- The paper introduces a unified, perception-driven RL framework using egocentric polar foothold priors for high-agility quadruped parkour.
- The system fuses depth and proprioceptive data through a CNN-GRU pipeline and employs a multi-critic architecture to enhance velocity tracking and maneuver execution.
- Results demonstrate state-of-the-art sim-to-real transfer with 100% success in real-world tests, highlighting the significance of PAS and geometry-driven control.
Introduction
The PUMA framework addresses the persistent challenge of robust, agile navigation in quadruped robots executing parkour-style maneuvers on discrete, complex terrains. In contrast to traditional hierarchical methods that decouple foothold planning and low-level control, PUMA proposes an end-to-end perception-driven architecture that integrates geometric reasoning through egocentric foothold priors, fusing onboard depth sensing and proprioceptive signals. The resultant system demonstrates state-of-the-art sim-to-real transfer, robust adaptive locomotion, and significant advances in exploiting terrain affordances for enhanced locomotive capability.
Methodology
Unified Single-Stage Learning Pipeline
PUMA employs a unified, single-stage RL pipeline based on an asymmetric actor-critic architecture. Both proprioceptive and exteroceptive (depth image) observations are combined and processed through a CNN, followed by temporal modeling with GRU layers and a multi-headed MLP to estimate egocentric foothold priors, base velocity, and latent terrain features. These predictions are concatenated with the current observation vector and forwarded to the policy network, which is optimized using PPO. All neural modules are trained concurrently, eschewing pre-training or hierarchy.
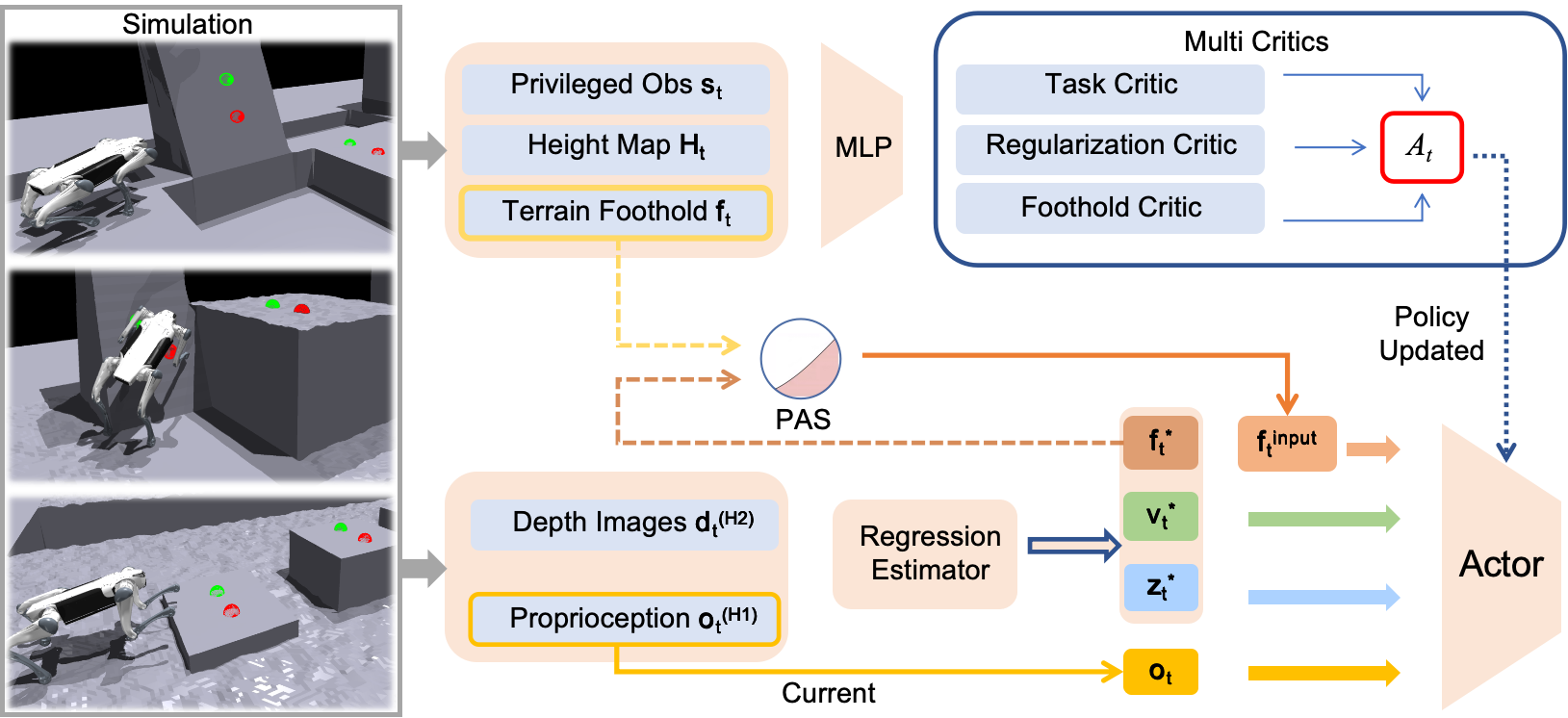
Figure 1: Overview of the PUMA training framework, detailing the fusion of proprioception and depth, egocentric foothold prior estimation, concatenated policy input, and multi-critic reward structure with PAS strategy for input annealing.
