling and conversion: test accuracy across mixed unit outputs (cm/inch/m); detect and correct unit misinterpretations under language ambiguity.
- Pseudo-3D scene graph reliability: measure end-to-end errors from UniDepth/WildeCamera + SAM/GroundingDINO pipelines; report how these errors affect downstream 3D tasks.
- Hop-based labeling scalability: reduce reliance on human-annotated keyframes; explore automatic segmentation/labeling and quantify label noise impacts on value estimation.
- Theoretical guarantees: beyond keeping reconstructed progress in [0,1], provide bounds on accumulated error/drift under stochastic hop prediction; analyze stability in long horizons.
- Consistency weighting design: systematically tune and justify the
αsensitivity; compare to Bayesian calibration, ensemble methods, or learned uncertainty models. - OOD reward hacking resistance: run adversarial/OOD stress tests; quantify false positives/negatives in progress estimates and their impact on policy exploitation.
- RL integration specifics: detail how dense value signals are used (reward shaping, Q-value targets, policy ranking) and benchmark sample efficiency vs baselines on standard RL suites.
- Fusion strategy ablation: compare simple averaging to learned fusion (attention, gating), per-context weighting, or confidence-aware blending across incremental/anchored predictors.
- Calibration across embodiments: verify progress/value estimates remain comparable across robot morphologies; ensure embodiment-invariant predictions do not silently bias certain kinematics.
- Dataset bias and coverage: quantify indoor/tabletop skew; test generalization to outdoor, large-scale, and industrial environments; address long-tail categories and rare spatial relations.
- Dense scenes filtering effects: object pointing filter (≤10 points) may reduce clutter diversity; evaluate performance in highly cluttered/stacked scenarios.
- Anti-forgetting replay ratio: justify the 15% replay choice; run ablations on replay percentage, sampling strategy, and their impact on general vs specialized capabilities.
- Benchmark transparency: provide exact benchmark names, metrics, splits, and absolute numbers; release evaluation scripts to ensure reproducibility of radar plot claims.
- Real-world deployment details: report task counts, environments, success rates, statistical significance, failure analyses, and run-time logs for “zero-shot robustness” claims.
- Inference latency and resource footprint: measure end-to-end latency (including perception, planning, tracing, value estimation), memory use, and throughput on edge robot hardware.
- Safety in contact-rich tasks: integrate force/torque sensing or tactile feedback; evaluate damage risk, compliance control, and safe fallback behaviors under trace errors.
- Cross-sensor generalization: test across diverse cameras (fisheye, depth sensors, mobile phones), varying intrinsics/extrinsics, and mixed sensor modalities.
- Multi-robot execution: beyond synthetic planning data, demonstrate coordinated execution; quantify communication, task allocation, and conflict resolution in real multi-agent settings.
- Privacy/licensing: clarify licensing and privacy compliance for human-centric data (e.g., EgoDex), especially for deployment in public environments.
- Long-horizon stability: evaluate progress drift and trace consistency over thousands of steps; test memory limits and recovery mechanisms for extended tasks.
- Failure recovery policies: the estimator detects regression, but policy-level recovery strategies remain unspecified; design and evaluate structured recovery plans.
- Explainability and debugging tools: provide visualization of 3D traces, spatial constraints, and progress estimates; enable practitioners to diagnose and correct model errors.
- Robustness to environmental shifts: systematically quantify sensitivity to lighting changes, seasonal variations, sensor noise, and domain shifts beyond training distributions.
Practical Applications
Below we translate RoboBrain 2.5’s core advances—precise 3D spatial reasoning via depth-aware (u, v, d) traces and dense, viewpoint-robust temporal value estimation—into practical applications. Each item notes sector(s), potential tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Trace-to-trajectory execution for precision manipulation (robotics, manufacturing, logistics)
- Tools/workflows: “3D Trace Generator” node feeding MoveIt/ROS 2; IK/collision checking converts (u, v, d) keypoint traces to robot joint trajectories; safety monitor halts on regress signals.
- Assumptions/dependencies: Known camera intrinsics/extrinsics and hand–eye calibration; trace-to-orientation policy or grasp planners; sufficient inference compute for ~8B model.
- Dense value estimator as a drop-in critic for RL and LfD (software, robotics R&D)
- Tools/workflows: PPO/SAC wrappers that replace sparse rewards with hop-normalized progress; “Critic-as-a-Service” API; policy ranking and early stopping based on progress.
