- The paper's main contribution is the introduction of a hierarchical negative sampling strategy that categorizes negatives as easy, medium, and hard based on semantic similarity.
- The methodology employs empirical ratio calibration and persona-grounded synthesis to construct realistic training triplets for contrastive learning.
- Empirical results show significant improvements on retrieval benchmarks, demonstrating the scalability and robustness of the approach in dialogue agents.
HiNS: Hierarchical Negative Sampling for Robust Memory Retrieval Embedding
Introduction
The paper "HiNS: Hierarchical Negative Sampling for More Comprehensive Memory Retrieval Embedding Model" (2601.14857) addresses the inadequacy of current embedding model training methodologies for memory-augmented language agents, particularly the issue of negative sample heterogeneity in data construction. Standard approaches either sample negatives uniformly or rely solely on hard negatives, neglecting the nuanced spectrum of negative sample difficulty and their representative frequencies in actual conversational memory scenarios. This omission leads to embedding models that poorly discriminate between semantically close distractors and trivial negatives, ultimately limiting memory retrieval fidelity in AI dialogue agents.
Methodological Contributions
The proposed HiNS pipeline introduces a hierarchical and empirically grounded framework for negative sampling during embedding model training. The core innovations are:
- Explicit Difficulty Stratification: Negatives are divided into three tiers—easy, medium, hard—based on contextual and semantic similarity to the query. "Hard" negatives are from the same conversation and topic but from a different speaker, "medium" negatives share the conversation but differ in topic, and "easy" negatives are drawn from other conversations.
- Empirical Ratio Calibration: The distribution of negative sample types is adjusted to reflect the observed ratios in human-agent conversational data, improving the cognitive plausibility and practical challenge of retrieval.
- Persona-Grounded Synthesis: High-quality pseudo-dialogues are synthesized using the Nemotron-Personas dataset, with conversation, topic clustering, and query/evidence pair construction tightly controlled to avoid exploitable shortcuts and to encourage realistic memory complexity.
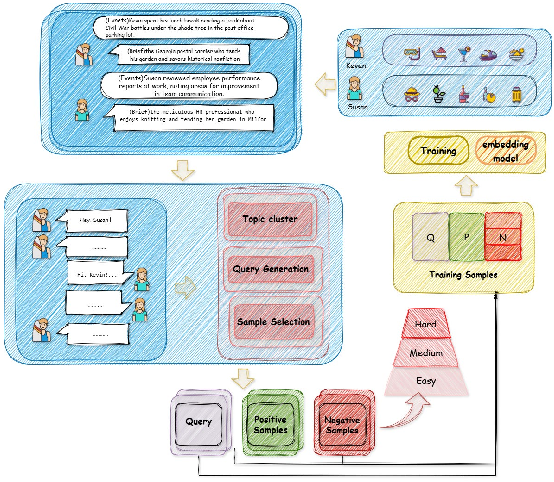
Figure 1: The HiNS pipeline: persona sampling, event generation, natural conversation synthesis, topic clustering, query construction, and hierarchical negative sampling for embedding model training.
This synthesis process, coupled with stratified sampling, provides training triplets for contrastive learning using an InfoNCE objective, offering a diversified and semantically structured supervision signal.
Empirical Validation
HiNS is instantiated with the BGE-small-en-v1.5 embedding model (384-dim, BERT-like), fine-tuned using 201,462 conversational samples and a DDP regime across multiple A800 GPUs. The negative sampling setting—15 negatives per query, proportioned as 30% hard, 30% medium, and 40% easy—avoids the issue of false negatives arising from in-batch selection.
Performance is measured on two challenging conversational memory retrieval benchmarks:
- LoCoMo (context-aware retrieval across diverse scenarios): HiNS yields an F1/BLEU-1 improvement of +3.27%/+3.30% (MemoryOS) and +1.95%/+1.78% (Mem0).
- PERSONAMEM (identity-consistent memory recall): HiNS improves total scores by +1.19% (MemoryOS) and +2.55% (Mem0).
The gains are consistent across different embedding model capacities (BGE-Small, BGE-Base, BGE-M3) and memory system architectures (from naive Mem0 to advanced MemoryOS), demonstrating the scalability and robustness of the approach.
Analysis: Ablations and Scaling
Ablation experiments show that the inclusion of all three negative types consistently yields the highest average retrieval metrics. Removing even "easy" negatives leads to notable degradation, especially in scenarios requiring robust temporal or multi-hop reasoning. This challenges the prevailing notion that only hard negatives are informative in contrastive learning, highlighting the stabilizing effect of easy negatives for model calibration.
Additional scaling studies confirm that stronger base models combined with HiNS synthesis lead to larger absolute performance gains, supporting the method's alignment with increased representational capacity. Careful evidence calibration, semantic query construction, and avoidance of in-batch negatives are necessary for fully realizing the method's advantages.
