HumanoidVLM: Vision-Language-Guided Impedance Control for Contact-Rich Humanoid Manipulation
Abstract: Humanoid robots must adapt their contact behavior to diverse objects and tasks, yet most controllers rely on fixed, hand-tuned impedance gains and gripper settings. This paper introduces HumanoidVLM, a vision-language driven retrieval framework that enables the Unitree G1 humanoid to select task-appropriate Cartesian impedance parameters and gripper configurations directly from an egocentric RGB image. The system couples a vision-LLM for semantic task inference with a FAISS-based Retrieval-Augmented Generation (RAG) module that retrieves experimentally validated stiffness-damping pairs and object-specific grasp angles from two custom databases, and executes them through a task-space impedance controller for compliant manipulation. We evaluate HumanoidVLM on 14 visual scenarios and achieve a retrieval accuracy of 93%. Real-world experiments show stable interaction dynamics, with z-axis tracking errors typically within 1-3.5 cm and virtual forces consistent with task-dependent impedance settings. These results demonstrate the feasibility of linking semantic perception with retrieval-based control as an interpretable path toward adaptive humanoid manipulation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows how a humanoid robot (Unitree G1) can look at a scene with its head camera, understand what task it needs to do, and then automatically choose the right “touch” settings to do that task safely and smoothly. These touch settings control how stiff or soft the robot’s arm is and how much the hand should close, so it can, for example, gently place an egg or firmly press a tool.
What questions did the researchers ask?
They focused on two simple questions:
- From just one camera image, can a robot figure out what kind of manipulation task it’s doing (like pressing, picking up, or poking) and pick the right settings for its arm and gripper?
- Will those chosen settings make the robot interact safely and reliably with different objects and surfaces in the real world?
How did they do it?
To make this work, they connected three main pieces: seeing and understanding, choosing settings, and moving safely.
Seeing and understanding the scene
They used a vision–LLM (VLM), which is an AI that can “look” at a picture and use words to describe what’s happening. Think of it like a smart helper that answers yes/no questions about the scene: “Is there a fork?” “Is the robot trying to poke a tomato?” This step turns camera images into a clear task label, like “tool poking” or “grasp and lift.”
Choosing the right settings from a small “library”
The robot then searches a small, hand-built library (database) of best-known settings for different tasks:
- “Impedance” settings for the arm (how stiff or soft it should be, like a spring and a shock absorber working together).
- A gripper angle (how open or closed the hand should be) for different object types (rigid, soft, fragile, etc.).
To find the right entry quickly and smartly, the system uses a technique called Retrieval-Augmented Generation (RAG) with FAISS. In everyday terms:
- RAG + FAISS = a fast, meaning-based search that finds the most similar task in the library, not just exact word matches.
- “Embeddings” are like turning words into numbers so the computer can measure what’s similar.
So, after the VLM says “this looks like tool poking,” the search pulls up the matching stiffness/softness and gripper setting that were previously tested to work well.
Moving safely and gently (impedance control)
The robot’s controller uses “impedance control,” which you can imagine as:
- Stiffness: like a spring—how hard it pushes back when pressed.
- Damping: like a shock absorber—how it smooths out motion so it doesn’t bounce.
By picking the right stiffness and damping:
- Soft settings help the robot follow a curved surface without scraping.
- Stiffer settings help it press a massage ball or poke with a fork without wobbling. The robot doesn’t have force sensors in its hands, so it calculates “virtual forces” from how far off it is from where it wants to be—like estimating how hard it’s pushing based on the spring’s stretch.
What did they find?
They tested 14 different camera scenes covering 9 task types (such as surface-following, pressing with a ball, placing an egg and a bottle, poking with a fork, and grasping from a table).
