HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
Abstract: Recent advancements in Multimodal LLMs (MLLMs) have demonstrated significant improvement in offline video understanding. However, extending these capabilities to streaming video inputs, remains challenging, as existing models struggle to simultaneously maintain stable understanding performance, real-time responses, and low GPU memory overhead. To address this challenge, we propose HERMES, a novel training-free architecture for real-time and accurate understanding of video streams. Based on a mechanistic attention investigation, we conceptualize KV cache as a hierarchical memory framework that encapsulates video information across multiple granularities. During inference, HERMES reuses a compact KV cache, enabling efficient streaming understanding under resource constraints. Notably, HERMES requires no auxiliary computations upon the arrival of user queries, thereby guaranteeing real-time responses for continuous video stream interactions, which achieves 10$\times$ faster TTFT compared to prior SOTA. Even when reducing video tokens by up to 68% compared with uniform sampling, HERMES achieves superior or comparable accuracy across all benchmarks, with up to 11.4% gains on streaming datasets.
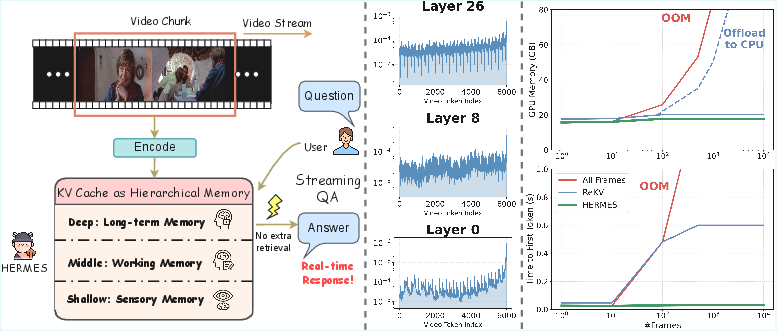
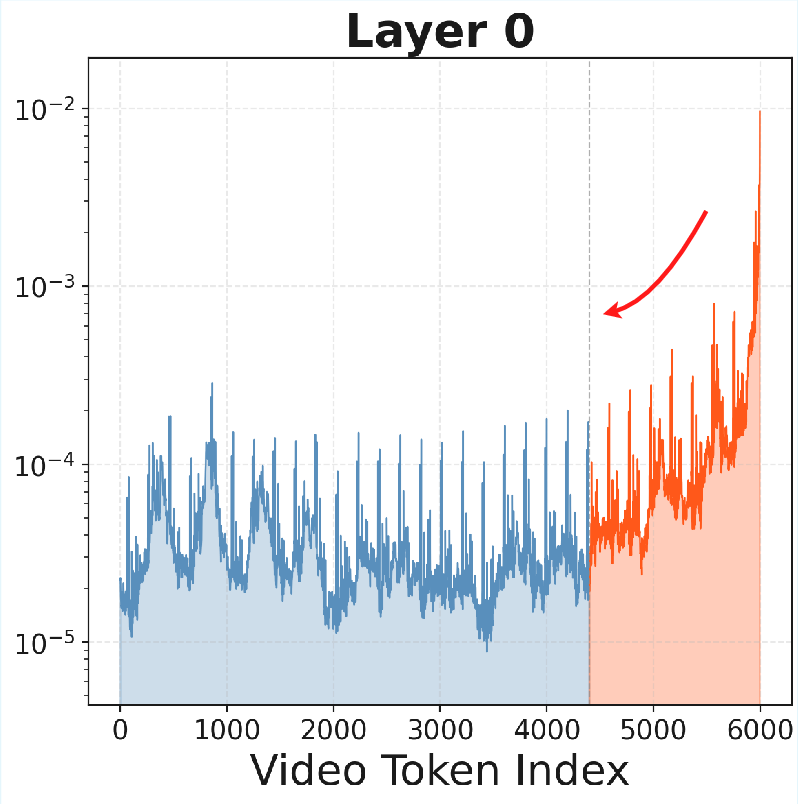
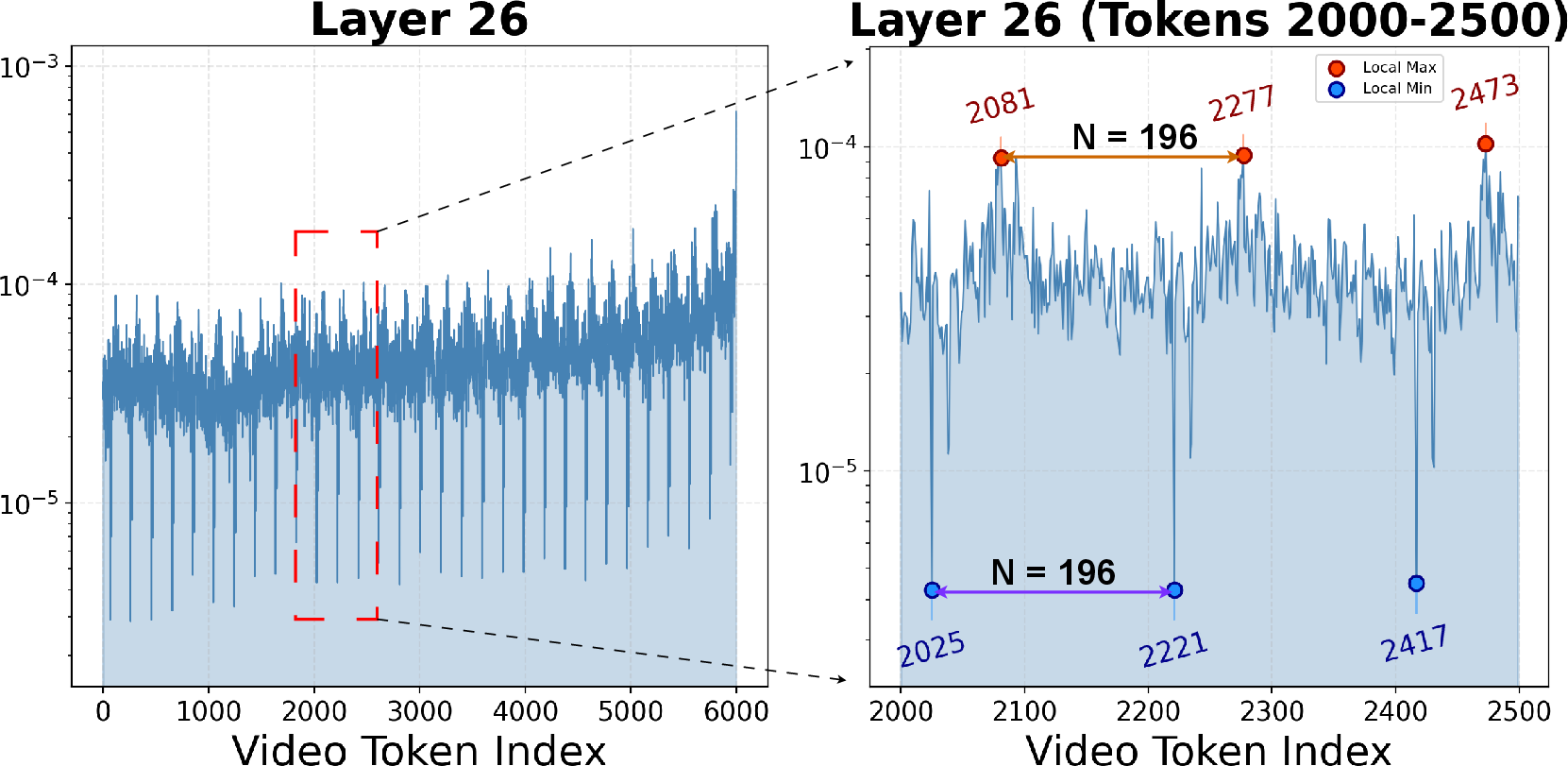
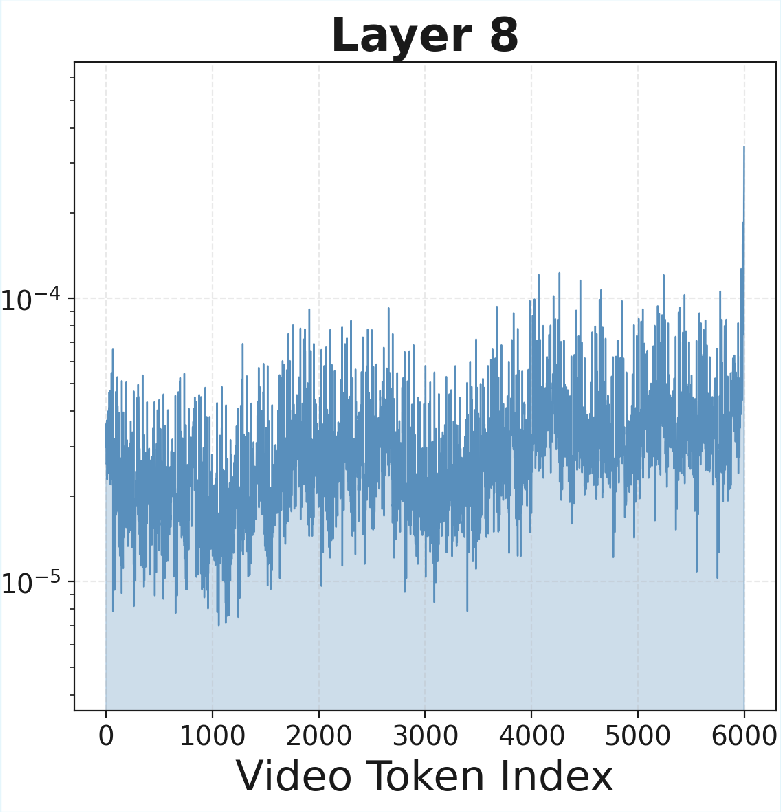
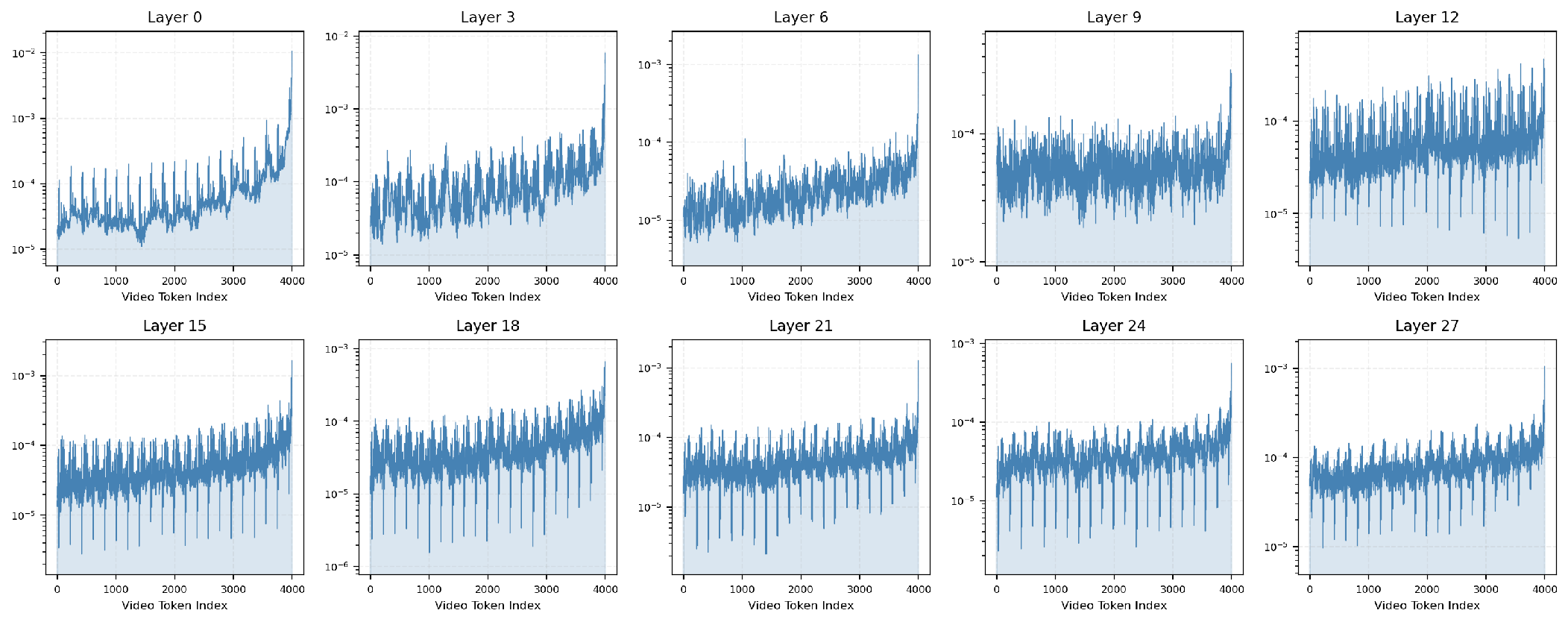
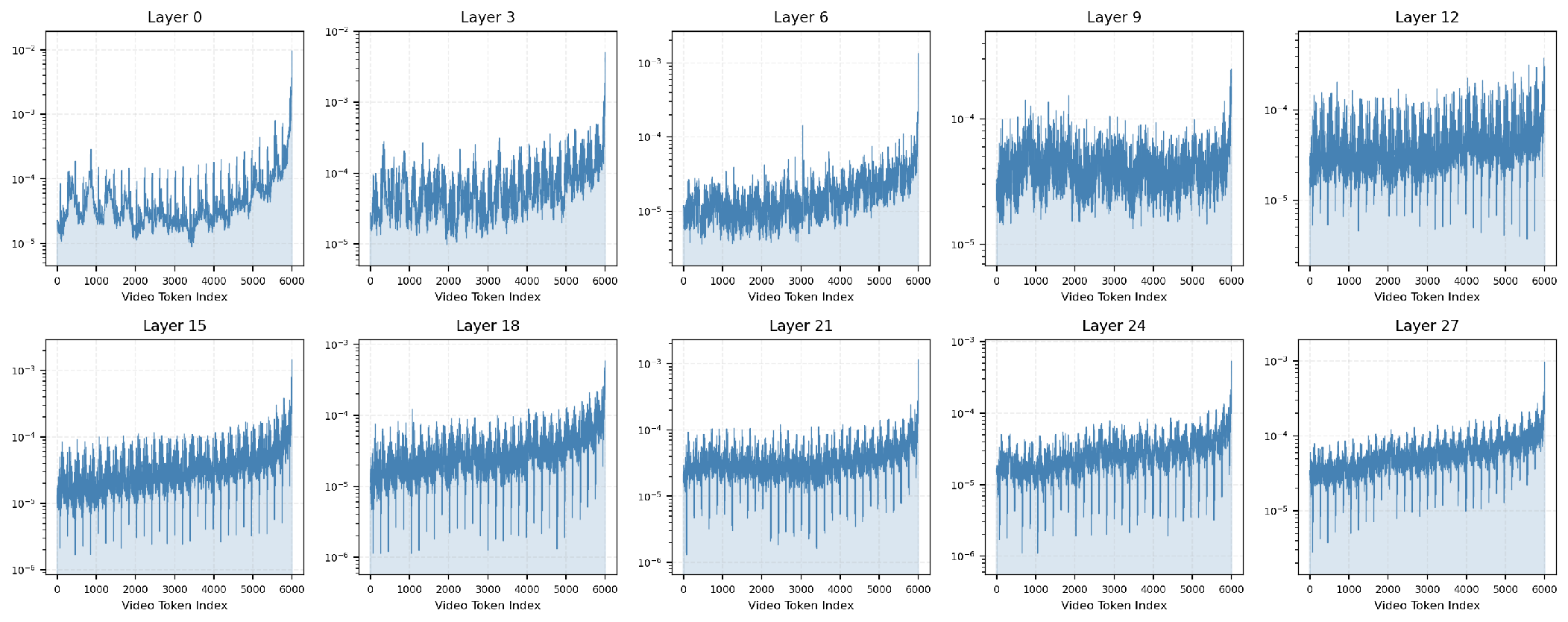
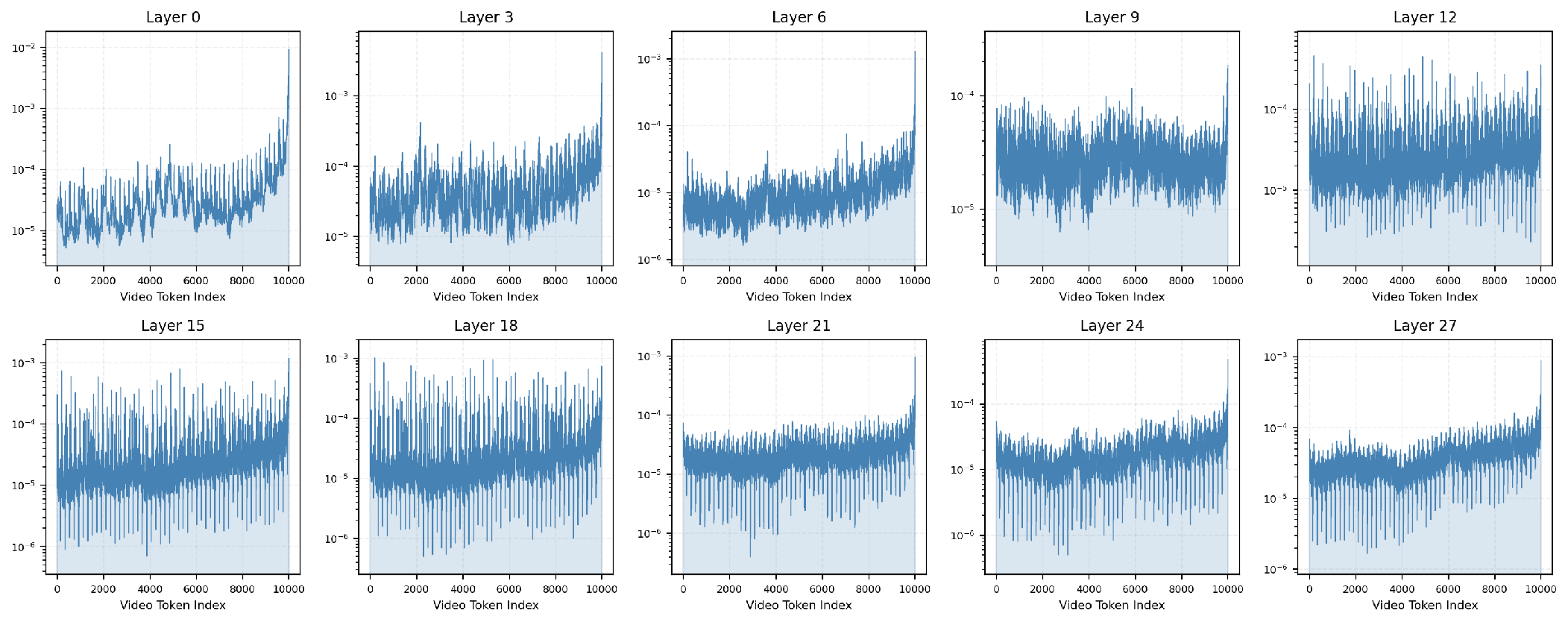 *Figure 3: Attention distributions across layers for a 4,000-token sliding window, confirming consistent hierarchical specialization.