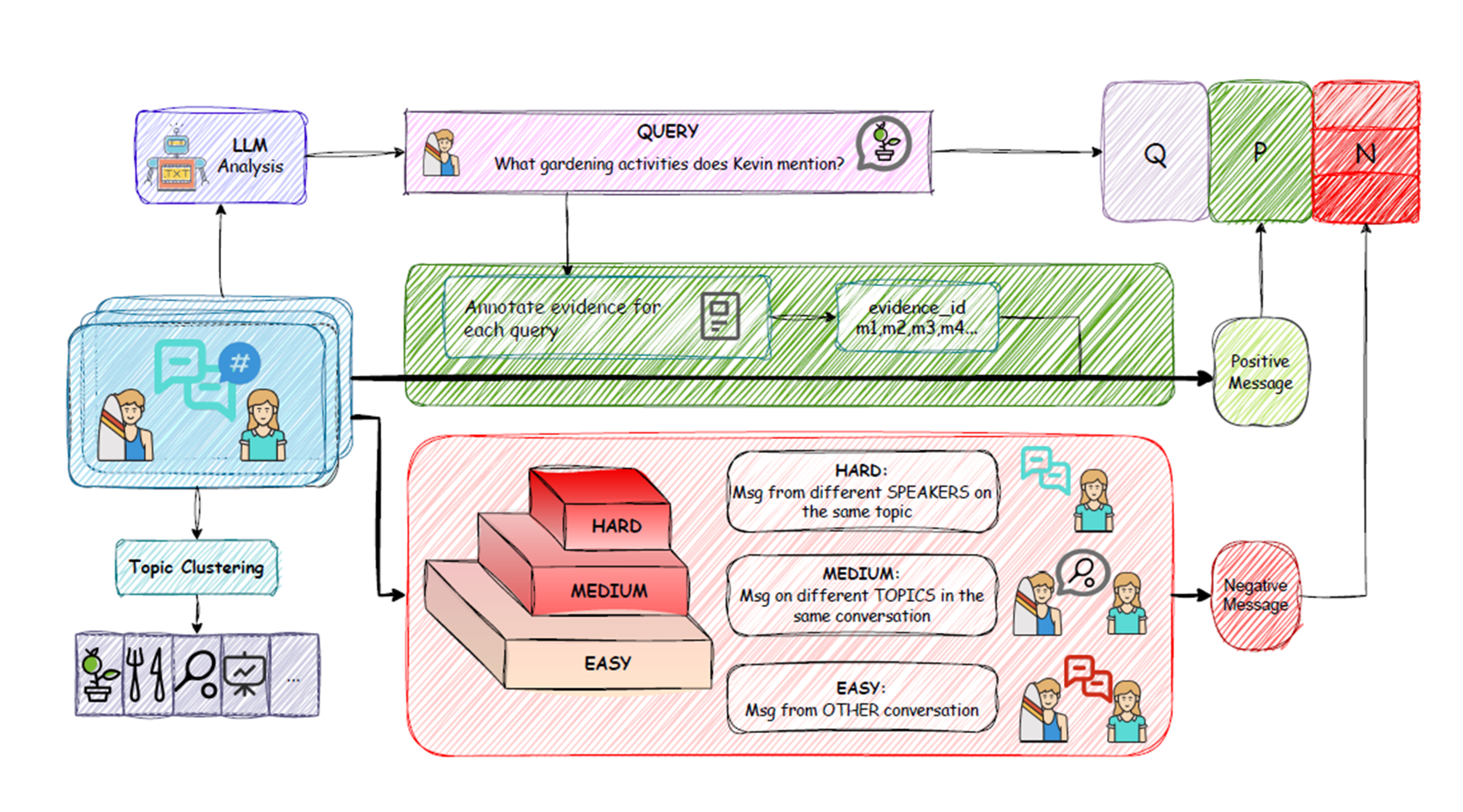
Figure 2: The hierarchical negative sampling process, visualizing easy, medium, and hard sampling from the synthesized conversational corpus.
Theoretical and Practical Implications
HiNS bridges the gap between synthetic negative generation and real-world conversational difficulty distributions, explicitly connecting memory retrieval evaluation to the kinds of errors that arise in non-trivial dialogue environments. By stratifying negatives and tuning their proportions, the resulting embeddings are better discriminators for both trivial and subtle distractors—critical for open-ended, long-horizon agent interactions.
For downstream agent frameworks, HiNS yields consistent enhancements, regardless of the sophistication of the external memory system, indicating that careful negative engineering in the embedding stage can generalize and improve memory robustness across the stack.
Practically, HiNS can be deployed as a universal fine-tuning pipeline for embedding models in memory-centric AI systems (dialogue agents, long-term personal assistants, and personalized recommendation interfaces), reducing the susceptibility to overfitting on specific error types and increasing resistance to adversarial retrieval settings.
Directions for Future Research
The current rule-based stratification approach may be replaced or enhanced by learned difficulty predictors, which could further improve semantic granularity in negative selection. Training data size and diversity, as well as more direct coupling with downstream agent behaviors (e.g., generation or interactive evaluation) remain promising directions. In addition, integrating privacy-preserving negative sampling procedures would be essential for deployment in real-world systems with sensitive memory content.
Conclusion
This work establishes that hierarchical, empirically-tuned negative sampling in the construction of conversational memory retrieval datasets leads to systematically improved embedding models, benefiting both baseline and advanced agent frameworks in long-horizon dialogue tasks. HiNS provides an extensible, data-centric foundation for more robust and discriminative memory-augmented AI systems.