Central to PUMA is the egocentric polar foothold prior, which eschews explicit Cartesian target following in favor of relative distance and heading representations for the front feet. This design simplifies regression complexity and allows the policy to utilize terrain affordances, such as inclined walls, for high-agility maneuvers (e.g., wall-assisted jumps). The prior guides velocity tracking by representing footholds as a vector of four scalars: distances from each forefoot to the expected point and heading errors to the current and subsequent footholds.
Probability Annealing Selection (PAS)
To address instability in foothold regression early in training, PUMA introduces PAS: a curriculum-based annealing approach that probabilistically blends ground-truth and predicted priors as actor inputs. The probability of using the estimator's prediction gradually increases over training, ensuring stable convergence.
Multi-Critic Reinforcement Structure
A critical architectural innovation is PUMA's multi-critic (MuC) framework, in which separate value networks are optimized for distinct reward groups (task, foothold, and regularization). Each critic estimates the advantage for its designated reward, and the weighted, normalized advantages are summed for use in policy updates. Empirical analysis demonstrates that MuC is essential for balancing the competing objectives of velocity tracking and dynamic terrain exploitation, especially during phase transitions in complex maneuvers.
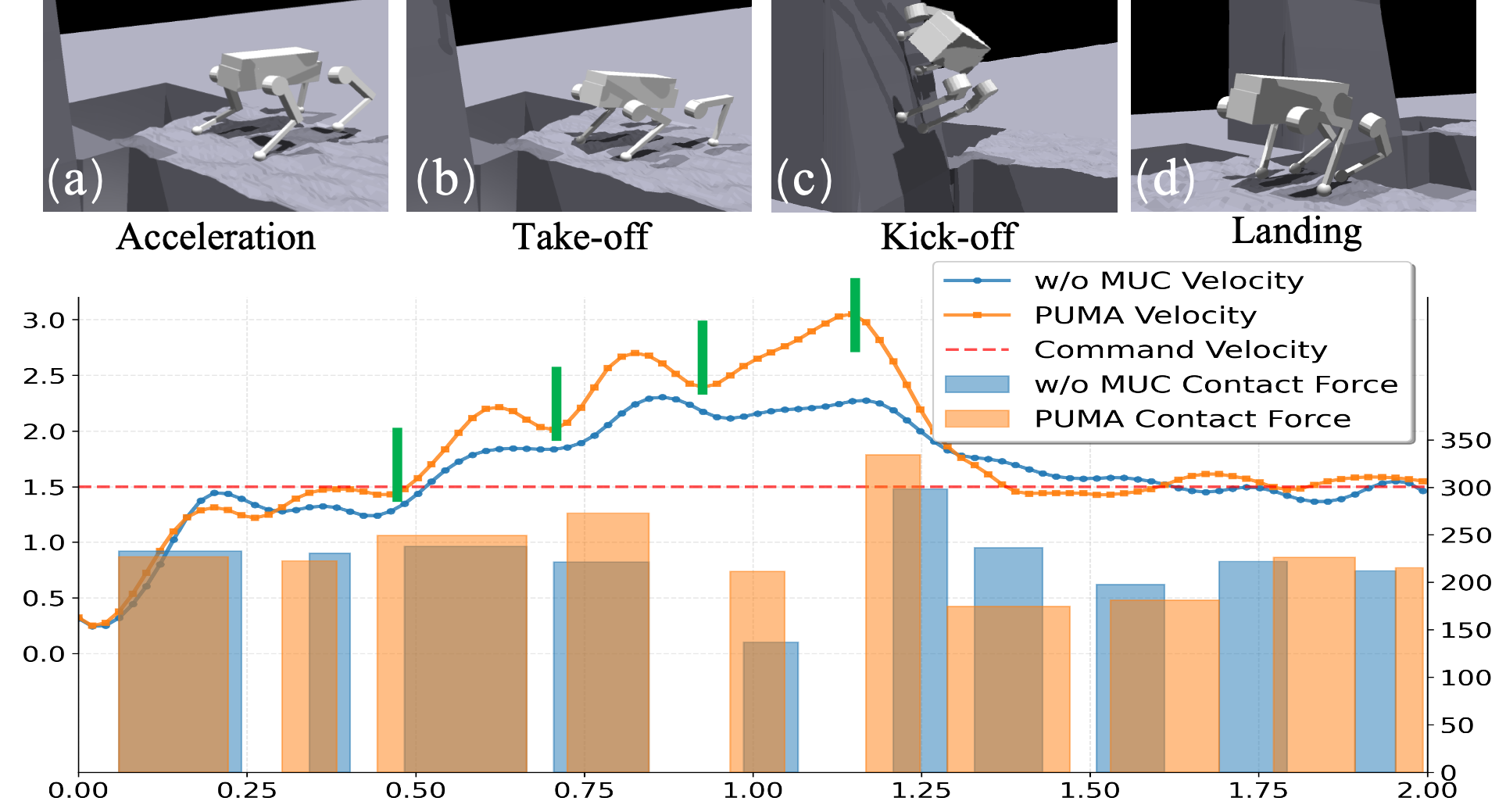
Figure 3: Temporal evolution of body velocity and total contact forces during a complete parkour jump; PUMA (orange) maintains superior velocity tracking and impulse generation compared to single-critic baselines.
Terrain Curriculum and Domain Randomization
PUMA’s training curriculum spans a range of procedurally generated terrains—wall-assisted gaps, surmounting platforms, and stepping stones—with difficulty ramping via gap widths, heights, and inclinations.
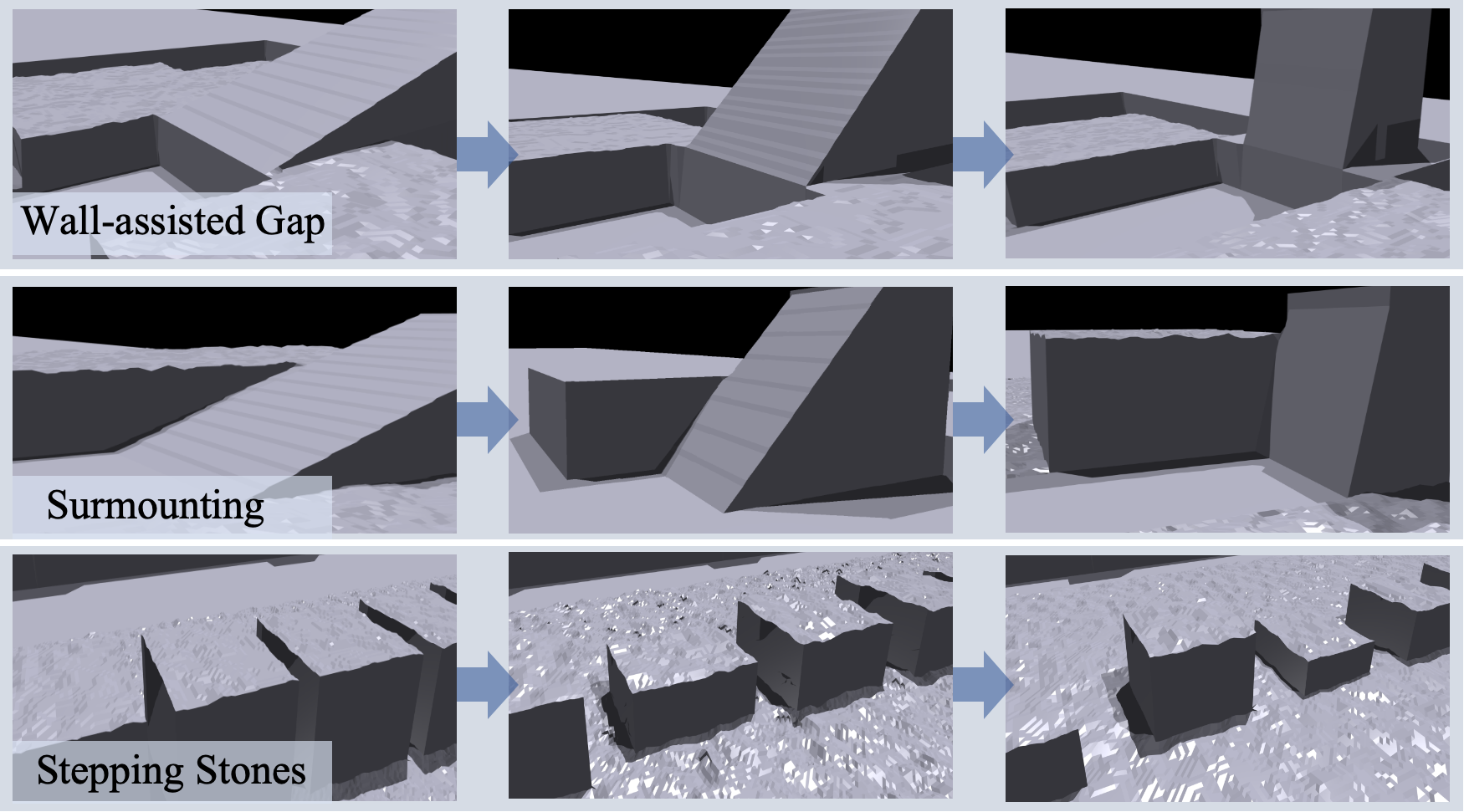
Figure 2: Terrain progression from left to right, with increasing roughness and inclination to systematically expand policy capability.
Heavy domain randomization in both sensor modalities and physical parameters, as well as asynchronous input delay modeling, underpins successful sim-to-real transfer.
Experimental Results
PUMA sets new benchmarks in both simulated and physical environments for success rate (SR) and traverse rate (TR) across multiple challenging terrain settings. Notably, the ablation studies reveal:
- Foothold prior is critical: Removing the prior or relative distance terms degrades SR on wall-assisted and surmounting terrains by over 30–80 percentage points.