Key results:
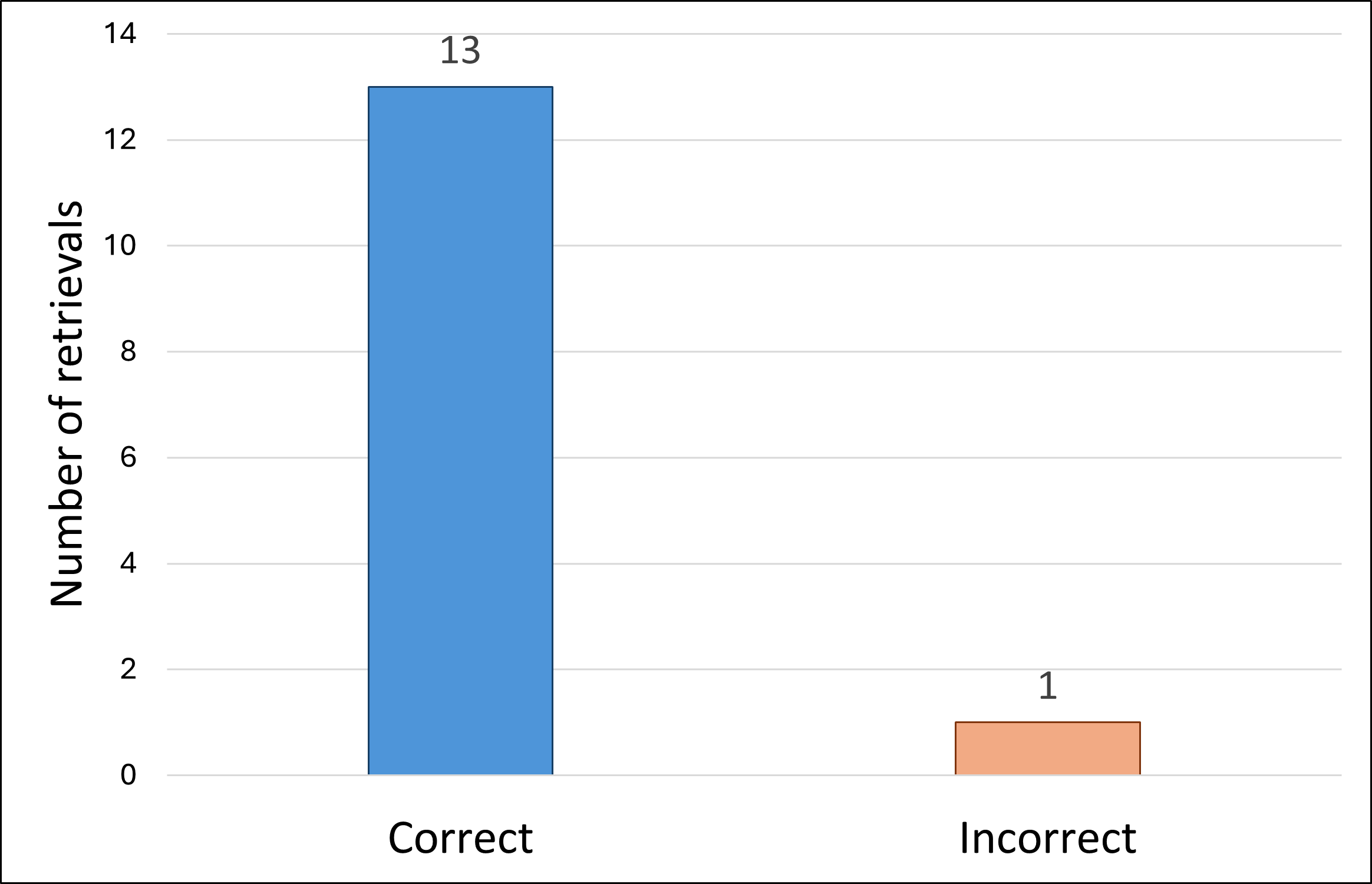
- The system picked the correct settings 13 out of 14 times (93% accuracy). The one mistake happened when the main object was mostly hidden.
