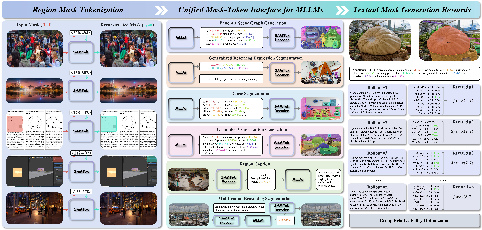
SAMTok: Representing Any Mask with Two Words
Abstract: Pixel-wise capabilities are essential for building interactive intelligent systems. However, pixel-wise multi-modal LLMs (MLLMs) remain difficult to scale due to complex region-level encoders, specialized segmentation decoders, and incompatible training objectives. To address these challenges, we present SAMTok, a discrete mask tokenizer that converts any region mask into two special tokens and reconstructs the mask using these tokens with high fidelity. By treating masks as new language tokens, SAMTok enables base MLLMs (such as the QwenVL series) to learn pixel-wise capabilities through standard next-token prediction and simple reinforcement learning, without architectural modifications and specialized loss design. SAMTok builds on SAM2 and is trained on 209M diverse masks using a mask encoder and residual vector quantizer to produce discrete, compact, and information-rich tokens. With 5M SAMTok-formatted mask understanding and generation data samples, QwenVL-SAMTok attains state-of-the-art or comparable results on region captioning, region VQA, grounded conversation, referring segmentation, scene graph parsing, and multi-round interactive segmentation. We further introduce a textual answer-matching reward that enables efficient reinforcement learning for mask generation, delivering substantial improvements on GRES and GCG benchmarks. Our results demonstrate a scalable and straightforward paradigm for equipping MLLMs with strong pixel-wise capabilities. Our code and models are available.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for AI models to understand and draw precise shapes on images, called masks. Think of a “mask” like using a highlighter to color a specific object or area in a photo. The big idea is a tool named SAMTok that turns any mask into just two special “words” (tokens) that a LLM can read and write—just like regular text. This makes it much easier to teach big vision-LLMs to handle pixel-level tasks (like outlining an object) without changing their design.
What questions were they trying to answer?
The authors wanted to solve four simple but important problems:
- How can a model both read masks (as inputs) and create masks (as outputs) using one simple, unified method?
- How can we avoid complicated extra parts (special decoders and losses) when adding mask skills to big language+vision models?
- How can we train these models using the same easy “predict the next word” method used for text?
- How can we use reinforcement learning (giving points for good answers) for mask-making without messy, slow extra steps?
How did they do it? (Methods in plain language)
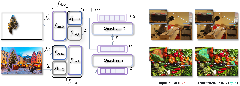
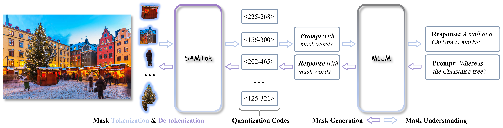
The team built SAMTok, a “mask tokenizer.” A tokenizer is like a zipper that compresses something big into a short code and can unzip it back later.
- What SAMTok does:
- It takes a mask (the highlighted region in an image) and turns it into two special tokens—like giving the region a two-word nickname.
- It can also take those two tokens and rebuild the original mask very accurately.
- How it works (simple analogy):
- Imagine a very big dictionary of “shape pieces.” SAMTok looks at the mask and picks the best first piece from the dictionary that matches the shape. Then it sees what details are still missing and picks a second piece that fixes the leftover differences. These two pieces together become the two tokens. Later, those two tokens can be “decoded” to get the mask back.
- This “two-step pick” is called residual vector quantization. “Residual” just means “what’s left to fix after the first guess.”
- What it’s built on:
- It starts from a strong segmentation model (SAM2), then adds:
- A mask encoder (turns the mask into a compact description),
- A vector quantizer (chooses two dictionary entries to represent that description),
- A decoder (turns the two tokens back into a full mask).
- How they trained it:
- They trained SAMTok on a huge set of 209 million masks from many kinds of images, so it can handle objects, parts, and scenes.
- Then they trained a vision-LLM (like QwenVL) on about 5 million examples that mix images, text, and these two-token masks. Because masks are now “just text tokens,” the model can learn everything using the normal “predict the next token” training—no special architecture changes or fancy losses.