- MuC is essential on complex terrain: Single-critic architectures (w/o MuC) exhibit catastrophic failure modes, primarily due to inadequate estimation of the foothold-related reward landscape.
- Polar prior superior to Cartesian: Egocentric polar priors outperform both explicit and implicit Cartesian foothold objectives in MSE regression accuracy and final maneuver success rates.
Training Efficiency and PAS
PAS enables stable and rapid convergence by avoiding premature reliance on an immature foothold estimator. Shortening or eliminating the annealing period induces policy collapse or slows training considerably.
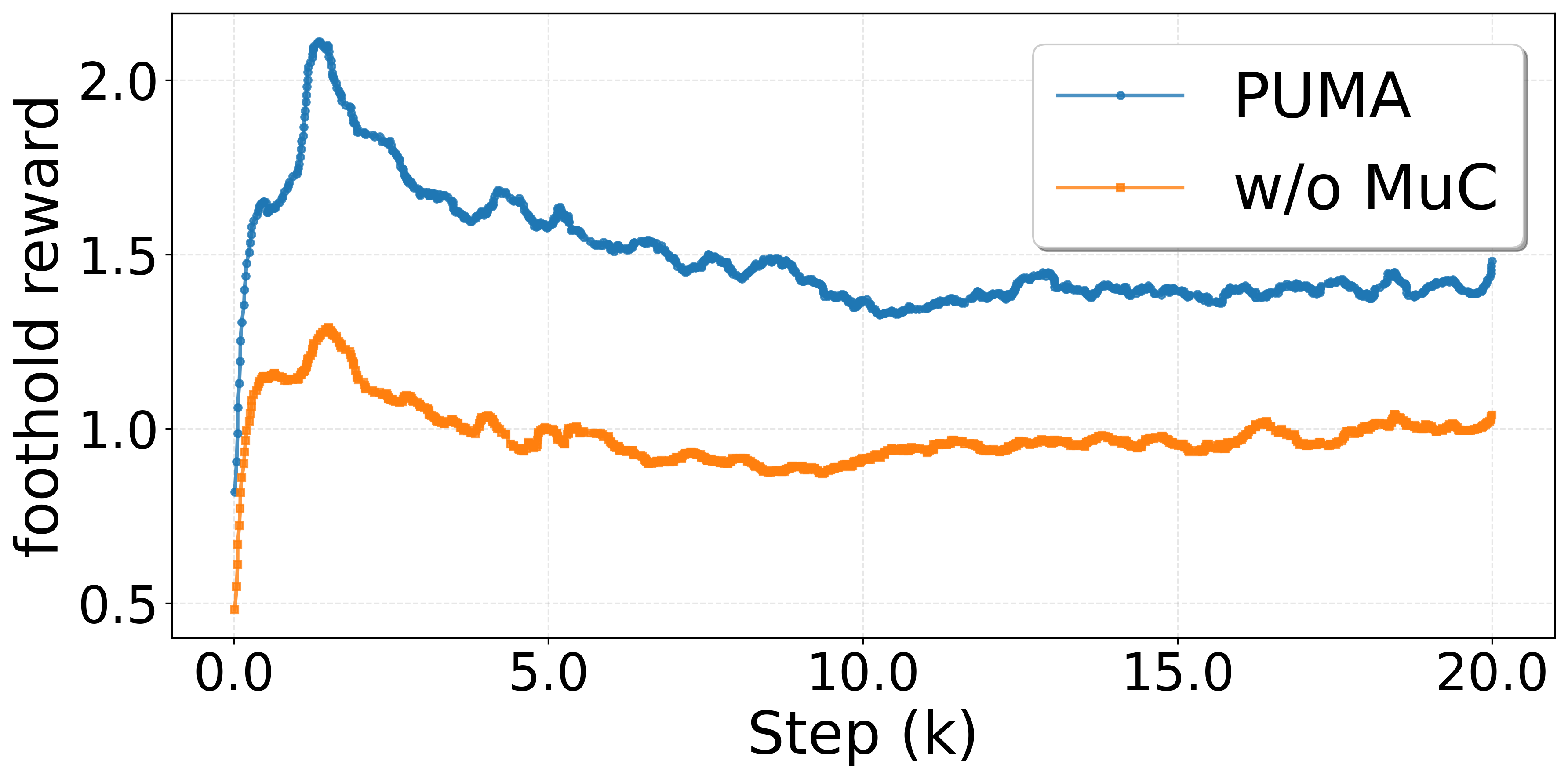
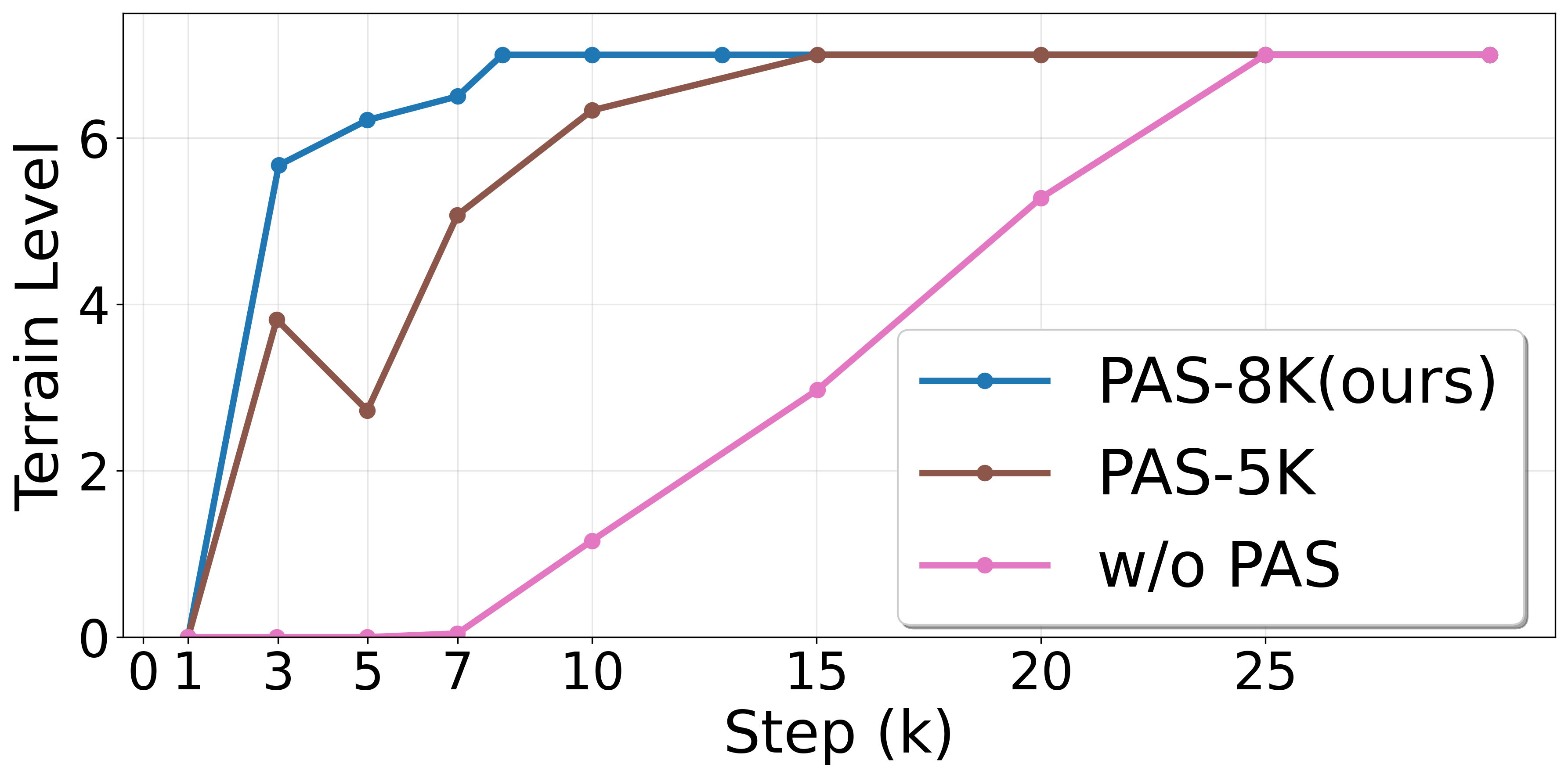
Figure 5: PUMA outperforms single-critic and alternative prior architectures in foothold reward accumulation (left), and PAS minimizes sample complexity to convergence (right).
Real-World Sim2Real Transfer
The PUMA policy, trained exclusively in simulation, achieved 100% success rate in real-world tests on a DeepRobotics Lite3 quadruped for both wall-assisted gaps up to 80°, surmounting tasks up to 0.7 m high, and stepping stone traversals. Baselines and ablation variants suffered from instability, missed contacts, or insufficient body posture adaptation.