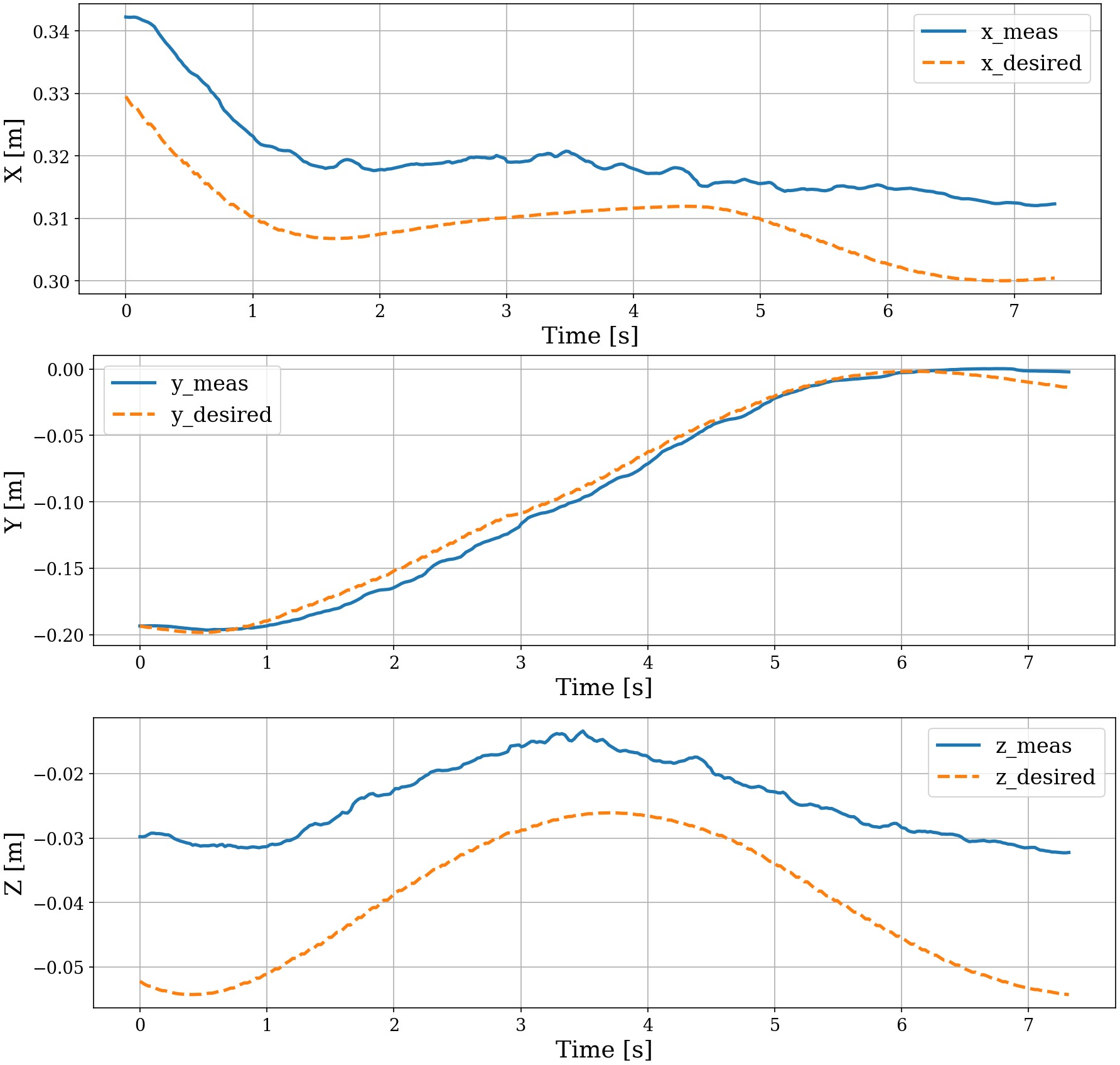
- During real robot tests, the up–down tracking error (the z-axis) stayed small, typically about 1–3.5 cm.
- The “virtual forces” matched the chosen settings: softer settings produced gentler forces; stiffer settings produced stronger forces, just as intended.
- For bimanual tasks (like placing an egg and a bottle at the same time), the robot used soft settings for the fragile egg and stiffer settings for the sturdier bottle—showing it can adapt to each hand’s job.
Why this matters: It proves a robot can look at a scene, understand the task, and automatically choose safe, task-appropriate touch behaviors without a human hand-tuning everything.
Why does it matter? What’s the potential impact?
This approach links high-level understanding (“What am I doing?”) with low-level actions (“How soft or stiff should my arm be?”). That’s important for robots working around people and varied objects, where the right touch changes from moment to moment.
Potential impact:
- Safer, more flexible home or workplace robots that can handle fragile or oddly shaped items.
- Faster setup, since you don’t need an expert to manually tune stiffness and gripper settings for each new task.
- A clear, interpretable method (retrieval from a known library) that engineers can inspect and improve.
Limitations and next steps:
- The current library is small (9 tasks), so it’s a proof of feasibility, not a final solution.
- Future work could add better orientation control, learn continuous settings (not just pick from a list), and use touch sensors or vision-based touch to adapt on the fly.
