IVRA: Improving Visual-Token Relations for Robot Action Policy with Training-Free Hint-Based Guidance
Abstract: Many Vision-Language-Action (VLA) models flatten image patches into a 1D token sequence, weakening the 2D spatial cues needed for precise manipulation. We introduce IVRA, a lightweight, training-free method that improves spatial understanding by exploiting affinity hints already available in the model's built-in vision encoder, without requiring any external encoder or retraining. IVRA selectively injects these affinity signals into a language-model layer in which instance-level features reside. This inference-time intervention realigns visual-token interactions and better preserves geometric structure while keeping all model parameters fixed. We demonstrate the generality of IVRA by applying it to diverse VLA architectures (LLaRA, OpenVLA, and FLOWER) across simulated benchmarks spanning both 2D and 3D manipulation (VIMA and LIBERO) and on various real-robot tasks. On 2D VIMA, IVRA improves average success by +4.2% over the baseline LLaRA in a low-data regime. On 3D LIBERO, it yields consistent gains over the OpenVLA and FLOWER baselines, including improvements when baseline accuracy is near saturation (96.3% to 97.1%). All code and models will be released publicly. Visualizations are available at: jongwoopark7978.github.io/IVRA













Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces IVRA, a simple add-on that helps robots understand where things are in an image more accurately. Many robot models turn pictures into a long line of small pieces (called “tokens”), which can make the model forget which pieces are neighbors in the original 2D image. IVRA fixes this by using “hints” the model already has—how similar nearby image pieces are—to keep object shapes and boundaries clear. It works at test time (no extra training) and improves how well robots follow instructions to act in the world.
What questions did the paper ask?
- Do current vision–language–action (VLA) models lose important 2D information (like object boundaries and exact positions) when they flatten images into a 1D sequence of tokens?
- Can we recover that lost spatial detail using the model’s own built-in vision encoder, without retraining?
- Will this quick, training-free fix help different robot models on both simulated and real-world tasks?
How does IVRA work? (Simple explanation)
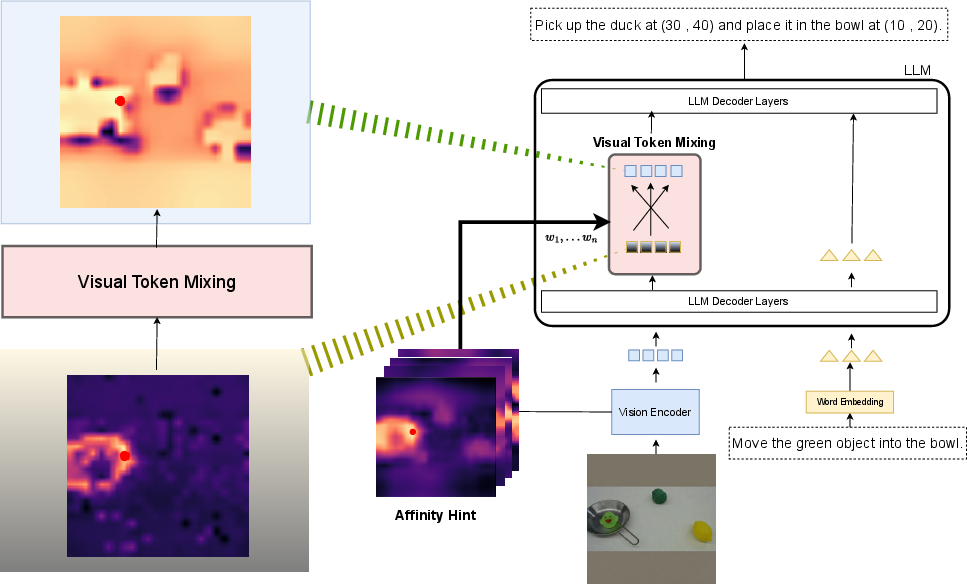
Think of an image as a tiled floor made of many small squares (patches). Most robot models lift those tiles into a single line, like writing the floor tiles as a sentence. That loses the “who is next to whom” information. IVRA brings that neighborhood information back.