How SAMTok plugs into a language+vision model
- For understanding masks (mask-in):
- If a task gives a region as input (for example, “Describe the highlighted dog”), SAMTok converts that region into two mask tokens, and the model reads them just like words.
- For generating masks (mask-out):
- If a task asks the model to find something (for example, “Find the red backpack”), the model simply outputs two mask tokens. SAMTok then turns those two tokens back into the actual drawn mask on the image.
Reinforcement learning made simple
- Normally, improving mask output with reinforcement learning (RL) is hard, because you must compare two real masks pixel by pixel.
- With SAMTok, the model’s mask is expressed as two tokens (text!). So the reward can be text-based: if the model’s mask tokens match the correct tokens, it gets points. This is fast, simple, and doesn’t need extra tools.
- They used a popular RL method called GRPO and a straightforward “answer-matching” reward.
What did they find, and why does it matter?
Across many tasks, the SAMTok-based models reached state-of-the-art or very strong results—often with fewer parameters and simpler training. Examples include:
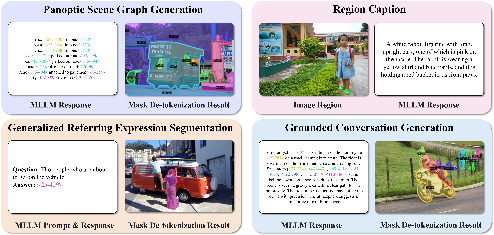
- Region captioning and region-based Q&A: The model accurately describes or answers questions about specific areas of images.
- Referring segmentation: Given a phrase like “the small mug on the left,” the model finds and outlines it precisely.
- Grounded conversation: The model can talk about a scene and mark the moments it mentions by drawing masks as it speaks.
- Interactive segmentation: Over multiple steps, the model keeps track of earlier choices and refines masks—useful for multi-turn editing or instructions.
Reinforcement learning further boosted mask quality significantly on key benchmarks:
- On a general referring segmentation task (GRES), the model’s accuracy rose notably (for example, gains of around +6–9% on one key metric).
- On a grounded conversation task (GCG), it improved at correctly marking the relevant regions (+4–7% on mask metrics). These are sizable jumps for already strong systems.
Why this matters:
- Masks as “two words” is both fast and precise. Previous methods often needed dozens or hundreds of tokens or special, complex modules.
- Training becomes simple and scalable: just “predict the next token,” like normal language training, plus easy RL.
- The same model can read and write masks using one unified interface—no separate pipelines.
What’s the bigger impact?
This work shows a practical path to give general-purpose AI models sharp, pixel-level skills without extra heavy machinery. That means:
- Easier to build interactive tools that can point to, describe, and edit exact parts of an image (think smart photo editors, educational apps, or assistants that can highlight instructions right on a picture).
- Better foundations for vision tasks that need precision, such as understanding diagrams, UI screenshots, or complex scenes.
- Simpler and cheaper training and improvement with reinforcement learning, since everything stays in “text form.”
In short, turning masks into two tokens makes pixel-level understanding feel like language—unlocking powerful, precise vision abilities with the simplicity and scale of text-based learning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions that the paper leaves open, aimed to guide future research:
- Quantitative mask reconstruction fidelity is not reported for SAMTok itself; systematically benchmark reconstruction IoU, boundary F-score, thin-structure accuracy, and small-object recall across diverse datasets to validate the “two tokens for any mask” claim.
- Codebook size, dimensionality, and utilization are unspecified; study how codebook size, embedding dimensionality, and residual quantization depth affect reconstruction error, token efficiency, dead-code rates, code utilization entropy, and training stability.
- Fixed two-stage residual quantization with a shared codebook is assumed; evaluate separate codebooks per stage, more than two residual steps, and variable-length tokenization (adaptive number of tokens per mask) for complex shapes or high-detail regions.
- Theoretical justification for “representing any mask with two words” is absent; derive compression–distortion trade-offs and establish bounds on representable mask complexity under two-token constraints.
- SAMTok tokens are image-conditional (produced from image + mask embeddings); analyze token collision rates across images (i.e., same token pair representing different regions), and quantify how image content affects token stability and portability.
