- The paper introduces AQAScore, a novel metric for evaluating semantic alignment by leveraging audio question answering in text-to-audio generation.
- It reformulates evaluation via binary semantic queries with ALLMs, showing superior correlation with human judgments across diverse benchmarks.
- Experimental results indicate AQAScore outperforms conventional embedding-based metrics in detecting compositional inconsistencies and attribute mismatches.
AQAScore: Semantics-Aware Evaluation for Text-to-Audio Generation
Motivation and Limitations in Existing Evaluation Protocols
The exponential advancement in text-to-audio (TTA) generation has produced systems capable of synthesizing realistic, diverse, and context-rich audio from natural language prompts. However, the evaluation of such models, particularly in terms of fine-grained semantic alignment between generated audio and textual descriptions, remains an open challenge. The prevailing methodology—embedding-based metrics such as CLAPScore—can effectively quantify global relevance via feature similarity but lacks compositional sensitivity. Specifically, these approaches are insensitive to compositional and attribute-level nuances and fail on tasks requiring event ordering or attribute binding, as evidenced by poor discrimination between semantically distinct scenarios (e.g., reversal of event order or swapped attributes).
This bottleneck highlights a critical need for metrics capable of reasoning over structured semantics within audio. Conventional metrics struggle where human benchmarks (e.g., RELATE, PAM, Baton, CompA) excel, prompting research into evaluation methods that explicitly incorporate fine-grained reasoning and semantic verification.
AQAScore Framework
AQAScore is introduced as a backbone-agnostic, semantics-aware evaluation protocol that leverages modern audio-aware LLMs (ALLMs). Its core innovation is the reframing of evaluation as an Audio Question Answering (AQA) task, in which semantic consistency between audio and text is measured by extracting the probability of a targeted “Yes” response to explicit semantic queries.
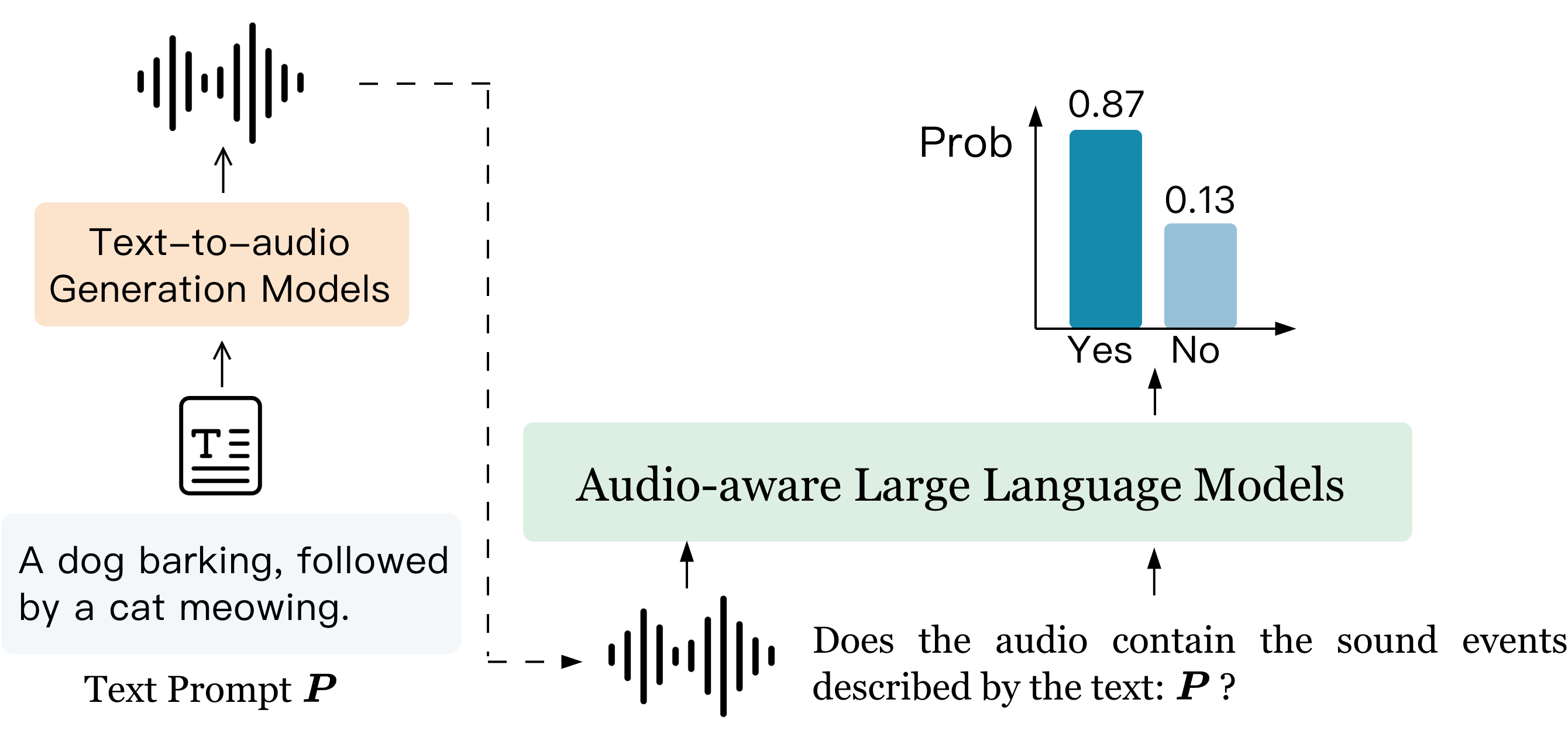
Figure 1: AQAScore framework reformulates evaluation as probabilistic semantic verification via AQA, utilizing the log probability distribution over ‘Yes’ and ‘No’ responses.