Here’s the idea, using everyday language:
- The model’s vision encoder already knows which patches look alike—like a “friend map” saying which tiles probably belong to the same object. This is called an affinity map: it gives a high score to pairs of patches that look similar (usually parts of the same object).
- When the robot’s LLM is reading the combined text+image tokens, IVRA gently blends each image token with its most similar neighbors according to that “friend map.” Imagine averaging the voices of a small group of classmates who are working on the same project—this keeps each group (object) clearly defined.
- IVRA only does this blending in a specific layer of the LLM and only for the image tokens (not the text tokens).
- The blending is careful: it mixes a small portion of the “neighbor average” with the original token. This keeps the original meaning but sharpens object boundaries and shapes.
- Important: nothing is retrained. IVRA is a plug-in that runs at test time. No new modules, no extra parameters—just a tiny extra step that uses what the model already knows.
Analogy: If the model is taking a test, IVRA is like a small sticky note reminding it which picture pieces belong together, so it doesn’t confuse where objects start and end.
What did they find?
The authors tested IVRA on several robot systems and tasks, in simulations and on real robots. Here are the big takeaways:
- In 2D simulated tasks (VIMA benchmark) using the LLaRA robot model and only 12% of the training data, IVRA raised average success by about +4.2%. On the hardest “Novel Task” setting, it improved results by +5.0%.
- In 3D simulated tasks (LIBERO benchmark):
- With OpenVLA, IVRA improved average success from 76.5% to 77.6%.
- With FLOWER (already very strong), IVRA still boosted average success from 96.3% to 97.1%, showing benefits even when the baseline is near perfect.
- On real robots, IVRA helped across four tasks:
- Picking a named object (Target Object): +10% improvement.
- Choosing an object by color (Color Match): +30% improvement.
- Selecting the right object in clutter (Cluttered Localization): +30% improvement.
- Picking the long vs. short object (Relative Height): +20% improvement.
- Cost and complexity:
- No retraining and no extra parameters.
- Only a tiny runtime overhead (~3% slower per action), which is small compared to the gains.
Why these results matter: Precise object boundaries and attributes (like color and size) are critical for reliable grasping and placement. IVRA makes models better at these details without extra data or training.
Why this matters and what it could change
- Faster iteration: Because IVRA works without retraining, researchers and practitioners can improve existing robot models immediately—just add IVRA at test time.
- Better precision: Sharper understanding of object boundaries and attributes means fewer mistakes when grasping or placing items, especially in crowded scenes.
- Broad usefulness: IVRA helped different models (LLaRA, OpenVLA, FLOWER), different environments (2D and 3D), and both simulated and real robots. That means it’s a general, plug-and-play upgrade.
- Data efficiency: The improvements are notable even with limited training data, which is important because collecting robot data is expensive and time-consuming.
Key terms in simple words
- Visual token: A small piece of an image the model treats like a “word.”
- Affinity map: A scorecard that says how similar each pair of image patches is. High scores usually mean “parts of the same object.”
- Training-free / inference-time: You don’t teach the model new skills; you just give it a helpful hint during use.
- VLA model: A system that reads vision (images), language (instructions), and outputs actions (what the robot should do).
In short, IVRA is a small, smart trick: it reminds the robot model which image pieces belong together so it can act more precisely—no retraining needed.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address.
- Sensitivity to the vision encoder: Quantify how IVRA’s gains vary with different backbone encoders (e.g., CLIP vs. DINO variants), patch sizes, image resolutions, and encoder architectures used in LLaRA, OpenVLA, FLOWER; provide guidelines for selecting compatible encoders.
- Choice of encoder layer for affinity extraction: Systematically ablate which intermediate encoder block is best for computing the affinity map and whether layer choice should vary by task or domain.