- Assumptions/dependencies: Access to initial and goal references (images or canonical state descriptors); domain coverage to avoid OOD reward hacking; multi-perspective fusion and consistency weighting enabled.
- Vision-only metrology and clearance checking on production lines (manufacturing, QA)
- Tools/products: Monocular RGB QA stations that measure gap/offset vs. spec; automated “go/no-go” checks for assemblies and fixtures.
- Assumptions/dependencies: Accurate intrinsics, rigid mounts, stable lighting; verification against ground-truth gauges; acceptable tolerance (cm–mm depends on calibration and environment).
- Packing, stacking, and bin-picking with metric constraints (logistics, e-commerce fulfillment)
- Tools/workflows: 3D spatial traces for collision-aware approach/retreat; progress-based error detection triggers regrasp or replan.
- Assumptions/dependencies: Reliable object detection/segmentation; grasp synthesis; workspace CAD or online mapping for collision models.
- Drawer, cabinet, and appliance manipulation with closed-loop recovery (service robotics, facilities)
- Tools/workflows: Trace primitives (pull, hinge-following) with temporal progress to detect slip/stall and apply compliance or retry.
- Assumptions/dependencies: Force/torque safety limits; per-site calibration; handle/keypoint detection under occlusions.
- Teleoperation assistance with 3D overlays and progress bars (industrial service, field ops)
- Tools/products: AR UI that visualizes keypoint traces and live progress/regress to guide human operators.
- Assumptions/dependencies: Scene registration (camera-to-world), latency budget, robust tracking under viewpoint changes.
- Anomaly detection and safety gating in autonomous cells (operations, safety)
- Tools/workflows: Runtime watchdog that pauses on regress/error or OOD inconsistency (forward vs. backward anchored predictions diverge).
- Assumptions/dependencies: Well-tuned thresholds; access to goal exemplars; integration with PLC/safety interlocks.
- Automated task-phase labeling and chaptering for how-to videos (media/education)
- Tools/products: Progress timeline extractor for tutorials; segment-level feedback on “what step the user is in.”
- Assumptions/dependencies: Domain adaptation from robot/human corpora; clear visual affordances; minimal occlusion.
- Data annotation acceleration for embodied datasets (ML tooling, academia)
- Tools/workflows: Semi-automatic point/trace labeling from monocular frames; metric questions (“how far,” “how high”) auto-answered in cm/inch.
- Assumptions/dependencies: Intrinsics/EXIF availability; human-in-the-loop QA for edge cases; consistent unit handling.
- Progress-aware data collection and curriculum scheduling (research infrastructure)
- Tools/workflows: Collect more samples where progress stagnates; balance hop/distance bins; terminate rollouts on plateau.
- Assumptions/dependencies: Online access to value estimator; sampling policies respecting OOD safeguards.
- Consumer measurement on smartphones for home tasks (daily life, DIY)
- Tools/products: App measures distances/clearances or suggests 3D placement traces for hanging, mounting, or arranging items.
- Assumptions/dependencies: Phone camera intrinsics (ARKit/ARCore helpful), simple calibration UX, disclaimers for tolerance.
Long-Term Applications
- Reliable household robots for fine-grained manipulation (consumer robotics, smart home)
- Tools/products: General-purpose home robot stack using (u, v, d) trace plans and dense progress for robust, closed-loop actions.
- Assumptions/dependencies: Cost-effective hardware, safe force control, broad generalization across homes and clutter types; regulatory/safety approvals.
- Surgical and interventional robotics progress monitoring and micro-tracing (healthcare)
- Tools/workflows: Vision-only progress estimation during procedures; metric micro-traces for tool guidance.
- Assumptions/dependencies: Sub-mm accuracy, medical-grade validation, sterility and lighting constraints, stringent regulation (FDA/CE).
- Autonomous construction and retrofit QA (construction, AEC)
- Tools/products: Robots verify code-compliant clearances, align fixtures, and execute metric-constrained placements; as-built checks via monocular cameras.
- Assumptions/dependencies: Harsh environment robustness, large-scale calibration, BIM alignment, safety certifications.
- Multi-robot orchestration with progress-synchronized workflows (warehouses, restaurants, hospitals)
- Tools/workflows: Shared progress states coordinate handoffs; value-based scheduling (prioritize agents near completion).
- Assumptions/dependencies: Reliable comms, task graphs and SLAs, cross-embodiment policy abstractions.
- Universal “Reward-as-a-Service” for autonomous learning from diverse videos (software platforms)
- Tools/products: Cloud API scoring progress in arbitrary tasks to accelerate self-improvement and ranking of policies/demo quality.