In short, the paper shows a practical and understandable way to give humanoid robots a better “sense of touch” guided by what they see and understand—bringing them closer to handling everyday tasks safely and intelligently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what the paper leaves missing, uncertain, or unexplored, framed to be concrete and actionable for future research.
- Robustness to occlusions: The single failure case arose from object occlusion; how can the VLM–RAG pipeline be made robust to partial/complete occlusions (e.g., via depth sensing, multi-view, active perception, or temporal context)?
- Use of depth and 3D geometry: The system receives RGB-D, but only uses RGB; what gains in task inference and parameter retrieval result from integrating depth, 3D scene reconstruction, or point-cloud features?
- Temporal reasoning: Task inference relies on a single image; would video-based temporal context improve disambiguation of tasks and interaction mode (e.g., approach vs contact vs lift)?
- Limited task coverage: The database has nine tasks and evaluation uses 14 images; how does performance scale across broader, more diverse, and non-tabletop tasks, including dynamic, deformable, and cluttered environments?
- Generalization to unseen tasks/objects: The retrieval is discrete over known entries; how can a learned continuous mapping or metric space interpolation handle novel tasks, unseen object categories, and mixed-material objects?
- Database construction and updating: Impedance/gripper entries are manually curated; can the system autonomously collect, validate, and update entries online, with criteria for stability, safety, and performance?
- Baselines and ablative studies: No comparison to rule-based controllers, learned variable impedance, or alternative VLMs/embeddings; what is the marginal contribution of VLM, FAISS retrieval, and each module?
- End-to-end latency and real-time viability: The VLM runs offboard; what are the measured inference and communication latencies, and how do they affect closed-loop manipulation in rapidly changing scenes?
- Position-based impedance with built-in position controllers: Without torque control or passivity guarantees, what are the formal stability/safety properties of the position-domain impedance execution on Unitree G1?
- Virtual force validity: “Virtual forces” are used as proxies without ground-truth contact measurements; how well do they correlate with real contact forces measured via instrumented environments or external F/T sensors?
- Rotational impedance: Rotational impedance is fixed; what is the impact of task-dependent rotational stiffness/damping on orientation-sensitive tasks (e.g., tool use, surface following over curved normals)?
- Full 3D compliance evaluation: Results emphasize z-axis errors; how do retrieved gains affect x/y compliance, tangential contact behavior, and frictional interactions?
- Gain scheduling and transitions: The pipeline sets gains per task but does not address transitioning between sub-tasks or during contact onset; how should gains be scheduled to avoid transients and ensure safety?
- Bimanual coordination: Dual-object placement uses asymmetric gains but lacks coordinated impedance strategies; how to design coupled bimanual impedance policies for multi-contact and role allocation?
- Gripper control granularity: Gripper actions are discrete (open/close) with a preset angle; how can continuous grasp angle control, compliance modulation, and slip detection improve handling of fragile/deformable objects?
- Object property inference: The system infers material/fragility implicitly from vision; can explicit estimation of stiffness, compliance, or fragility (via vision or visuotactile signals) improve gripper/impedance selection?
- Failure detection and recovery: When VLM misclassifies or retrieval is wrong, how does the system detect errors and recover (e.g., confidence thresholds, alternative queries, active re-perception)?
- Safety in HRI: Despite claims of HRI relevance, no safety metrics or human-in-the-loop tests are reported; what quantitative safety criteria (contact force bounds, passivity margins) are needed for shared workspaces?
- Controller frequency: The controller runs at 50 Hz; is this sufficient for contact-rich dynamics, and how do higher rates or edge deployment affect stability and responsiveness?
- Calibration and measurement fidelity: End-effector positions are estimated via forward kinematics; what are the calibration errors (camera–robot extrinsics, joint offsets) and their impact on tracking/force proxies?
- Parameter transparency and reproducibility: Values for virtual mass M, rotational gains, and database entries are not fully disclosed; can the authors release code, data, and parameter ranges to enable replication?
- Retrieval pipeline design: The FAISS queries use text embeddings from VLM outputs; would multimodal embeddings (e.g., CLIP, image–text fusion) or structured scene graphs yield more accurate retrieval?
- Task success metrics: The study reports tracking errors and retrieval accuracy but not task success rates (e.g., grasp success, tool-use success) across repeated trials; can standardized task-level metrics be added?