- Affinity definition and normalization: Compare cosine similarity with alternative metrics (e.g., learned Mahalanobis, softmax kernels, edge-aware affinities), and evaluate the impact of clamping negatives (max(Aij, 0)) vs. preserving repulsive cues for boundary sharpening.
- Spatial locality vs. global mixing: Assess whether restricting affinity pooling to local neighborhoods (top-k or radius-constrained) yields better small-object fidelity and lower computational cost than full N×N mixing.
- Scalability and memory footprint: Characterize runtime and GPU memory usage across higher-resolution inputs, multi-image prompts, and video sequences; develop efficient approximations (e.g., sparse affinities, low-rank factorizations) for large N.
- Temporal consistency in video/control: Extend IVRA to temporal tokens by incorporating frame-to-frame affinities (optical flow, tracklets) and evaluate on video-based policies requiring motion/occlusion reasoning.
- Depth and 3D cues: Investigate whether incorporating depth maps, point clouds, or multi-view correspondences into affinity computation improves 3D manipulation in LIBERO-like settings.
- Automatic layer selection in LLM: Replace empirical layer choice (e.g., layer 20) with data-driven or diagnostic criteria for selecting injection layers per architecture; explore multi-point or adaptive injection strategies.
- Effect on language grounding and reasoning: Measure whether IVRA perturbs cross-modal alignment or linguistic reasoning (e.g., referring expressions, compositional instructions) using dedicated language–grounding benchmarks.
- Cross-attention vs. self-attention intervention: Test injecting hints into cross-attention modules, or modulating visual–text attention weights based on affinity, to directly influence grounding instead of only self-attention.
- Adaptive token mixing coefficient (λ): Develop per-token/per-image adaptive λ (or gating) driven by confidence, entropy, or affinity sharpness to avoid over-smoothing while maximizing boundary preservation.
- Failure-mode analysis: Identify scenarios where IVRA degrades performance (e.g., strong texture similarity across different objects, heavy occlusion, transparent/reflective surfaces) and propose safeguards.
- Robustness to domain shift: Evaluate under challenging real-world conditions (moving cameras, varied lighting/backgrounds, reflectance, non-planar surfaces, deformable objects) beyond the fixed overhead camera and plain tabletop.
- Broader embodiment and sensors: Test on different robot platforms (mobile manipulators, hand–eye cameras) and sensor suites (stereo, event cameras, tactile/proprioception) to probe generality and integration challenges.
- Interaction with external detectors: Clarify and quantify how IVRA complements or conflicts with open-vocabulary detectors/region features; propose unified pipelines that combine region proposals with affinity-guided token mixing.
- Beyond success rate metrics: Introduce quantitative measures of instance-level preservation (e.g., boundary F-score, mask IoU via pseudo-labels, attention locality indices) to substantiate improved spatial fidelity.
- Theoretical understanding: Analyze how affinity-guided pooling alters the representational geometry and attention distributions in Transformers; connect improvements to formal notions of locality, mutual information, or inductive bias.
- Training vs. training-free trade-offs: Compare IVRA to lightweight learned adapters (e.g., parameter-efficient finetuning) and hybrid approaches (learned λ or hint fusion) to understand accuracy–complexity Pareto fronts.
- Generalization across VLA families: Validate IVRA on additional VLA models (e.g., LLARVA, RT-2-style, PaLM-E) and report when architectural differences require variant implementations or tuning.
- Task diversity and scale: Expand real-world evaluation to more tasks, larger episode counts, statistical significance testing, and longer-horizon, partially observable scenarios to stress compositional planning and recovery behavior.
- Safety and reliability: Assess the impact of inference-time token manipulation on action safety (near-misses, unintended contacts), and develop monitoring or rollback mechanisms for high-stakes deployments.
Glossary
- Adapters: Small trainable modules inserted into a model to adapt or fuse features without retraining the entire network. "these strategies often train adapters or decoders to fuse the spatial hints back into the model."
- Affinity-guided pooling: A pooling operation that weights features using similarity scores (affinities) to preserve local structure. "we apply an affinity-guided pooling operation."
