- The paper's main contribution is demonstrating that multi-task QLoRA maintains or improves code correctness and static quality across diverse code tasks with significantly reduced resource use.
- It evaluates Qwen2.5-Coder at multiple scales (0.5B, 1.5B, 3B) on NL-to-Code generation, code summarization, and translation tasks, revealing crucial scalability impacts.
- Empirical findings reveal that multi-task QLoRA can match or outperform full fine-tuning by reducing cyclomatic complexity and enhancing BLEU and CodeBLEU scores on benchmark tasks.
Problem Motivation and Research Questions
With the increasing deployment of large code models (LCMs) for code generation, translation, and summarization, the computational and memory demands of standard full model fine-tuning approaches have become a bottleneck for practical adaptation and adoption. Parameter-Efficient Fine-Tuning (PEFT) methods, such as QLoRA, partially address these constraints but prior studies have mainly evaluated them in single-task regimes, leaving their robustness, transferability, and quality behavior under realistic multi-task joint optimization largely uncharacterized. The authors formulate two precise research questions: (1) how does multi-task QLoRA compare with single-task PEFT for functional and quality metrics across disparate code-related tasks; and (2) what performance and efficiency trade-offs emerge when contrasting multi-task QLoRA against full-parameter multi-task tuning as model scale and task coverage vary.
Methodology: Model, Data, and Training Regimes
The investigation adopts Qwen2.5-Coder as the LCM testbed, considering three parameter scales (0.5B, 1.5B, 3B). Tasks span NL-to-Code generation, Code-to-NL summarization, and code translation (Java, Python, C#), with domain-aligned datasets and multi-metric evaluation including execution-based correctness and comprehensive static analysis for non-functional quality. Apart from the QLoRA configuration (adapter rank, scaling, dropout; only updating lightweight adapters), consistent hyperparameters and dataset splits enable controlled comparisons. Training configurations include multi-task and single-task QLoRA, and multi-task full-model fine-tuning.
Empirical Results: Correctness and Code Quality under Multi-Task QLoRA
Code Generation
Multi-task QLoRA achieves competitive or superior correctness (pass@1) compared to single-task training. For Python, improvements with model scale are observed, with the 3B model attaining 21.05% pass@1 compared to 20.53% for single-task. For Java, the 3B multi-task model achieves 32.07% pass@1, outperforming single-task (29.89%). Inspection of quality metrics reveals that at larger scales, multi-task QLoRA consistently reduces cyclomatic complexity and maintainability warnings—contrary to assumptions that PEFT inevitably degrades quality—while providing more concise code. Analysis of static quality (Pylint, PMD, SonarCloud) corroborates improved or equivalent standards compliance, with effect sizes in paired statistical tests remaining negligible.

Figure 1: MT-QLoRA produces functionally correct, concise Python code that aligns with the specification, whereas ST-QLoRA yields more complex, partially incorrect output.
Code Translation
Translation outcomes display strong directionality and scale dependence. For Java→C#, single-task QLoRA is generally superior in CodeBLEU, though the difference narrows or reverses at intermediate model sizes. For C#→Java, multi-task QLoRA at the 1.5B and 3B scales exhibits robust generalization—achieving up to 70.72% CodeBLEU. Static analysis unveils fewer Roslyn/PMD issues at higher capacities when using multi-task QLoRA, especially for challenging inputs with deeper control flow.