*Figure 3: Attention distributions across layers for a 4,000-token sliding window, confirming consistent hierarchical specialization.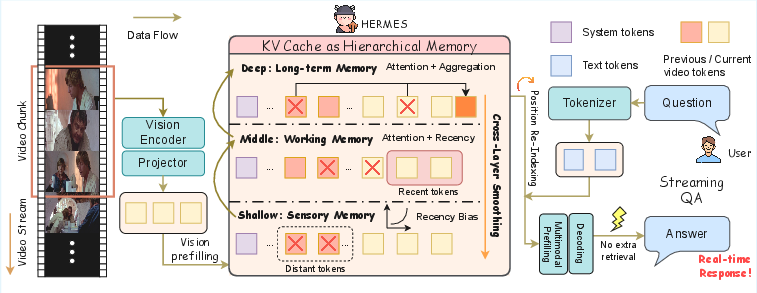
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces HermesBlue, a new way for AI to understand live, ongoing videos (like a livestream or a security feed) quickly and accurately, without using a lot of computer memory. It works with existing multimodal LLMs (MLLMs) and doesn’t need extra training. The core idea is to treat the model’s “KV cache” (a kind of short-term memory inside the model) like a smart, layered memory system—similar to how people remember things in the moment, in the short term, and in the long term.
Goals and questions the paper asks
The researchers want to solve three big problems for live video understanding:
- How can an AI keep understanding a never-ending video reliably over time?