- No explicit analysis of failure modes; conduct error analysis for overlapping instances, nested holes, highly concave shapes, occlusions, motion blur, and fine-grained parts to identify where SAMTok degrades.
- Robustness to domain shifts is underexplored; test on medical imaging, remote sensing, synthetic scenes, cartoons, and extreme UI layouts to quantify generalization beyond datasets used for training.
- Video segmentation is only evaluated in single-frame captioning; extend SAMTok to spatiotemporal masks (tubelets) and assess temporal consistency, drift, and memory over multi-frame sequences.
- The RL reward uses textual answer matching of mask words, not geometric quality; investigate combined rewards (e.g., token match + IoU/geometry), reward shaping, and fast differentiable proxies to avoid “token gaming” and align improvements with pixel-level accuracy.
- RL applicability may be limited to settings with ground-truth mask words embedded in answers; devise strategies to compute rewards when ground truth is only provided as pixel masks or free-form text (e.g., automatic token grounding, soft matching).
- Caption metrics decreased after mask-centric RL; develop multi-objective RL that balances language quality and mask accuracy, including Pareto-front analysis and explicit trade-off controls.
- GRPO hyperparameters, group size, and sampling strategies are not ablated; characterize sensitivity to RL settings, stability across long sequences with many masks, and credit assignment for interleaved text–mask outputs.
- Sequence length and throughput are not reported; measure inference/training latency, memory, and throughput under scenarios with many regions per image (e.g., panoptic/PSG with tens to hundreds of masks), and optimize batching and caching.
- Comparative cost analysis is missing; quantify end-to-end compute/inference costs versus polygon/RLE/token-per-pixel approaches and continuous-embedding segmentation heads, including speed–accuracy trade-offs.
- Dependence on SAM2 is strong; assess portability to other decoders/backbones (e.g., Mask2Former, HQ-SAM), and study sensitivity to SAM version, image resolution, and prompt-encoder variants.
- Generalizability across base MLLMs is not evaluated; replicate results on multiple architectures (e.g., LLaVA, InternVL, CogVLM, Gemini-like) to verify that no-architecture-modification scaling holds broadly.
- Training data scale is very large (209M masks, ~5M conversations); perform data-efficiency ablations to estimate minimal datasets for acceptable performance, and examine curriculum strategies for low-resource training.
- Vocabulary integration of thousands of special mask tokens may interfere with language modeling; analyze effects on perplexity, token collisions with BPE, multilingual behavior, and prompt robustness (e.g., accidental triggering, token leakage).
- Token frequency skew and long-tail coverage are not discussed; measure distribution of mask token usage, ensure rare codes are trained adequately, and explore techniques (e.g., code rebalancing, temperature-based sampling) to prevent codebook underutilization.
- Handling compositional relations among multiple masks is not deeply analyzed; formalize how mask words represent part–whole hierarchies, spatial relations, and cross-mask constraints, and investigate structured decoding (e.g., graph outputs).
- Grounding comparisons are limited; perform controlled comparisons versus native box/point interfaces across accuracy and latency, and explore hybrid interfaces (e.g., mask tokens + boxes) for robustness.
- Resolution robustness is unaddressed; test how resizing/cropping affects tokenization and reconstruction (e.g., scale invariance, aspect ratio changes) and whether tokens remain consistent across preprocessing pipelines.
- Security and safety considerations are unexamined; study adversarial prompts or token injection attacks that could cause mislocalization, and develop safeguards for interactive systems that accept user-provided mask tokens.
- Open-vocabulary segmentation semantics are implicit; assess whether SAMTok tokens carry any semantic information or are purely geometric, and explore joint semantic–geometric tokenization for tasks requiring class-aware masks.
- Reproducibility details are sparse in the main text; provide explicit hyperparameters for codebook training, optimizer settings, GRPO configuration, and public ablations to ensure independent verification.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s models and tooling, leveraging SAMTok’s two-token mask interface, proven SOTA/competitive results on GCG, GRES, RefCOCO/+/g, MR-RefCOCO/+/g, DLC/MDVP, and zero-shot generalization on GroundingSuite.