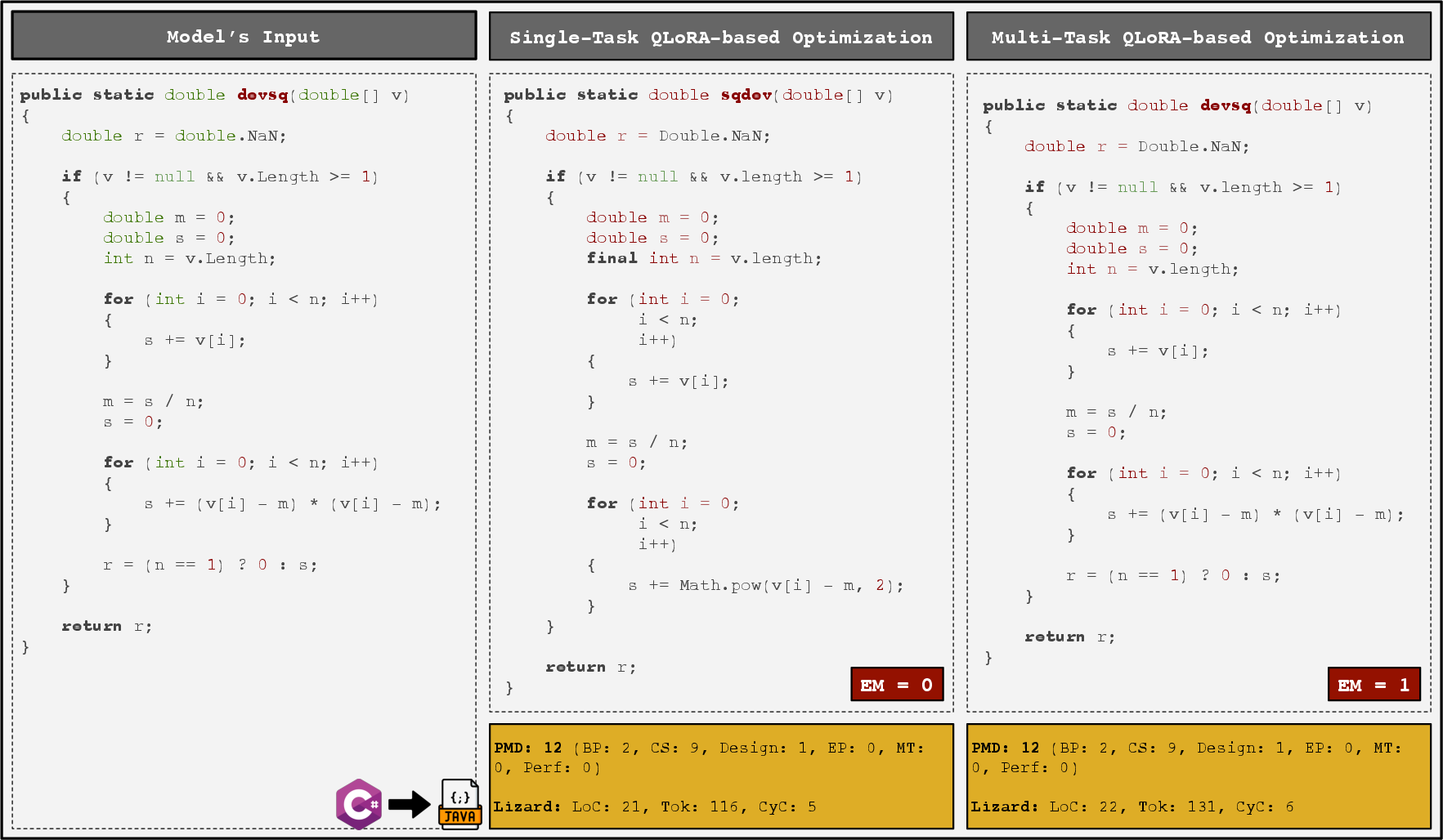
Figure 2: MT-QLoRA preserves interface and functional details in C#→Java translation, achieving exact match, whereas ST-QLoRA drops critical computations and alters interface definition.
Code Summarization
Multi-task QLoRA yields strong gains for Python summarization—across BLEU, METEOR, ROUGE-L, and BERTScore, with improvements up to 51.5% over single-task QLoRA at 1.5B and >28% at 3B. Java summarization behaves differently, with single-task training slightly outperforming in overlap and semantic metrics. However, LLM-as-a-judge scores for content adequacy, conciseness, and fluency show parity between regimes.