- Affinity hints: Similarity signals extracted from a vision encoder that indicate which patches are related. "These affinity hints are then injected into deeper layers of the LLM"
- Affinity map: A representation of pairwise similarities across image patches capturing local spatial relationships. "uses an affinity map, extracted from the model's encoder, indicating local similarity between patches."
- Affinity matrix: A matrix whose entries quantify similarity between patches in an image. "we compute an affinity matrix "
- Attention residual: The residual (skip) connection output surrounding the attention sublayer in a Transformer block. "P3 (after the attention residual)"
- Calibration: The process of mapping image coordinates to robot action space through a known transformation. "a simple linear mapping between the image coordinates and the robot action space can be established by calibration."
- CLIP: A contrastively pretrained vision-language encoder that aligns images and text in a shared embedding space. "encoders such as CLIP"
- Compositionality: The property of combining learned skills or concepts to solve new tasks. "stresses different forms of transfer and compositionality."
- Convex combination: A linear blend of vectors with nonnegative weights summing to one. "We form the final visual token as a convex combination:"
- Denoised features: Feature representations refined to reduce noise, often via affinity-based reweighting. "produce denoised features by re-weighting coarse embeddings with affinity matrices"
- Detection transformer: A transformer-based object detection architecture integrating language or set-based queries. "into the detection transformer to achieve open-set localization"
- Diffusion Policy: A control policy approach that leverages diffusion models for action generation. "including Diffusion Policy~\cite{chi2023diffusion}"
- Embodied control: Control of an agent (e.g., a robot) acting in a physical 3D environment. "to 3D embodied control"
- End-to-end training: Jointly training all components of a system from input to output. "through end-to-end training"
- Frozen vision encoder: A pretrained visual backbone kept fixed (not updated) during downstream processing. "A frozen vision encoder provides an affinity hint"
- Instance-level features: Features corresponding to individual object instances rather than global scene statistics. "a language-model layer in which instance-level features reside."
- Instance-level recognition: Identifying specific object instances and their boundaries/attributes. "improves instance-level recognition and localization"
- Inference-time intervention: A modification applied only during inference, without changing model parameters. "This inference-time intervention realigns visual-token interactions"
- Language-conditioned: Conditioned on natural language inputs to guide perception or control. "language-conditioned 3D manipulation tasks"
- Layer normalization: A normalization technique applied within Transformer layers to stabilize training/inference. "proceed through the layer normalization"
- Layer-agnostic: Not highly sensitive to which layer the method is applied to. "It is important that IVRA is largely layer-agnostic"
- Long-horizon control: Control tasks requiring extended sequences of actions over many steps. "long-horizon control."
- Low-data regime: A setting where only a small fraction of training data is available. "in a low-data regime."
- Multimodal prompts: Prompts that combine multiple modalities (e.g., text and image) to specify tasks. "VIMA uses multimodal prompts for diverse manipulation tasks"
- Open-set localization: Localizing objects described by open-ended text categories not seen during training. "to achieve open-set localization"
- Open-vocabulary detection: Detecting objects specified by arbitrary text labels beyond a fixed class set. "open-vocabulary detection methods"
- Oracle detector: An assumed perfect or external detector used to provide ideal object information. "with the oracle detector"
- Patch embeddings: Vector representations computed for each image patch by a vision encoder. "yielding patch embeddings ."
- Patch-wise correlations: Similarity measures computed between pairs of image patches. "compute patch-wise correlations"
- Plug-and-play: Easily integrated into existing systems without retraining or architectural changes. "we apply IVRA to FLOWER in a plug-and-play manner"
- Projection module: A linear (or small) mapping used to project features to a target dimensionality. "after/before the projection module (A. Proj., B. Proj.)"
- Quantized robot actions: Discrete action tokens obtained by quantizing continuous control commands. "directly mappable to quantized robot actions"
- Region annotations: Labeled regions (e.g., boxes or masks) used for training detection/segmentation models. "training on curated region annotations."