- How can it answer user questions in real time (very low delay)?
- How can it use little GPU memory so it runs efficiently on common hardware?
They also ask: Can we reuse what the model already remembers (its KV cache) instead of building separate memory systems or slowing things down with extra steps?
How it works (methods in simple terms)
First, some simple definitions:
- Video tokens: tiny pieces of information the model creates from video frames. Think of each frame becoming a set of “notes” the model can read later.
- KV cache (Key-Value cache): the model’s built-in scratchpad where it stores what it’s seen so far, layer by layer. You can imagine each layer of the model has its own shelf of sticky notes (the cache) about the video.
- Attention: the model’s way of deciding which notes to focus on when answering a question.
The team looked closely at how different layers in the model “pay attention” to video tokens over time and discovered a pattern that resembles human memory:
- Shallow layers = sensory memory: they strongly favor the newest frames (what just happened).
- Middle layers = working memory: they balance recent and earlier info, combining short-term details with meaning.
- Deep layers = long-term memory: they keep sparse, stable “anchors” that summarize each video frame (like bookmarks at regular intervals).
Based on that, HermesBlue has three main parts:
- Hierarchical KV cache management
The system decides which tokens to keep or discard differently for each layer:
- Shallow layers keep the newest stuff (like a “what just happened” buffer), letting older notes fade out quickly.
- Deep layers keep those frame “anchor” tokens, identified by strong attention, because they represent important long-term summaries.
- Middle layers mix both strategies, gradually shifting from “recent” to “important” as layers go deeper.
- Cross-layer memory smoothing If each layer throws away different tokens, their memories can get out of sync. To fix this, HermesBlue gently shares importance signals across layers so they keep a consistent picture of the video. It also combines discarded pieces into a small “summary token” per deep layer, so long-term info isn’t lost.
- Position re-indexing
Models use position numbers to keep track of order. With endless video, those numbers can get too big and hurt quality. HermesBlue “renumbers” positions to a safe range without breaking the story:
- Lazy re-indexing (for streaming): renumber only when needed to keep speed high.
- Eager re-indexing (for offline/long videos): renumber more often to keep long-range meaning extra stable.
Importantly, HermesBlue is training-free: you plug it into existing models, and it works without retraining. It also answers user questions directly from the cache—no extra database or retrieval step—so responses are real-time.
Main results and why they matter
HermesBlue delivers three standout benefits:
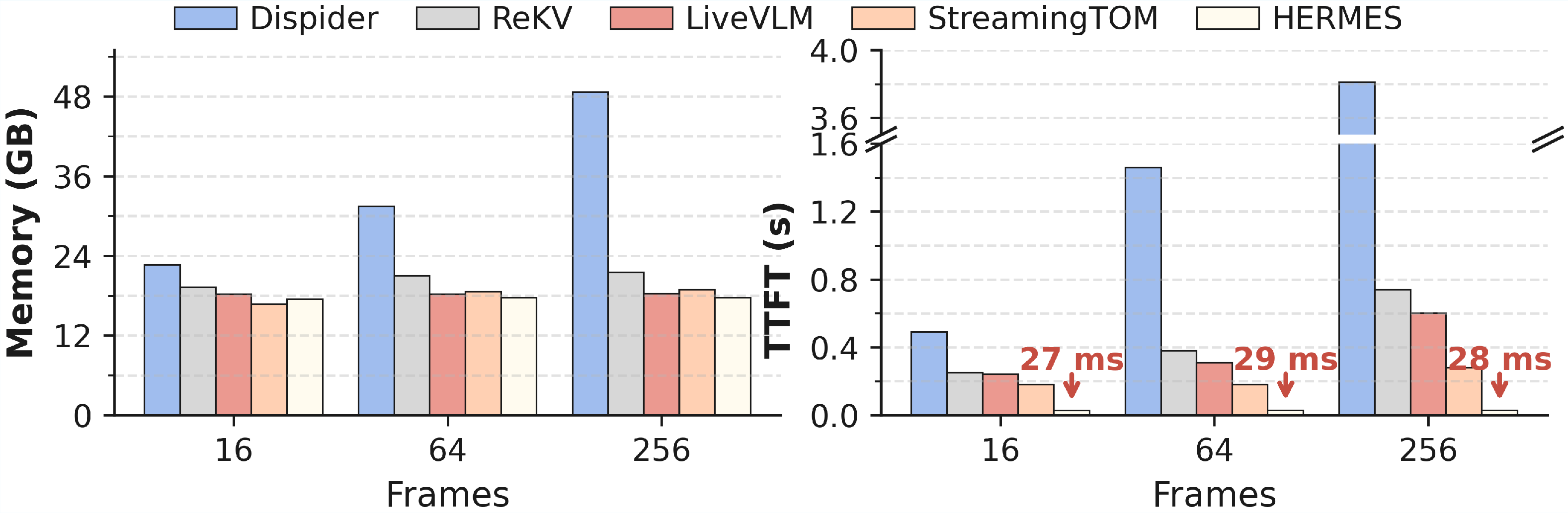
- Much faster first response: It achieves up to 10× faster “Time to First Token” (TTFT), which means users start seeing answers much sooner after asking a question. It also keeps response speed steady as videos get longer.
- Lower memory use, stable performance: Even as more frames arrive, GPU memory stays stable because the cache has a fixed size with smart token selection. It avoids crashes from running out of memory.
