- The paper applies a hybrid approach combining neural Thompson Sampling with large-scale linear programming to enforce multi-stakeholder constraints in recommendations.
- It introduces Laplace-approximated Bayesian networks for efficient uncertainty quantification paired with constrained exploration.
- In both synthetic and production evaluations, BanditLP demonstrates superior cumulative rewards while maintaining strict constraint satisfaction.
BanditLP: Large-Scale Stochastic Optimization for Multi-Stakeholder Recommendations
The increasing complexity of large-scale recommender systems requires frameworks that can address the simultaneous needs of multiple stakeholders, often subject to intricate operational and fairness constraints. Existing contextual-bandit algorithms are generally optimized for a single scalar objective, neglecting business-critical constraints and stakeholder-specific requirements observed in domains such as e-commerce, content curation, and marketing. The challenge lies in the integration of expressive exploration (to avoid selection bias and support long-term gains) with rigorous enforcement of multi-level constraints at web scale.
BanditLP directly addresses this by coupling neural Thompson Sampling (TS) — for high-dimensional, uncertainty-aware modeling and exploration — with a large-scale linear program (LP) to perform constrained action selection per serving round. This architecture is specifically devised for multi-stakeholder recommendation, with a key focus on scalability and adaptability to domain-specific constraints.
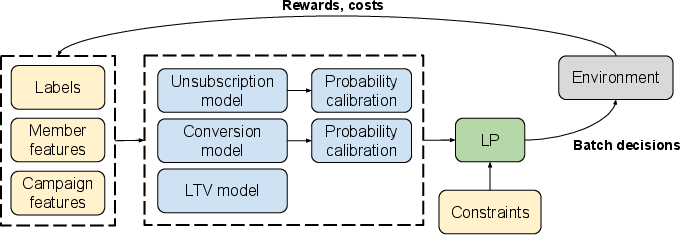
Figure 1: Overview of email marketing recommender system based on BanditLP at LinkedIn.
Methodological Contributions
BanditLP Architecture
BanditLP formalizes multi-stakeholder recommendation as a constrained stochastic optimization problem. For each round, it observes user and item contexts, applies neural TS to sample from the posterior predictive distributions of rewards and costs, and solves an LP to select actions that maximize the cumulative primary objective while satisfying platform-level, provider-level, and user-level constraints.
The LP is constructed as:
- Objective: Maximize total expected reward over all user-item pairs, where the reward is computed from Thompson-sampled posterior distributions estimated via neural networks.
- Constraints: Enforce multi-level feasibility conditions spanning global metrics (e.g., platform-wide budget or churn), group-level fairness or exposure requirements (e.g., provider balance), and per-user or per-item limitations (e.g., frequency caps, safety).
The system is application-agnostic, supporting arbitrary neural architectures for reward/cost estimation and a wide variety of constraint sets. The reward and constraint estimators are periodically updated using user feedback to iteratively refine the policy.
Scalable Bayesian Neural Exploration
BanditLP uses Laplace-approximated Bayesian neural networks for reward and cost prediction, enabling efficient uncertainty quantification necessary for TS-based exploration. To scale to production, the method employs sub-network approximations (typically the last layers of the model), minimizing the computational burden while maintaining sufficient epistemic uncertainty.
BanditLP also proposes practical techniques for tuning the exploration/exploitation trade-off when neural TS outputs are consumed by an LP. The "overlap-at-K" metric is introduced for direct monitoring and parameter tuning, ensuring that the realized degree of exploration aligns with operational requirements.
Production-Grade Linear Programming
The LP subroutine leverages DuaLip, a first-order-dual decomposition solver engineered for web-scale applications, capable of solving problems with up to billions of variables within strict latency budgets. By solving a regularized QP and exploiting strong duality, this approach guarantees solution feasibility when the number of providers is moderate, and is robust to the statistical noise introduced by TS.
