- The paper introduces Retrieval Performance Prediction (RPP) and Generation Performance Prediction (GPP) tasks to estimate the contextual utility and factual quality in RAG.
- The study leverages both pre-generation and post-generation modes, demonstrating that integrating answer perplexity with QPP methods significantly enhances prediction accuracy.
- Experimental results on the Natural Questions dataset reveal that prediction performance degrades with larger context sizes, highlighting the need for adaptive, query-sensitive RAG pipelines.
Predicting Retrieval Utility and Answer Quality in Retrieval-Augmented Generation (2601.14546)
Introduction and Motivation
This paper addresses prediction challenges in Retrieval-Augmented Generation (RAG), proposing formal estimation tasks for both retrieval utility and answer quality. It introduces two distinct prediction objectives: Retrieval Performance Prediction (RPP), which estimates the contextual utility gained from retrieved documents compared to zero-shot generation, and Generation Performance Prediction (GPP), which targets the factual quality of generated answers. The hypothesis underlying these tasks is that both traditional retriever-centric signals (e.g., query performance prediction, QPP) and reader-centric features (e.g., LLM-perplexity of context and answer) can be leveraged to anticipate RAG effectiveness. The work further explores query-agnostic document quality metrics—such as readability and relevance priors—for their incremental contribution to prediction accuracy.
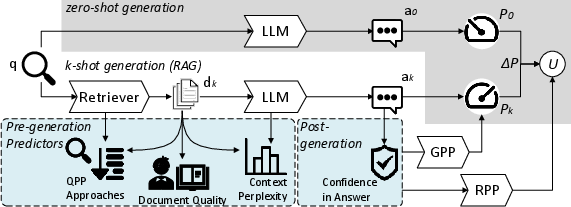
Figure 1: Proposed prediction tasks RPP and GPP augmenting the standard RAG workflow with utility and answer quality estimation modules.
Prediction Task Definitions and Methodological Framework
The paper formalizes utility in RAG as the difference in answer quality from k-shot generation relative to zero-shot baseline. Specifically, utility is defined as U=P(G(q;D[1:k]))−P(G(q;∅)), where P is a metric such as F1 (for QA), G is the generator, and D[1:k] are top-k retrievals. RPP estimates U using a set of features available prior to generation, while GPP estimates P(ak), i.e., the quality of the final answer.
The proposed prediction models operate in two modes:
- Pre-generation (PreGen): Predict using only retriever and context-level features.
- Post-generation (PostGen): Predict leveraging signals from the generated answer, including answer perplexity.
Three categories of predictors are combined:
- Retriever-centric (QPP): Score-based, embedding-based, and cross-encoder models adapted from QPP.
- Reader-centric (Perplexity): Context and answer perplexity as proxy signals for potential misalignment or model uncertainty.
- Query-agnostic (Document Quality): Readability indices (e.g., Flesch, Kincaid, Dale-Chall) and neural quality estimation (QualT5).
Linear regression ensembles these predictors to maximize correlation with ground truth utility and answer quality metrics over the NQ benchmark.
Experimental Protocol and Datasets
The paper evaluates predictor sets on the Natural Questions (NQ) dataset, using three retrieval pipelines (BM25, BM25→MonoT5, E5) with k ranging from 2 to 10. Generation is conducted using 8-bit quantized Llama-3-8B with controlled answer length and structure. QPP methods include NQC, MaxScore, DenseQPP, A-Pair-Ratio, and BERT-QPP. Document quality predictors span readability formulas and QualT5. Prediction accuracy is measured via Spearman's ρ between predicted and actual RPP/GPP targets.
Results and Analysis
Core Findings
RPP and GPP prediction accuracy exhibit strong positive correlation with ensemble approaches, particularly when integrating QPP and reader-centric features. Notably:
- DenseQPP and cross-encoder QPP models deliver robust baseline correlations, but ensemble linear regression of multiple QPP approaches consistently improves accuracy.
- Inclusion of context perplexity (C) yields statistically significant improvements for GPP, especially with weaker retrievers (BM25), corroborating that LLM uncertainty is indicative of answer reliability.
- Readability and document quality features provide slight but measurable additional gains; however, their impact is limited compared to QPP and perplexity-based signals when the “reader” is an LLM rather than a human.
- When answer perplexity (A) is added in PostGen mode, prediction accuracy further increases for both RPP and GPP, at the expense of score availability only after answer generation.
Cost of Prediction Modes
PreGen predictors offer early, efficient estimation but less precision, especially as context (k) grows. PostGen predictors, particularly answer perplexity, capture additional interactions between retrieved context and LLM knowledge, enabling more precise quality estimation post hoc.
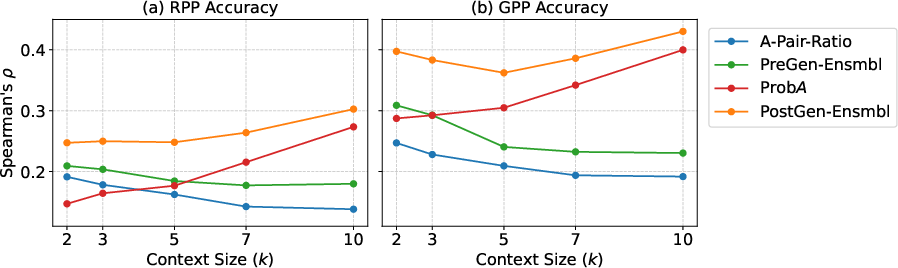
Figure 2: Prediction accuracy for RPP and GPP as context size varies, showing superior performance of ensembles and post-generation predictors.
Scaling with Context Size
Prediction accuracy of QPP-only and PreGen ensemble models degrades as k increases, highlighting the challenge of modeling long, concatenated contexts. In contrast, answer perplexity improves with longer context sizes, indicating that LLM self-confidence can partially mitigate analysis complexity in extended retrieval settings.
Theoretical and Practical Implications
The study demonstrates that RPP and GPP can be reliably approximated using a mix of retriever, reader, and document features, and that model uncertainty (perplexity) is a critical complementary signal to traditional IR metrics. These predictors could inform dynamic, query-adaptive RAG pipelines, guiding context selection, retrieval model choice, and error detection. The results imply that context utility is a multifactorial property, affected by document relevance, intrinsic quality, and LLM knowledge alignment, distinguishing it fundamentally from answer correctness.
Ensemble regression offers a straightforward, interpretable integration strategy, but future work may explore more sophisticated non-linear methods or meta-models, especially as context and answer length scale. Cross-dataset and cross-model generalization remain open research directions, given varying LLM architectures and retrieval environments.
Conclusion
This paper initiates a systematic framework for predicting context utility and answer quality in RAG via two well-defined tasks, RPP and GPP. Strong numerical correlations between predicted and true scores—achieved through ensembles of QPP, perplexity, and document quality features—demonstrate the feasibility of proxy-based performance estimation in RAG. Prediction difficulty increases with context size and is higher for utility than answer quality, emphasizing the need for further research on robust, context-sensitive RAG control. Practical deployments stand to benefit from per-query prediction of context worth, enabling more calibrated, adaptive, and efficient knowledge-intensive NLP systems.