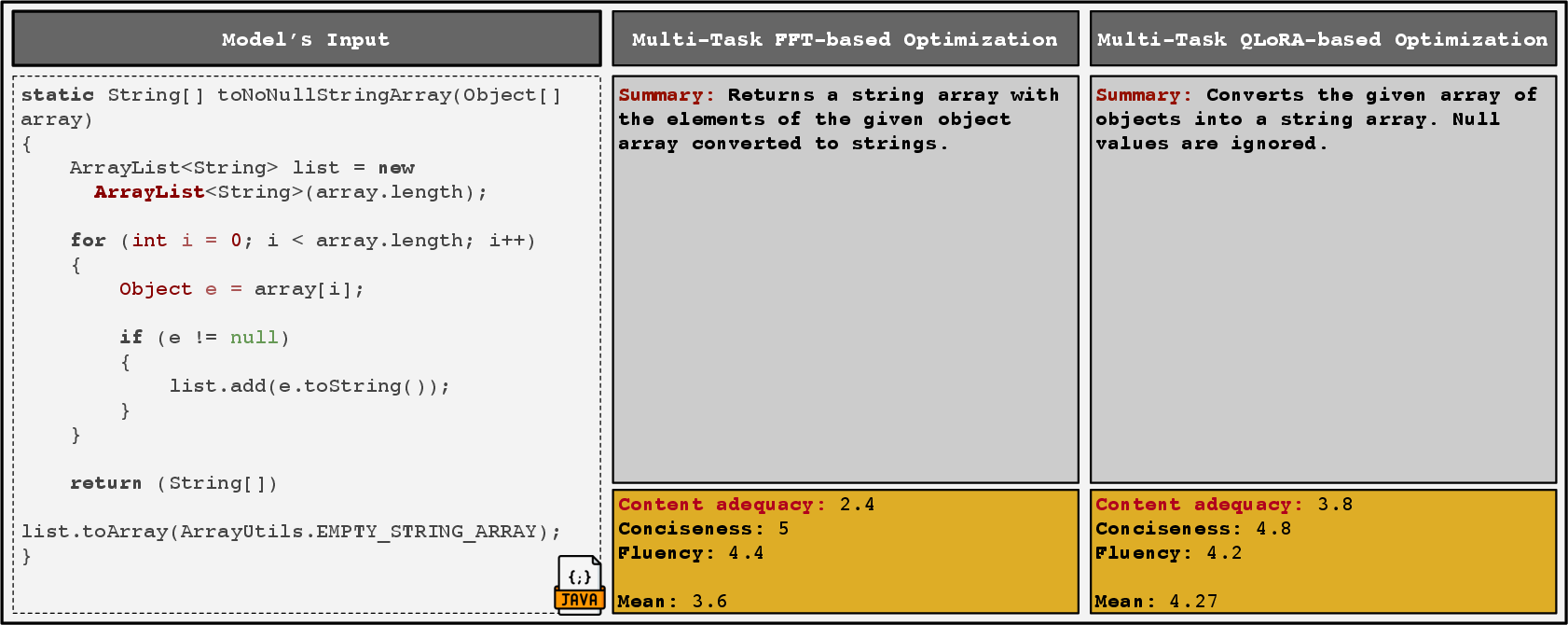
Figure 3: MT-QLoRA delivers more semantically complete Python code summaries, capturing key behavioral constraints that ST-QLoRA omits.