Probability Calibration
Given the rarity of conversion/unsubscription events and the requirement for accurate calibrated probabilities in the LP, BanditLP applies off-the-shelf isotonic regression to the TS-derived outputs. The calibration step is carefully decoupled from the uncertainty generation to preserve exploration properties, as naive calibration approaches can lead to anti-exploration shrinkage.
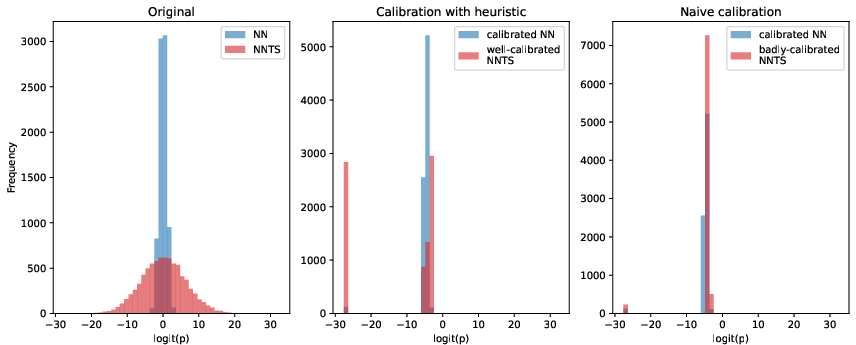
Figure 2: Calibration heuristic preserves exploration.
Experimental Evaluation
Offline Evaluation
BanditLP is evaluated on synthetic datasets and the Open Bandit Dataset (OBD), benchmarking against three baselines:
- NNTS: Neural TS without constraints.
- LinUCB-LP: Constrained LinUCB using an LP.
- NN-LP: Supervised neural predictor with LP selection, no exploration.