- Assumptions/dependencies: Strong OOD detection; privacy and IP-safe video ingestion; scalable, low-latency inference.
- AR guidance for human skill acquisition with step-aware feedback (education, workforce training)
- Tools/products: Wearable or mobile AR gives exact 3D pointers and progress coaching for assembly/repair/cooking skills.
- Assumptions/dependencies: Real-time tracking and registration, safe overlays, curriculum design, varied environment adaptation.
- High-precision micro-assembly and electronics manufacturing (advanced manufacturing)
- Tools/workflows: Millimeter-to-sub-mm placement traces and progress-verifiable steps for soldering, connector mating, and adhesive application.
- Assumptions/dependencies: Extreme calibration precision, vibration control, cleanroom constraints, orientation/force models.
- Autonomous inspection and maintenance with metric diagnostics (energy, utilities, infrastructure)
- Tools/products: Drones/rovers measure clearance, sag, corrosion progression, or valve states with dense progress toward resolution tasks.
- Assumptions/dependencies: Outdoor lighting/weather robustness, long-range calibration, safe navigation, goal exemplars for backward anchoring.
- Self-improving embodied agents bootstrapped from internet-scale human videos (academia, frontier AI)
- Tools/workflows: Use dense progress as a universal signal to mine subgoals, discover skills, and learn reward models across embodiments.
- Assumptions/dependencies: Domain gap bridging human↔robot; scalable curation; safety filters to prevent reward hacking.
- Standards and policy for metric-grounded embodied datasets and camera metadata (policy, standards bodies)
- Tools/workflows: Procurement guidelines requiring camera intrinsic/extrinsic disclosure; benchmarks for progress estimator reliability and OOD consistency.
- Assumptions/dependencies: Cross-industry consensus, open benchmarks, conformance tests, privacy-preserving data specs.
Notes on common dependencies across applications:
- Camera geometry: (u, v, d) requires known intrinsics; performance scales with calibration quality and scene conditions.
- Goal specification: Backward-anchored predictions assume access to a goal image or canonical goal state; workflows must manage this artifact.
- Control stack integration: 3D traces must be converted to robot-specific trajectories (IK, orientation, speed/force profiles, collision checks).
- OOD safety: Bi-directional consistency gating should be kept on by default; environment/domain adaptation may be necessary.
- Compute and latency: An ~8B multimodal model may need GPU acceleration or quantized/ distilled variants for edge devices.
Glossary
- 3D Spatial Measuring: Estimating absolute real-world quantities (e.g., distances, clearances) from visual inputs to satisfy physical constraints. Example: "3D Spatial Measuring to estimate absolute metric quantities (e.g, distance, clearance) required by physical constraints"
- 3D Spatial Referring: Localizing objects and resolving spatial relationships in 3D scenes to identify targets for manipulation. Example: "3D Spatial Referring to localize objects"
- 3D Spatial Trace Generation: Producing ordered, collision-free 3D keypoint trajectories that serve as spatial plans for manipulation. Example: "3D Spatial Trace Generation to produce collision-free keypoint traces"
- 3D spatial trace: An ordered sequence of 3D points representing a full manipulation path in space. Example: "generate a 3D positional sequence, named as 3D spatial trace"
- Absolute metric constraints: Physical limits expressed in real-world units that actions must respect (e.g., exact distances/clearances). Example: "they demand that robots respect absolute metric constraints"
- Axis-aligned 3D boxes: Bounding boxes oriented with the coordinate axes that encapsulate 3D objects. Example: "yielding axis-aligned 3D boxes"
- Backward-Anchored Prediction: A progress estimation anchored at the goal state to improve sensitivity near completion. Example: "Conversely, Backward-Anchored Prediction is anchored to the goal state , where progress is one."
- Bi-directional Consistency Checking: A reliability mechanism that compares forward- and backward-anchored progress predictions to detect OOD errors. Example: "we propose a bi-directional consistency checking strategy"
- Camera intrinsics: Internal camera parameters (e.g., focal length, principal point) used to project between image and 3D coordinates. Example: "using known camera intrinsics."
- Catastrophic forgetting: The tendency of a model to lose previously learned abilities when fine-tuned on new tasks. Example: "To prevent the catastrophic forgetting of general capabilities"
- Closed-loop control: Control that continuously uses feedback to adjust actions during execution. Example: "enabling robust closed-loop control and efficient RL."