- Interactive image editing via natural language (Software, Creative tools, Advertising)
- What: Select, edit, erase, or stylize precise regions by speaking or typing (“remove the street sign,” “brighten only the foreground subject”). Multi-round segmentation supports iterative refinement.
- Tools/products/workflows: Plugins for Photoshop, Figma, Canva; “region-aware” chat editing; batch edits driven by prompts; pipeline: MLLM parses intent → outputs two mask tokens → SAMTok decodes mask → editor applies operation.
- Assumptions/dependencies: Access to SAMTok encoder/decoder and a base MLLM with mask tokens added; GPU latency acceptable for interactive use; permissions for integrating Qwen/SAM2 licenses.
- Region-aware accessibility for images and documents (Accessibility tech, Education, Public sector)
- What: Precisely describe or summarize selected regions (captions, VQA) to assist low-vision users; highlight UI components or chart panels.
- Tools/products/workflows: Screen-reader companion that accepts “describe the lower-left panel;” document-reading assistants using MDVP-style region captioning; region-by-region tutoring on diagrams.
- Assumptions/dependencies: Robustness across document layouts and screenshots (supported by strong MDVP zero-shot); privacy-safe processing for sensitive documents.
- E-commerce product guidance and grounded shopping assistants (Retail, Marketing)
- What: Grounded conversation generation that links phrases to exact product regions (“compare the stitching here vs. the collar”), enabling visual Q&A, try-before-you-buy imagery, and guided browsing.
- Tools/products/workflows: PDP chat widgets that highlight masks as users ask questions; automatic product-region tagging and enrichment for search; pipeline: caption + masks (GCG) to connect text with pixel regions.
- Assumptions/dependencies: Catalog/domain tuning for specific product photography; UI integration to overlay masks; governance for claims (avoid hallucinated attributes).
- Region-level content moderation and compliance editing (Media platforms, Policy/compliance, Legal)
- What: Detect and blur/redact sensitive regions (faces, license plates, medical info, graphic content) with pixel-level precision; enforce platform policies consistently.
- Tools/products/workflows: Moderation pipelines that route “mask tokens” to blur/obfuscation operators; audit trails linking decisions to mask IDs for explainability.
- Assumptions/dependencies: Policy definitions → region prompts; thorough validation to minimize false positives/negatives; secure data handling.
- Document redaction and PII removal (Enterprise, Legal, Government)
- What: Identify and mask PII or confidential fields (names, addresses, signatures, seals) in scans/screenshots using text-to-mask and mask-to-text.
- Tools/products/workflows: “Redact by instruction” services; QA dashboards showing predicted masks and extracted text; integration with eDiscovery and DLP tools.
- Assumptions/dependencies: OCR integration where needed; human-in-the-loop for critical documents; compliance logging.
- Diagram and panel-level tutoring (Education, Publishing)
- What: Region VQA/captioning on complex figures, panels, and screenshots (“explain the flow in the highlighted subpanel”).
- Tools/products/workflows: Interactive textbook viewers; lab/engineering diagram assistants; exam feedback that grounds answers to regions.
- Assumptions/dependencies: Domain vocabulary coverage; content licensing; LMS integration.
- Robotics picking and bin operations in structured settings (Robotics, Logistics)
- What: Referential segmentation to localize items/parts (“pick the blue bin on the left”), with multi-round refinement when ambiguity arises.
- Tools/products/workflows: Vision module that outputs masks, then tool planners use masks for grasp planning; closed-loop correction via dialog.
- Assumptions/dependencies: Calibration to robot camera stack; depth or pose estimation fused downstream; domain fine-tuning for factory/warehouse visuals.
- Segmentation annotation acceleration (ML tooling, Data labeling)
- What: Multi-round interactive segmentation to speed up dataset creation and correction; “instruct-and-click” workflows.
- Tools/products/workflows: Labeling UIs where annotators issue short prompts and refine masks across rounds; automatic quality checks via textual reward proxies.
- Assumptions/dependencies: Label platform integration; class ontology mapping; annotator training.
- UI automation and RPA with pixel-level grounding (Enterprise software, QA)
- What: Identify and segment UI elements (buttons, fields) robustly, replacing brittle coordinate-based scripts; refer to elements by “names” anchored to masks.