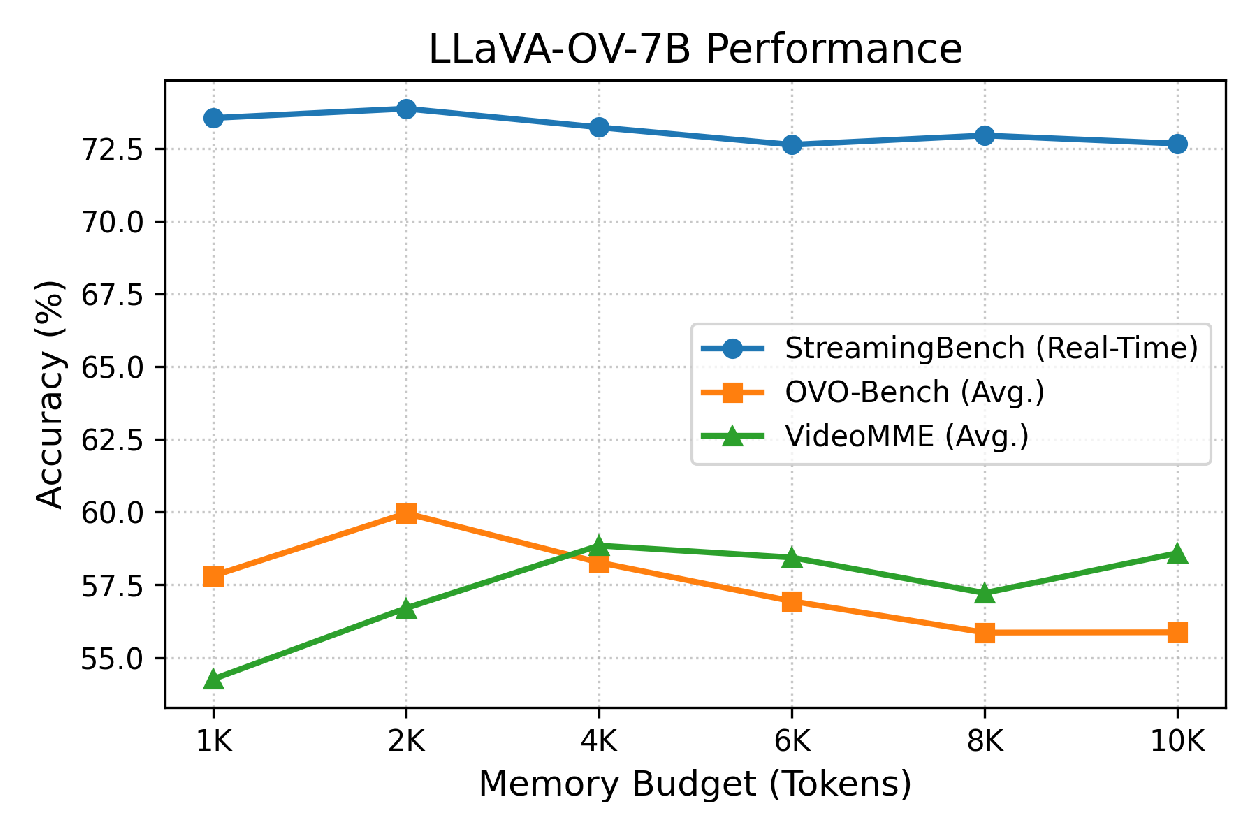
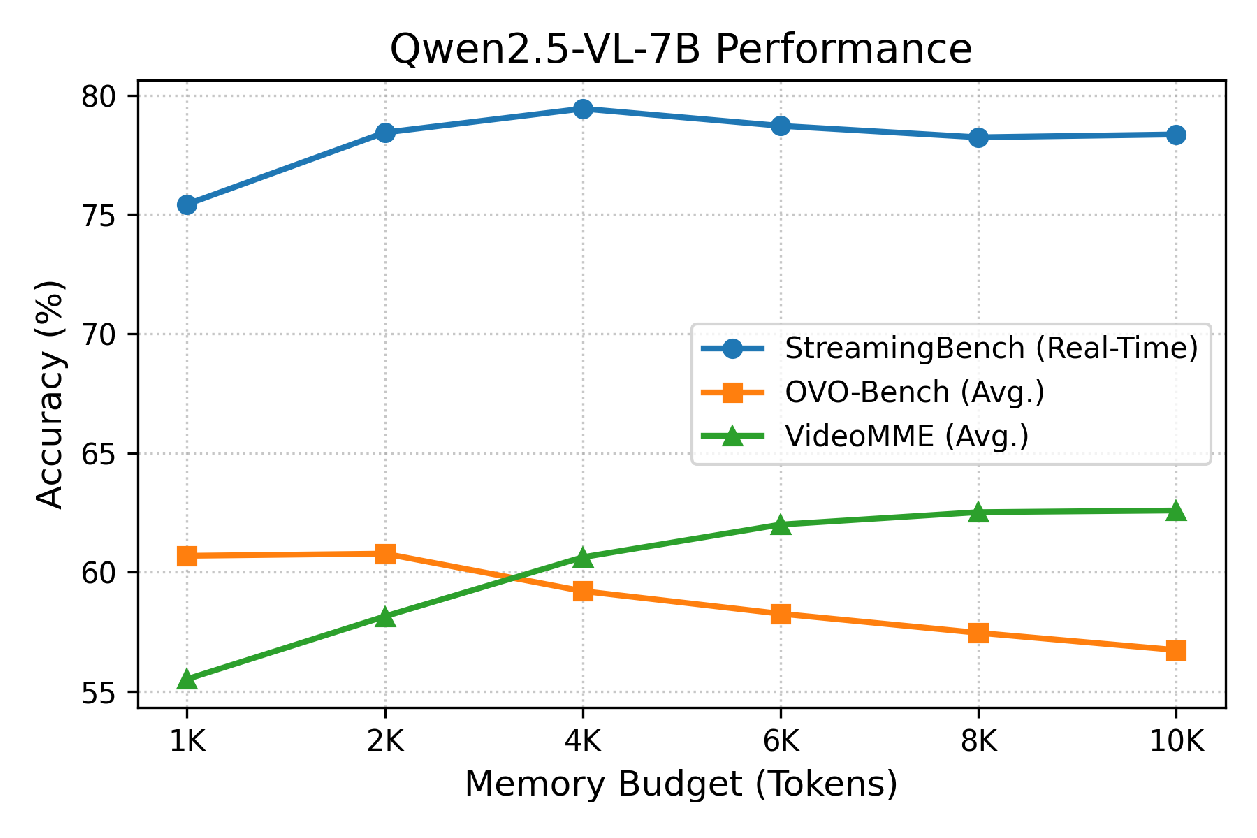
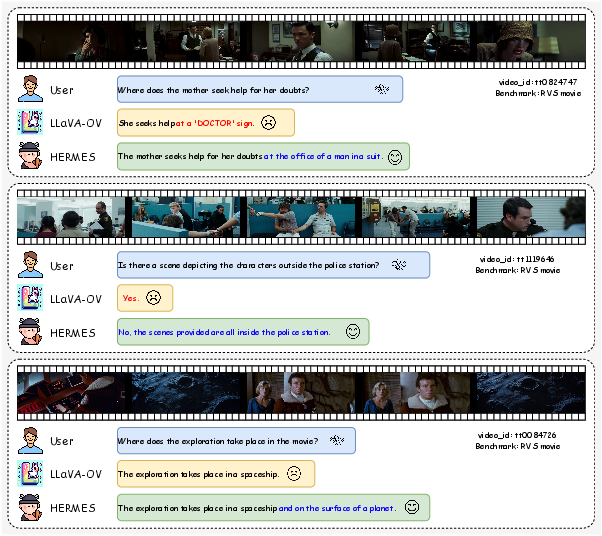
- High accuracy with fewer tokens: HermesBlue can remove up to 68% of video tokens compared to uniform sampling yet still match or beat accuracy on many benchmarks. On streaming tasks, it improves accuracy by up to 11.4% over the base models. It works well across different open-source models (like LLaVA-OneVision and Qwen2.5-VL) and on both streaming and offline long-video tests.
Why this matters: Together, these results show you can build practical, fast, and accurate live video assistants without heavy hardware or special training.
What this could change (impact and implications)
HermesBlue shows that the KV cache—the model’s built-in memory—can act like a well-organized, human-like memory system (sensory, working, long-term). This idea could:
- Make real-time video assistants (for sports, classrooms, livestreams) more responsive and reliable.
- Help monitoring systems (like security or driving cams) understand events over long periods without slowing down.