- Domain shift and lighting: Robustness to lighting changes, background clutter, and camera viewpoint variations is not quantified; how does performance degrade under realistic household variability?
- Material-contact modeling: The system does not model friction or surface compliance; can simple contact models or learned estimators inform impedance selection beyond empirical lookup?
- Adaptive/closed-loop impedance: Without force or visuotactile sensing, impedance is fixed per task; how can online adaptation with tactile (or vision-based contact state) improve safety and performance?
- Multi-step and language-conditioned tasks: The pipeline infers a single task via yes/no queries; can free-form language instructions or hierarchical plans enable multi-step, compositional tasks?
- Scaling beyond Unitree G1: How portable is the approach to other humanoids with different kinematics, actuation, and sensing, and what calibration/mapping procedures are required?
- Energy and compute constraints: Offboard GPU inference may not be practical in mobile settings; what are the trade-offs and feasibility of on-board deployment and model compression for real-time control?
- Formal guarantees: No formal analysis (e.g., passivity, stability margins under bounded disturbances) is provided; can theoretical guarantees be established for the VLM–retrieval–impedance pipeline in contact-rich manipulation?
Practical Applications
Summary
This paper presents HumanoidVLM, a vision–language–guided, retrieval-based controller that selects task-appropriate Cartesian impedance gains and gripper configurations from an egocentric RGB image and executes them via task-space impedance control on a Unitree G1 humanoid. The approach couples a VLM (Molmo-7B-O) with a FAISS-based RAG over two small, human-validated databases (impedance and gripper angles), achieving 93% retrieval accuracy across 14 scenarios and stable, compliant manipulation in contact-rich tasks.
Below are the practical applications, grouped by deployment horizon. Each item specifies sectors, candidate tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These can be piloted or deployed now with modest integration and safety oversight, especially in labs, pilot sites, and controlled industrial or service settings.
- Adaptive impedance selection for contact-rich manipulation on existing humanoids and arms
- Description: Use VLM+RAG to auto-select stiffness/damping and gripper angles per task (e.g., surface following, delicate placement, tool poking, grasp-and-lift).
- Sectors: Robotics, manufacturing (light assembly), logistics (light manipulation), service robotics, HRI labs.
- Tools/products/workflows: ROS2/MoveIt plugin exposing an “Impedance Parameter Server”; FAISS microservice; JSON/CSV impedance-profile libraries; on-robot wrapper for Unitree G1 and other manipulators; commissioning wizard to test and store task profiles.
- Assumptions/dependencies: Egocentric RGB camera; offboard GPU or edge inference; pre-built, human-validated database; limited tasks (nine in paper); contact mainly along z-axis; no wrist force-torque sensing (virtual forces used as proxies); 93% retrieval on small test set; failure modes with occlusion.
- Rapid commissioning workflow for new tasks via “database authoring”
- Description: Operators empirically try multiple gains per task, record the most stable/efficient parameters, and store them in a searchable DB for repeatable deployment.
- Sectors: Industry (cells with high mix/low volume), labs, makerspaces.
- Tools/products/workflows: Commissioning UI for trial logging, retrieval tags, and safety bounds; human-in-the-loop review and approval; retrieval-confidence display.
- Assumptions/dependencies: Skilled operator for safe gain exploration; controlled environment; standard operating procedures for safe testing and rollback.
- Semantically adaptive compliance for collaborative HRI
- Description: Adjust compliance on-the-fly based on perceived task and object fragility (e.g., soft vs stiff gains for egg vs bottle in bimanual placement).
- Sectors: HRI, cobotics, education labs.
- Tools/products/workflows: Safety envelope over K/D bounds; confidence-aware fallback (manual teleop or fixed safe gains); logging for audits.
- Assumptions/dependencies: Clear visual view; reliable VLM task inference; established safe impedance ranges; careful hazard analysis for 7% mis-retrieval.
- Tool-use support in constrained contact tasks
- Description: Moderate stiffness/damping selection for tasks like poking, pressing buttons, gently scraping/wiping where force sensing is absent.
- Sectors: Facilities services, light maintenance, retail automation.
- Tools/products/workflows: Task templates for common tools; gripper-angle DB for object/tool categories.
- Assumptions/dependencies: Stable grasping hardware; limited orientation sensitivity (rotational impedance fixed in paper); non-critical safety context.