Given an audio–text pair (a,t), AQAScore operates by constructing a binary semantic query (“Does this audio contain the sound events described by the text: {description}?”) and computing the softmax-normalized probability that the ALLM assigns to the “Yes” response. This score is interpreted as the model’s confidence in the semantic alignment between audio and text. The protocol extends naturally to pairwise comparisons by ranking candidate audios or captions according to their AQAScore.
This probabilistic approach, distinct from open-ended generative rating or embedding similarity, is theoretically more robust to semantic inconsistencies—including missing events, incorrect ordering, and attribute mismatches—due to its explicit reasoning mechanism and fine-grained log-probability extraction.
Experimental Evaluation
Benchmarks
AQAScore is subjected to comprehensive evaluation on diverse benchmarks:
- Human-rated relevance: RELATE and PAM, which provide subjective human scores for text–audio relevance.
- Pairwise comparison: RELATE-Pair and Baton-Pair, which task models with ranking audio or text candidates based on semantic match.
- Compositional reasoning: CompA, featuring sub-tasks focused on event order and attribute binding.
ALLM Backbones
Experiments employ both Qwen2.5-Omni (3B, 7B) and Audio Flamingo 3 (various tuning regimes), selected for their open-source availability and competitive performance on audio reasoning tasks.
Key Results
AQAScore demonstrates significantly higher correlation with human judgments compared to CLAPScore and generative prompting baselines across all evaluation modes.
- RELATE and PAM: On RELATE, Qwen2.5-Omni-7B achieves an LCC of 0.544 (vs. CLAPScore’s best at 0.448). On PAM, Qwen2.5-Omni-7B achieves an SRCC of 0.589, substantially outperforming embedding-based and direct prompt baselines.
- Pairwise benchmarks: AQAScore reaches the highest pairwise accuracy on RELATE-Pair and Baton, with Qwen2.5-Omni-7B at 77.6% accuracy (CLAPScore max: 76.0%).
- Compositional reasoning (CompA): In the Order-Text task, Qwen2.5-Omni-7B yields 67.0% accuracy, outperforming CompA-CLAP and other baselines; attribute binding remains challenging for all models, but AQAScore retains superior accuracy.
Robustness to prompt design and template variation is empirically validated; the standard deviation in performance across question templates is consistently low.