- Reduce costs by running on a single GPU and avoiding extra retrieval systems or retraining.
Big picture: Managing the model’s own memory cleverly can unlock efficient, real-time understanding of never-ending videos. HermesBlue is a practical step toward AI that “watches” and “thinks” continuously—fast, accurate, and resource-friendly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Robustness of the “hierarchical KV cache” hypothesis across diverse MLLMs: validate whether shallow/middle/deep layer roles (sensory/working/long-term memory) and rhythmic anchor-token patterns generalize beyond LLaVA-OV and Qwen2.5-VL, especially for models with different visual tokenization, attention architectures, and positional encodings.
- Generality of frame-level “anchor tokens”: the 196-token rhythm strongly depends on a fixed-per-frame tokenization; assess whether similar anchor structures exist under dynamic resolutions, variable token counts per frame (e.g., Qwen2.5-VL), or patchification differences, and how to detect anchors when token-per-frame is not constant.
- Sensitivity to pseudo-query design for attention-based scoring in deep layers: quantify how different “generic guidance prompts” affect token importance and downstream QA accuracy; develop query-agnostic or query-forecasting mechanisms and measure mismatch when user queries deviate from pseudo-query intent.
- Hyperparameter auto-tuning and content-adaptive policies: k (forgetting rate), ω0, γ, layer partition ratios (10/60/30), and λ smoothing parameters are hand-crafted; design automatic or learned policies that adapt to scene dynamics (e.g., shot changes, motion intensity), user interaction frequency, and domain (egocentric vs cinematic).
- Formal justification of attention-as-importance: provide theoretical or causal evidence (e.g., knock-out tests, gradient-based attribution, causal scrubbing) that attention-weighted Top-K retention preserves the information needed for correct generation under streaming QA.
- Structured vs per-token selection: examine whether Top-K per-token selection fragments within-frame context; evaluate per-frame or per-segment selection, and coherence-preserving strategies that maintain temporal neighborhoods and scene continuity.
- Summary token construction is underspecified: detail the aggregation operator (e.g., mean pooling, attention pooling, projections), the number and placement of summary tokens per layer, and quantify the information loss, contamination risks, and performance vs cost trade-offs.
- Cross-layer memory smoothing design space: explore alternative propagation (e.g., bi-directional smoothing, skip-layer smoothing), learnable smoothing coefficients, and per-head or per-channel smoothing; extend ablations beyond VideoMME and derive principled settings per backbone.
- Position re-indexing trigger criteria: specify exact thresholds for “lazy” re-indexing, analyze semantic drift introduced by index remapping under 1D RoPE and 3D M-RoPE, and provide guidelines for selecting eager vs lazy strategies under different workloads and model limits.
- Multi-round interactive streaming evaluation: benchmark scenarios with frequent, interleaved user queries during ingestion, measuring cumulative TTFT/TPOT, cache contention, and stability; study scheduler designs ensuring zero query-time overhead under concurrency.
- Robustness to real-world stream variability: test variable frame rates, dynamic resolutions, dropped frames, jitter, motion blur, occlusion, camera shake, and sudden scene changes; adapt importance signals and re-indexing thresholds to these conditions.
- Generalization to edge/consumer hardware: evaluate latency and memory on 8–24 GB consumer GPUs and mobile devices, quantify energy usage, and characterize performance with smaller memory budgets (≤1K tokens) to guide deployment constraints.
- Extreme long-horizon stability: assess behavior on multi-hour live streams and continuous sessions (beyond the tested durations), including drift, catastrophic forgetting, and cumulative summary-token effects; develop safeguards against long-term degradation.
- Task coverage beyond QA: include continuous tasks that stress temporal memory (tracking, action localization, moment retrieval, event segmentation) to test whether HermesBlue retains fine-grained spatiotemporal cues needed for non-QA objectives.
- Audio and subtitles integration: extend hierarchical KV management to multimodal streaming (audio, ASR text, captions), define cross-modal cache policies, and study interference or synergy among modalities within the shared KV memory.
- Adaptive chunking and sampling policies: investigate dynamic chunk size and FPS adaptation based on scene/content signals and latency constraints; quantify effects on TTFT/TPOT and accuracy, and devise controllers for real-time adjustment.
- Failure mode diagnostics: provide qualitative/quantitative analyses of cases where eviction drops critical context (e.g., rare events, low-salience clues), and design online detectors/mitigations (e.g., “do-not-evict” flags, content-aware pinning).
- Hybrid memory architectures: explore minimal external memory indices or lightweight retrieval that complement internal KV cache without incurring query-time latency spikes; characterize trade-offs vs purely internal memory.
- Training-free vs lightly-trained variants: evaluate small-scale finetuning to learn per-layer importance scorers or smoothing parameters; compare gains vs cost and identify regimes where training-free suffices.
- Re-indexing and RoPE variants: examine compatibility with alternative positional encodings (ALiBi, rotary variants, learned PE), and whether re-indexing strategies need to be tailored per encoding to avoid semantic distortion.
- Benchmark settings and fairness: provide systematic comparisons with training-based streaming systems under matched memory budgets and query schedules; ensure measures (e.g., TTFT) reflect identical pipeline assumptions (prefill/retrieval policies).
- Use with subtitles in VideoMME and other long-video benchmarks: the paper reports results without subtitles; evaluate with textual streams to understand how additional context interacts with KV compression and smoothing.
- Reproducibility and implementation details: publish full algorithms for summary token creation, exact smoothing schedules, pseudo-query templates, and re-indexing thresholds; enable standardized evaluation scripts for future comparative studies.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage HermesBlue’s training-free, plug-and-play architecture for streaming video understanding (low-latency, constant GPU memory footprint, no auxiliary retrieval at query time, up to 10× faster TTFT, and up to 68% token reduction with stable accuracy).
- Real-time operations copilot for live security/traffic rooms
- Sectors: public safety, transportation, smart cities
- Tools/products/workflows: “Streaming QA Copilot” that answers operator questions (“Which vehicle ran the red light 30s ago?”), backward-tracing using compact KV cache, on-prem GPU node with 4K–6K video-token budget per layer
- Dependencies/assumptions: Camera feed access and consent; performance hinges on base MLLM choice (e.g., Qwen2.5-VL/LLaVA-OV); lighting/occlusion impact; policy compliance (surveillance and retention rules)
- Edge streaming analytics on constrained hardware for industrial automation
- Sectors: manufacturing, logistics, robotics
- Tools/products/workflows: TensorRT-LLM or vLLM plugin “KV Memory Manager” implementing HermesBlue (hierarchical KV management + cross-layer smoothing + lazy re-indexing), chunked video encoding pipeline, on-device anomaly QA (“What caused the conveyor jam?”)