- Tools/products/workflows: “Two-token selectors” as stable handles inside automation scripts; visual diff and regression testing that highlights precise deltas.
- Assumptions/dependencies: Screenshots or live capture; per-application tuning for custom components; security for sensitive UIs.
- Scene-graph-aided media indexing and search (Media asset management, DAM)
- What: Index object relations with masks (“person holding guitar,” “cup on saucer”) for precise retrieval and clip trimming.
- Tools/products/workflows: PSG-powered indexing that stores relation triples + mask IDs; search UI that previews highlighted matches.
- Assumptions/dependencies: Efficient storage of mask metadata; batch processing pipelines; IP/licensing for large media libraries.
- Smartphone photo assistant for casual edits (Consumer apps)
- What: Voice/text commands for quick pixel-accurate edits (“blur the license plate,” “highlight the sunset areas”).
- Tools/products/workflows: On-device or edge-assisted mobile workflows; paired with generative fill/inpainting tools.
- Assumptions/dependencies: Edge inference or cloud offload; latency and battery constraints; simple UX for mask visualization.
Long-Term Applications
These opportunities likely require further research, domain adaptation, scaling, or systems integration beyond the current model’s training scope or latency profile.
- Medical imaging assistance (Healthcare)
- What: Region-referred findings (“segment the lesion specified in the report”), part-level anatomy tutoring, and guided measurements.
- Tools/products/workflows: PACS-integrated assistants; reporting support that links text to masks.
- Assumptions/dependencies: Domain-specific training, clinical validation, regulatory approval (FDA/CE), strict privacy and bias auditing.
- Autonomous driving and ADAS perception support (Automotive, Mobility)
- What: Language-driven region localization for rare classes or temporary hazards; human-in-the-loop triage of edge cases; accelerated annotation for road scenes.
- Tools/products/workflows: Ops tools for triaging and labeling long-tail events; data engines that auto-suggest region masks for review.
- Assumptions/dependencies: Real-time constraints; safety-critical verification; specialized datasets (night, weather, LiDAR fusion).
- Temporal and video-level interactive segmentation (Media, Sports analytics, Robotics)
- What: Propagate referred masks through time; “track what I highlighted while the camera pans.”
- Tools/products/workflows: Video editors with language-driven trackers; sports play breakdown with grounded overlays.
- Assumptions/dependencies: Temporal modeling extensions; efficient inference; motion/occlusion robustness.
- Open-world household and industrial manipulation (Consumer robotics, Manufacturing)
- What: Free-form language → pixel masks → grasp/placement on novel objects/parts with multi-step reasoning (“unscrew the panel covering the fan”).
- Tools/products/workflows: Task planners that interleave reasoning and mask generation; safety checks using verified region masks.
- Assumptions/dependencies: Task-level RL/IL, compliance with safety standards, multi-sensor fusion.
- Remote sensing and precision agriculture (Energy, Agriculture, Climate)
- What: Region-referred segmentation of fields, rooftops, flooding extents, crop stress areas; dialog-based QA over satellite imagery.
- Tools/products/workflows: GIS tools that accept prompts and return georeferenced masks; monitoring dashboards.
- Assumptions/dependencies: Domain adaptation to aerial/satellite spectra and scales; georegistration; evaluation benchmarks.
- Industrial inspection and defect localization (Manufacturing, Quality assurance)
- What: Pixel-accurate defect masks specified by textual SOPs (“highlight scratches longer than 2 cm”); explainable QA through grounded outputs.
- Tools/products/workflows: Line-side vision systems with region grounding; audit trails with mask IDs.
- Assumptions/dependencies: High-resolution, domain-specific training; measurement calibration; throughput constraints.
- Real-time AR/VR spatial interfaces (XR, Gaming, Enterprise training)
- What: Natural-language overlays and selections (“highlight doorways and safety signs”), anchored to precise masks in live scenes.
- Tools/products/workflows: On-device mask-token inference feeding AR renderers; collaborative multi-user annotations.
- Assumptions/dependencies: Latency-optimized models, hardware acceleration, robust tracking.