- Self-attention block: The submodule in a Transformer that computes attention among tokens within a sequence. "before the layer’s self-attention block"
- Spatial fidelity: Preservation of accurate spatial structure and object boundaries in representations. "This strategy balances spatial fidelity and high-level context"
- Token mixing: Combining information across tokens (e.g., visual tokens) to refine representations. "guides token mixing with weighted pooled tokens"
- Token-mixing coefficient: A scalar controlling the strength of mixing between original and pooled tokens. "only set the token-mixing coefficient to 0.2"
- Transformer block: A standard module comprising attention and feed-forward sublayers. "within each transformer block"
- Vision-Language-Action (VLA): Models that map visual and language inputs to action outputs. "Vision-Language-Action (VLA) models have rapidly emerged"
- Vision-LLM (VLM): A model that jointly processes visual and textual data. "VLM produces a discrete set of special tokens"
- Visual tokens: Tokens derived from image patches that are fed into a language/transformer model. "affinity maps computed from visual tokens inside the LLM are often diffuse"
- Weighted average pooling: Averaging features using weights (e.g., affinities) to emphasize relevant neighbors. "within-layer locations for our affinity-based weighted average pooling"
- Zero-shot generalization: Performing correctly on tasks or categories not seen during training. "To evaluate zero-shot generalization, we use the LLaRA model"
Practical Applications
Practical Applications Derived from the Paper’s Findings
The paper presents IVRA, a training-free, inference-time method that injects encoder-derived visual affinity hints into mid-layers of Vision-Language-Action (VLA) models to preserve instance-level spatial structure. IVRA consistently improves manipulation success across 2D and 3D benchmarks (VIMA, LIBERO) and on real robots with negligible latency overhead and no retraining. Below are actionable applications and their feasibility.
Immediate Applications
- IVRA plug-in for existing robot policies
- Sectors: manufacturing, logistics, retail, service robotics
- Use case: Drop-in upgrade to LLaRA/OpenVLA/FLOWER-based manipulators to boost pick-and-place precision without retraining or re-labeling.
- Tools/products/workflows: IVRA inference module (Python SDK), ROS2/Isaac wrappers, config for layer index and λ, on/off A/B toggles in MLOps.
- Assumptions/dependencies: Access to a ViT-like frozen vision encoder and mid-layer features; ability to run a small NxN affinity computation per frame; patch-token based VLA architecture.
- Bin-picking and kitting in clutter
- Sectors: manufacturing, logistics/warehousing
- Use case: Robust selection and placement from cluttered bins; reduced accidental collisions; better boundary-aware grasping.
- Tools/products/workflows: IVRA-enabled grasp planners; affinity-map visualizer for operators; KPI: collision rate, pick accuracy.
- Assumptions/dependencies: Calibrated camera-to-robot mapping; lighting within encoder’s operating domain; real-time budget tolerates ~3% latency overhead.
- Attribute-based picking and sorting (color/shape/size)
- Sectors: retail (shelf restocking), e-commerce fulfillment, industrial QA
- Use case: “Pick the green cap,” “select the long bolt,” “sort by color/size” with higher fidelity to object boundaries and attributes.
- Tools/products/workflows: Workflow nodes that parse textual specs into VLA prompts; IVRA-enhanced policies; conveyor sorting lines.
- Assumptions/dependencies: Attributes visible in RGB; attribute vocabularies mapped to instruction templates; stable SKU appearance.
- Quality control and visual inspection with manipulation
- Sectors: manufacturing
- Use case: Remove defective items identified by visual anomalies (wrong color/contamination) with precise targeting.
- Tools/products/workflows: Perception-to-action pipelines where detectors flag items and IVRA policy executes targeted removals; audit logs with affinity maps for traceability.
- Assumptions/dependencies: Anomaly detection upstream (could be open-vocabulary or classical); reliable access to image patches for affinity.