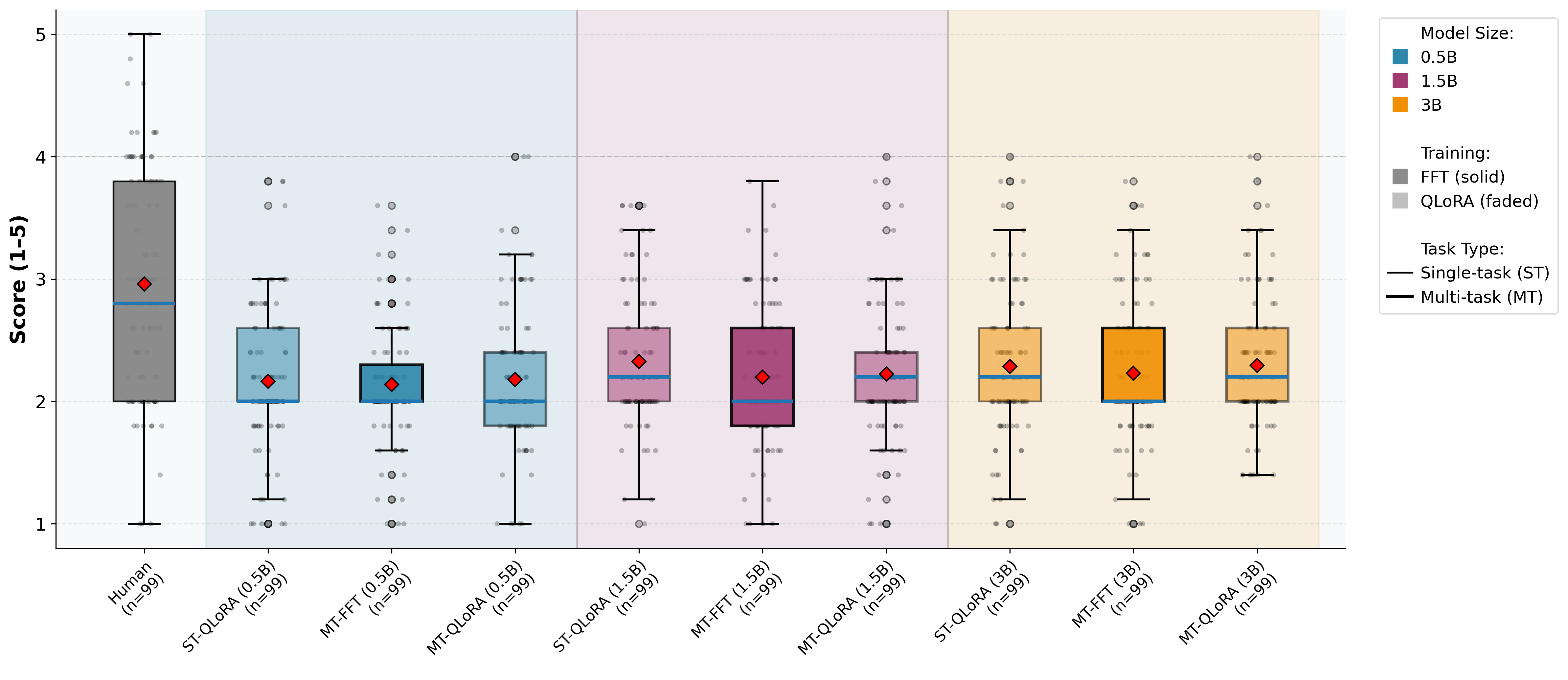
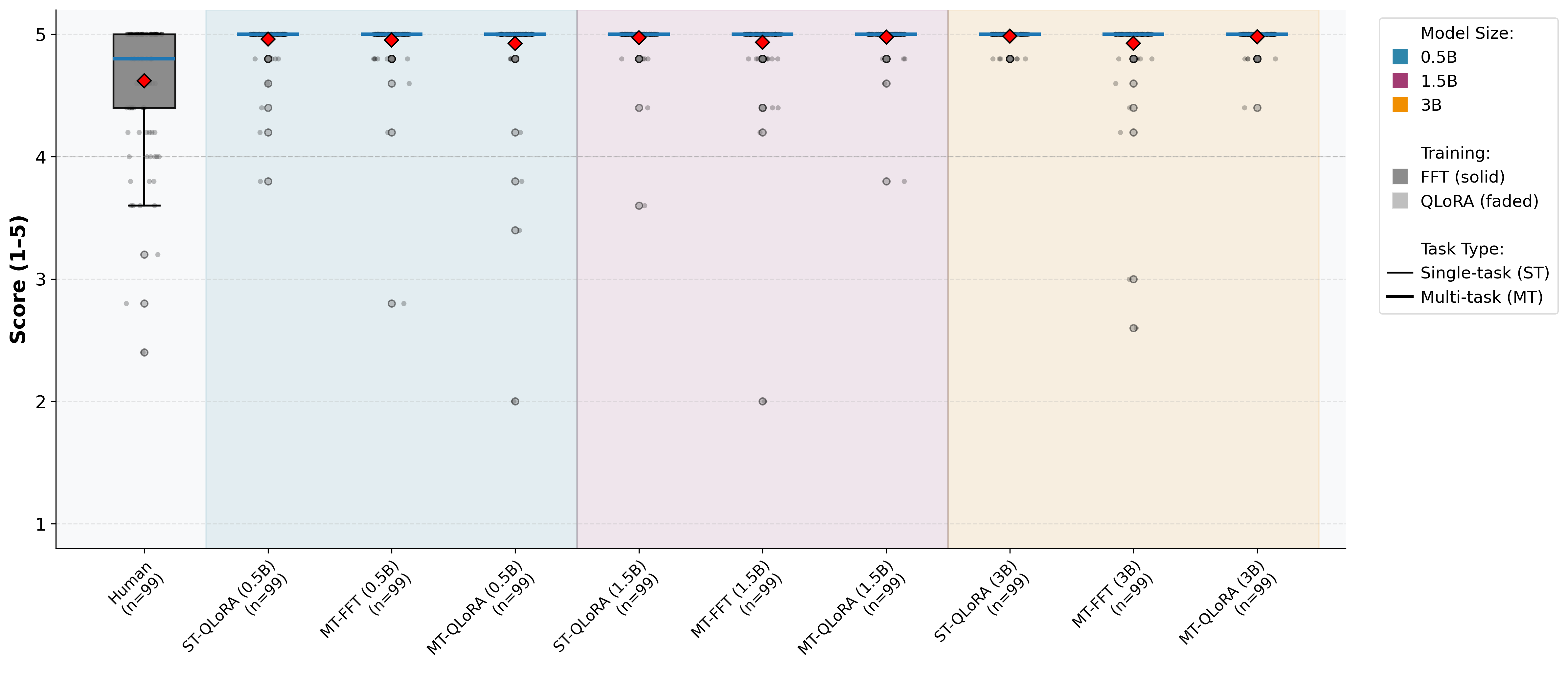
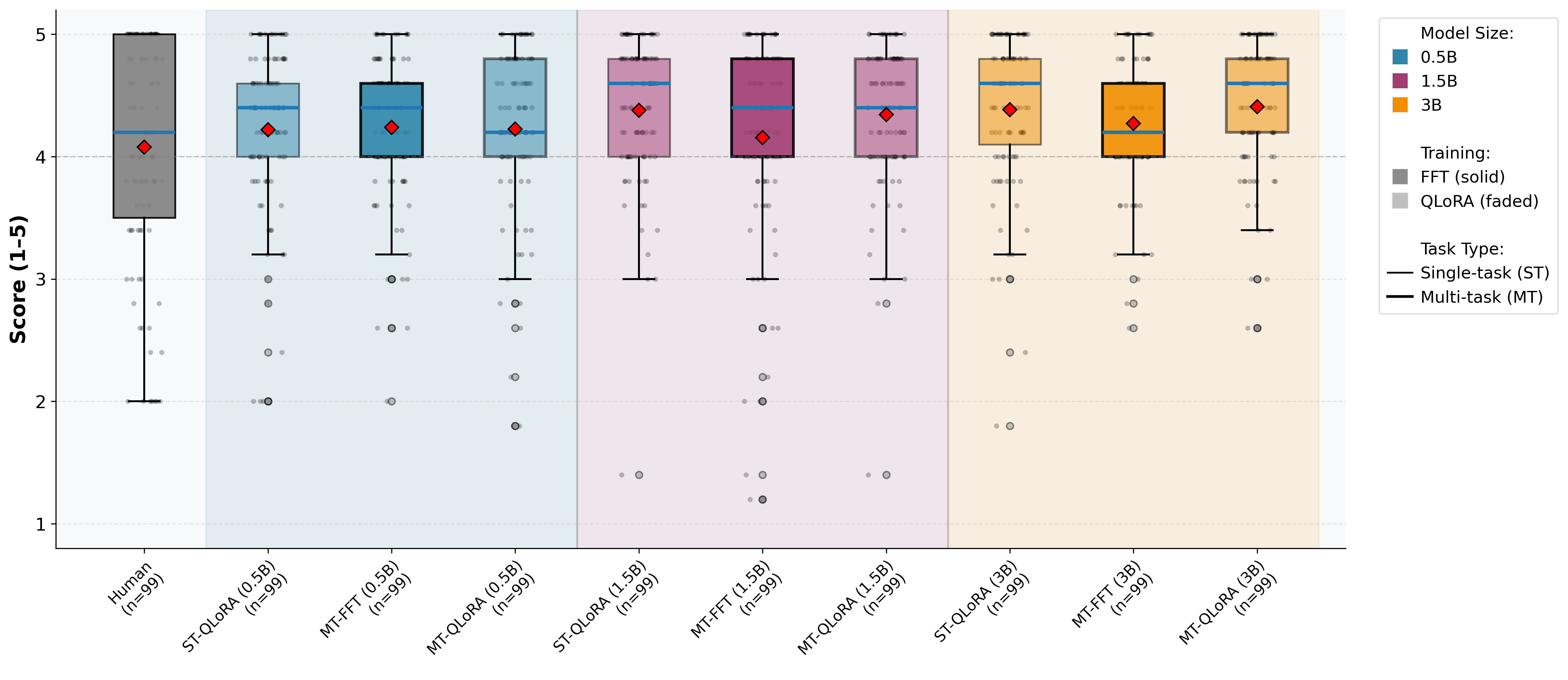
Figure 4: LLM-as-a-judge assessment: Content adequacy scores for Java across configurations.
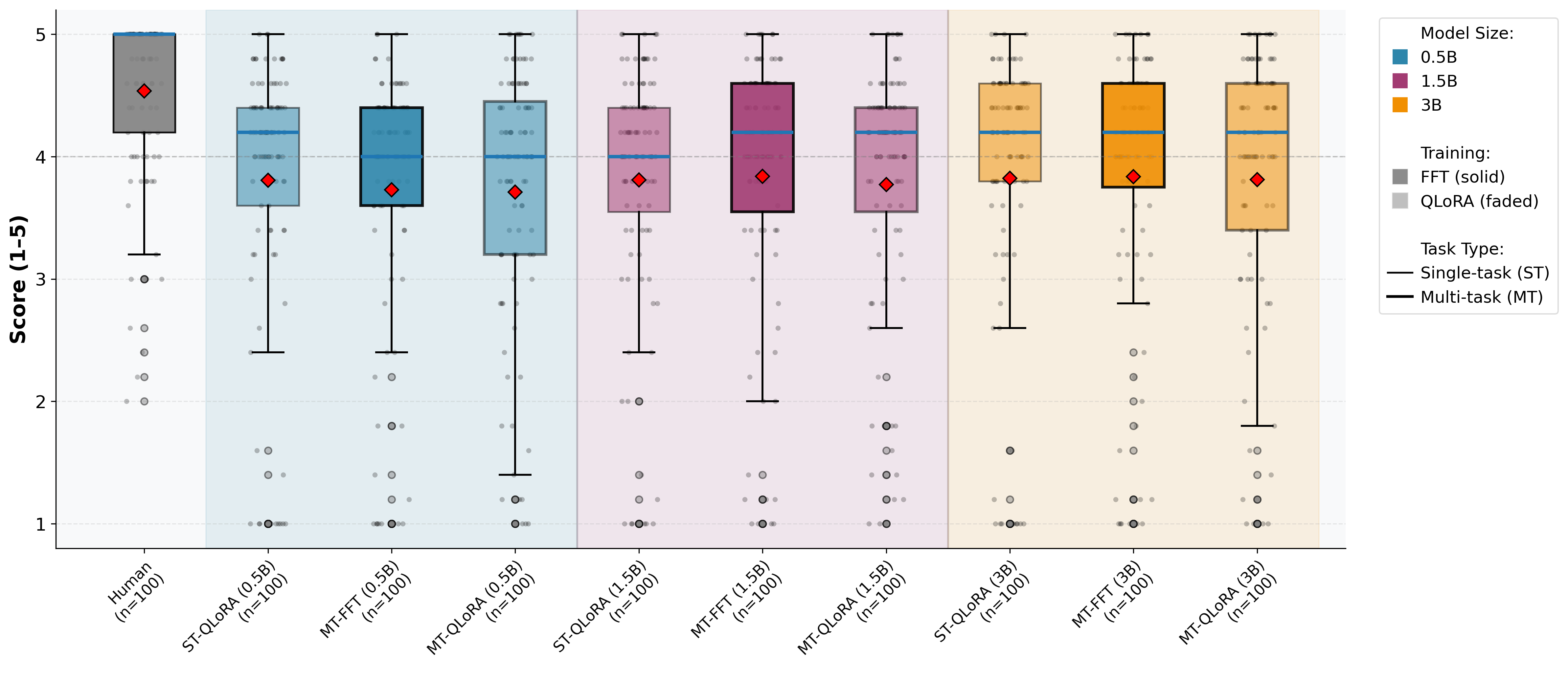
Figure 5: LLM-as-a-judge assessment: Content adequacy scores for Python across configurations.
Comparison to Multi-Task Full Fine-Tuning
Evaluating multi-task QLoRA against multi-task full fine-tuning, the results are particularly noteworthy. For code generation, QLoRA matches or exceeds full fine-tuning at almost all capacities and tasks; e.g., 21.05% vs. 17.37% (3B, Python). For Python summarization, QLoRA outperforms full tuning dramatically (BLEU: 29.90% vs. 22.54% at 3B), and code quality remains on par or improved. For code translation, full fine-tuning has an edge for Java→C#, while