- Collision-free 3D trajectories: Paths in 3D space that avoid intersections with objects or obstacles. Example: "generate collision-free 3D trajectories"
- Conservative State Update: A cautious progress update rule that down-weights uncertain estimates to prevent exploitation in OOD states. Example: "Conservative State Update."
- Decoupled (u, v, d) representation: A coordinate format separating image-plane position and depth for easier 3D reasoning via camera intrinsics. Example: "we adopt a decoupled representation"
- Dense Temporal Value Estimation: Vision-based, frame-by-frame progress/regress assessment providing continuous value feedback for control. Example: "we introduce Dense Temporal Value Estimation"
- Embodiment-invariant progress feedback: Progress signals that generalize across different robot bodies and kinematics. Example: "enabling the model to provide stable, embodiment-invariant progress feedback"
- End-effector: The working tool or gripper at the end of a robot arm that interacts with the environment. Example: "e.g, a robot end-effector or an object"
- Forward-Anchored Prediction: A progress estimation anchored at the initial state to provide a stable global reference. Example: "Forward-Anchored Prediction provides a stable global reference"
- Hop-based labeling strategy: A normalization scheme that labels progress between state pairs relative to remaining or covered distance to the goal. Example: "we apply the hop-based labeling strategy described in \Cref{subsec:dense_temporal_value_estimation}"
- Hop-wise Progress Construction: The process of constructing training targets by discretizing trajectories and labeling normalized progress hops. Example: "Hop-wise Progress Construction"
- Incremental Prediction: Step-by-step progress estimation that accumulates local hop predictions through a trajectory. Example: "Incremental Prediction offers a fine-grained, step-by-step assessment."
- Kinematic feasibility: The property that a planned motion can be physically executed given the robot’s kinematic constraints. Example: "to ensure kinematic feasibility"
- Metric blindness: The failure of models to perceive or reason about absolute depth and scale, leading to physically invalid plans. Example: "models suffer from ``metric blindness.''"
- Metric-grounded: Explicitly tied to real-world measurements and units, as opposed to qualitative or relative descriptions. Example: "metric-grounded outputs"
- Multi-Perspective Progress Fusion: Combining incremental, forward-anchored, and backward-anchored predictions to reduce drift and improve robustness. Example: "we fuse dense temporal value estimates from three complementary perspectives"
- Multi-view expert trajectories: Demonstrations captured from multiple camera viewpoints used to learn progress/value estimators. Example: "modeling general reward on multi-view expert trajectories"
- Observation-Thought-Action (OTA) trajectories: Logged sequences that interleave visual observations, internal reasoning, and executed actions. Example: "synthesized Observation-Thought-Action (OTA) trajectories"
- Open-loop predictors: Models that generate actions without monitoring and adjusting for execution feedback during rollout. Example: "models usually operate as ``open-loop'' predictors."
- Out-of-Distribution (OOD) hallucination: Spurious, overconfident predictions made on states not covered by the training data. Example: "faces the risk of Out-of-Distribution (OOD) hallucination."
- Pipeline Parallelism (PP): Splitting model layers across devices to pipeline different stages of computation during training. Example: "Pipeline Parallelism (PP)"
- Pseudo-3D scene graphs: Scene graphs derived from 2D images augmented with depth estimation to approximate 3D structure. Example: "convert them into pseudo-3D scene graphs."
- Reward hacking: Exploiting flaws in the reward/value estimator to achieve high rewards without solving the intended task. Example: "leading to ``reward hacking.''"
- Spatiotemporal supervision: Training signals that jointly supervise spatial and temporal aspects of perception and control. Example: "extensive training on high-quality spatiotemporal supervision."
- Step-aware progress prediction: Estimating progress at the granularity of individual steps or frames to enable fine-grained feedback. Example: "provides dense, step-aware progress prediction"
- Tensor Parallelism (TP): Partitioning tensors (e.g., along the model’s dimensions) across devices to parallelize computation. Example: "Tensor Parallelism (TP)"
- Temporal Value Comparison: A training task where models learn to order or compare frames by their progress states rather than regressing absolute values. Example: "we introduce a Temporal Value Comparison task"
- Top-down occupancy maps: Bird’s-eye grid representations encoding object positions and free space for planning and placement. Example: "generate top-down occupancy maps"
- Value function (Critic): A model that predicts the expected progress or return from a given state; used to guide control or RL. Example: "act as a robust value function (Critic)"
- Vision-Language-Action (VLA) models: Systems that map language and vision inputs to executable actions in embodied tasks. Example: "Vision-Language-Action (VLA) models"
Collections
Sign up for free to add this paper to one or more collections.