On both benchmarks, BanditLP achieves the best trade-off between cumulative reward and constraint satisfaction: it maintains constraint violations at (or below) zero and surpasses deterministic or linear baselines in final reward, illustrating the importance of expressiveness and exploration. Notably, when initialization induces selection bias, pure exploitation policies fail to escape local optima, while BanditLP continues to discover new high-performing actions.
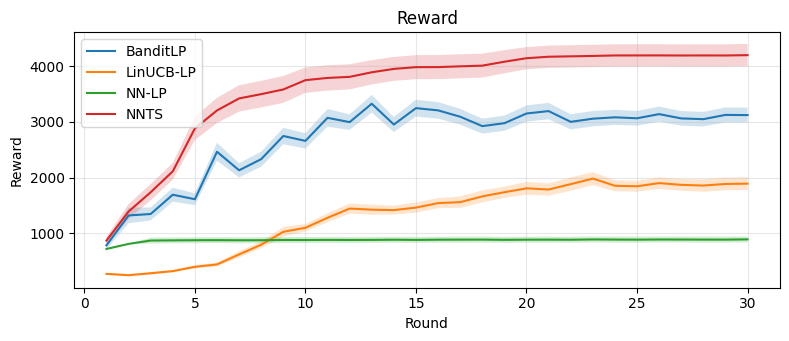
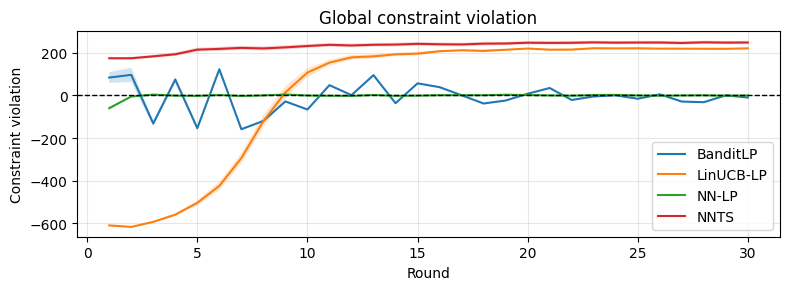
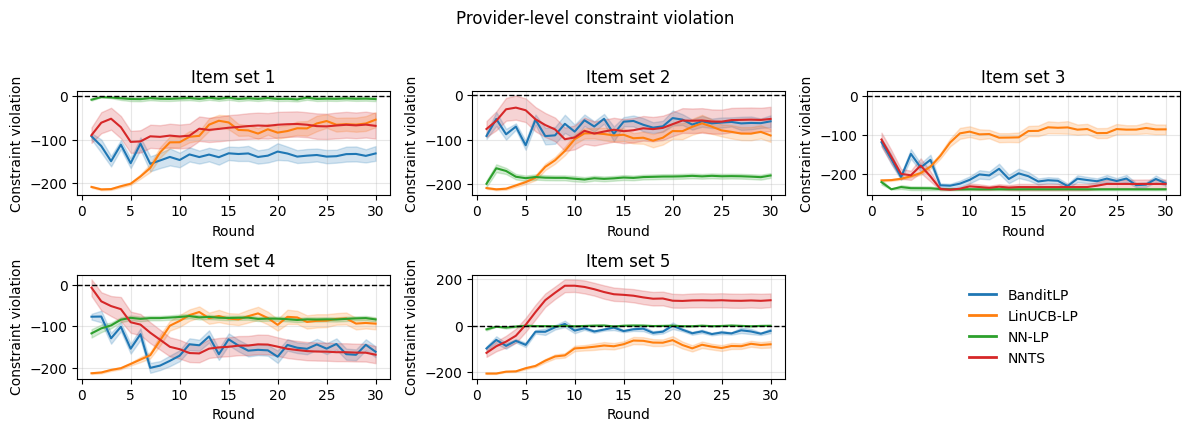
Figure 3: Synthetic experiments. Top: cumulative reward. Middle: global constraint violation. Bottom: provider-level constraint violations.
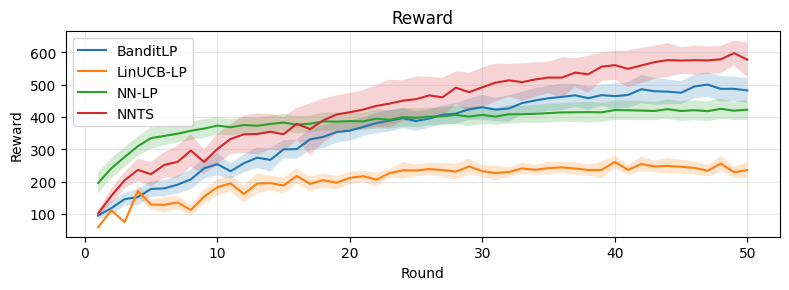
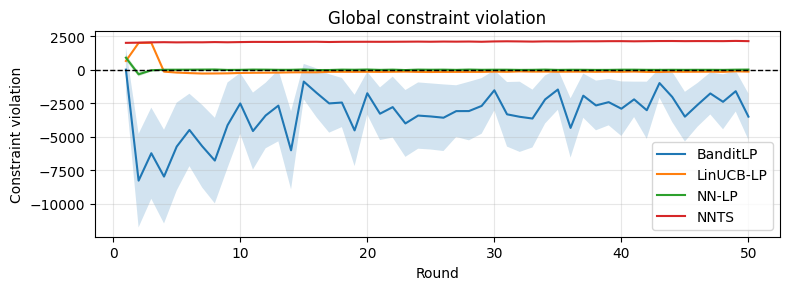
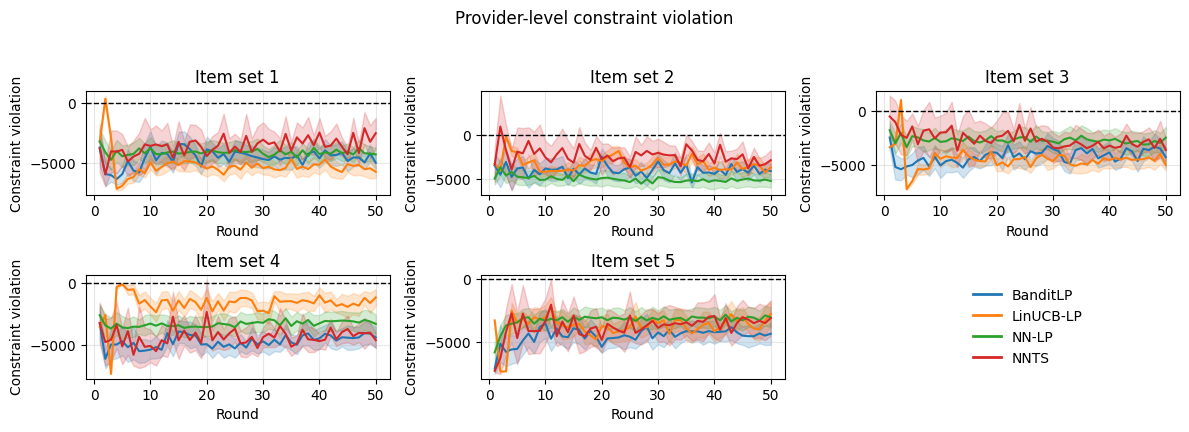
Figure 4: OBD experiments replicate the synthetic results; BanditLP maintains constraint feasibility and high reward.