- Assistive and wellness prototypes with controlled pressure application
- Description: Use retrieved higher normal-direction stiffness for tasks like applying a massage ball against a surface with bounded virtual forces.
- Sectors: Assistive robotics (R&D), rehabilitation labs.
- Tools/products/workflows: Pressure profiles with virtual-force monitoring dashboards; clinician-supervised trials.
- Assumptions/dependencies: Research-only (not clinical-grade); virtual force as proxy (no force sensors); strict supervision and safety gating; regulatory constraints.
- Baseline for academic benchmarking and teaching modules
- Description: A reproducible baseline for “semantic-to-control” mapping, impedance evaluation (errors, virtual forces), and VLM-robotics integration.
- Sectors: Academia, STEM education.
- Tools/products/workflows: Open-source repo with FAISS+sentence-transformers+VLM; lab exercises on impedance control and retrieval; dataset of ego-centric images and task labels.
- Assumptions/dependencies: Access to humanoid/arm platform; GPU for VLM; reproducible camera setup.
- Compliance monitoring and audit logging for safety reviews
- Description: Interpretability via traceable retrievals (task label → impedance/gripper selection) and virtual-force telemetry for safety committees.
- Sectors: HRI safety, internal compliance, institutional review boards (IRB-equivalent for robotics labs).
- Tools/products/workflows: Retrieval logs, explainability reports, bounds-check alerts, playback of pose/force proxies.
- Assumptions/dependencies: Established safety thresholds; versioned DB entries; documented failure handling.
Long-Term Applications
These require additional research, scaling, sensing, or productization beyond the current proof-of-feasibility.
- Continuous, learned mapping from scene/task to full 6-DoF variable impedance and grasp strategy
- Description: Replace discrete DB with a learned continuous policy that interpolates to unseen tasks and modulates both translational and rotational impedance.
- Sectors: Advanced manufacturing, dexterous manipulation, construction robotics.
- Tools/products/workflows: Scene-to-impedance neural mappers; uncertainty estimation; self-supervised data collection.
- Assumptions/dependencies: Large, diverse, labeled datasets; safety-constrained learning; robust sim-to-real transfer.
- Closed-loop impedance adaptation with tactile/force/visuotactile feedback
- Description: Fuse VLM-based priors with on-the-fly force/tactile estimates to adapt compliance safely during contact.
- Sectors: Healthcare (patient handling, rehabilitation), home assistance, precision assembly.
- Tools/products/workflows: Tactile skins, wrist F/T sensors, visuotactile cameras; adaptive controllers with safety filters (e.g., passivity-based).
- Assumptions/dependencies: Additional hardware sensors; real-time estimation and stability guarantees; regulatory approvals for human contact.
- Certified “Impedance Profile Libraries” and marketplaces
- Description: Standardized, shareable task profiles (K/D/gripper) vetted for safety and compatibility across robot models.
- Sectors: Robotics platforms ecosystem, integrators, OEMs.
- Tools/products/workflows: Profile schemas, certification processes, versioning, compatibility layers.
- Assumptions/dependencies: Industry standards for impedance parameters; cross-vendor agreement; liability frameworks.
- Semantically grounded insertion and compliant assembly
- Description: Orientation-sensitive, contact-rich tasks (e.g., peg-in-hole, screwing, connector mating) guided by scene semantics and adaptive impedance.
- Sectors: Electronics assembly, automotive, aerospace.
- Tools/products/workflows: Rotational impedance control, force/torque sensing, precise state estimation, hybrid position–force control.
- Assumptions/dependencies: High-precision hardware; robust perception in clutter; high safety guarantees.
- General-purpose home and service robots handling delicate and diverse objects
- Description: Household tasks (organizing, table setting, dish handling, appliance interaction) with task-aware compliance to avoid damage.
- Sectors: Consumer robotics, eldercare, hospitality.
- Tools/products/workflows: Continual learning for household vocabularies; confidence-aware autonomy with human fallback; skill libraries.
- Assumptions/dependencies: Broad generalization; long-tail robustness; cost-effective sensors and compute; rigorous safety certification.
- Edge–cloud “Compliance-as-a-Service” for multi-robot fleets
- Description: Cloud-hosted retrieval and policy services that return compliant control parameters from robot camera feeds; fleet-wide updates.
- Sectors: Warehousing, facilities management, smart buildings.