- Hospital and lab logistics robots
- Sectors: healthcare, biotech labs
- Use case: Pick/place vials or supplies in cluttered trays and racks; reduce wrong-item pickups; safer manipulation in shared spaces.
- Tools/products/workflows: IVRA-enabled cart robots; operator dashboard showing affinity overlays for confidence checks.
- Assumptions/dependencies: Institutional safety protocols; predictable lighting/placement; non-surgical applications (no immediate clinical certification).
- Home and service robots (tidying, toy sorting, kitchen assistance)
- Sectors: consumer robotics, eldercare
- Use case: “Pick the yellow sponge,” “place the long utensil in the tray,” improved selection amid mixed items on countertops.
- Tools/products/workflows: Firmware update delivering IVRA; mobile apps to tune λ and layer location; on-device visualization for debugging.
- Assumptions/dependencies: Single camera or multi-camera calibration; household variability within encoder’s generalization range.
- Produce grading and conveyor sorting
- Sectors: agriculture, food processing
- Use case: Sort fruit/vegetables by ripeness color or size while minimizing misgrasp due to boundary bleed.
- Tools/products/workflows: IVRA add-on in existing pick-and-place cells; throughput monitoring; changeover via language prompts.
- Assumptions/dependencies: Motion blur management; consistent conveyor speed; color robustness under high-CRI illumination.
- Data-efficient deployment and rapid pilots
- Sectors: any VLA-based robotics teams
- Use case: Achieve higher success with modest training data (e.g., +4.2% on VIMA with ~12% data), accelerating proof-of-concepts.
- Tools/products/workflows: Pilot kits bundling pretrained policies + IVRA; small synthetic datasets; minimal on-site fine-tuning.
- Assumptions/dependencies: Tasks similar to benchmarks; domain gap manageable with affinity cues alone.
- Academic baselines and benchmarking
- Sectors: academia, R&D labs
- Use case: Standardize IVRA as a comparative baseline for spatial reasoning in VLAs; reproduce LIBERO/VIMA improvements.
- Tools/products/workflows: Open-source IVRA code; ablation scripts (layer position, pooling location P0–P4, λ sweep); affinity-map qualitative panels.
- Assumptions/dependencies: Access to public LLaRA/OpenVLA/FLOWER checkpoints; identical preprocessing.
- Developer diagnostics and explainability
- Sectors: software tools, robotics integration
- Use case: Inspect affinity maps pre/post IVRA to debug failure cases and justify grasp choices to stakeholders.
- Tools/products/workflows: “IVRA Monitor” UI; logs of affinity-weighted tokens; policy rollouts with overlays.
- Assumptions/dependencies: Visualization hooks to encoder and LLM layers; storage for telemetry.
Long-Term Applications
- 3D-aware IVRA with depth/point clouds/multi-view
- Sectors: manufacturing, construction, energy, surgical robotics
- Use case: Extend hints to 3D affinities for precise assembly, valve turning, cable routing, or safe instrument manipulation.
- Tools/products/workflows: Fusion of RGB-D/point cloud affinities; volumetric token mixing; CAD-constrained planning.
- Assumptions/dependencies: Robust 3D sensing; O(N2) scaling managed via sparsification; validation for safety-critical domains.
- Mobile manipulation in dynamic, unstructured environments
- Sectors: logistics (back-of-house), field robotics, agriculture
- Use case: Temporal affinity across frames for moving objects; consistent targeting while the robot/base is in motion.
- Tools/products/workflows: Spatiotemporal token mixing layers; SLAM-integrated affinity; predictive grasping modules.
- Assumptions/dependencies: Real-time constraints; motion blur; temporal consistency models.
- Integration with open-vocabulary grounding and detection
- Sectors: retail, inspection, defense EOD
- Use case: Combine Region/Box queries (Grounding DINO-like) with IVRA’s fine-grained token mixing to localize and manipulate long-tail objects.
- Tools/products/workflows: Hybrid pipeline (detector proposals → IVRA-enhanced policy); uncertainty-aware handoff.