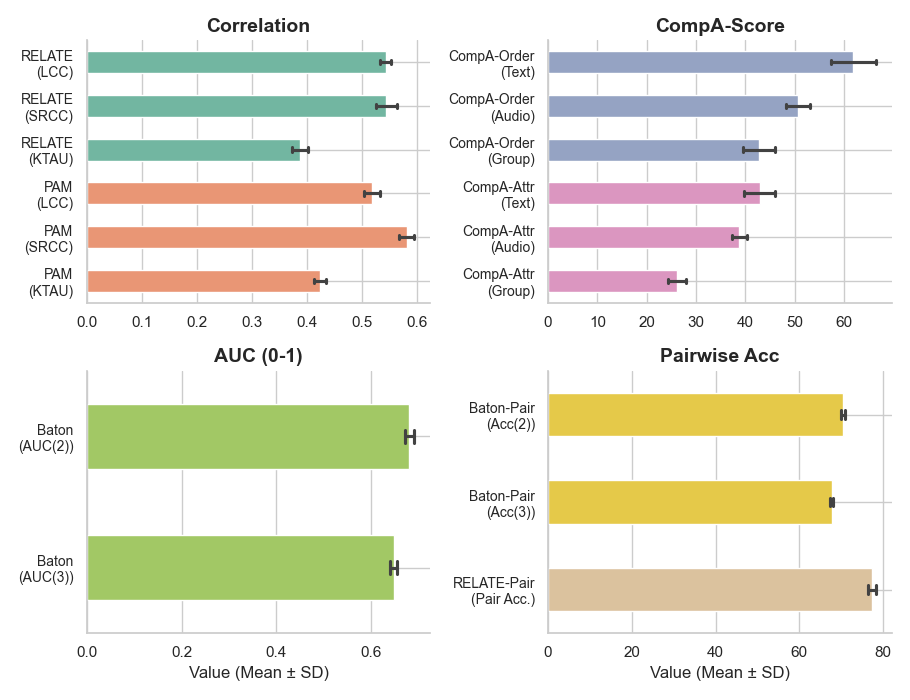
Figure 2: AQAScore’s judgments show low variance across diverse prompt templates, indicating robustness to prompt phrasing.
AQAScore demonstrates backbone agnosticism, with performance scaling monotonically with ALLM model capacity and pretraining hours. Reasoning-oriented models consistently outperform conversationally tuned variants, suggesting that chat fine-tuning may degrade the calibration necessary for fine-grained probability extraction.
Comparative Analysis and Broader Implications
The explicit AQA formulation enables AQAScore to capture subtle semantic alignment, outperforming all baselines in both relevance and compositional reasoning tasks. The framework’s sensitivity to semantic errors (missing events, attribute swaps, order inversion) implies that it can expose failure modes in current TTA generation systems that embedding techniques overlook.
In contrast, reference-based caption metrics and direct rating approaches show limitations, especially in pairwise comparison tasks involving compositional or attribute reasoning. Additionally, while prompt-based direct selection occasionally aligns better with human preference on relative caption ranking (e.g., FENSE and BRACE), AQAScore excels in hallucination robustness, achieving >98% discrimination on hallucinated audio-caption pairs.
These findings suggest AQAScore holds practical value for benchmark evaluation and as a high-fidelity reward signal for RL-based optimization of text-to-audio models. The paradigm shift from unstructured similarity to targeted semantic verification may also inform future multi-modal evaluation frameworks (vision, speech, music).
Limitations and Future Directions
Current AQAScore-centric evaluation is limited to text–audio relevance in general audio; other perceptual dimensions (style, musicality, emotion) and domain-specialized benchmarks remain underexplored. Data scarcity for human-labeled semantic alignment in TTA hinders broader meta-analysis. Additionally, while AQAScore offers robust fine-grained evaluation, general-purpose ALLMs present inconsistency in certain pairwise caption selection tasks, suggesting potential gains from developing evaluation-specialized ALLMs.
Conclusion
AQAScore leverages probabilistic audio question answering in ALLMs to provide a semantics-sensitive, robust metric for evaluating text-to-audio model outputs. By framing evaluation as targeted verification rather than similarity, it achieves stronger alignment with human judgment and finer detection of semantic inconsistency, scaling effectively with model capacity and exhibiting robustness to prompt design. The methodology establishes a foundation for future work in reward modeling, multi-modal evaluation, and compositional semantic understanding in generative audio systems.