QLoRA narrows the gap or overtakes for C#→Java at larger scales. Overall, the parameter-efficient method attains correctness/quality parity (and, in some languages, superiority) with orders-of-magnitude lower resource consumption.
Qualitative Insights
Instance-level analysis on generated code demonstrates that MT-QLoRA models more reliably align implementation structure with task requirements, especially for multi-step behavioral specifications and complex, deeply nested translation cases. The unique success set for MT-QLoRA is larger in higher-complexity regions, suggesting enhanced cross-task generalization and transfer learning capacity that are not captured by pass/fail aggregate metrics alone.
Implications and Forward Directions
These results directly undermine the prevailing expectation that parameter-efficient and multi-task optimization necessarily degrade code quality or correctness. Notably, larger LCMs (3B) fine-tuned with QLoRA in the multi-task regime are able to maintain or exceed the standard of correctness and static quality of heavyweight full-model tuning for text-to-code, code-to-text, and cross-language translation within a unified deployment. Translation instability across directions highlights a frontier for dynamic task routing, adapter specialization, or capacity-aware fine-tuning.
The findings support the viability of highly efficient multi-task code LLMs on moderate compute, furthering accessibility for software engineering automation in constrained or edge environments. The comprehensive evaluation framework adopted—integrating execution and non-functional diagnostics—should inform best practices and future benchmarks. Future research should target mitigation of destructive interference in multi-task adapters, model selection for language/task pairs, and generalization to additional software artifacts and programming languages.
Conclusion
The paper presents a rigorous, multi-dimensional assessment of QLoRA for multi-task fine-tuning on leading code LLMs, establishing empirical evidence that parameter-efficient approaches do not entail necessary compromises in either functional or static quality. For multi-modal software engineering tasks in practical settings—where cross-task generalization, cost, and code quality are conjoint constraints—the presented results substantiate the adoption of advanced PEFT strategies as state of the art, particularly at the billion-parameter model scale and above.
Reference: "Parameter-Efficient Multi-Task Fine-Tuning in Code-Related Tasks" (2601.15094)