- Dependencies/assumptions: Porting to edge accelerators (e.g., Jetson) may require quantization and careful memory tuning; industrial integration (SCADA/PLC); domain shifts (glare, vibration)
- Live sports and broadcast assistants
- Sectors: media, entertainment
- Tools/products/workflows: OBS/Twitch/YouTube-Live “Streaming QA Bot” that answers audience questions and pinpoints highlights using frame-level anchor tokens; real-time captions and event summaries with constant-latency responses
- Dependencies/assumptions: Domain prompts or light finetuning improve coverage (player names, rules); copyright/moderation controls; stable ingest bandwidth
- Live content moderation at scale
- Sectors: platform safety, social media
- Tools/products/workflows: Moderator console wired to HermesBlue cache (no query-time retrieval), instant “rewind-to-evidence” queries for policy enforcement; workflow integration with existing rule engines
- Dependencies/assumptions: Safety tuning for false positives/negatives; legal frameworks by region; multi-language overlay (if needed)
- Retail loss prevention and shopper assistance
- Sectors: retail
- Tools/products/workflows: Store-floor assistant answering “Where did the dropped item roll?”; loss-prevention “backward trace” to source of event; compact KV memory enables many concurrent cameras with predictable GPU footprint
- Dependencies/assumptions: Privacy policies; store network reliability; calibration for occlusions and variable lighting
- Meeting and lecture real-time indexing and Q&A
- Sectors: education, enterprise productivity
- Tools/products/workflows: Video-conferencing add-in that supports “What was on the whiteboard 5 minutes ago?” or “When did topic X start?”; lazy re-indexing preserves short-term position semantics; auto-chaptering via anchor tokens
- Dependencies/assumptions: Video quality; whiteboard/slide legibility; pairing with ASR for multimodal grounding
- Healthcare remote monitoring triage
- Sectors: healthcare
- Tools/products/workflows: Nurse dashboard that can ask “Has the patient attempted to leave the bed in the last 2 minutes?”; fall-detection with just-in-time contextual QA; stable latency for continuous feeds
- Dependencies/assumptions: HIPAA/GDPR compliance; human-in-the-loop oversight; hospital network and device certifications; robust performance under night lighting and occlusions
- Bodycam/dashcam field assistant
- Sectors: public safety, insurance, fleet/logistics
- Tools/products/workflows: Wearable assistant with voice queries (“What license plate did I pass two intersections ago?”), backward tracing using hierarchical cache; fixed memory budget avoids OOM on long shifts
- Dependencies/assumptions: Edge compute form factors and thermals; privacy and consent; high-variance scenes (weather, motion blur)
- Dataset distillation and annotation acceleration
- Sectors: academia, ML operations
- Tools/products/workflows: Annotation UI that jumps across deep-layer “anchor tokens” to review representative frames; batch compression of long videos via HermesBlue’s token selection and summary tokens for efficient labeling
- Dependencies/assumptions: Integration with labeling tools; domain mismatch risk; evaluator consistency across tasks
- Cloud cost reduction for video analytics SaaS
- Sectors: software/DevOps
- Tools/products/workflows: Inference-server patch that constrains video KV cache to fixed budgets (e.g., 4K), maintaining constant memory and sub-30ms TTFT; autoscaling governed by stable per-stream GPU cost
- Dependencies/assumptions: Compatibility with serving stacks (vLLM, Triton, TensorRT-LLM); base model licensing; monitoring for accuracy drift under compression
Long-Term Applications
These require additional research, scaling, hardware adaptation, or regulatory work before broad deployment.
- AR glasses multimodal assistant with persistent hierarchical memory
- Sectors: consumer electronics, accessibility
- Tools/products/workflows: On-device HermesBlue variants with energy-aware lazy re-indexing; continuous scene QA and “rewind” on-device
- Dependencies/assumptions: Mobile-class acceleration, power constraints, thermals; strong privacy controls; improved base MLLM vision robustness outdoors
- Autonomous robots with conversational, long-horizon memory
- Sectors: robotics, warehousing, agriculture
- Tools/products/workflows: Robot copilot that recalls past environmental states (“Where was the misplaced pallet earlier today?”) without external retrieval; cross-layer smoothing tuned to robot perception stacks
- Dependencies/assumptions: Tight integration with navigation/perception; real-time guarantees; domain-specific safety validation
- City-scale multi-camera reasoning and cross-stream “causal rewind”
- Sectors: smart cities, transportation, public safety
- Tools/products/workflows: Distributed KV-cache orchestration across cameras; cross-stream alignment to answer “Which route did the suspect take across intersections?”
- Dependencies/assumptions: Multi-camera identity linking; privacy-preserving aggregation; governance and auditability
- Personalized lifelogging and private retrieval over long horizons
- Sectors: consumer apps, wellness
- Tools/products/workflows: On-device hierarchical memory for hours-to-days; private “What did I put on the desk this morning?” queries; summary-token timelines
- Dependencies/assumptions: Consent-first design; on-device compute; robust summarization and bias/failure-mode controls
- Standardized KV-memory APIs in inference engines
- Sectors: AI infrastructure
- Tools/products/workflows: “KV Memory Manager” specification for hierarchical cache management, cross-layer smoothing, and re-indexing; integration with vLLM/TensorRT-LLM/HF Transformers
- Dependencies/assumptions: Cross-model RoPE/M-RoPE variations; community adoption; benchmarks for streaming memory quality
- Adaptive or learned importance scoring
- Sectors: research, model tooling
- Tools/products/workflows: Replace fixed interpolation (recency/attention) with learned schedulers or RLHF; dynamic layer partitioning for various backbones and tasks
- Dependencies/assumptions: Training data and safe optimization; avoiding overfitting to specific query distributions
- Surgical and procedure assistance in ORs
- Sectors: healthcare
- Tools/products/workflows: Multi-camera, multi-modal (video + vitals) persistent memory for long procedures; instant recall (“When was clamp applied?”), robust to occlusions
- Dependencies/assumptions: Regulatory approval; sterile hardware; ultra-low latency and failure tolerance
- ADAS/AV narrative layer with verifiable evidence retrieval
- Sectors: automotive
- Tools/products/workflows: Driver-assist that can answer “What led to the braking event 90s ago?”; compressed, authenticated summaries for incident investigation
- Dependencies/assumptions: Automotive-grade SoCs; safety certification; extreme reliability under adverse conditions
- Long-form creative tooling (auto-edit, storyboarding, highlight reels)
- Sectors: film, media production
- Tools/products/workflows: Editor plugins that traverse anchor tokens and summary tokens to assemble story arcs from hours of footage; queryable timelines
- Dependencies/assumptions: Integration with NLEs (Premiere/Resolve); domain prompting; quality thresholds for professional use
Cross-cutting assumptions and dependencies
- Base model quality and licensing: Accuracy, robustness, and allowed use depend on the underlying MLLM (e.g., LLaVA-OV, Qwen2.5-VL).
- Hardware constraints: Reported TTFT and memory figures were obtained on an A800 (80 GB). Edge/mobile deployments require further optimization (quantization, batching, fused ops).
- Domain variability: Lighting, motion blur, occlusions, and domain-specific semantics can affect performance; light finetuning or tailored prompts may be necessary.