A/B Testing in Production
Deployed within LinkedIn's email marketing platform, BanditLP was subjected to a rigorous A/B test against a deterministic LP-based recommender. Both systems shared base models, but only BanditLP introduced exploration via neural TS. The experiment population was stabilized to avoid effect dilution, and data-diverted training ensured no cross-contamination between treatment and control.
Numerical outcomes of the A/B test:
- Revenue: +3.08% improvement (95% CI: [0.17%, 5.99%])
- Unsubscription rate: -1.51% reduction (95% CI: [-2.25%, -0.72%])
- Conversion rate: Unchanged
Exploration-driven gains manifest principally in long-term business metrics, not in short-term conversion rates, confirming that exploration can yield statistically significant improvements within binding constraints.
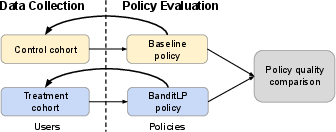
Figure 5: Data-diverted experimental setup prevents cross-policy data leakage during A/B testing.
Ablation Studies and Sensitivity Analysis
BanditLP includes ablation analyses to isolate the impacts of exploration and prediction quality on constraint satisfaction and allocation variance.
- Constraint Satisfaction: Across variations in the exploration temperature (τ), unsubscription rates remain tightly controlled, indicating the LP's constraints are robust against the injected stochasticity of TS.
- Allocation Stability: Allocation variance increases with τ, but this effect is amplified for high-quality models (where baseline allocations are stable absent exploration). This supports careful tuning of τ in operational deployments to balance exploration and allocation stability.
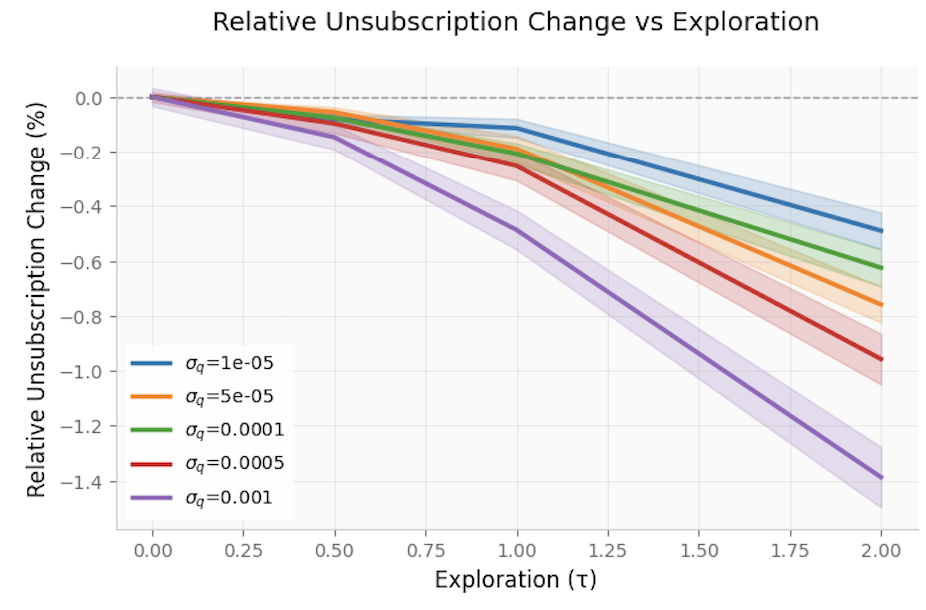
Figure 6: Relative unsubscription change is minimal as exploration increases, confirming robust constraint satisfaction.