Figure 4: Demonstrated parkour performance on discrete and highly inclined real-world terrains for wall-assisted gap, stepping stones, and platform surmounting tasks.
Analysis of Failure Cases
Failure is typically attributed to erroneous estimation of foothold priors under proprioceptive or perceptual noise, inadequate postural adaptation (especially with yaw-only or Cartesian prior variants), and inability to coordinate timing and force during contact-rich transitions.

Figure 6: Failure modes include roll misadaptation, misorientation, erroneous foothold estimation, and low-force contacts impeding dynamic maneuvers.
Theoretical and Practical Implications
The proposed egocentric polar foothold prior constitutes a minimalist, geometry-driven representation that supports robust generalization, improves regression tractability, and decouples spatial aspects of locomotion. The single-stage, end-to-end design eliminates brittle dependencies on explicit plan following, facilitating real-time reactivity and improved exploration in RL. Multi-critic RL architectures demonstrate clear superiority for multi-objective, contact-rich robotic tasks. The PAS curriculum is validated as a critical component for stabilizing simultaneous estimator and policy learning.
Practically, PUMA considerably reduces pipeline complexity, sensor fidelity requirements, and sim-to-real transfer barriers for dynamic agile locomotion on quadrupedal robots. These advances are directly applicable to field robotics, search-and-rescue, and infrastructure inspection domains.
Future Directions
While PUMA demonstrates robust geometric reasoning, it does not explicitly incorporate semantic terrain understanding, material adaptation, or dynamic environment perception. Integrating learned semantic priors, visual affordance predictors, and temporal scene understanding remains a pertinent direction. Furthermore, extending the approach to adaptive gaits, deformable terrain contacts, multi-agent coordination, and closed-loop visual feedback for hazard anticipation could further amplify real-world applicability.
Conclusion
PUMA introduces a compact, perception-driven paradigm for encoding motion guidance via egocentric foothold priors within a unified, end-to-end learning framework, empirically validated on demanding parkour benchmarks and sim-to-real transfer tasks. The work substantiates the necessity of reward-space decomposition via multi-critic RL and curriculum-based estimator input blending. PUMA sets a new reference point for future research on perception-guided, robust and adaptive legged locomotion (2601.15995).