- Privacy, safety, and compliance: Many applications involve sensitive video. Enforce consent, retention limits, and human oversight; adhere to local regulations (e.g., HIPAA/GDPR).
- Configuration tuning: Layer partitioning (e.g., 10% shallow, 60% middle, 30% deep), memory budget (often ≥4K tokens), smoothing λ, and re-indexing strategy (lazy vs. eager) must be tuned per model/task.
- Failure modes: While backward tracing benefits from anchor tokens and summary tokens, rare or subtle events may be missed under aggressive compression; monitoring and fallback policies are advised.
Glossary
- Ad-hoc retrieval: On-demand fetching of stored content from an external database when a query arrives. "perform ad-hoc retrieval and multimodal prefilling at query time"
- Anchor tokens: Specific tokens that act as periodic frame-level summaries and attract high attention in deep layers. "These local maxima can be regarded as frame-level "anchor tokens", summarizing the visual information of each frame."
- Attention visualization: Analysis or plotting of attention distributions to interpret model behavior. "a mechanistic analysis on attention visualization"
- Attention weights: Scalar values indicating how much a query attends to each token during attention. "where denotes the attention weight of the -th token at the layer ."
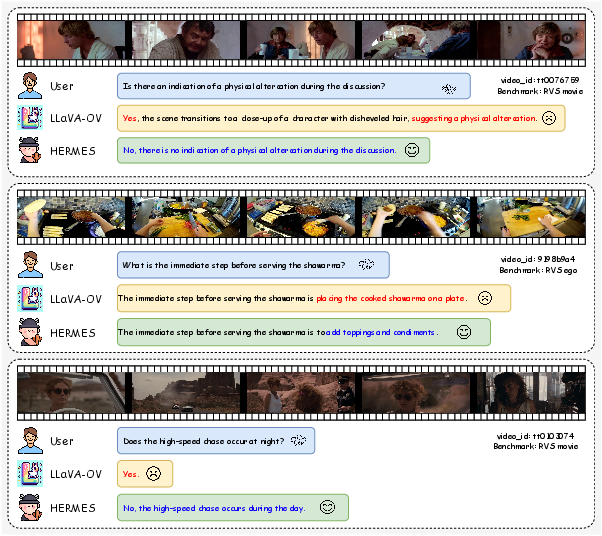
- Backward tracing: Tasks that require reasoning about earlier parts of a video from a later query. "average accuracy of real-time visual perception and backward tracing tasks."
- Chunk-wise processing: Handling streaming inputs in fixed-size segments sequentially. "fed into LLaVA-OV-7B in a streaming chunk-wise manner"
- Cross-Layer Memory Smoothing: A mechanism that propagates importance signals across layers to align memory. "Cross-Layer Memory Smoothing"
- Dynamic resolution: Adapting input resolution on the fly rather than using a fixed size. "we maintain its native dynamic resolution on video input"
- Eager re-indexing: Updating positional indices at every compression step to keep them strictly contiguous. "Eager Re-Indexing"
- Ebbinghaus’ memory decay theory: Psychological model describing exponential forgetting over time. "Inspired by Ebbinghausâ memory decay theory"
- End-to-end cohesion: Consistency and integration across all stages of a system without fragmented pipelines. "lack of end-to-end cohesion"
- End-to-end reasoning: Seamless inference over all stored context within the model’s pipeline. "seamless end-to-end reasoning over stored video contexts"
- External memory: Storage outside the model (e.g., databases) for video content or captions. "External memory methods store video content as captions or raw vision patches in databases"
- FIFO: First-in, first-out policy where the oldest tokens are evicted first. "a FIFO KV cache budget of 6K video tokens per layer"
- FP16 mixed precision: Computation using half-precision floats for efficiency while preserving accuracy. "All evaluations are conducted using FP16 mixed precision"
- Greedy decoding: Decoding strategy that selects the highest-probability token at each step. "Greedy decoding is used to generate deterministic outputs."
- Hierarchical KV cache management: Layer-specific retention strategies that reflect different memory roles. "hierarchical KV cache management"
- KV cache: Stored key and value tensors from previous tokens used to speed up transformer inference. "KV cache as a hierarchical memory framework"
- Layer-wise attention: Variation in attention patterns across different transformer layers. "layer-wise attention preferences over hierarchical video information"
- Lazy re-indexing: Deferring positional index updates until near the model’s limit to reduce overhead. "Lazy Re-Indexing"
- Long-horizon understanding: Maintaining and using information across extended temporal spans. "for long-horizon understanding"
- Long-term memory: Persistent storage of key information over long sequences in deeper layers. "Deep Layers as Long-term Memory:"
- Mechanistic investigation: Empirical analysis aimed at explaining model behavior via internal signals. "Based on a mechanistic attention investigation"
- Memory budget: The fixed capacity of tokens retained in the cache. "a constant budget of 6K video tokens per KV cache layer."
- M-RoPE: Multi-dimensional Rotary Positional Encoding for vision-language inputs. "3D M-RoPE (Qwen2.5-VL)"
- Multimodal LLMs (MLLMs): LLMs that process and reason over multiple modalities (e.g., text, video). "Multimodal LLMs (MLLMs)"
- Multimodal prefilling: Precomputing and caching multimodal tokens before answering a query. "perform ad-hoc retrieval and multimodal prefilling at query time"
- OOM errors: Out-of-memory failures when GPU memory is exhausted. "exhibiting no risk of OOM errors"
- Position re-indexing: Remapping positional indices of cached tokens to a contiguous range to avoid overflow. "Position Re-Indexing"
- Positional drift: Degradation caused by inconsistent or excessively large positional indices. "prevents positional drift"
- Prefilling: Encoding and caching input tokens prior to decoding the response. "During the prefilling stage for video tokens"
- Pseudo query: A generic prompt used to estimate attention when the real user query is unknown. "as a pseudo query."
- Recency bias: Preference for attending more to recent tokens than earlier ones. "exhibit an intense recency bias"
- RoPE: Rotary Positional Encoding, a method for injecting position via complex rotations. "1D RoPE (LLaVA-OV)"
- Sensory memory: Short-lived storage focused on the most recent inputs in shallow layers. "Shallow Layers as Sensory Memory:"
- State-of-the-art (SOTA): The best-performing method at the time of writing. "prior SOTA"
- Summary token: A compact representation that aggregates evicted tokens to preserve long-term information. "evicted tokens are aggregated into a summary token per layer"
- Time Per Output Token (TPOT): Latency per generated token during decoding. "Time Per Output Token (TPOT)"
- Time to First Token (TTFT): Latency from query arrival to the first generated token. "Time to First Token (TTFT)"
- Token eviction: Removing tokens from the cache when capacity is reached. "token eviction is triggered"
- Top-K selection: Keeping only the K tokens with the highest importance scores. "We then apply Top-K selection"
- Training-free: A method requiring no additional model training to apply. "a training-free framework"
- Working memory: Mid-layer storage integrating recent inputs with salient earlier information. "Middle layers as Working Memory:"
Collections
Sign up for free to add this paper to one or more collections.