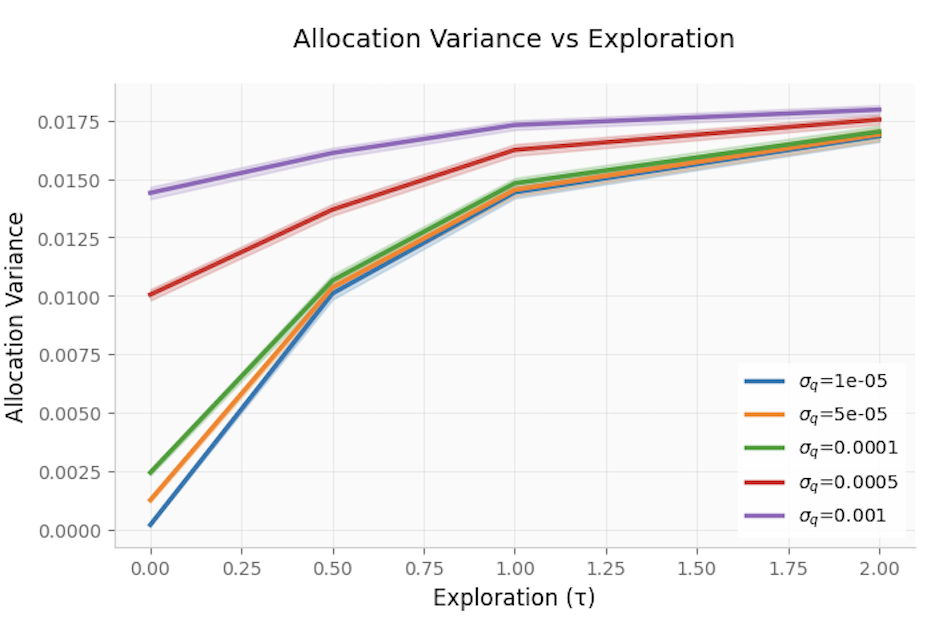
Figure 7: Allocation variance rises with exploration, especially under high-quality models.
Practical and Theoretical Implications
BanditLP demonstrates a scalable, modular architecture for blending deep model-based exploration with exact constraint enforcement at web scale. The separation of learning (expressive Bayesian neural modeling) and optimization (massive LP solving) enables deployment across a broad class of applications without rigid coupling of prediction and allocation logic. The framework is extensible to constraint families beyond those demonstrated, and can accommodate non-stationary or real-time learning regimes with further engineering of the LP/solver integration.
The demonstrated improvement in long-term business outcomes, alongside minimization of adverse user impacts (such as unsubscriptions), confirms that practical exploration is both feasible and advantageous even in settings with hard operational constraints. This runs contrary to conventional practice in production recommenders, which often eschew exploration out of concern for violating constraints.
From a theoretical standpoint, BanditLP's design opens the door for study of regret and feasibility trade-offs in neural bandit models with complex, multi-level constraint sets and modularized solve architectures.
Conclusion
BanditLP provides a robust, scalable solution for multi-stakeholder constrained decision-making in high-dimensional recommender systems. Through the combination of neural exploration and an LP-based optimizer, it guarantees constraint satisfaction while achieving strong long-term performance, validated in both simulated and large-scale production environments. Immediate future directions include enhanced automation of calibration/diagnostics at scale, extension to richer constraint structures (e.g., temporal, cascading, cross-marketing interactions), and real-time learning/deployment integration for continuous optimization.