- Tools/products/workflows: Low-latency streaming, model serving, fleet telemetry dashboards, A/B testing for profiles.
- Assumptions/dependencies: Reliable connectivity; latency bounds; data security/privacy; MLOps for robotics.
- Policy and standards for AI-in-the-loop physical interaction
- Description: Regulatory frameworks for traceability, confidence thresholds, fallback mechanisms, and runtime safety bounds when VLMs influence control.
- Sectors: Policy, standards bodies (ISO/IEC), robotics consortia.
- Tools/products/workflows: Conformance test suites; logging/telemetry standards; hazard analysis templates for retrieval-based controllers.
- Assumptions/dependencies: Multi-stakeholder consensus; incident reporting channels; alignment with existing cobot safety norms (e.g., ISO/TS 15066).
- Infrastructure inspection and energy-sector maintenance with compliant contact
- Description: Robots applying controlled contact for gauge reading, valve manipulation, gentle cleaning/inspection on delicate surfaces.
- Sectors: Energy, utilities, industrial inspection.
- Tools/products/workflows: Domain-specific impedance profiles, tool libraries, safety envelopes for hazardous environments.
- Assumptions/dependencies: Ruggedized platforms; environmental certifications; enhanced perception under adverse conditions.
Notes on cross-cutting feasibility:
- Visual dependence: Performance drops under occlusions or poor lighting; multi-view and depth cues would improve robustness.
- Safety: Mis-retrieval risk mandates bounded gains, runtime monitors, and confidence-based fallbacks.
- Hardware variance: Porting beyond Unitree G1 requires calibration, kinematic compatibility, and possibly different gripper models.
- Compute: Real-time VLM inference currently assumes offboard GPU; productization needs efficient edge models or hardware accelerators.
Glossary
Cartesian impedance parameters: Refers to coefficients like stiffness and damping used to regulate how a robot's end-effector interacts with its environment along the cartesian axes. Example: "The retrieval system relies on two JSON databases. The impedance database stores task-specific cartesian impedance parameters..."
Compliant manipulation: A robotic action that allows some flexibility and adaptation in the interaction with objects, often making use of impedance control to accommodate variations in contact forces. Example: "This approach enables the robot to autonomously determine task-appropriate compliance settings for a given scene."
Ego-centric RGB image: An image captured from the robot's own viewpoint, often used for perception tasks where the robot interprets its surroundings as it sees them. Example: "Given a single egocentric image, HumanoidVLM infers the ongoing manipulation task through structured visual queries..."
FAISS-based Retrieval-Augmented Generation (RAG): A system using Facebook AI Similarity Search (FAISS) for efficient similarity search and retrieval in vector spaces, enhancing the generation of content based on retrieved knowledge. Example: "The system couples a visionâLLM for semantic task inference with a FAISS-based Retrieval-Augmented Generation (RAG) module..."
Inverse kinematics: A computational process that calculates joint parameters to achieve a desired position/orientation of the end-effector. Example: "These desired virtual poses are then converted into joint targets through inverse kinematics..."
Multimodal representation: A data representation that combines multiple types of information, like visual and textual data, to enhance understanding and processing. Example: "The visual output is converted into a multimodal representation and embedded using the all-MiniLM-L6-v2 sentence-transformer..."
Semantic task inference: The process of deducing the purpose or required actions for accomplishing a task based on semantic understanding of contextual information. Example: "The system couples a visionâLLM for semantic task inference with a FAISS-based Retrieval-Augmented Generation (RAG) module..."
Stiffnessâdamping pairs: Refers to combinations of stiffness and damping coefficients used in impedance control to define the interaction quality and compliance during contact with objects. Example: "As a result, current humanoid systems lack the capacity to autonomously translate visual semantics into actionable, task-appropriate interaction behaviorsâa limitation..."
Task-space impedance controller: A control system that directly manipulates a robot's end-effector impedance to allow compliant interaction with an environment. Example: "The retrieved control parameters (, , and gripper angle ) are transmitted to the onboard G1 computer, where a task-space cartesian impedance controller generates compliant end-effector trajectories."
Vision--LLMs (VLMs): Models capable of understanding connections between visual and linguistic data, used for high-level reasoning tasks. Example: "In parallel, recent advances in Vision--LLMs (VLMs) have demonstrated impressive capabilities in open-world perception, contextual reasoning..."
Collections
Sign up for free to add this paper to one or more collections.