- Privacy-preserving, on-device pixel-wise assistants (Consumer, Enterprise)
- What: All-local redaction/editing of sensitive content in photos/docs; region-aware suggestions without cloud transmission.
- Tools/products/workflows: Distilled/quantized SAMTok+MLLM stacks; secure enclave deployment.
- Assumptions/dependencies: Model compression, mobile NN accelerators, careful energy management.
- Policy enforcement and auditing for visual decisions (Government, Compliance)
- What: Standardized, auditable region-level decisions (what was redacted, why); fairness and bias auditing at the pixel level.
- Tools/products/workflows: “Mask-as-evidence” logs; dashboards linking policies → prompts → masks → outcomes.
- Assumptions/dependencies: Governance frameworks, dataset transparency, reproducibility guarantees.
- Multimodal software agents with pixel-level actionability (Software engineering, DevTools)
- What: Agents that reason, act, and edit UIs or documents using mask tokens as robust references; integrate with code and APIs.
- Tools/products/workflows: Agent frameworks where the planner calls “segment-by-text,” then invokes downstream tools on the mask region.
- Assumptions/dependencies: Tool-use orchestration, safety/guardrails, cross-application generalization.
- STEM education and lab assistance (Education, Research tools)
- What: Region-grounded guidance for microscopy, CAD, circuit diagrams, and lab apparatus; “explain the highlighted subcircuit.”
- Tools/products/workflows: Lab notebook add-ons; interactive problem sets with region-aware hints.
- Assumptions/dependencies: Domain vocabulary and symbol training; integration with specialized viewers.
Cross-cutting assumptions and dependencies
- Base model and tokenizer integration: The host MLLM must add SAMTok’s special mask tokens and have access to the SAMTok codebook and SAM2-based encoder/decoder.
- Data and domain coverage: Out-of-domain or specialized imagery (medical, aerial, industrial) will require domain-specific fine-tuning and rigorous validation.
- Performance and latency: Running an MLLM plus SAM2-derived components can be GPU-intensive; real-time or on-device scenarios need model compression or edge/cloud hybrids.
- RL and supervision signals: The textual reward paradigm assumes availability of ground-truth mask-token answers during training; in production, surrogate QA signals or human feedback may be needed.
- Licensing and compliance: Ensure licenses for SAM2, Qwen models, datasets, and any redistribution comply with application requirements; implement privacy and security controls for sensitive content.
- Safety and accountability: For high-stakes domains (healthcare, automotive, industrial), require human oversight, calibration, bias testing, and adherence to regulatory standards before deployment.
Glossary
- AP50: Average Precision at an intersection-over-union threshold of 0.5, used to assess detection/segmentation quality. "improvements of 4.7\% in AP50 and 6.6\% in Recall."
- CIDEr: A captioning metric that measures consensus between generated and reference descriptions using TF-IDF weighting over n-grams. "the new SOTA improves over the previous best by +1.3\% METEOR and +5.5\% CIDEr in captioning metrics"
- Codebook: The finite set of discrete vectors used to map continuous embeddings to quantized codes in vector quantization. "a vector quantizer with codebook "
- Commitment loss: A regularization term encouraging the encoder outputs to commit to the quantized codes, stabilizing training with quantization. "including a reconstruction loss and a commitment loss."