- Assumptions/dependencies: Additional training or curated data for grounding; latency budget for two-stage systems.
- Affinity-guided UI automation for multimodal agents
- Sectors: software automation (RPA), enterprise IT
- Use case: Screen element grouping via visual affinity to improve click/drag reliability for instruction-following desktop agents.
- Tools/products/workflows: “IVRA-for-UI” adapter for screenshot tokens; enterprise RPA orchestration.
- Assumptions/dependencies: ViT-like screen encoders; accurate tokenization of UI elements; dataset shift across themes/DPIs.
- Operator-in-the-loop AR/VR teleoperation assistance
- Sectors: mining, subsea, nuclear decommissioning, healthcare training
- Use case: Overlay affinity-highlighted regions to guide human teleoperators toward safe grasps and placements.
- Tools/products/workflows: AR HUD with affinity maps; haptic cues triggered by affinity confidence.
- Assumptions/dependencies: Low-latency streaming; robust calibration; human factors validation.
- Regulatory auditing and procurement standards for robot explainability
- Sectors: healthcare, food, pharma, aviation MRO
- Use case: Use affinity visualizations as audit artifacts to demonstrate boundary-aware targeting and reduce unintended contacts.
- Tools/products/workflows: Compliance packs with logged affinity evidence; procurement checklists requiring mid-layer access/monitoring.
- Assumptions/dependencies: Regulator acceptance of inference-time interventions; standardized logging formats.
- Hardware acceleration and edge deployment
- Sectors: embedded robotics, consumer devices
- Use case: Dedicated kernels for affinity computation and token mixing to run at the edge with high-resolution inputs.
- Tools/products/workflows: CUDA/TensorRT kernels; sparsified/top-k affinity; on-sensor prefiltering.
- Assumptions/dependencies: Vendor support for mid-layer hooks; memory limits for large N (patch count).
- Adaptive, learned hint schedules
- Sectors: research → productization
- Use case: Meta-controllers that pick layer positions, λ, and pooling sparsity on-the-fly based on scene difficulty.
- Tools/products/workflows: Bandit/RL tuning loops; uncertainty-driven gating; per-task profiles.
- Assumptions/dependencies: Additional telemetry; careful guardrails to avoid instability.
- Cross-domain generalization kits
- Sectors: education, SMEs in automation
- Use case: “IVRA Studio” for quick tuning on new domains with minimal data; scenario templates (kitchen, lab, warehouse).
- Tools/products/workflows: Wizard for layer/λ selection; benchmark harness; synthetic-to-real adapters.
- Assumptions/dependencies: Representative pilot scenes; limited domain shift.
- Safety-critical robotics (surgical, human-robot collaboration)
- Sectors: healthcare, industrial cobots
- Use case: Reduce near-misses via better boundary adherence; support fine suturing or delicate placements with future 3D IVRA.
- Tools/products/workflows: Redundant sensing; fail-safes; formal verification of token-mixing effects.
- Assumptions/dependencies: Extensive validation, certification, and human factors trials; robust out-of-distribution behavior.
Notes on feasibility and dependencies that cut across applications:
- Architectural: Requires ViT-like encoders with accessible intermediate patch embeddings and the ability to intercept LLM layers for token mixing. Closed ecosystems without hooks may need vendor cooperation.
- Computational: Affinity is O(N2) in patch count; high-resolution or multi-camera setups need sparsification or tiling. Reported overhead is small (~3%) at tested scales.
- Calibration: Precise pixel-to-robot mapping is necessary for physical tasks; multi-camera/moving-camera scenarios introduce additional complexity.
- Data/Domain: IVRA improves data efficiency but still assumes visual attributes are visible and within the encoder’s prior; severe domain shifts may require complementary adaptation.
- Safety: While IVRA reduces erroneous contacts in clutter, safety-critical deployments still require risk analysis, monitoring, and compliance processes.
Collections
Sign up for free to add this paper to one or more collections.