- Cross-attention: An attention mechanism where queries attend to keys/values from a different source (e.g., image features). "via self-attention and with the image features via cross-attention"
- Cross-entropy loss: A standard classification/regression loss; here used for pixel-wise mask reconstruction. "The reconstruction loss is computed as the sum of the cross-entropy loss and the Dice loss"
- Dice loss: An overlap-based loss for segmentation that optimizes the similarity between predicted and ground-truth masks. "The reconstruction loss is computed as the sum of the cross-entropy loss and the Dice loss"
- Generalized Intersection over Union (gIoU): A mask/box overlap metric that extends IoU to penalize non-overlapping predictions. "achieving gains of 8.9\% in gIoU and 21.0\% in N-acc"
- Generalized referring expression segmentation (GRES): A benchmark/task for text-to-mask segmentation conditioned on complex referring expressions. "generalized referring expression segmentation (GRES)"
- Grounded conversation generation (GCG): A task that interleaves captioning with region grounding by generating masks for mentioned phrases. "grounded conversation generation (GCG)"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm for optimizing sequence generation with relative rewards. "After applying GRPO~\cite{grpo}, QwenVL-SAMTok demonstrates significant improvements"
- Mask decoder: The model component that produces segmentation masks from image and prompt embeddings. "a mask decoder $f_{\text{msk}$"
- Mask embedding: A compact latent vector representing a region mask for encoding/decoding. "we obtain the desired SAMTok encoder output: a -dimensional continuous mask embedding ${\mathbf{z}$:"
- Mask VAE: A variational autoencoder specialized for masks, enabling bidirectional mapping between masks and latents. "SAMTok is a mask VAE integrated with vector quantization"
- METEOR: A captioning metric that uses stem matching, synonyms, and alignment to evaluate text quality. "+1.3\% METEOR and +5.5\% CIDEr"
- mIoU (mean Intersection over Union): The average IoU across instances or classes, commonly used for segmentation evaluation. "+5.2\% mIoU"
- N-acc: A naming/phrase-level accuracy metric in referring segmentation that measures correct association between predicted regions and target referents. "21.0\% in N-acc"
- Nearest-neighbor lookup: The operation of selecting the closest codebook vector to a continuous embedding during quantization. "First, we conduct a nearest-neighbor lookup in the codebook "
- Next-token prediction loss: The standard autoregressive training objective for LLMs, used here to learn mask understanding/generation. "through next token prediction loss, achieving SOTA performance across dozens of diverse benchmarks."
- Panoptic scene graph generation (PSG): A task combining panoptic segmentation with scene graph relations at the pixel level. "panoptic scene graph generation (PSG)"
- Prompt encoder: The module that encodes user prompts (e.g., masks) into embeddings for conditioning segmentation. "the SAM prompt encoder $f_{\text{prm}$ encodes a 2D mask "
- Quantization codes: The discrete indices selected from a codebook to represent continuous embeddings compactly. "The SAMTok encoder first encodes masks into quantization codes, which are then formatted into predefined special tokens."
- Residual quantization: A multi-stage quantization method that iteratively quantizes residuals to achieve high-fidelity compression. "We employ a residual quantization scheme~\cite{rq} to discretize the continuous mask embedding "
- Residual vector quantizer: A quantizer that uses multiple code selections to encode a vector via its residuals for improved fidelity. "a mask encoder and residual vector quantizer to produce discrete, compact, and information-rich tokens."
- RLE encoding: Run-Length Encoding, a compact textual representation of binary masks by encoding consecutive runs. "representing them as text in formats similar to RLE encoding or polygons."
- SAM2: The second-generation Segment Anything Model used as the foundation segmentation backbone. "SAMTok builds on SAM2 and is trained on 209M diverse masks"
- Self-attention: An attention mechanism where queries attend to keys/values from the same sequence or feature set. "via self-attention and with the image features via cross-attention"
- SFT (Supervised Fine-Tuning): Post-training with labeled data to adapt a base model to specific tasks. "requiring only next-token prediction loss for supervised fine-tuning (SFT) and straightforward reinforcement learning (RL)?"
- Stop-gradient operator: An operation that prevents backpropagation through a tensor during training. "where denotes the stop-gradient operator"
- Textual answer-matching reward: A string-based RL reward computed by matching predicted textual tokens against ground-truth answers. "we propose a textual answer-matching reward function for generated masks"
- Vector quantization: Mapping continuous vectors to nearest entries in a discrete codebook to obtain compact representations. "Vector quantization methods excel at the property of effectively discretizing continuous latents into compact codes to facilitate RL training."
- Variational autoencoder (VAE): A probabilistic encoder–decoder model that learns latent representations via variational inference. "Variational autoencoders (VAE) excel at the property of converting between images and latent representations."
- Vision Question Answering (VQA): A task where models answer questions about images, used as a training paradigm for MLLMs. "as simple as VQA trainingârequiring only next-token prediction loss"
- Visual grounding: Linking textual phrases to corresponding image regions through localization (masks/boxes). "visual groundingâunder a single textual formulation."
Collections
Sign up for free to add this paper to one or more collections.